Миграция из локального хранилища HDFS в служба хранилища Azure с помощью Azure Data Box
Вы можете перенести данные из локального хранилища HDFS кластера Hadoop в служба хранилища Azure (хранилище BLOB-объектов или Data Lake Storage) с помощью устройства Data Box. Можно выбрать Диск Data Box, Data Box на 80 ТБ или Data Box Heavy на 770 ТБ.
В этой статье показано, как выполнять задачи, перечисленные ниже.
- Подготовка к переносу данных
- Копирование данных в Диск Data Box, Data Box или устройство Data Box Heavy
- Отправка устройства обратно в Корпорацию Майкрософт
- Применение разрешений доступа к файлам и каталогам (только Data Lake Storage)
Необходимые компоненты
Компоненты, указанные ниже, необходимы для выполнения переноса.
Учетная запись хранения Azure.
Локальный кластер Hadoop, содержащий исходные данные.
-
Подключите устройство Data Box или Data Box Heavy к локальной сети с помощью кабеля.
Если вы готовы, давайте начнем.
Копирование данных на устройство Data Box
Если данные помещаются в одно устройство Data Box, скопируйте данные на устройство Data Box.
Если объем данных превышает емкость устройства Data Box, примените дополнительную процедуру, чтобы разделить данные между несколькими устройствами Data Box, затем выполните копирование.
Чтобы скопировать данные из локального хранилища HDFS на устройство Data Box, необходимо настроить несколько действий, а затем использовать средство DistCp .
Выполните описанные ниже действия, чтобы скопировать данные на устройство Data Box с помощью REST API хранилища BLOB-объектов/объектов. Интерфейс REST API делает устройство в качестве хранилища HDFS в кластере.
До копирования данных с помощью REST следует определить примитивы безопасности и подключения для подключения к интерфейсу RESTF на Data Box или Data Box Heavy. Войдите в локальный пользовательский веб-интерфейс Data Box и перейдите на страницу Подключиться и копировать. В учетных записях хранения Azure для устройства в разделе "Параметры доступа", найдите и выберите REST.
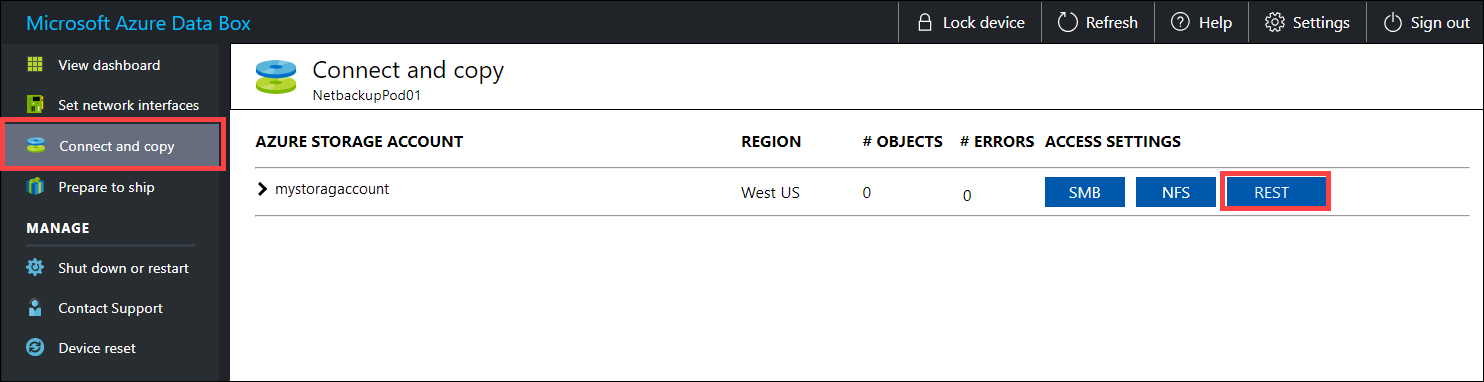
В диалоговом окне "Доступ к учетной записи хранения и отправка данных" скопируйте элемент Конечная точка службы BLOB-объектов и Ключ учетной записи хранения. В записи конечной точки службы BLOB-объектов опустите
https://и замыкающую косую черту.В этом случае конечная точка представлена записью:
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/. Ведущая часть используемого URI:mystorageaccount.blob.mydataboxno.microsoftdatabox.comВ качестве примера см. Подключение к REST по протоколу HTTP.
Добавьте конечную точку и IP-адрес узла Data Box или Data Box Heavy в
/etc/hostsна каждом узле.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comЕсли вы используете другой механизм для DNS, убедитесь, что конечная точка Data Box может быть разрешена.
Задайте для переменной оболочки
azjarsрасположение jar-файловhadoop-azureиazure-storage. Эти файлы находятся в каталоге установки Hadoop.Чтобы определить, существуют ли эти файлы, используйте следующую команду:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure. Замените заполнитель<hadoop_install_dir>, указав путь к каталогу, в котором установлен Hadoop. Обязательно укажите полный путь.Примеры:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarСоздайте контейнер хранилища, который будет использоваться для копирования данных. Кроме того, в этой команде следует указать целевой каталог. На этом этапе можно указать фиктивный целевой каталог.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Замените заполнитель
<blob_service_endpoint>, указав имя конечной точки службы BLOB-объектов.Замените заполнитель
<account_key>, указав ключ доступа вашей учетной записи.Замените временное значение
<container-name>, указав имя контейнера.Замените заполнитель
<destination_directory>, указав имя каталога, в который необходимо скопировать данные.
Выполните команду list, чтобы убедиться, что контейнер и каталог были созданы.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/Замените заполнитель
<blob_service_endpoint>, указав имя конечной точки службы BLOB-объектов.Замените заполнитель
<account_key>, указав ключ доступа вашей учетной записи.Замените временное значение
<container-name>, указав имя контейнера.
Скопируйте данные из Hadoop HDFS в хранилище BLOB-объектов Data Box в созданный ранее контейнер. Если каталог, в который вы копируетесь, не найден, команда автоматически создает ее.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Замените заполнитель
<blob_service_endpoint>, указав имя конечной точки службы BLOB-объектов.Замените заполнитель
<account_key>, указав ключ доступа вашей учетной записи.Замените временное значение
<container-name>, указав имя контейнера.Замените заполнитель
<exlusion_filelist_file>, указав имя файла, который содержит список исключений файлов.Замените заполнитель
<source_directory>, указав имя каталога, который содержит данные для копирования.Замените заполнитель
<destination_directory>, указав имя каталога, в который необходимо скопировать данные.
Параметр
-libjarsиспользуется, чтобы обеспечить доступность файлаhadoop-azure*.jarи зависимого файлаazure-storage*.jarдля командыdistcp. Возможно для некоторых кластеров это уже выполнено.В следующем примере показано, как команда
distcpиспользуется для копирования данных.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataЧтобы повысить скорость копирования, выполните действия, описанные ниже.
Попробуйте изменить количество сопоставителей. (Число сопоставителей по умолчанию — 20. В приведенном выше примере используются
m= 4 сопоставителя).Попробуйте выполнить
-D fs.azure.concurrentRequestCount.out=<thread_number>. Замените<thread_number>числом потоков на один сопоставитель. Произведение числа карт и количества потоков на средство сопоставления неm*<thread_number>должно превышать 32.Попробуйте параллельно запустить несколько команд
distcp.Обратите внимание, что лучше работать с большими файлами, чем с небольшими.
Если у вас есть файлы размером более 200 ГБ, рекомендуется изменить размер блока на 100 МБ со следующими параметрами:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
Отправка Data Box в корпорацию Майкрософт
Выполните действия, описанные ниже, чтобы подготовить и отправить устройство Data Box в корпорацию Майкрософт.
Сначала подготовьте устройство Data Box или Data Box Heavy к отправке.
После завершения подготовки устройства загрузите файлы спецификации. Эти файлы BOM или манифеста используются позже для проверки данных, отправленных в Azure.
Отключите устройство и отсоедините кабели.
Вызовите курьера для отправки посылки службой доставки UPS.
Сведения об устройствах Data Box см. в разделе Отправка Data Box.
Сведения об устройствах Data Box Heavy см. в разделе Отправка Data Box Heavy.
После получения устройства корпорация Майкрософт подключается к сети центра обработки данных, а данные передаются в учетную запись хранения, указанную при размещении заказа на устройство. По файлам спецификации проверьте, что все данные передаются в Azure.
Применение разрешений доступа к файлам и каталогам (только Data Lake Storage)
У вас уже есть данные в учетной записи хранения Azure. Теперь вы применяете разрешения на доступ к файлам и каталогам.
Примечание.
Этот шаг необходим, только если вы используете Azure Data Lake Storage в качестве хранилища данных. Его можно пропустить, если в качестве хранилища данных используется только учетная запись хранения BLOB-объектов без иерархического пространства имен.
Создание субъекта-службы для учетной записи с включенной учетной записью Azure Data Lake Storage
Сведения о создании субъекта-службы см. в статье "Практическое руководство. Создание приложения Microsoft Entra и субъекта-службы" с доступом к ресурсам с помощью портала.
При выполнении действий, описанных в разделе Назначение приложению роли этой статьи, не забудьте назначить субъекту-службе роль участника данных BLOB-объектов хранилища.
При выполнении действий, описанных в разделе Получение значений для входа этой статьи, сохраните идентификатор приложения и значения секрета клиента в текстовый файл. Вам нужны эти скоро.
Создание списка скопированных файлов с их разрешениями
Из локального кластера Hadoop выполните следующую команду:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
Эта команда создает список скопированных файлов с их разрешениями.
Примечание.
Выполнение этой команды может занять много времени, что зависит от количества файлов в HDFS.
Создание списка удостоверений и сопоставление их с удостоверениями Microsoft Entra
Загрузите сценарий
copy-acls.py. См. раздел Загрузка вспомогательных сценариев и настройка пограничных узлов для их запуска в этой статье.Выполните следующую команду, чтобы создать список уникальных удостоверений.
./copy-acls.py -s ./filelist.json -i ./id_map.json -gЭтот сценарий создает файл с именем
id_map.json, содержащий удостоверения, которые необходимо сопоставить с удостоверениями на основе ADD.Откройте файл
id_map.jsonв текстовом редакторе.Для каждого объекта JSON, отображаемого в файле, обновите
targetатрибут имени участника-пользователя Microsoft Entra (UPN) или ObjectId (OID) с соответствующим сопоставленным удостоверением. После этого сохраните файл. Этот файл потребуется для выполнения следующего шага.
Применение разрешений к скопированным файлам и применение сопоставлений идентификаторов
Выполните следующую команду, чтобы применить разрешения к данным, скопированным в учетную запись Data Lake Storage:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
Замените заполнитель
<storage-account-name>именем вашей учетной записи хранения.Замените временное значение
<container-name>, указав имя контейнера.Замените заполнители
<application-id>и<client-secret>заполнители идентификатором приложения и секретом клиента, полученными при создании субъект-службы.
Приложение. Разделение данных между несколькими устройствами Data Box
Прежде чем перемещать данные на устройство Data Box, необходимо скачать некоторые вспомогательные скрипты, убедиться, что данные упорядочены для размещения на устройстве Data Box и исключить ненужные файлы.
Загрузка вспомогательных сценариев и настройка пограничных узлов для их запуска
На пограничном или головном узле локального кластера Hadoop выполните следующую команду:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderЭта команда создает клон репозитория GitHub, содержащего вспомогательные сценарии.
Убедитесь, что на локальном компьютере установлен пакет jq .
sudo apt-get install jqУстановите пакет Requests Python.
pip install requestsЗадайте разрешения на выполнение для необходимых сценариев.
chmod +x *.py *.sh
Убедитесь, что данные упорядочены для размещения на устройстве Data Box.
Если размер данных превышает размер одного устройства Data Box, можно разделить файлы на группы, которые можно хранить на нескольких устройствах Data Box.
Если объем данных не превышают размер одного устройства Data Box, можно перейти к следующему разделу.
С более высоким уровнем разрешений запустите сценарий
generate-file-list, загруженный вследствие выполнения инструкций из предыдущего раздела.Ниже приведено описание параметров команды.
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.Скопируйте созданные списки файлов в HDFS, чтобы они были доступны для задания DistCp .
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
Исключите ненужные файлы
Необходимо исключить некоторые каталоги из задания DisCp. Например, исключите каталоги, содержащие сведения о состоянии, в котором поддерживается работа кластера.
В локальном кластере Hadoop, где планируется инициировать задание DistCp, создайте файл, указывающий список каталогов для исключения.
Приведем пример:
.*ranger/audit.*
.*/hbase/data/WALs.*
Следующие шаги
Узнайте, как Data Lake Storage работает с кластерами HDInsight. Дополнительные сведения см. в статье Об использовании Azure Data Lake Storage с кластерами Azure HDInsight.