Удаление дубликатов в каждой таблице для унификации данных
Шаг унификации "Правила дедупликации" находит и удаляет повторяющиеся записи для клиента из исходной таблицы, так что каждый клиент представлен одной строкой в каждой таблице. Каждая таблица дедуплицируется отдельно с использованием правил для идентификации записей для данного клиента.
Правила обрабатываются по порядку. После применения всех правил ко всем записям в таблице группы совпадений, имеющие общую строку, объединяются в одну группу совпадений.
Определение правил дедупликации
Хорошее правило идентифицирует уникального клиента. Рассмотрите свои данные. Возможно будет достаточно идентифицировать клиентов на основе такого поля, как адрес электронной почты. Однако если вы хотите различать клиентов, у которых есть общий адрес электронной почты, вы можете выбрать правило с двумя условиями, сопоставляющими по адресу электронной почты + имени. Дополнительную информацию см. в разделе Рекомендации по дедупликации.
На странице Правила дедупликации выберите таблицу и нажмите Добавить правило для определения правил дедупликации.
Совет
Если вы обогатили таблицы на уровне источника данных чтобы улучшить результаты объединения, выберите Использовать обогащенные таблицы в верхней части страницы. Дополнительная информация дана в теме Обогащение источников данных.

В области Добавить правило ведите следующие данные:
Выбрать поле: выберите из списка доступных полей таблицу, которую вы хотите проверить на наличие повторяющихся данных. Выберите поля, которые, вероятно, уникальны для каждого клиента. Например, адрес электронной почты или комбинация имени, города и номера телефона.
Нормализовать: выберите параметры нормализации для столбца. Нормализация влияет только на шаг сопоставления и не меняет данные.
- Цифры: преобразует символы Юникода, представляющие числа, в простые числа.
- Символы: удаляет символы и специальные символы, такие как !"#$%&'()*+,-./:;<=>? @[]^_`{|}~. Например Head&Shoulder становится HeadShoulder.
- Текст в нижний регистр: преобразует символы верхнего регистра в нижний регистр. "ВСЕ ЗАГЛАВНЫЕ БУКВЫ и Капитализация Начальных Букв" преобразуется во "все заглавные буквы и капитализация начальных букв".
- Тип (телефон, имя, адрес, организация): стандартизирует имена, должности, номера телефонов и адреса.
- Юникод в ASCII: преобразует символы Юникода в их буквенный эквивалент ASCII. Например, буква ề с диакритическим знаком преобразуется в букву e.
- Пробел: удаляет все пробелы. Hello World превращается в HelloWorld.
- Псевдоним сопоставление: позволяет загружать собственный список пар строк, чтобы указать строки, которые всегда следует считать точным совпадением.
- Пользовательский обход: позволяет загрузить собственный список строк, чтобы указать строки, которые никогда не должны совпадать.
Точность: задает уровень точности. Точность используется для точного и нечеткого совпадения и определяет, насколько близкими должны быть две строки, чтобы их можно было считать совпадением.
- Базовый: выберите Низкий (30%), Средний (60%), Высокий (80%), и Точный (100%). Выберите Точно, чтобы сопоставлять только записи, которые совпадают на 100 процентов.
- Пользовательский: задайте процент, которому должны соответствовать записи. Система сопоставляет только записи, превышающие этот порог.
Имя: имя для правила.
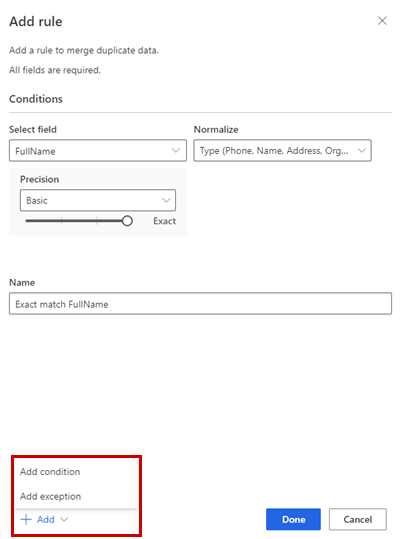
При желании выберите Добавить>Добавить условие, чтобы добавить дополнительные условия к правилу. Условия связаны с помощью логического оператора "И", поэтому выполнение происходит только при соблюдении всех условий.
Также можно выбрать Добавить>Добавить исключение, чтобы добавить исключения в правило. Исключения используются для устранения редких случаев ложноположительных и ложноотрицательных результатов.
Нажмите Готово, чтобы создать правило.
Вы также можете (необязательно) добавить дополнительные правила.
Выберите таблицу, а затем нажмите Изменить настройки объединения.
В области Объединить настройки:
Выберите один из трех вариантов, чтобы определить, какую запись сохранить при обнаружении повторяющихся данных:
- Наиболее заполненные: определяет запись с наиболее заполненными столбцами в качестве записи победителя. Это параметр объединения по умолчанию.
- Самые новые: определяет запись победителя на основе "самая новая". Требуется дата или числовое поле для определения давности.
- Наименее недавние: определяет запись победителя на основе "наименее недавние". Требуется дата или числовое поле для определения давности.
В случае ничьей побеждает запись с MAX(PK) или большим значением первичного ключа.
Также можно определить параметры объединения для отдельных столбцов таблицы. Для этого выберите Расширенные в нижней части области. Например, вы можете сохранить самую последнюю электронную почту И наиболее полный адрес из разных записей. Разверните таблицу, чтобы увидеть все ее столбцы, и определите, какой параметр использовать для отдельных столбцов. Если вы выберете вариант, основанный на давности, вам также необходимо указать поле даты/времени, определяющее давность.
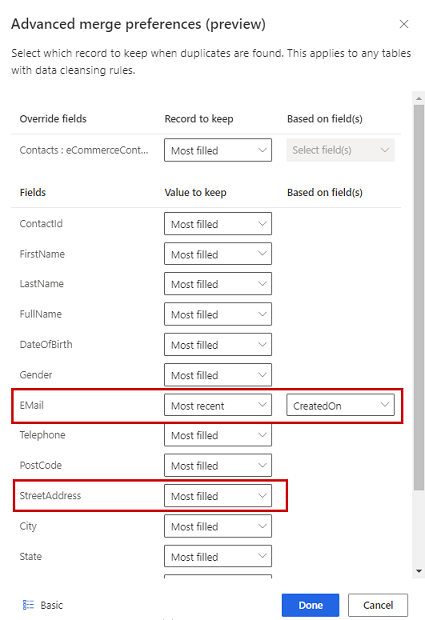
Выберите Готово, чтобы применить настройки объединения.
После определения правил дедупликации и настроек объединения нажмите Далее.
