Настройка Azure Synapse Analytics в действии копирования
В этой статье описывается, как использовать действие копирования в конвейере данных для копирования данных из Azure Synapse Analytics и из нее.
Поддерживаемая конфигурация
Для настройки каждой вкладки в действии копирования перейдите к следующим разделам соответственно.
Общие
Ознакомьтесь с руководством по общим параметрам, чтобы настроить вкладку "Общие параметры".
Исходный код
Следующие свойства поддерживаются для Azure Synapse Analytics на вкладке "Источник " действия копирования.

Требуются следующие свойства:
Тип хранилища данных: выберите "Внешний".
Подключение ion. Выберите подключение Azure Synapse Analytics из списка подключений. Если подключение не существует, создайте новое подключение Azure Synapse Analytics, нажав кнопку "Создать".
тип Подключение ion: выберите Azure Synapse Analytics.
Используйте запрос. Для чтения исходных данных можно выбрать таблицу, запрос или хранимую процедуру . В следующем списке описана конфигурация каждого параметра:
Таблица: чтение данных из таблицы, указанной в таблице , при выборе этой кнопки. Выберите таблицу из раскрывающегося списка или выберите "Изменить ", чтобы ввести имя схемы и таблицы вручную.

Запрос. Укажите настраиваемый SQL-запрос для чтения данных. Например,
select * from MyTable. Или щелкните значок карандаша для редактирования в редакторе кода.
Хранимая процедура: используйте хранимую процедуру, которая считывает данные из исходной таблицы. Последней инструкцией SQL должна быть инструкция SELECT в хранимой процедуре.

- Имя хранимой процедуры: выберите хранимую процедуру или укажите имя хранимой процедуры вручную при нажатии кнопки "Изменить".
- Параметры хранимой процедуры: выберите параметры импорта для импорта параметра в указанной хранимой процедуре или добавьте параметры для хранимой процедуры, нажав кнопку +Создать. Допустимые значения: пары имен или значений. Имена и регистр параметров должны совпадать с именами и регистром параметров хранимой процедуры.

В разделе "Дополнительно" можно указать следующие поля:
Время ожидания запроса (минуты): укажите время ожидания для выполнения команды запроса, значение по умолчанию — 120 минут. Если для этого свойства задан параметр, допустимые значения имеют интервал времени, например "02:00:00" (120 минут).
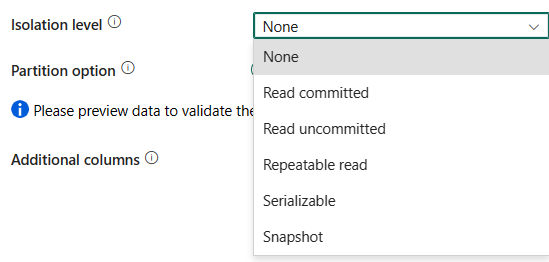
Уровень изоляции: указывает поведение блокировки транзакций для источника SQL. Допустимые значения: None, Read committed, Read uncommitted, Repeatable read, Serializable или Snapshot. Если это не указано, используется уровень изоляции None . Дополнительные сведения см. в разделе "Изоляция".
Параметр секционирования: укажите параметры секционирования данных, используемые для загрузки данных из Azure Synapse Analytics. Допустимые значения: Нет (по умолчанию), физические секции таблицы и динамический диапазон. Если параметр секции включен (то есть нет), степень параллелизма для параллельной загрузки данных из Azure Synapse Analytics управляется параметром параллельного копирования для действия копирования.
Нет. Выберите этот параметр, чтобы не использовать секцию.
Физические секции таблицы: выберите этот параметр, если вы хотите использовать физическую секцию. Столбец секции и механизм автоматически определяются на основе определения физической таблицы.
Динамический диапазон: выберите этот параметр, если вы хотите использовать секцию динамического диапазона. При использовании запроса с параллельным включенным параметром секционирования
?DfDynamicRangePartitionConditionдиапазона требуется. Пример запроса:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.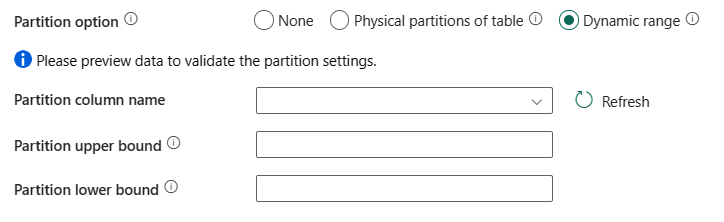
- Имя столбца секционирования: укажите имя исходного столбца в целочисленном или типе даты и даты и времени (
int,,smallint,smalldatetimedatedatetimebigintdatetime2, илиdatetimeoffset), используемом секционированием диапазона для параллельной копии. Если значение не указано, автоматически определяется индекс или первичный ключ таблицы, который затем используется в качестве столбца секционирования. - Верхняя граница секции: укажите максимальное значение столбца секционирования для разделения диапазона секций. Это значение используется для выбора шага секционирования, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса секционируются и копируются.
- Нижняя граница секции: укажите минимальное значение столбца секционирования для разделения диапазона секций. Это значение используется для выбора шага секционирования, а не для фильтрации строк в таблице. Все строки в таблице или результатах запроса секционируются и копируются.
- Имя столбца секционирования: укажите имя исходного столбца в целочисленном или типе даты и даты и времени (
Дополнительные столбцы: добавление дополнительных столбцов данных для хранения относительного пути или статического значения исходных файлов. Выражение поддерживается для последнего. Дополнительные сведения см. в описании "Добавление дополнительных столбцов во время копирования".
Назначение
Следующие свойства поддерживаются для Azure Synapse Analytics на вкладке "Назначение " действия копирования.

Требуются следующие свойства:
- Тип хранилища данных: выберите "Внешний".
- Подключение ion. Выберите подключение Azure Synapse Analytics из списка подключений. Если подключение не существует, создайте новое подключение Azure Synapse Analytics, нажав кнопку "Создать".
- тип Подключение ion: выберите Azure Synapse Analytics.
- Параметр таблицы. Вы можете выбрать "Использовать существующую", "Автоматически создать таблицу". В следующем списке описана конфигурация каждого параметра:
- Используйте существующую: выберите таблицу в базе данных из раскрывающегося списка. Или проверка Изменить, чтобы ввести имя схемы и таблицы вручную.
- Автоматическая создание таблицы: она автоматически создает таблицу (если она отсутствует) в исходной схеме.
В разделе "Дополнительно" можно указать следующие поля:
Метод copy Choose the method , который требуется использовать для копирования данных. Вы можете выбрать команду Copy, PolyBase, bulk insert или Upsert. В следующем списке описана конфигурация каждого параметра:
Команда копирования. Используйте инструкцию COPY для загрузки данных из хранилища Azure в Azure Synapse Analytics или пул SQL.
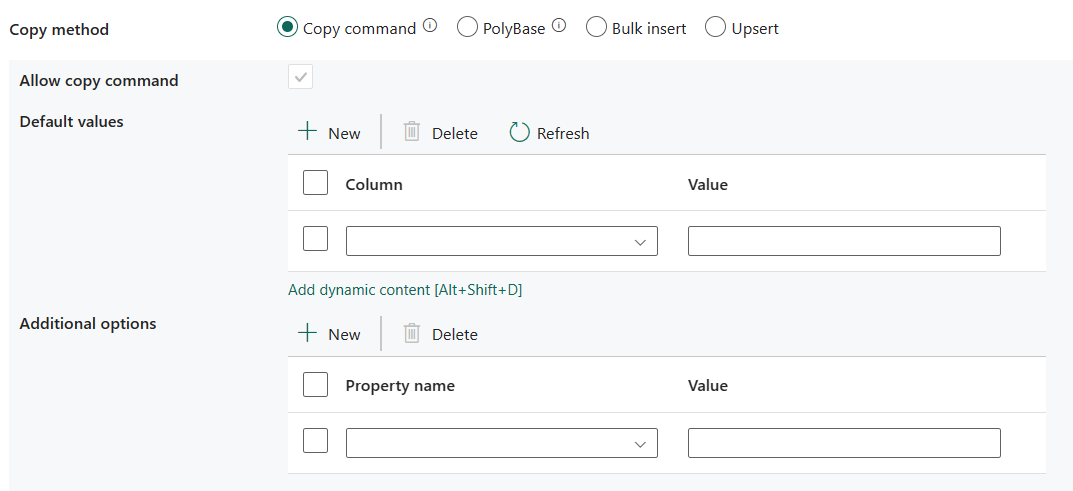
- Разрешить команду копирования: при выборе команды "Копировать" необходимо выбрать команду "Копировать".
- Значения по умолчанию: укажите значения по умолчанию для каждого целевого столбца в Azure Synapse Analytics. Значения по умолчанию из этого свойства переопределяют ограничение DEFAULT, заданное в хранилище данных, а столбец идентификаторов не может иметь значение по умолчанию.
- Дополнительные параметры: дополнительные параметры, которые будут переданы инструкции Azure Synapse Analytics COPY непосредственно в предложении With в инструкции COPY. Значение необходимо заключать в кавычки для соответствия требованиям инструкции COPY.
PolyBase: PolyBase — это механизм высокой пропускной способности. Используйте его для загрузки больших объемов данных в Azure Synapse Analytics или пул SQL.
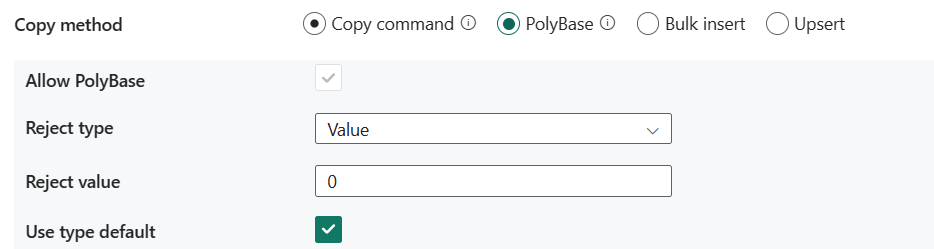
- Разрешить PolyBase: при выборе PolyBase необходимо выбрать параметр PolyBase.
- Тип отклонения: укажите, является литеральным значением или процентом отклонить значение. Допустимые значения: Значение (по умолчанию) и Процент.
- Отклонить значение: укажите число или процент строк, которые могут быть отклонены до сбоя запроса. Дополнительные сведения о параметрах отклонения PolyBase см. в подразделе "Аргументы" раздела CREATE EXTERNAL TABLE (Transact-SQL). Допустимые значения: 0 (по умолчанию), 1, 2 и. т. д.
- Отклонение примера значения: определяет количество строк, которые необходимо извлечь, прежде чем PolyBase пересчитывает процент отклоненных строк. Допустимые значения: 1, 2 и т. д. Если в качестве типа отклонения выбран процент , это свойство необходимо.
- Используйте тип по умолчанию: укажите, как обрабатывать отсутствующие значения в текстовых файлах с разделителями, когда PolyBase извлекает данные из текстового файла. Дополнительные сведения об этом свойстве см. в подразделе "Аргументы" раздела CREATE EXTERNAL FILE FORMAT (Transact-SQL). Допустимые значения выбраны (по умолчанию) или не выбраны.
Массовая вставка: используйте массовую вставку для вставки данных в место назначения массово.

- Блокировка таблицы массового вставки. Это позволяет повысить производительность копирования во время операции массового вставки в таблицу без индекса из нескольких клиентов. Дополнительные сведения см. в статьях BULK INSERT (Transact-SQL).
Upsert: укажите группу параметров для поведения записи, когда требуется переставить данные в место назначения.

Ключевые столбцы: выберите, какой столбец используется для определения того, соответствует ли строка из источника строке из назначения.
Блокировка таблицы массового вставки. Это позволяет повысить производительность копирования во время операции массового вставки в таблицу без индекса из нескольких клиентов. Дополнительные сведения см. в статьях BULK INSERT (Transact-SQL).
Скрипт предварительного копирования: укажите сценарий для действия копирования перед записью данных в целевую таблицу в каждом запуске. Это свойство можно использовать для очистки предварительно загруженных данных.
Время ожидания пакетной операции записи: укажите время ожидания завершения операции вставки пакета до истечения времени ожидания. Допустимое значение — интервал времени. Значение по умолчанию — "00:30:00" (30 минут).
Размер пакета записи: укажите количество строк для вставки в таблицу SQL на пакет. Допустимое значение: целое число (количество строк). По умолчанию эта служба динамически определяет соответствующий размер пакета в зависимости от размера строки.
Максимальное число одновременных подключений: укажите верхний предел одновременных подключений, установленных в хранилище данных во время выполнения действия. Указывайте значение только при необходимости ограничить количество одновременных подключений.
Отключить аналитику метрик производительности: этот параметр используется для сбора метрик, таких как DTU, DWU, RU и т. д., для оптимизации производительности копирования и рекомендаций. Если вы обеспокоены этим поведением, выберите этот проверка box. По умолчанию он не выбирается.
Прямая копия с помощью команды COPY
Команда Azure Synapse Analytics COPY напрямую поддерживает Хранилище BLOB-объектов Azure и Azure Data Lake Storage 2-го поколения в качестве исходных хранилищ данных. Если исходные данные соответствуют критериям, описанным в этом разделе, используйте команду COPY для копирования непосредственно из исходного хранилища данных в Azure Synapse Analytics.
Исходные данные и формат содержат следующие типы и методы проверки подлинности:
Поддерживаемый тип хранилища исходных данных Поддерживаемый формат Поддерживаемый тип проверки подлинности источника Хранилище BLOB-объектов Azure Текст с разделителями
Parquetанонимная аутентификация;
Проверка подлинности на основе ключа учетной записи
Аутентификация SASAzure Data Lake Storage 2-го поколения Текст с разделителями
ParquetПроверка подлинности на основе ключа учетной записи
Аутентификация SASМожно задать следующие параметры формата:
- Для Parquet: тип сжатия может быть None, snappy или gzip.
- Для разделителя:
- Разделитель строк: при копировании текста с разделителями в Azure Synapse Analytics с помощью прямой команды COPY явно укажите разделитель строк (\r; \n; или \r\n). Только если разделитель строк исходного файла равен \r\n, значение по умолчанию (\r, \n или \r\n). В противном случае включите промежуточное хранение для вашего сценария.
- Значение NULL остается в качестве значения по умолчанию или имеет значение пустой строки ("").
- Кодировка остается по умолчанию или имеет значение UTF-8 или UTF-16.
- Число строк пропускается по умолчанию или имеет значение 0.
- Тип сжатия может быть None или gzip.
Если источник является папкой, необходимо выбрать рекурсивно проверка box.
Время начала (UTC) и время окончания (UTC) в фильтре по последнему изменению, префиксу, включению обнаружения секций и дополнительным столбцам не указаны.
Сведения о приеме данных в Azure Synapse Analytics с помощью команды COPY см. в этой статье.
Если исходное хранилище данных и формат не поддерживаются командой COPY, используйте поэтапное копирование с помощью функции команды COPY. Он автоматически преобразует данные в формат, совместимый с командой COPY, а затем вызывает команду COPY для загрузки данных в Azure Synapse Analytics.
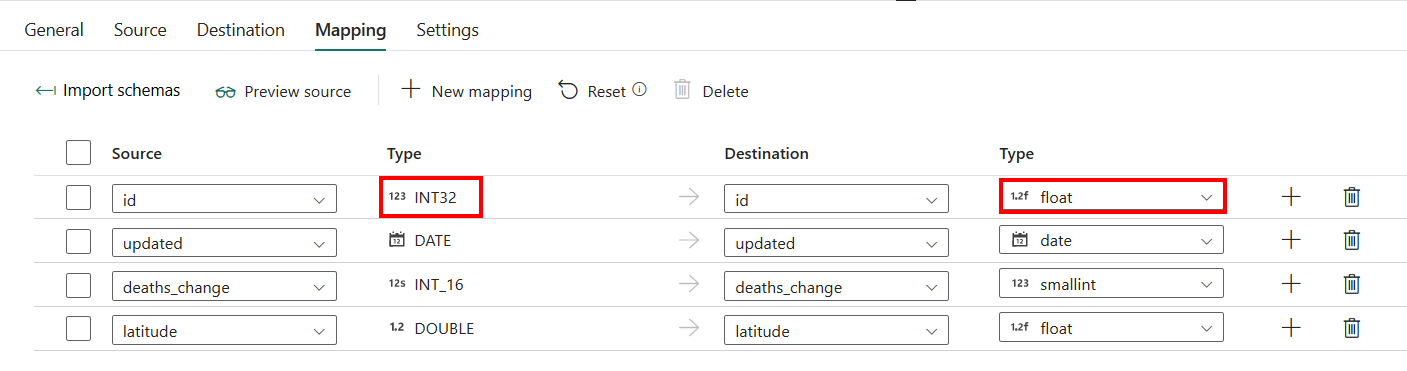
Сопоставление
Если вы не применяете Azure Synapse Analytics с автоматическим созданием таблицы в качестве назначения, перейдите в раздел "Сопоставление".
Если вы применяете Azure Synapse Analytics с автоматическим созданием таблицы в качестве назначения, за исключением конфигурации в сопоставлении, можно изменить тип для столбцов назначения. После выбора схемы импорта можно указать тип столбца в назначении.
Например, тип столбца идентификатора в источнике является int, и его можно изменить на float type при сопоставлении с целевым столбцом.
Настройки
Для настройки вкладки Параметры перейдите к разделу "Настройка других параметров" на вкладке "Параметры".
Параллельное копирование из Azure Synapse Analytics
Соединитель Azure Synapse Analytics в действии копирования обеспечивает встроенное секционирование данных для параллельного копирования данных. Параметры секционирования данных можно найти на вкладке Источник действия Copy.
Если включено копирование с секционированием, то выполнение действия копирования отправляет параллельные запросы к источнику Azure Synapse Analytics для загрузки данных по секциям. Параллельная степень управляется степенью параллелизма копирования на вкладке параметров действия копирования. Например, если задать степень параллелизма копирования четыре, служба одновременно создает и выполняет четыре запроса на основе указанного параметра секции и параметров, а каждый запрос получает часть данных из Azure Synapse Analytics.
Рекомендуется включить параллельное копирование с секционированием данных, особенно при загрузке большого объема данных из Azure Synapse Analytics. Ниже приведены рекомендуемые конфигурации для разных сценариев. Если данные копируются в файловое хранилище данных, то рекомендуется сохранять данные в папку несколькими файлами (указывая только имя папки), так как производительность в таком случае будет выше, чем при записи в один файл.
| Сценарий | Предлагаемые параметры |
|---|---|
| Полная загрузка из большой таблицы с физическими секциями. | Параметр секционирования. Физические секции таблицы. Во время выполнения служба автоматически определяет физические секции и копирует данные по секциям. Чтобы проверить, имеет ли таблица физическую секцию, выполните следующий запрос. |
| Полная загрузка из большой таблицы без физических секций, когда таблица содержит столбец целочисленного типа или типа даты и времени для секционирования данных. | Параметры секции: секция динамического диапазона. Столбец секционирования (необязательно). Укажите столбец для секционирования данных. Если значение не указано, то используется столбец с индексом или первичным ключом. Верхняя граница секционирования и Нижняя граница секционирования (необязательно). Указывайте, если необходимо определить шаг секционирования. Эти значения не предназначены для фильтрации строк в таблице. Все строки в таблице будут секционированы и скопированы. Если это не указано, действие копирования автоматически обнаруживает значения. К примеру, если ваш столбец раздела "Идентификатор" имеет диапазон значений от 1 до 100 и вы установили нижнюю границу как 20, а верхнюю границу как 80 с параллельным копированием как 4, служба извлекает данные по 4 разделам — идентификаторы в диапазоне <=20, [21, 50], [51, 80] и >=81 соответственно. |
| Загрузка большого объема данных пользовательским запросом без использования физических секций, однако с использованием столбца целочисленного типа или типа даты/даты и времени для секционирования данных. | Параметры секции: секция динамического диапазона. Запрос: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Столбец секционирования: укажите столбец, используемый для секционирования данных. Верхняя граница секционирования и Нижняя граница секционирования (необязательно). Указывайте, если необходимо определить шаг секционирования. Эти значения не предназначены для фильтрации строк в таблице. Все строки в результатах запроса будут секционированы и скопированы. Если значение не указано, действие копирования автоматически определяет значение. К примеру, если ваш столбец раздела "Идентификатор" имеет диапазон значений от 1 до 100, и вы установили нижнюю границу как 20, а верхнюю границу как 80, с параллельным копированием как 4, служба извлекает данные по 4 разделам — идентификаторы в диапазоне <=20, [21, 50], [51, 80] и >=81 соответственно. Ниже приведены дополнительные примеры запросов для различных сценариев. • Запросите всю таблицу: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Запрос из таблицы с выделенным столбцом и дополнительными фильтрами предложения where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Запрос с вложенными запросами: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Запрос с секцией в вложенных запросах: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Ниже приведены рекомендации по загрузке данных с параметром секционирования.
- Чтобы избежать неравномерного распределения данных, выбирайте в качестве столбца секционирования отличительный столбец (например, первичный ключ или уникальный ключ).
- Если в таблице есть встроенные секции, используйте параметр "Физические секции таблицы " для повышения производительности.
- Azure Synapse Analytics может выполнять не более 32 запросов в данный момент, установка слишком большого уровня параллелизма копирования может привести к проблеме регулирования Synapse.
Пример запроса для проверки физической секции
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Если таблица содержит физическую секцию, то параметр "Имеет секции" будет иметь значение "Да", как показано ниже.
Сводка таблицы
В следующих таблицах содержатся дополнительные сведения о действии копирования в Azure Synapse Analytics.
Исходный код
| Имя | Описание | Значение | Обязательное поле | Свойство скрипта JSON |
|---|---|---|---|---|
| Тип хранилища данных | Тип хранилища данных. | Внешний | Да | / |
| Соединение | Подключение к исходному хранилищу данных. | < подключение > | Да | подключение |
| Тип подключения | Тип исходного подключения. | Azure Synapse Analytics | Да | / |
| Использование запроса | Способ чтения данных. | •Таблице •Запроса • Хранимая процедура |
Да | • typeProperties (under typeProperties ->source)-Схемы -Таблице • sqlReaderQuery • sqlReaderStoredProcedureName storedProcedureParameters -Имя -Значение |
| Время ожидания запроса | Время ожидания выполнения команды запроса по умолчанию — 120 минут. | timespan | No | queryTimeout |
| Уровень изоляции | Поведение блокировки транзакций для источника SQL. | •Ни один • Чтение зафиксировано • Чтение незафиксированного • Повторяемое чтение •Сериализуемый •Снимок |
No | isolationLevel: • ReadCommitted • ReadUncommitted • RepeatableRead •Сериализуемый •Снимок |
| Параметр секции | Параметры секционирования данных, используемые для загрузки данных из База данных SQL Azure. | •Ни один • Физические секции таблицы • Динамический диапазон — имя столбца секционирования — верхняя граница секции — нижняя граница секции |
No | partitionOption: • PhysicalPartitionsOfTable • DynamicRange partition Параметры: — partitionColumnName — partitionUpperBound — partitionLowerBound |
| Дополнительные столбцы | Добавьте дополнительные столбцы данных для хранения относительного пути или статического значения исходных файлов. Выражение поддерживается для последнего. | • Имя •Значение |
No | additionalColumns: •Имя •Значение |
Назначение
| Имя | Описание | Значение | Обязательное поле | Свойство скрипта JSON |
|---|---|---|---|---|
| Тип хранилища данных | Тип хранилища данных. | Внешний | Да | / |
| Соединение | Подключение к целевому хранилищу данных. | < подключение > | Да | подключение |
| Тип подключения | Тип подключения назначения. | Azure Synapse Analytics | Да | / |
| Параметр таблицы | Параметр целевой таблицы данных. | • Использование существующих • Автоматическая создание таблицы |
Да | • typeProperties (under typeProperties ->sink)-Схемы -Таблице • tableOption: — autoCreate typeProperties (under typeProperties ->sink)-Схемы -Таблице |
| Метод copy | Метод, используемый для копирования данных. | • Копировать команду • PolyBase • Массовая вставка • Upsert |
No | / |
| При выборе команды "Копировать" | Используйте инструкцию COPY для загрузки данных из хранилища Azure в Azure Synapse Analytics или пул SQL. | / | № Применяется при использовании инструкции COPY. |
allowCopyCommand: true copyCommandSettings |
| Значения по умолчанию | Укажите значения по умолчанию для каждого целевого столбца в Azure Synapse Analytics. Значения по умолчанию из этого свойства переопределяют ограничение DEFAULT, заданное в хранилище данных, а столбец идентификаторов не может иметь значение по умолчанию. | < значения по умолчанию > | No | defaultValues: — columnName -Defaultvalue |
| Дополнительные параметры | Дополнительные параметры, которые будут переданы в Azure Synapse Analytics непосредственно в предложении WITH инструкции COPY. Значение необходимо заключать в кавычки для соответствия требованиям инструкции COPY. | < дополнительные параметры > | No | additionalOptions: - <имя> свойства: <значение> |
| При выборе PolyBase | PolyBase — это механизм высокой пропускной способности. Используйте его для загрузки больших объемов данных в Azure Synapse Analytics или пул SQL. | / | № Применяется при использовании PolyBase. |
allowPolyBase: true polyBaseSettings |
| Тип отклонения | Тип значения отклонения. | •Значение •Процент |
No | rejectType: -Значение -Процент |
| Отклонение значения | Число или процент строк, которые могут быть отклонены до сбоя запроса. | 0 (по умолчанию), 1, 2 и т. д. | No | rejectValue |
| Отклонение примера значения | Определяет количество строк, которое PolyBase следует получить до повторного вычисления процента отклоненных строк. | 1, 2 и т. д. | Да, если вы указываете процент в качестве типа отклонения | rejectSampleValue |
| Использование типа по умолчанию | Укажите способ обработки отсутствующих значений в текстовых файлах с разделителями, когда PolyBase извлекает данные из текстового файла. Дополнительные сведения об этом свойстве см. в разделе "Аргументы" в разделе CREATE EXTERNAL FILE FORMAT (Transact-SQL) | выбрано (по умолчанию) или не выбрано. | No | useTypeDefault: true (по умолчанию) или false |
| При выборе массового вставки | Вставка данных в место назначения в массовом режиме. | / | No | writeBehavior: Insert |
| Блокировка таблицы массового вставки | Это позволяет повысить производительность копирования во время операции массового вставки в таблицу без индекса из нескольких клиентов. Дополнительные сведения см. в статьях BULK INSERT (Transact-SQL). | выбран или не выбран (по умолчанию) | No | sqlWriterUseTableLock: true или false (по умолчанию) |
| При выборе Upsert | Укажите группу параметров для поведения записи, если требуется обновить данные в место назначения. | / | No | writeBehavior: Upsert |
| Ключевые столбцы | Указывает, какой столбец используется для определения того, соответствует ли строка из источника строке из назначения. | < Имя столбца> | No | upsert Параметры: — ключи: < имя столбца > — interimSchemaName |
| Блокировка таблицы массового вставки | Это позволяет повысить производительность копирования во время операции массового вставки в таблицу без индекса из нескольких клиентов. Дополнительные сведения см. в статьях BULK INSERT (Transact-SQL). | выбран или не выбран (по умолчанию) | No | sqlWriterUseTableLock: true или false (по умолчанию) |
| Скрипт предварительного копирования | Скрипт действия копирования для выполнения перед записью данных в целевую таблицу в каждом запуске. Это свойство можно использовать для очистки предварительно загруженных данных. | < скрипт предварительного копирования > (строка) |
No | preCopyScript |
| Время ожидания пакетной службы | Время ожидания до выполнения операции пакетной вставки, пока не истечет срок ее действия. Разрешенным значением является временной диапазон. Значение по умолчанию — "00:30:00" (30 минут). | timespan | No | writeBatchTimeout |
| Размер пакета записи | Количество строк для вставки в таблицу SQL на пакет. По умолчанию эта служба динамически определяет соответствующий размер пакета в зависимости от размера строки. | < количество строк > (целое число) |
No | writeBatchSize |
| Максимальное число одновременных подключений | Верхний предел одновременных подключений, установленных для хранилища данных при выполнении действия. Указывайте значение только при необходимости ограничить количество одновременных подключений. | < верхний предел одновременных подключений > (целое число) |
No | maxConcurrentConnections |
| Отключение аналитики метрик производительности | Этот параметр используется для сбора метрик, таких как DTU, DWU, RU и т. д., для оптимизации производительности копирования и рекомендаций. Если вы обеспокоены этим поведением, выберите этот проверка box. | выбор или отмена выбора (по умолчанию) | No | disableMetricsCollection: true или false (по умолчанию) |