Настройка и использование потока данных
С помощью потоков данных можно объединить данные из нескольких источников и подготовить эти унифицированные данные для моделирования. При создании потока данных вам будет предложено обновить данные для потока данных. Обновление потока данных необходимо, прежде чем его можно будет использовать в семантической модели в Power BI Desktop, или ссылаться на нее как связанную или вычисляемую таблицу.
Примечание.
Потоки данных могут быть недоступны в служба Power BI для всех клиентов DoD для государственных организаций США. Дополнительные сведения о доступных функциях и которые не доступны, см. в статье о доступности функций Power BI для клиентов государственных организаций США.
Настройка потока данных
Чтобы настроить обновление потока данных, выберите дополнительные параметры (многоточие) и выберите Параметры.
Параметры Параметры предоставляют множество вариантов потока данных, как описано в следующих разделах.
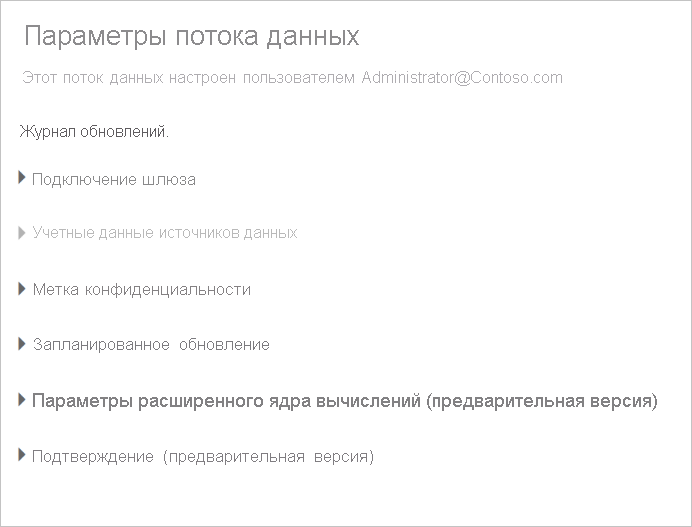
Взять на себя ответственность: если вы не являетесь владельцем потока данных, многие из этих параметров отключены. Чтобы взять на себя ответственность за поток данных, выберите "Взять на себя" , чтобы взять под контроль. Вам будет предложено предоставить учетные данные, чтобы обеспечить необходимый уровень доступа.
Шлюз Подключение. В этом разделе можно выбрать, использует ли поток данных шлюз и выбрать используемый шлюз. Если шлюз указан в процессе редактирования потока данных, возможно, потребуется обновить учетные данные с помощью параметра редактирования потока данных.
Учетные данные источника данных. В этом разделе вы выбираете используемые учетные данные и можете изменить способ проверки подлинности в источнике данных.
Метка конфиденциальности: здесь можно определить чувствительность данных в потоке данных. Дополнительные сведения о метках конфиденциальности см. в статье "Применение меток конфиденциальности" в Power BI.
Запланированное обновление: здесь можно определить время суток, когда выбранные обновления потока данных обновляются. Поток данных можно обновить с той же частотой, что и семантическая модель.
Расширенные параметры вычислительной подсистемы. Здесь можно определить, хранится ли поток данных в вычислительном ядре. Подсистема вычислений позволяет последующим потокам данных, ссылающихся на этот поток данных, выполнять слияния и соединения и другие преобразования быстрее, чем в противном случае. Он также позволяет выполнять DirectQuery по потоку данных. При выборе "Вкл." поток данных всегда поддерживается в режиме DirectQuery, а все ссылки получают преимущества от подсистемы. Выбор оптимизированного означает, что обработчик используется только в том случае, если есть ссылка на этот поток данных. При нажатии кнопки "Отключить" подсистема вычислений и возможность DirectQuery для этого потока данных отключены.
Подтверждение. Вы можете определить, сертифицирован или повышен поток данных.
Примечание.
Пользователи с лицензией Pro или PPU категории "Премиум" могут создавать поток данных в рабочей области Premium.
Внимание
Если рабочая область удаляется, содержащая потоки данных, все потоки данных в этой рабочей области также удаляются. Даже если восстановление рабочей области возможно, вы не можете восстановить удаленные потоки данных напрямую или через поддержку корпорации Майкрософт.
Обновление потока данных
Потоки данных действуют как стандартные блоки поверх друг друга. Предположим, что у вас есть поток данных с именем "Необработанные данные" и связанная таблица с именем "Преобразованные данные", которая содержит связанную таблицу с потоком необработанных данных. При обновлении расписания для триггеров потока данных необработанных данных он активирует любой поток данных, ссылающийся на него после завершения. Эта функция создает эффект цепочки обновлений, что позволяет избежать необходимости планировать потоки данных вручную. При работе с связанными таблицами обновляется несколько нюансов:
Связанная таблица будет активирована обновлением только в том случае, если она существует в той же рабочей области.
Связанная таблица будет заблокирована для редактирования при обновлении исходной таблицы или отмене обновления исходной таблицы. Если какой-либо из потоков данных в эталонной цепочке не удалось обновить, все потоки данных откатятся к старым данным (обновления потока данных являются транзакциями в рабочей области).
При активации завершения обновления источника обновляются только те таблицы, на которые ссылается ссылка. Чтобы запланировать все таблицы, необходимо также задать расписание обновления связанной таблицы. Избегайте настройки расписания обновления для связанных потоков данных, чтобы избежать двойного обновления.
Отмена потоков данных обновления поддерживает возможность отмены обновления , в отличие от семантических моделей. Если обновление выполняется в течение длительного времени, можно выбрать дополнительные параметры (многоточие рядом с потоком данных), а затем нажмите кнопку "Отмена обновления".
Потоки данных добавочного обновления (только "Премиум") можно также задать для обновления добавочно. Для этого выберите поток данных, который вы хотите настроить для добавочного обновления, а затем щелкните значок добавочного обновления .

Параметр добавочного обновления добавляет параметры в поток данных, чтобы указать диапазон дат. Подробные сведения о настройке добавочного обновления см. в разделе "Использование добавочного обновления с потоками данных".
Существуют некоторые обстоятельства, при которых не следует задавать добавочное обновление:
Связанные таблицы не должны использовать добавочное обновление, если они ссылаются на поток данных. Потоки данных не поддерживают свертку запросов (даже если таблица включена DirectQuery).
Семантические модели, ссылающиеся на потоки данных, не должны использовать добавочное обновление. Обновления потоков данных обычно выполняются, поэтому добавочные обновления не должны быть обязательными. Если обновление занимает слишком много времени, рассмотрите возможность использования подсистемы вычислений или режима DirectQuery.
Использование потока данных
Поток данных можно использовать следующими способами:
Создайте связанную таблицу из потока данных, чтобы разрешить другому автору потока данных использовать данные.
Создайте семантику модели из потока данных, чтобы пользователь могли использовать данные для создания отчетов.
Создайте подключение из внешних средств, которые могут считываться из формата CDM (Common Data Model).
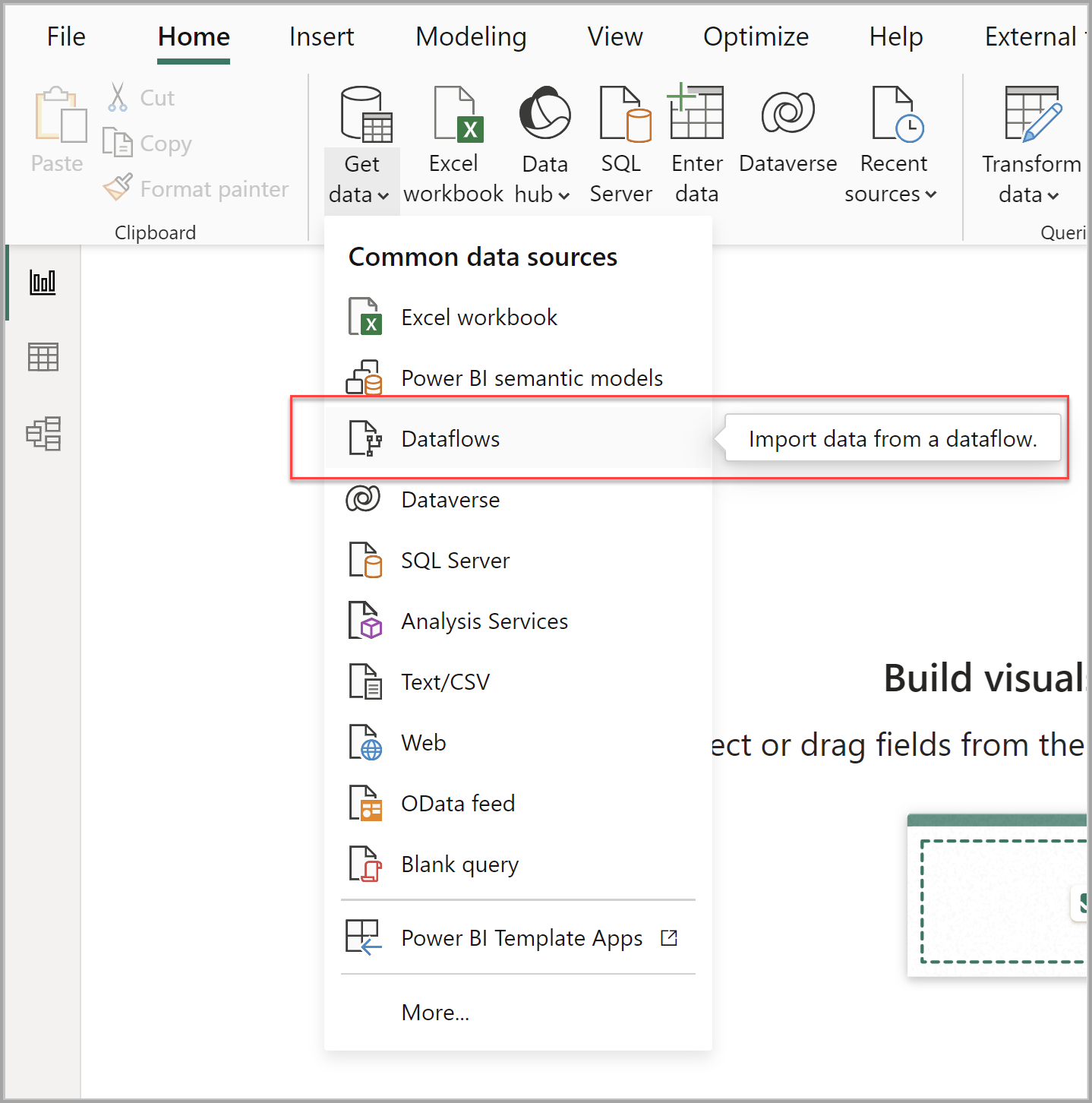
Использование из Power BI Desktop для использования потока данных, откройте Power BI Desktop и выберите потоки данных в раскрывающемся списке "Получить данные ".
Примечание.
Соединитель потоков данных использует другой набор учетных данных, отличный от текущего пользователя, вошедшего в систему. Это связано с поддержкой пользователей с несколькими клиентами.
Выберите поток данных и таблицы, к которым требуется подключиться.
Примечание.
Вы можете подключиться к любому потоку данных или таблице независимо от того, в какой рабочей области она находится, и независимо от того, была ли она определена в рабочей области "Премиум" или "Премиум".
Если directQuery доступен, вам будет предложено выбрать, нужно ли подключаться к таблицам с помощью DirectQuery или Import.
В режиме DirectQuery можно быстро просить крупномасштабные семантические модели локально. Однако больше не удается выполнить преобразования.
Использование импорта приводит данные в Power BI и требует обновления семантической модели независимо от потока данных.
Связанный контент
Дополнительные сведения о потоках данных и Power BI см. в следующих статьях.
- Введение в потоки данных и самостоятельную подготовку данных
- Создание потока данных
- Настройка хранилища потока данных для использования Azure Data Lake 2-го поколения
- Функции потоков данных уровня "Премиум"
- ИИ с потоками данных
- Рекомендации и ограничения, касающиеся потоков данных
- Рекомендации по потокам данных