ИИ с потоками данных
В этой статье показано, как использовать искусственный интеллект (ИИ) с потоками данных. В этой статье рассматриваются следующие вопросы:
- Службы Cognitive Services
- Автоматизированное машинное обучение
- Интеграция машинного обучения Azure
Внимание
Создание моделей автоматической Машинное обучение (AutoML) Power BI для потоков данных версии 1 прекращено и больше недоступно. Клиентам рекомендуется перенести решение в функцию AutoML в Microsoft Fabric. Дополнительные сведения см . в объявлении о выходе на пенсию.
Cognitive Services в Power BI
С помощью Cognitive Services в Power BI можно применять различные алгоритмы, отличные от Azure Cognitive Services , чтобы обогатить данные в подготовке данных самообслуживания для потоков данных.
Службы, поддерживаемые сегодня, — это анализ тональности, извлечение ключевых фраз, обнаружение языка и теги изображений. Преобразования выполняются в служба Power BI и не требуют подписки Azure Cognitive Services. Для этой функции требуется Power BI Premium.
Включение функций ИИ
Когнитивные службы поддерживаются для узлов емкости Premium EM2, A2, P1 или F64 и других узлов с дополнительными ресурсами. Службы Cognitive Services также доступны с лицензией Premium на пользователя (PPU). Отдельная рабочая нагрузка искусственного интеллекта в емкости используется для запуска когнитивных служб. Прежде чем использовать когнитивные службы в Power BI, рабочая нагрузка ИИ должна быть включена в параметрах емкости портала администрирования. Вы можете включить рабочую нагрузку ИИ в разделе рабочих нагрузок.
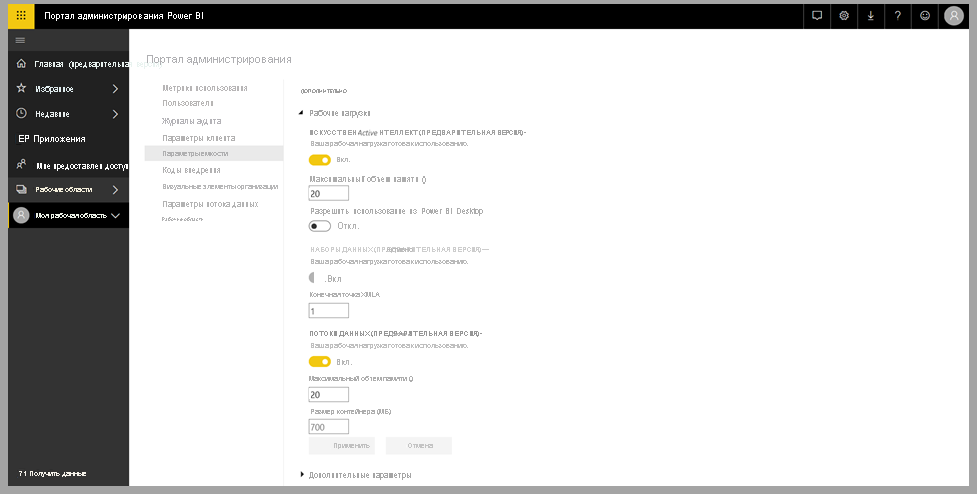
Начало работы с Cognitive Services в Power BI
Преобразования Cognitive Services являются частью самостоятельной подготовки данных для потоков данных. Чтобы обогатить данные с помощью Cognitive Services, начните с редактирования потока данных.

Нажмите кнопку Аналитика ИИ на верхней ленте Редактор Power Query.

Во всплывающем окне выберите функцию, которую вы хотите использовать, и данные, которые необходимо преобразовать. В этом примере оценивается тональность столбца, содержащего текст проверки.
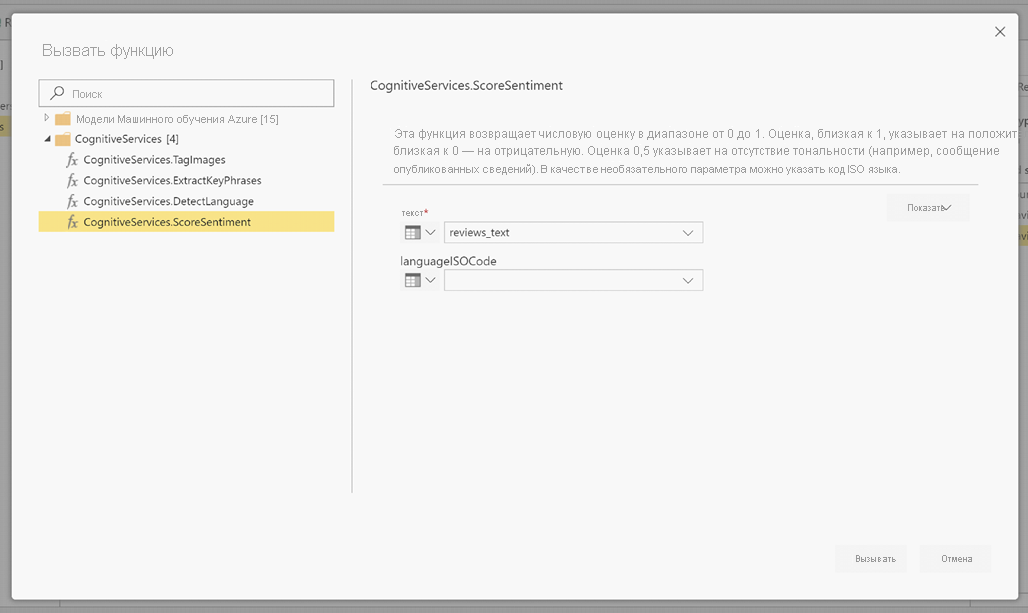
LanguageISOCode — это необязательный вход для указания языка текста. В этом столбце ожидается iso-код. Столбец можно использовать в качестве входных данных для LanguageISOCode или использовать статический столбец. В этом примере язык указывается как английский (en) для всего столбца. Если этот столбец не задан, Power BI автоматически обнаруживает язык перед применением функции. Затем нажмите кнопку "Вызвать".
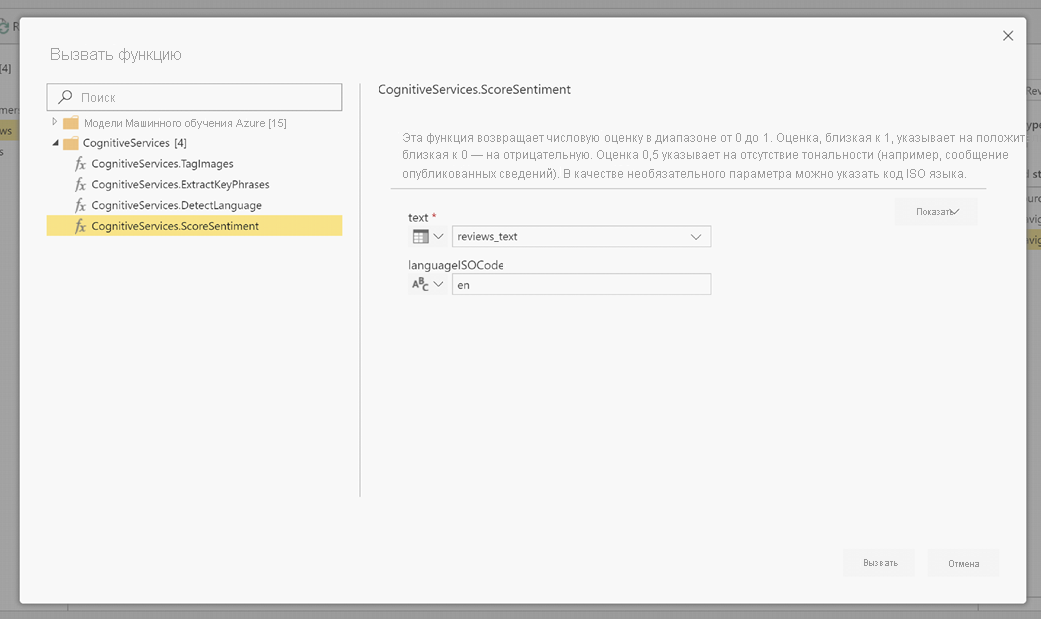
После вызова функции результат добавляется в таблицу в виде нового столбца. Преобразование также добавляется в качестве примененного шага в запросе.

Если функция возвращает несколько выходных столбцов, вызов функции добавляет новый столбец со строкой нескольких выходных столбцов.
Используйте параметр развертывания для добавления одного или обоих значений в качестве столбцов в данные.

Доступные функции
В этом разделе описываются доступные функции в Cognitive Services в Power BI.
Распознавание языка
Функция обнаружения языка оценивает текстовые входные данные, а для каждого столбца возвращает имя языка и идентификатор ISO. Эта функция полезна для столбцов данных, которые собирают произвольный текст, где язык неизвестен. Функция ожидает данные в текстовом формате в качестве входных данных.
Анализ текста распознает до 120 языков. Дополнительные сведения см. в статье "Что такое обнаружение языка в Службе Cognitive Service Azure для языка".
Извлечение ключевых фраз
Функция извлечения ключевых фраз оценивает неструктурированный текст, а для каждого текстового столбца возвращает список ключевых фраз. Функция требует текстового столбца в качестве входных данных и принимает необязательные входные данные для LanguageISOCode. Дополнительные сведения см. в разделе " Начало работы".
Извлечение ключевых фраз лучше всего работает, когда вы даете больше фрагментов текста для работы, напротив анализа тональности. Анализ тональности лучше работает на небольших блоках текста. Для получения наилучших результатов обеих операций советуем реструктуризировать входные данные соответствующим образом.
Оценка тональности
Функция оценки тональности оценивает ввод текста и возвращает оценку тональности для каждого документа в диапазоне от 0 (отрицательное) до 1 (положительное). Эта функция полезна для выявления положительных и отрицательных тональности в социальных сетях, отзывах клиентов и обсуждениях форумов.
Анализ текста использует алгоритм классификации машинного обучения для создания оценки тональности от 0 до 1. Оценки ближе к 1 указывают положительные настроения. Оценки ближе к 0 указывают отрицательные тональности. Модель предварительно обучена обширным текстом с ассоциациями тональности. В настоящее время невозможно предоставить собственные обучающие данные. Модель использует сочетание техник во время анализа текста, включая обработку текста, анализа частей речи, размещения слов и связи между словами. Дополнительные сведения об алгоритме см. в Машинное обучение и Анализ текста.
Анализ тональности выполняется для всего входного столбца, а не для извлечения тональности для определенной таблицы в тексте. На практике имеется тенденция повышения оценки точности, когда документы содержат одно или два предложения, а не большой блок текста. Во время этапа оценки объективности модель определяет, является ли входной столбец цельным или содержит тональность. Входной столбец, который в основном не выполняется до фразы обнаружения тональности, что приводит к оценке 0,50 без дополнительной обработки. Для входных столбцов, продолжающихся в конвейере, следующий этап создает оценку больше или меньше 0,50 в зависимости от степени тональности, обнаруженной в входном столбце.
В настоящий момент анализ тональности поддерживает английский, немецкий, испанский и французский языки. Другие языки находятся на этапе предварительной версии. Дополнительные сведения см. в статье "Что такое обнаружение языка в Службе Cognitive Service Azure для языка".
Изображения тегов
Функция "Изображения тегов" возвращает теги на основе более чем 2000 узнаваемых объектов, живых существ, пейзажей и действий. Если теги неоднозначны или не являются общими знаниями, выходные данные предоставляют "подсказки", чтобы уточнить смысл тега в контексте известного параметра. Теги не организованы как таксономия, и иерархии наследования не существуют. Коллекция тегов содержимого формирует основу для "описания" изображения, отображаемого на понятном для пользователя языке и отформатированного в полные предложения.
После загрузки изображения или указав его URL-адрес, алгоритмы компьютерного зрения выводят теги, в зависимости от объектов, живых существ и действий, указанных на изображении. Добавление тегов не ограничивается основным предметом, например человеком на переднем плане, но также включает параметр (внутри помещения или снаружи), мебель, инструменты, растения, животных, аксессуары, гаджеты и т. д.
Для этой функции требуется URL-адрес изображения или столбец abase-64 в качестве входных данных. В настоящее время тег изображения поддерживает английский, испанский, японский, португальский и упрощенный китайский. Дополнительные сведения см. в разделе "Интерфейс ComputerVision".
Автоматизированное машинное обучение в Power BI
Автоматизированное машинное обучение (AutoML) для потоков данных позволяет бизнес-аналитикам обучать, проверять и вызывать модели машинного обучения непосредственно в Power BI. Он включает простой интерфейс для создания новой модели машинного обучения, в которой аналитики могут использовать их потоки данных для указания входных данных для обучения модели. Служба автоматически извлекает наиболее важные функции, выбирает соответствующий алгоритм и настраивает и проверяет модель машинного обучения. После обучения модели Power BI автоматически создает отчет о производительности, включающий результаты проверки. Затем модель можно вызвать для любых новых или обновленных данных в потоке данных.
Автоматизированное машинное обучение доступно только для потоков данных, размещенных в емкостях Power BI Premium и Embedded.
Работа с AutoML
Машинное обучение и ИИ видят беспрецедентный рост популярности в отраслях и научных исследовательских областях. Предприятия также ищут способы интеграции этих новых технологий в свои операции.
Потоки данных предлагают самостоятельную подготовку данных для больших данных. AutoML интегрирован в потоки данных и позволяет использовать усилия по подготовке данных для создания моделей машинного обучения прямо в Power BI.
AutoML в Power BI позволяет аналитикам данных использовать потоки данных для создания моделей машинного обучения с упрощенным интерфейсом с помощью только навыков Power BI. Power BI автоматизирует большую часть обработки и анализа данных за созданием моделей машинного обучения. Она имеет ограждения, чтобы обеспечить хорошее качество модели и обеспечивает видимость процесса, используемого для создания модели машинного обучения.
AutoML поддерживает создание двоичных моделей прогнозирования, классификации и регрессии для потоков данных. Эти функции являются типами защищенных методов машинного обучения, что означает, что они учатся на основе известных результатов прошлых наблюдений для прогнозирования результатов других наблюдений. Входная семантическая модель для обучения модели AutoML — это набор строк, помеченных известными результатами.
AutoML в Power BI интегрирует автоматизированное машинное обучение из Машинное обучение Azure для создания моделей машинного обучения. Однако для использования AutoML в Power BI не требуется подписка Azure. Служба Power BI полностью управляет процессом обучения и размещения моделей машинного обучения.
После обучения модели машинного обучения AutoML автоматически создает отчет Power BI, который объясняет высокую производительность модели машинного обучения. AutoML подчеркивает возможность объяснения, выделяя ключевые факторы влияния среди входных данных, влияющих на прогнозы, возвращаемые моделью. В отчете также содержатся ключевые метрики для модели.
На других страницах созданного отчета отображаются статистические сводки модели и сведения о обучении. Статистическая сводка интересна для пользователей, которые хотели бы видеть стандартные меры по обработке и анализу данных производительности модели. Сведения об обучении обобщают все итерации, выполняемые для создания модели, с соответствующими параметрами моделирования. В нем также описывается, как каждый вход использовался для создания модели машинного обучения.
Затем вы можете применить модель машинного обучения к данным для оценки. При обновлении потока данных данные обновляются с помощью прогнозов из модели машинного обучения. Power BI также включает в себя индивидуальное объяснение для каждого конкретного прогноза, которое создает модель машинного обучения.
Создание модели машинного обучения
В этом разделе описывается создание модели AutoML.
Подготовка данных для создания модели машинного обучения
Чтобы создать модель машинного обучения в Power BI, необходимо сначала создать поток данных для данных, содержащих исторические сведения о результатах, которые используются для обучения модели машинного обучения. Вы также должны добавить вычисляемые столбцы для любых бизнес-метрик, которые могут быть сильными прогнозаторами для результата, который вы пытаетесь предсказать. Дополнительные сведения о настройке потока данных см. в статье "Настройка и использование потока данных".
AutoML имеет определенные требования к данным для обучения модели машинного обучения. Эти требования описаны в следующих разделах на основе соответствующих типов моделей.
Настройка входных данных модели машинного обучения
Чтобы создать модель AutoML, выберите значок машинного обучения в столбце "Действия " таблицы потока данных и выберите " Добавить модель машинного обучения".
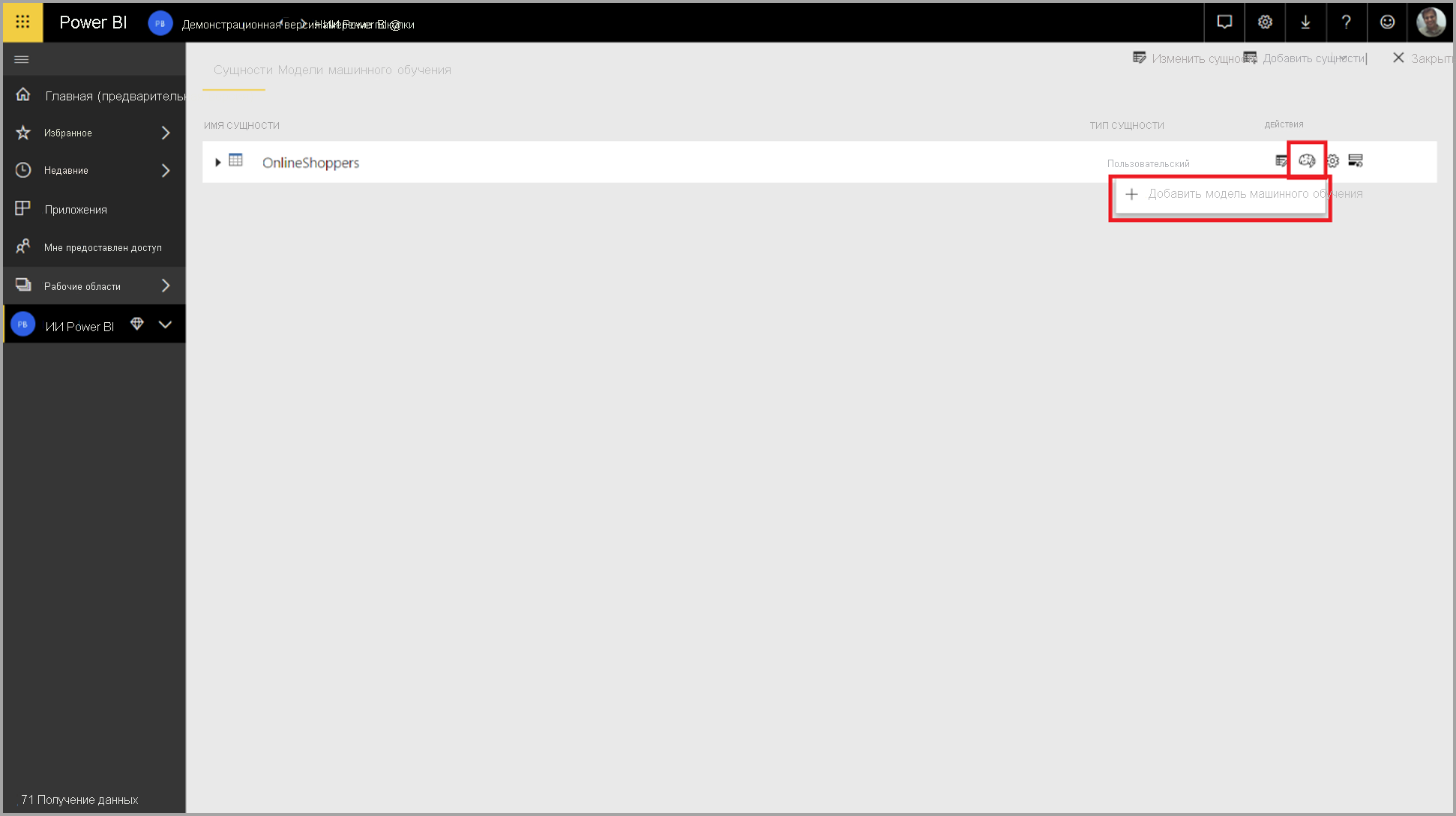
Упрощенный интерфейс запускается, состоящий из мастера, который поможет вам создать модель машинного обучения. Мастер включает следующие простые шаги.
1. Выберите таблицу с историческими данными и выберите столбец результатов, для которого требуется прогноз
Столбец результатов определяет атрибут метки для обучения модели машинного обучения, показанную на следующем рисунке.

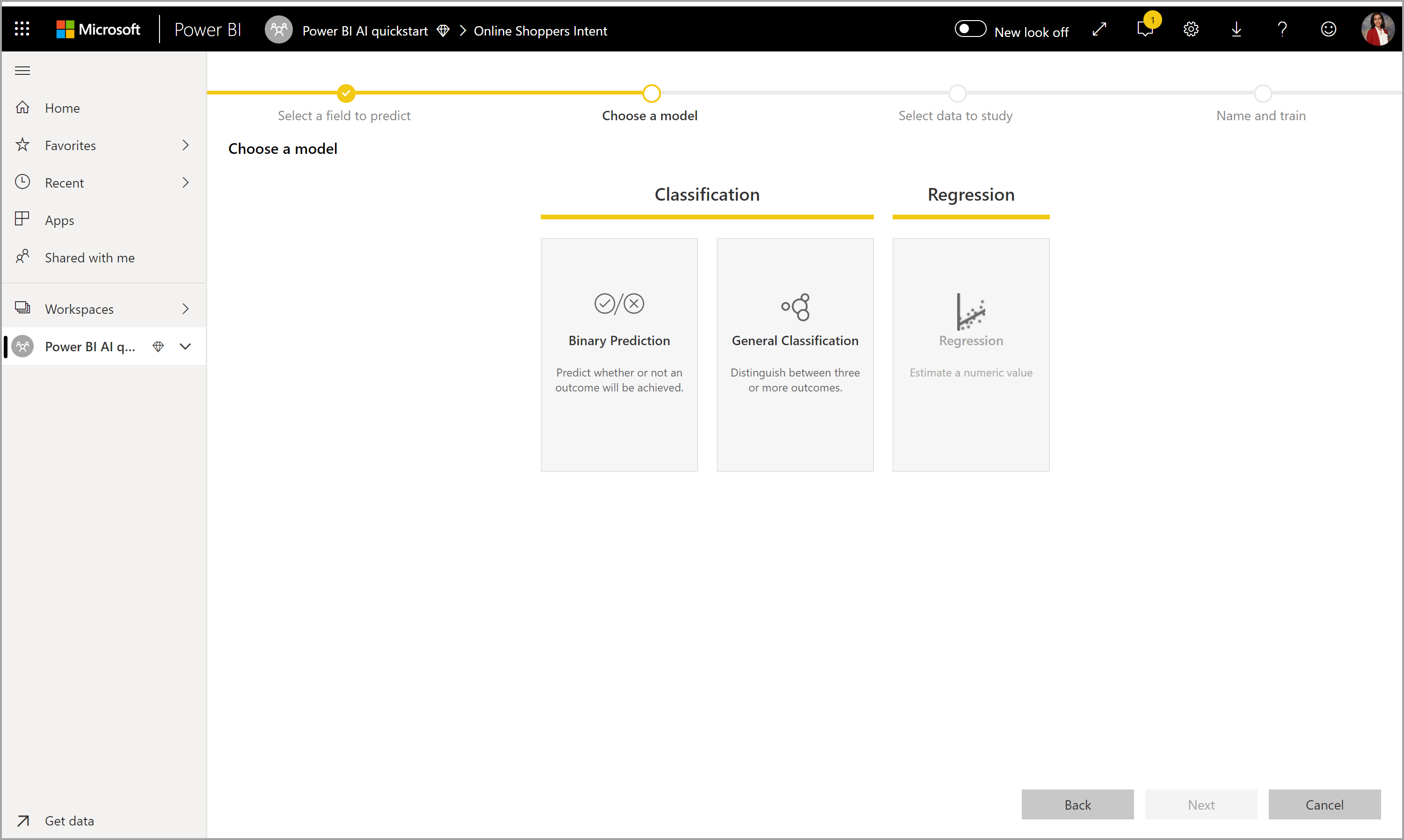
2. Выбор типа модели
При указании столбца результатов AutoML анализирует данные меток, чтобы рекомендовать наиболее вероятный тип модели машинного обучения, который можно обучить. Вы можете выбрать другой тип модели, как показано на следующем рисунке, щелкнув " Выбрать модель".
Примечание.
Некоторые типы моделей могут не поддерживаться для выбранных данных и поэтому они будут отключены. В предыдущем примере регрессия отключена, так как текстовый столбец выбран в качестве столбца результатов.
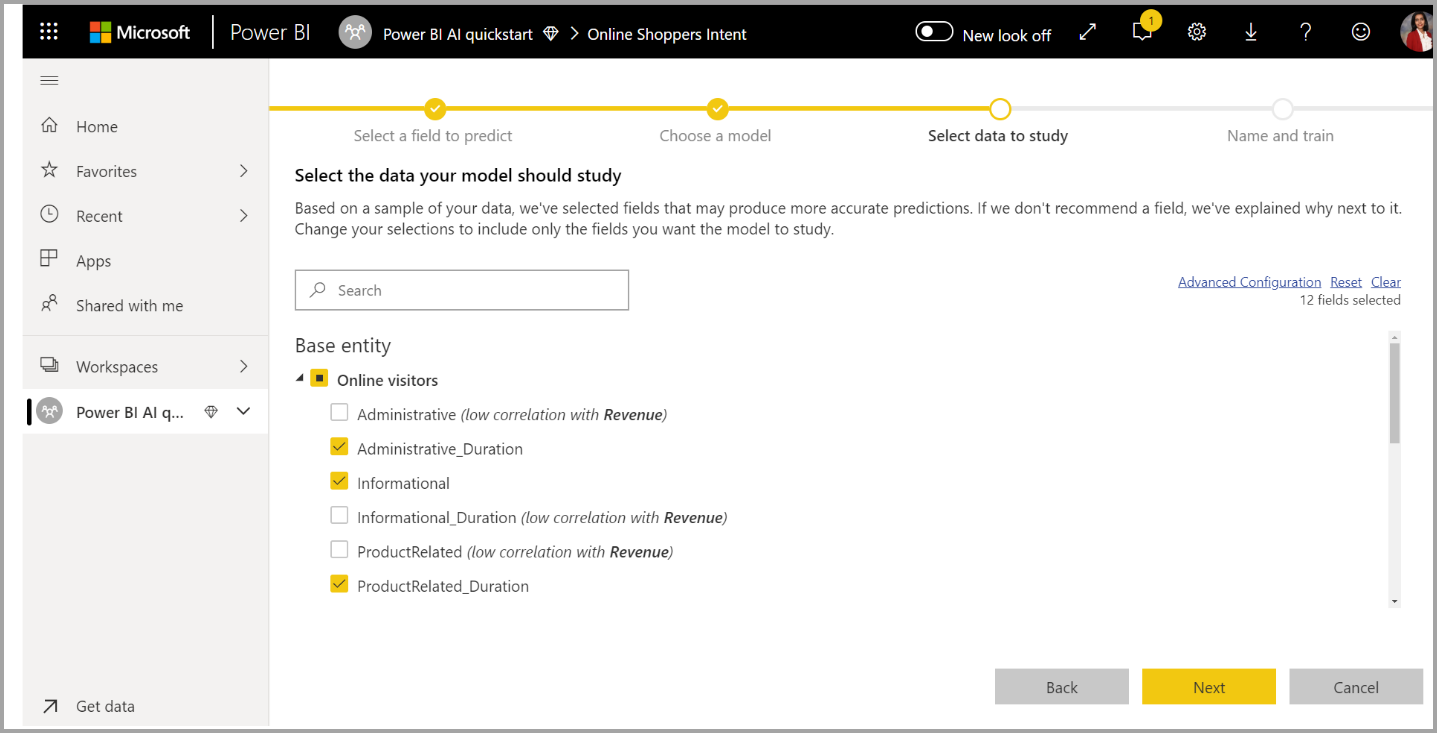
3. Выберите входные данные, которые требуется использовать в качестве прогнозных сигналов.
AutoML анализирует пример выбранной таблицы, чтобы предложить входные данные, которые можно использовать для обучения модели машинного обучения. Объяснения предоставляются рядом с столбцами, которые не выбраны. Если определенный столбец имеет слишком много уникальных значений или только одно значение, или низкая или высокая корреляция с выходным столбцом, не рекомендуется.
Любые входные данные, зависящие от столбца результатов (или столбца метки), не должны использоваться для обучения модели машинного обучения, так как они влияют на ее производительность. Такие столбцы помечены как "подозрительно высокая корреляция с выходным столбцом". Ввод этих столбцов в обучающие данные приводит к утечке меток, где модель хорошо работает над данными проверки или тестирования, но не может соответствовать этой производительности при использовании в рабочей среде для оценки. Утечка меток может быть возможной проблемой в моделях AutoML, когда производительность модели обучения слишком хороша, чтобы быть правдой.
Эта рекомендация по функциям основана на образце данных, поэтому следует просмотреть используемые входные данные. Вы можете изменить выбранные элементы, чтобы включить только столбцы, которые требуется изучать модель. Вы также можете выбрать все столбцы, установив флажок рядом с именем таблицы.
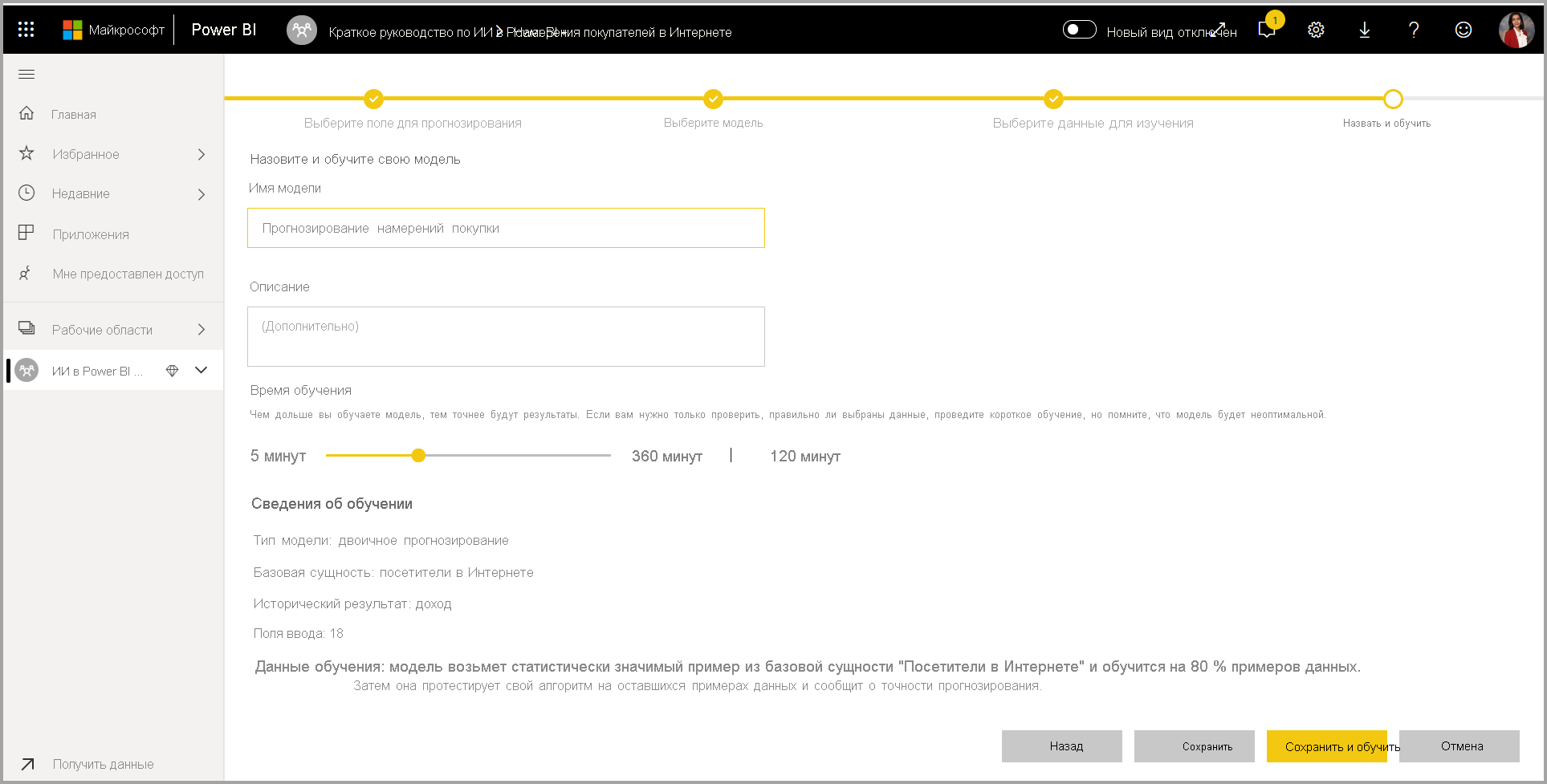
4. Присвойте модели имя и сохраните конфигурацию.
На последнем шаге можно назовите модель, нажмите кнопку "Сохранить" и выберите начало обучения модели машинного обучения. Вы можете сократить время обучения, чтобы увидеть быстрые результаты или увеличить время, затраченное на обучение, чтобы получить лучшую модель.
Обучение модели машинного обучения
Обучение моделей AutoML является частью обновления потока данных. AutoML сначала подготавливает данные для обучения. AutoML разделяет исторические данные, предоставляемые на обучающие и тестовые семантические модели. Тестовая семантическая модель — это набор удержаний, используемый для проверки производительности модели после обучения. Эти наборы реализуются как таблицы обучения и тестирования в потоке данных. AutoML использует перекрестную проверку для проверки модели.
Затем каждый входной столбец анализируется и применяется и применяется импютация, которая заменяет все отсутствующие значения замененными значениями. В AutoML используется несколько различных стратегий вменения. Для входных атрибутов, которые рассматриваются как числовые функции, среднее значение значений столбца используется для импютации. Для входных атрибутов, которые рассматриваются как категориальные признаки, AutoML использует режим значений столбцов для импютации. Платформа AutoML вычисляет среднее и режим значений, используемых для вложенной семантической модели обучения.
Затем выборка и нормализация применяются к данным по мере необходимости. Для моделей классификации AutoML выполняет входные данные с помощью стратифицированной выборки и балансирует классы, чтобы обеспечить равенство счетчиков строк для всех.
AutoML применяет несколько преобразований для каждого выбранного входного столбца на основе его типа данных и статистических свойств. AutoML использует эти преобразования для извлечения функций для обучения модели машинного обучения.
Учебный процесс для моделей AutoML состоит из до 50 итерации с различными алгоритмами моделирования и параметрами гиперпараметров для поиска модели с оптимальной производительностью. Обучение может завершиться рано с меньшими итерациями, если AutoML заметил, что не наблюдается улучшения производительности. AutoML оценивает производительность каждой из этих моделей, проверяя семантику тестовой проверки. На этом шаге обучения AutoML создает несколько конвейеров для обучения и проверки этих итераций. Процесс оценки производительности моделей может занять некоторое время в любом месте от нескольких минут до нескольких часов до времени обучения, настроенного в мастере. Время зависит от размера семантической модели и доступных ресурсов емкости.
В некоторых случаях последняя модель, созданная, может использовать обучение ансамбля, где для повышения прогнозной производительности используются несколько моделей.
Объясняемость модели AutoML
После обучения модели AutoML анализирует связь между входными функциями и выходными данными модели. Он оценивает величину изменения выходных данных модели для семантической модели тестирования удержания для каждой входной функции. Эта связь называется важностью функции. Этот анализ выполняется как часть обновления после завершения обучения. Поэтому обновление может занять больше времени обучения, настроенного в мастере.
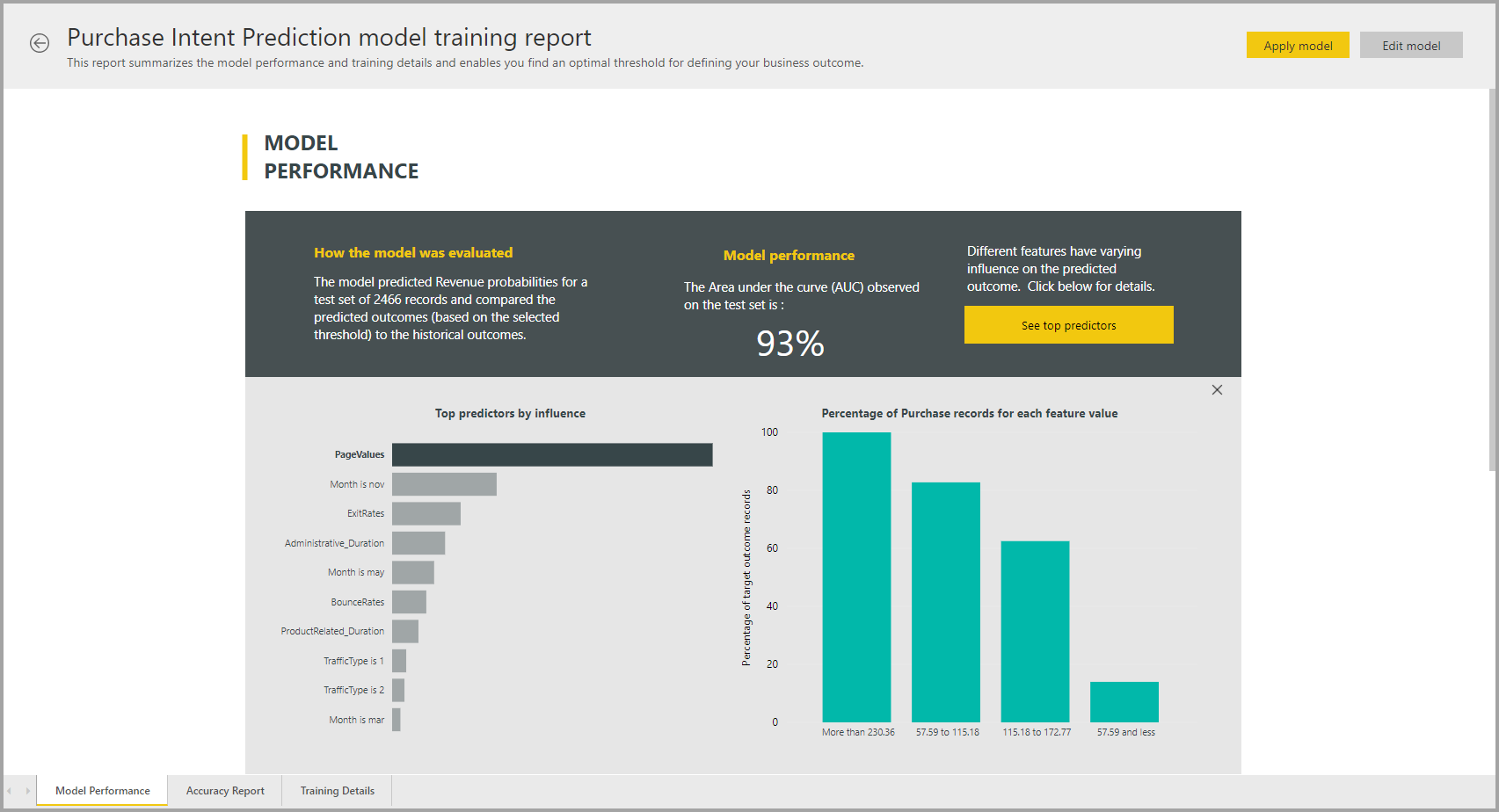
Отчет об модели AutoML
AutoML создает отчет Power BI, который суммирует производительность модели во время проверки, а также глобальную важность функций. Этот отчет можно получить на вкладке Машинное обучение Models после успешного обновления потока данных. В отчете перечислены результаты применения модели машинного обучения к данным тестовой проверки удержания и сравнения прогнозов с известными значениями результатов.
Вы можете просмотреть отчет модели, чтобы понять его производительность. Вы также можете проверить, соответствуют ли ключевые факторы влияния модели бизнес-аналитике по известным результатам.
Диаграммы и меры, используемые для описания производительности модели в отчете, зависят от типа модели. Эти диаграммы производительности и меры описаны в следующих разделах.
Другие страницы в отчете могут описывать статистические меры по модели с точки зрения обработки и анализа данных. Например, отчет о двоичном прогнозировании включает диаграмму получения и кривую ROC для модели.
Отчеты также включают страницу "Сведения об обучении", которая содержит описание обучения модели и диаграмму, описывающую производительность модели для каждого запуска итерации.
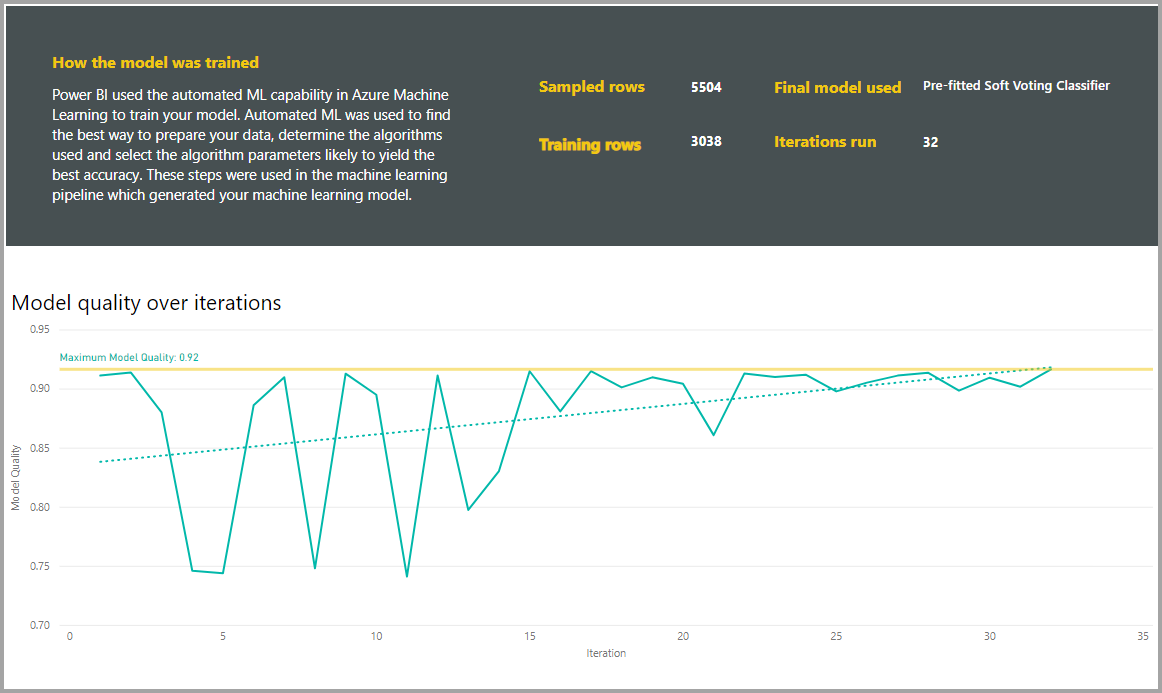
Другой раздел на этой странице описывает обнаруженный тип входного столбца и метода импютации, используемый для заполнения отсутствующих значений. Он также включает параметры, используемые конечной моделью.
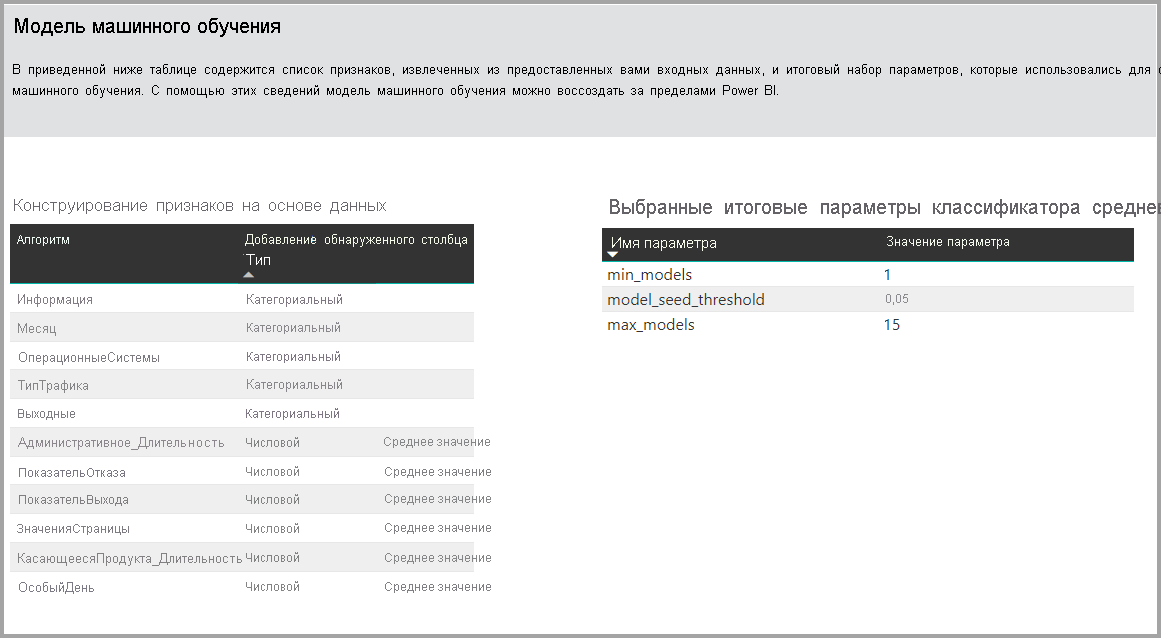
Если модель, созданная с использованием ансамбля обучения, страница "Сведения об обучении" также содержит диаграмму, показывающую вес каждой составной модели в ансамбле и ее параметрах.

Применение модели AutoML
Если вы удовлетворены производительностью созданной модели машинного обучения, ее можно применить к новым или обновленным данным при обновлении потока данных. В отчете модели нажмите кнопку "Применить" в правом верхнем углу или кнопку "Применить модель машинного обучения" на вкладке "Модели Машинное обучение".
Чтобы применить модель машинного обучения, необходимо указать имя таблицы, к которой она должна применяться, и префикс для столбцов, которые будут добавлены в эту таблицу для выходных данных модели. Префикс по умолчанию для имен столбцов — это имя модели. Функция Apply может включать дополнительные параметры, относящиеся к типу модели.
Применение модели машинного обучения создает две новые таблицы потока данных, содержащие прогнозы и отдельные объяснения для каждой строки, которую она оценивает в выходной таблице. Например, если вы применяете модель PurchaseIntent к таблице OnlineShoppers , выходные данные создают таблицы обогащенных PurchaseShoppers и OnlineShoppers с обогащенными таблицами объяснений PurchaseIntent. Для каждой строки в обогащенной таблице объяснение разбивается на несколько строк в таблице обогащенных объяснений на основе входной функции. ОписаниеIndex помогает сопоставить строки из обогащенной таблицы объяснений со строкой в обогащенной таблице.
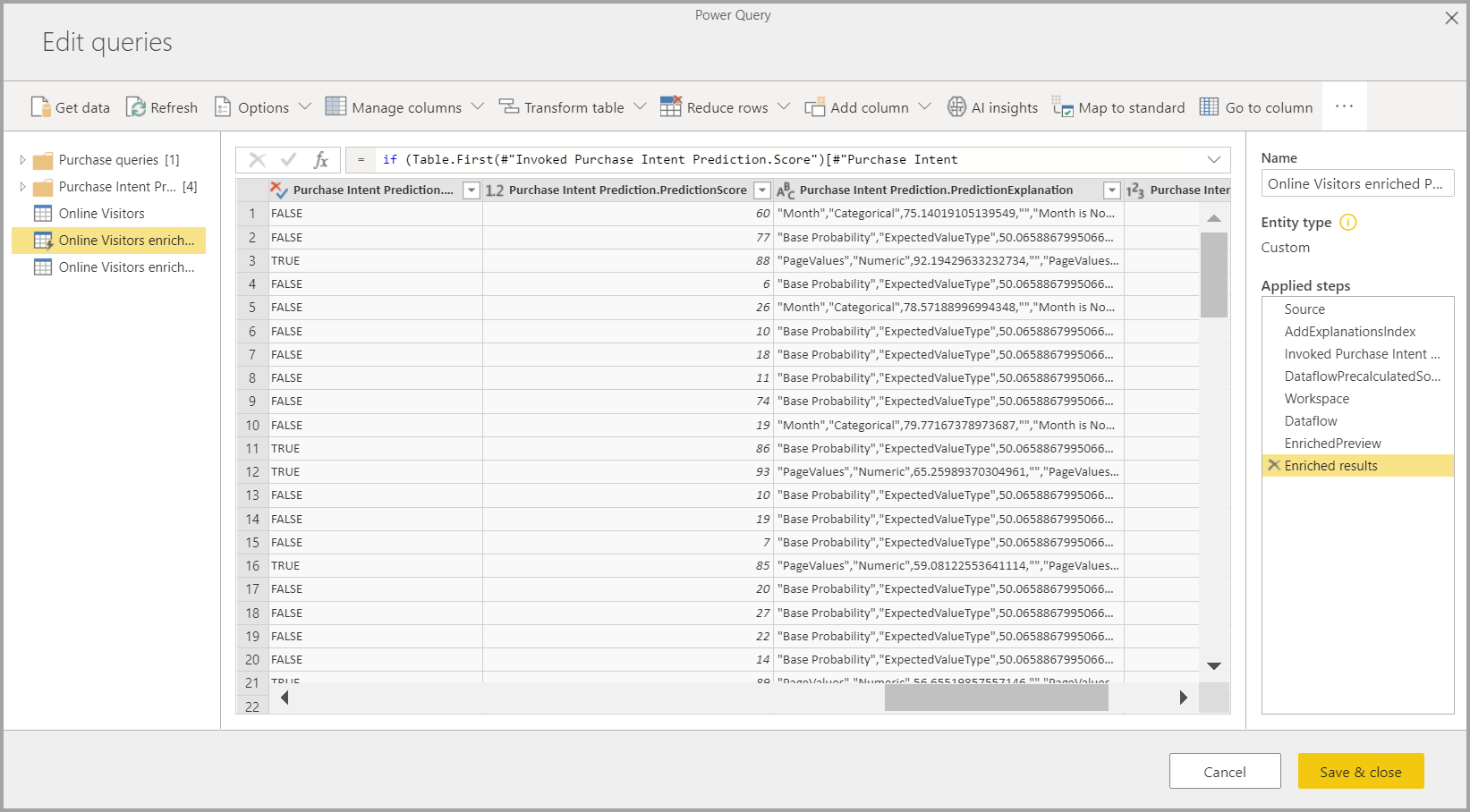
Вы также можете применить любую модель AutoML Power BI к таблицам в любом потоке данных в той же рабочей области с помощью Аналитика ИИ в браузере функций PQO. Таким образом, модели, созданные другими пользователями в той же рабочей области, можно использовать без необходимости владельца потока данных, имеющего модель. Power Query обнаруживает все модели Машинного обучения Power BI в рабочей области и предоставляет их как динамические функции Power Query. Эти функции можно вызвать, используя их из ленты в Редактор Power Query или напрямую вызвав функцию M. Эта функция в настоящее время поддерживается только для потоков данных Power BI и Power Query Online в служба Power BI. Этот процесс отличается от применения моделей машинного обучения в потоке данных с помощью мастера AutoML. Таблицы объяснений, созданные с помощью этого метода, отсутствуют. Если вы не являетесь владельцем потока данных, вы не можете получить доступ к отчетам об обучении моделей или повторно обучить модель. Кроме того, если исходная модель редактируется путем добавления или удаления входных столбцов или источника потока данных, этот зависимый поток данных будет нарушен.

После применения модели AutoML всегда обновляет прогнозы при обновлении потока данных.
Чтобы использовать аналитические сведения и прогнозы из модели машинного обучения в отчете Power BI, можно подключиться к выходной таблице из Power BI Desktop с помощью соединителя потоков данных.
Модели двоичного прогнозирования
Модели двоичного прогнозирования, более официально известные как модели двоичной классификации, используются для классификации семантической модели в две группы. Они используются для прогнозирования событий, которые могут иметь двоичный результат. Например, будет ли возможность продаж преобразовывать, будет ли учетная запись получать данные, будет ли счет выплачиваться вовремя, является ли транзакция мошеннической, и т. д.
Выходные данные модели двоичного прогнозирования — это оценка вероятности, которая определяет вероятность достижения целевого результата.
Обучение модели двоичного прогнозирования
Предварительные требования:
- Для каждого класса результатов требуется не менее 20 строк исторических данных.
Процесс создания модели двоичного прогнозирования выполняет те же действия, что и другие модели AutoML, описанные в предыдущем разделе, настройка входных данных модели машинного обучения. Единственное различие заключается в шаге "Выбор модели ", где можно выбрать целевое значение результата, которое вам наиболее интересно. Вы также можете предоставить понятные метки для результатов, которые будут использоваться в автоматически созданном отчете, который суммирует результаты проверки модели.

Отчет модели двоичного прогнозирования
Модель двоичного прогнозирования создает в виде выходных данных вероятность того, что строка достигнет целевого результата. Отчет включает срез порога вероятности, который влияет на то, как оценки больше и меньше порога вероятности интерпретируются.
В отчете описывается производительность модели с точки зрения истинных положительных, ложных срабатываний, истинных отрицательных и ложных отрицательных. Истинные положительные и истинные отрицательные результаты правильно прогнозируются для двух классов в данных результатов. Ложные срабатывания — это строки, спрогнозируемые для достижения целевого результата, но на самом деле это не так. И наоборот, ложные отрицательные значения — это строки, которые имели целевые результаты, но прогнозировались как не те.
Меры, такие как точность и отзыв, описывают влияние порога вероятности на прогнозируемые результаты. Срез порогового значения вероятности можно использовать для выбора порогового значения, которое достигает сбалансированного компромисса между точностью и отзывом.

В отчете также содержится средство анализа затрат и преимуществ, помогающее определить подмножество населения, которое должно быть нацелено на получение наибольшей прибыли. Учитывая предполагаемые затраты на единицу целевого назначения и преимущества единицы от достижения целевого результата, анализ затрат на выгоду пытается максимизировать прибыль. Это средство можно использовать для выбора порогового значения вероятности на основе максимальной точки в графе для максимальной прибыли. Вы также можете использовать график для вычисления прибыли или стоимости для выбранного порогового значения вероятности.
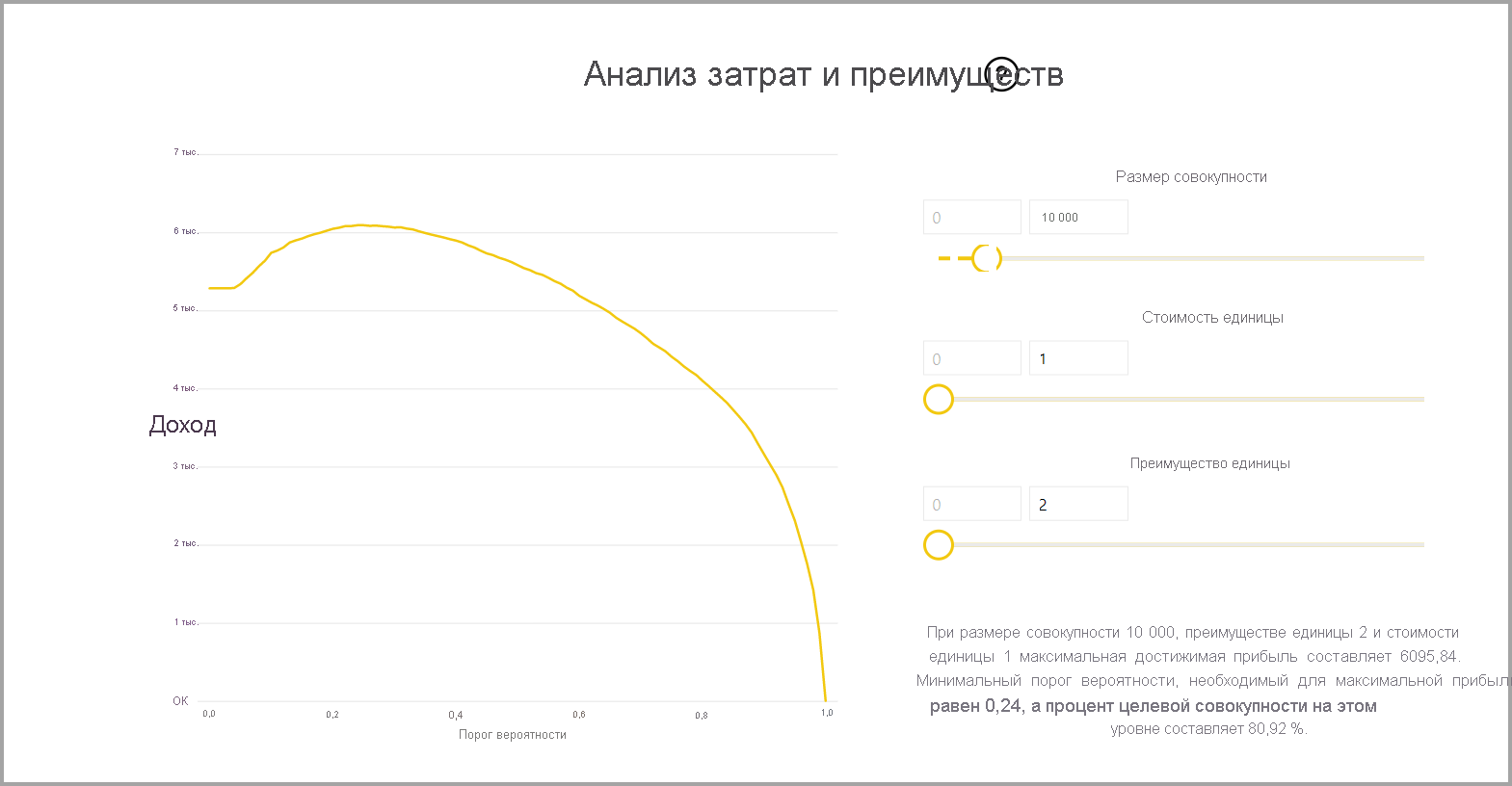
Страница отчета о точности модели включает диаграмму совокупных приростов и кривую ROC для модели. Эти данные предоставляют статистические меры производительности модели. Отчеты включают описания показанных диаграмм.
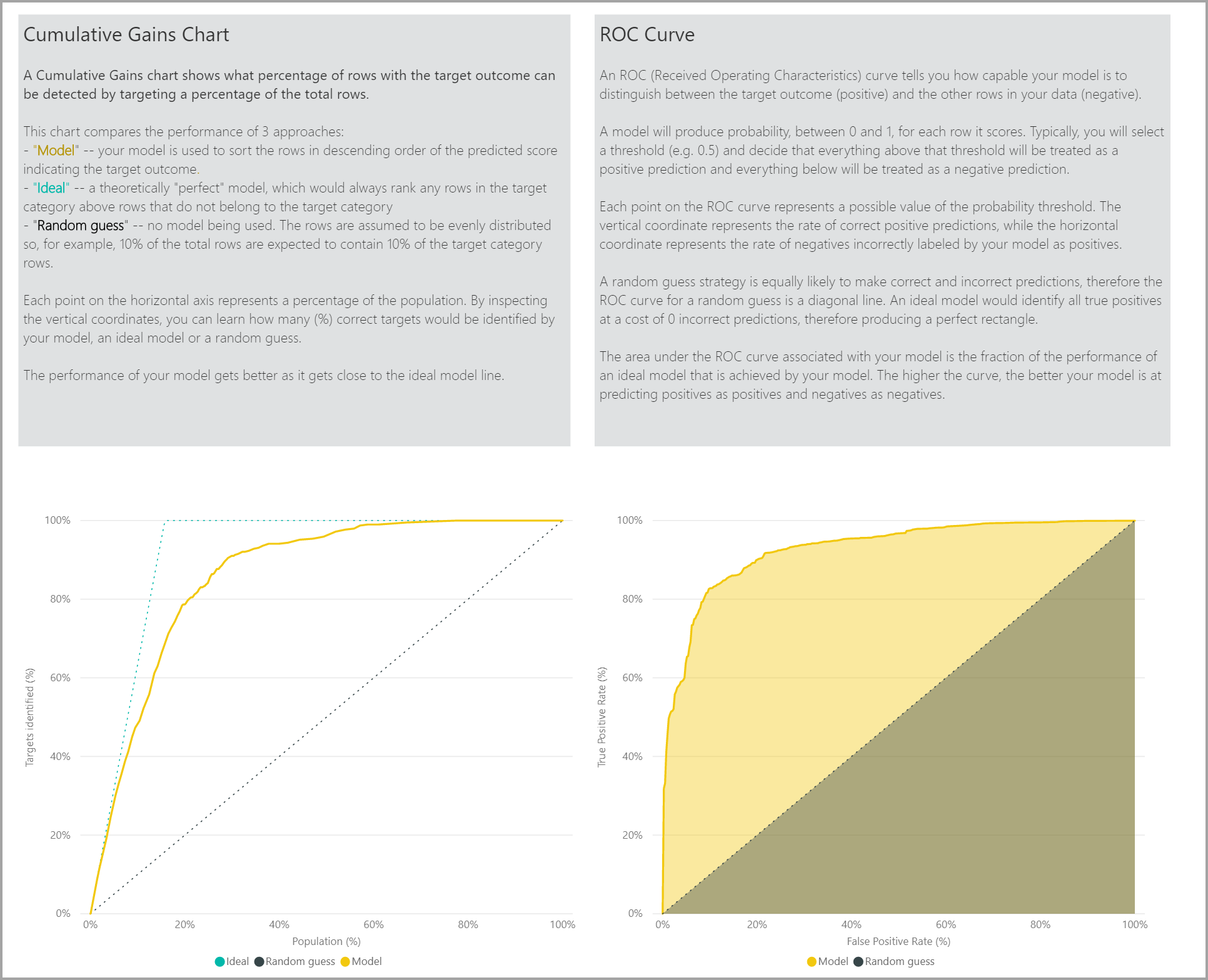
Применение модели двоичного прогнозирования
Чтобы применить модель двоичного прогнозирования, необходимо указать таблицу с данными, к которым необходимо применить прогнозы из модели машинного обучения. Другие параметры включают префикс имени выходного столбца и порог вероятности для классификации прогнозируемого результата.
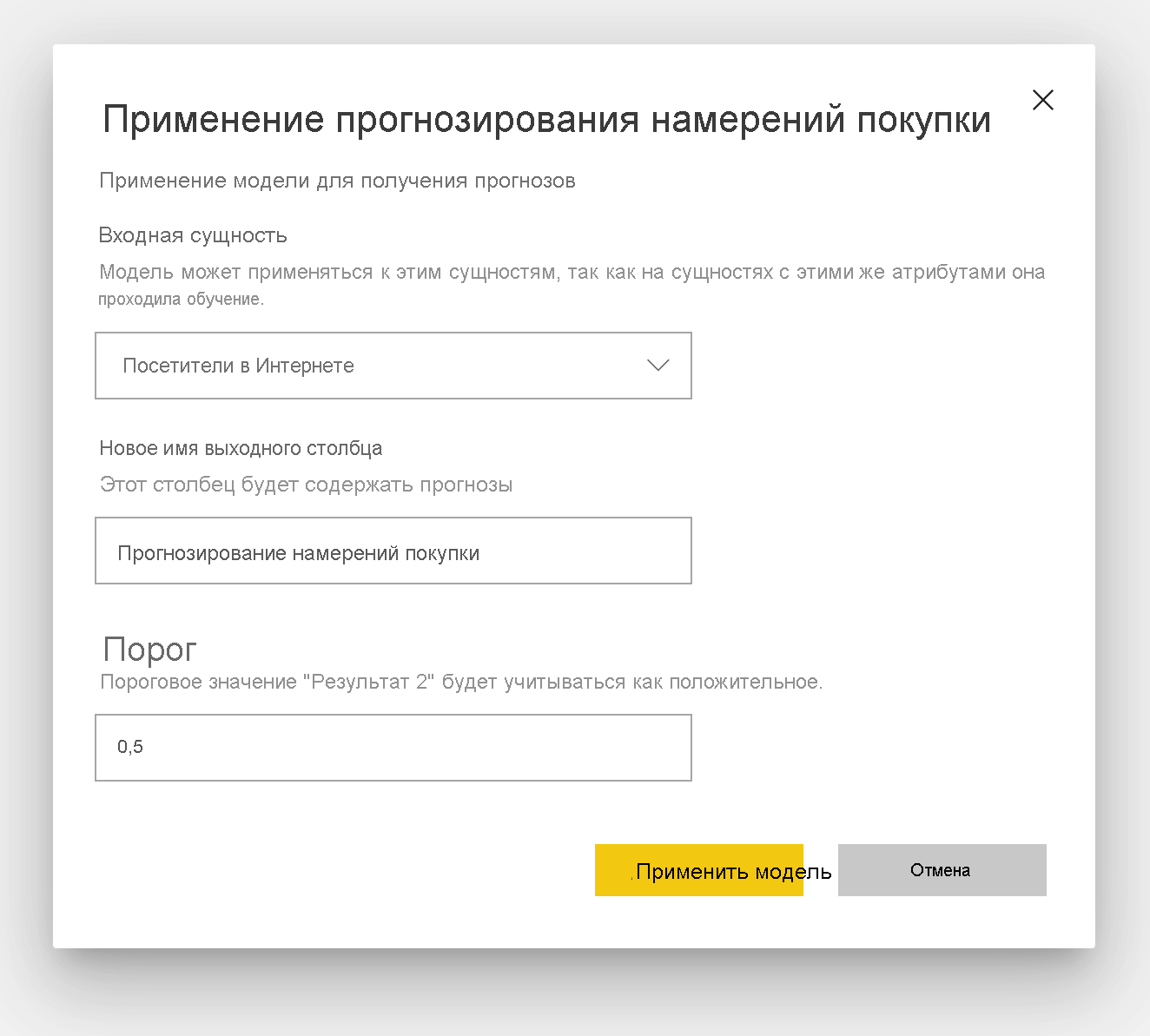
При применении модели двоичного прогнозирования он добавляет четыре выходных столбца в обогащенную выходную таблицу: Результаты, ПрогнозScore, PredictionExplanation и ExplanationIndex. Имена столбцов в таблице имеют префикс, указанный при применении модели.
PredictionScore — это процентная вероятность, которая определяет вероятность достижения целевого результата.
Столбец "Результат" содержит прогнозируемую метку результата. Записи с вероятностями, превышающими пороговое значение, прогнозируются как вероятные для достижения целевого результата и помечены как True. Записи меньше порога прогнозируются, как вряд ли достигнут результат и помечены как false.
Столбец PredictionExplanation содержит объяснение с определенным влиянием, которое входные функции имели на PredictionScore.
Classification models (Модели классификации)
Модели классификации используются для классификации семантической модели в несколько групп или классов. Они используются для прогнозирования событий, которые могут иметь один из нескольких возможных результатов. Например, может ли клиент иметь высокий, средний или низкий срок жизни. Они также могут предсказать, является ли риск по умолчанию высоким, умеренным, низким и т. д.
Выходные данные модели классификации — это оценка вероятности, которая определяет вероятность того, что строка достигнет критериев для данного класса.
Обучение модели классификации
Входная таблица, содержащая данные обучения для модели классификации, должна иметь строку или целый столбец чисел в качестве столбца результатов, который определяет прошлые известные результаты.
Предварительные требования:
- Для каждого класса результатов требуется не менее 20 строк исторических данных.
Процесс создания модели классификации выполняет те же действия, что и другие модели AutoML, описанные в предыдущем разделе, настройка входных данных модели машинного обучения.
Отчет о модели классификации
Power BI создает отчет о модели классификации, применяя модель машинного обучения к данным тестового хранения. Затем он сравнивает прогнозируемый класс для строки с фактическим известным классом.
Отчет модели содержит диаграмму, содержащую разбивку правильно и неправильно классифицированных строк для каждого известного класса.
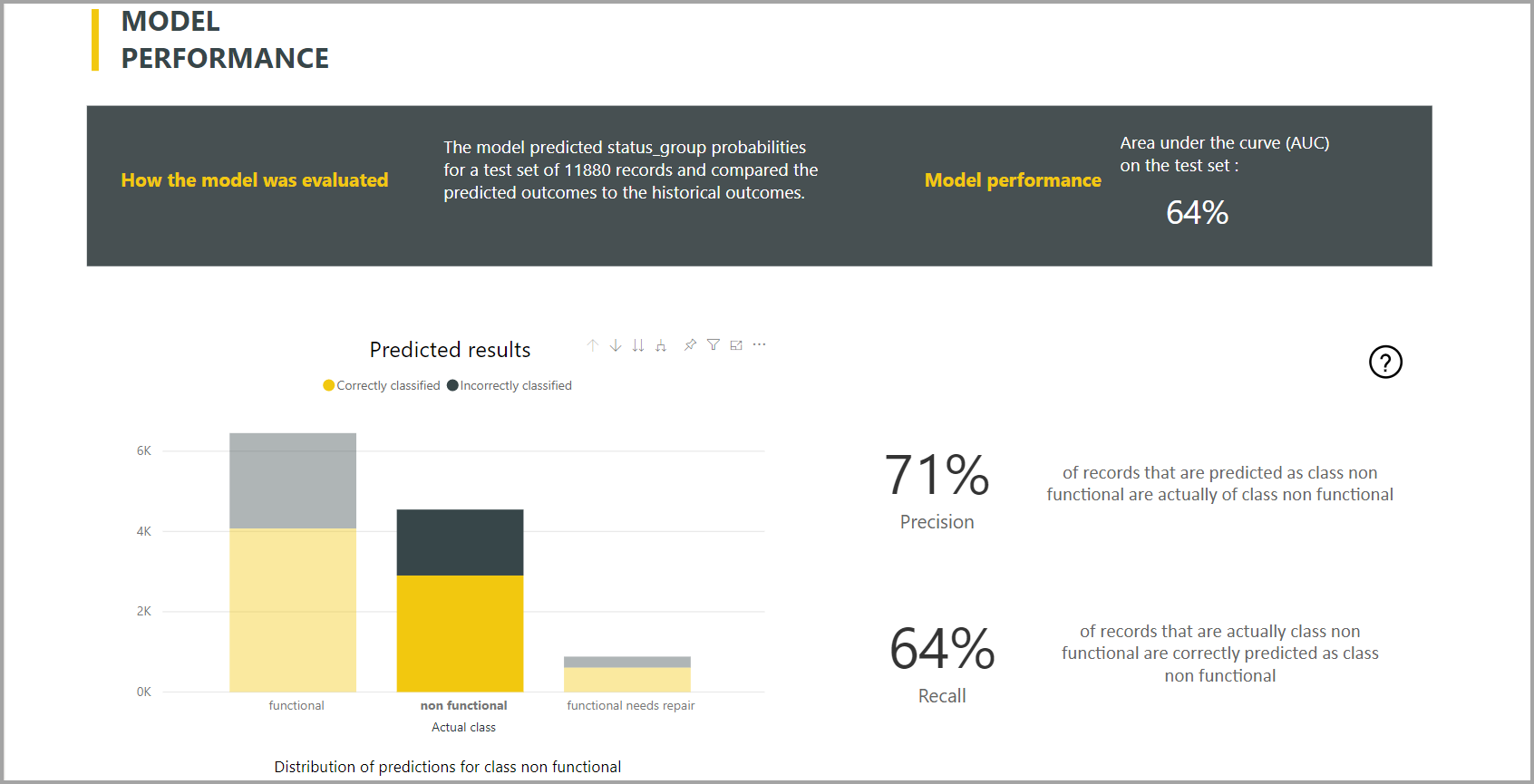
Дополнительное действие детализации для конкретного класса позволяет проанализировать способ распределения прогнозов для известного класса. В этом анализе показаны другие классы, в которых строки известного класса, скорее всего, будут неправильно классифицированы.
Объяснение модели в отчете также включает в себя основные прогнозаторы для каждого класса.
Отчет о модели классификации также содержит страницу сведений об обучении, аналогичную страницам для других типов моделей, как описано ранее в отчете об модели AutoML.
Применение модели классификации
Чтобы применить модель машинного обучения классификации, необходимо указать таблицу с входными данными и префиксом имени выходного столбца.
При применении модели классификации к обогащенной выходной таблице добавляется пять выходных столбцов: ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities и ExplanationIndex. Имена столбцов в таблице имеют префикс, указанный при применении модели.
Столбец ClassProbabilities содержит список показателей вероятности для строки для каждого возможного класса.
ClassificationScore — это процентная вероятность, которая определяет вероятность достижения строкой условий для данного класса.
Столбец ClassificationResult содержит наиболее вероятный прогнозируемый класс для строки.
Столбец ClassificationExplanation содержит пояснение с определенным влиянием, что входные функции имели на КлассификацииScore.
Модели регрессии
Модели регрессии используются для прогнозирования числового значения и могут использоваться в таких сценариях, как определение:
- Выручка, скорее всего, будет реализована из сделки по продажам.
- Значение времени существования учетной записи.
- Сумма счета по задолженности, который, скорее всего, будет выплачен
- Дата оплаты счета и т. д.
Выходные данные модели регрессии — это прогнозируемое значение.
Обучение модели регрессии
Входная таблица, содержащая данные обучения для модели регрессии, должна иметь числовый столбец в качестве столбца результата, который определяет известные значения результатов.
Предварительные требования:
- Для модели регрессии требуется не менее 100 строк исторических данных.
Процесс создания модели регрессии выполняет те же действия, что и другие модели AutoML, описанные в предыдущем разделе, настройка входных данных модели машинного обучения.
Отчет о модели регрессии
Как и в других отчетах об модели AutoML, отчет регрессии основан на результатах применения модели к тестовых данных удержания.
Отчет модели содержит диаграмму, которая сравнивает прогнозируемые значения с фактическими значениями. На этой диаграмме расстояние от диагонали указывает на ошибку в прогнозе.
На остаточной диаграмме ошибок отображается распределение процента средней ошибки для различных значений в семантической модели теста удержания. Горизонтальная ось представляет среднее значение фактического значения для группы. Размер пузырька показывает частоту или количество значений в этом диапазоне. Вертикальная ось — средняя остаточная ошибка.
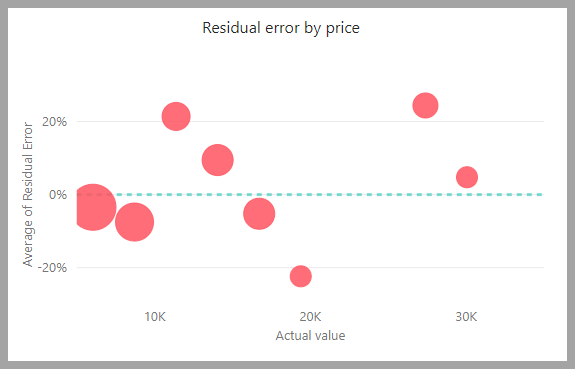
Отчет о модели регрессии также содержит страницу сведений об обучении, например отчеты для других типов моделей, как описано в предыдущем разделе, отчет о модели AutoML.
Применение модели регрессии
Чтобы применить модель машинного обучения регрессии, необходимо указать таблицу с входными данными и префиксом имени выходного столбца.
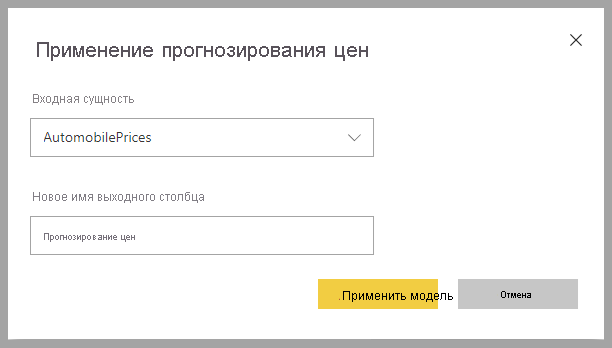
При применении модели регрессии добавляется три выходных столбца в обогащенную выходную таблицу: RegressionResult, RegressionExplanation и ExplanationIndex. Имена столбцов в таблице имеют префикс, указанный при применении модели.
Столбец RegressionResult содержит прогнозируемое значение строки на основе входных столбцов. Столбец RegressionExplanation содержит объяснение с конкретным влиянием на входные функции на регрессионResult.
интеграция Машинное обучение Azure в Power BI
Многочисленные организации используют модели машинного обучения для улучшения аналитических сведений и прогнозов по их бизнесу. Вы можете использовать машинное обучение с отчетами, панелями мониторинга и другими аналитическими данными. Возможность визуализировать и вызывать аналитические сведения из этих моделей может помочь распространить эти аналитические сведения для бизнес-пользователей, которым он больше всего нужен. Теперь Power BI упрощает внедрение аналитических сведений из моделей, размещенных на Машинное обучение Azure, с помощью простых жестов мыши и указателей мыши.
Чтобы использовать эту возможность, специалист по обработке и анализу данных может предоставить доступ к модели Машинное обучение Azure аналитику бизнес-аналитика с помощью портал Azure. Затем в начале каждого сеанса Power Query обнаруживает все модели Машинное обучение Azure, к которым пользователь имеет доступ, и предоставляет их как динамические функции Power Query. Затем пользователь может вызвать эти функции путем доступа к ним с ленты в Редактор Power Query или путем вызова функции M напрямую. Power BI также автоматически пакетирует запросы доступа при вызове модели Машинное обучение Azure для набора строк для повышения производительности.
В настоящее время эта функция поддерживается только для потоков данных Power BI и для Power Query в интернете в служба Power BI.
Дополнительные сведения о потоках данных см. в статье "Общие сведения о потоках данных" и подготовке данных самообслуживания.
Дополнительные сведения о Машинное обучение Azure см. в следующем разделе:
- Обзор. Что такое Машинное обучение Azure?
- Краткие руководства по Машинное обучение Azure: документация по Машинное обучение Azure
Предоставление доступа к модели Машинное обучение Azure пользователю Power BI
Чтобы получить доступ к модели Машинное обучение Azure из Power BI, пользователь должен иметь доступ на чтение к подписке Azure и рабочей области Машинное обучение.
В этой статье описано, как предоставить пользователю Power BI доступ к модели, размещенной в службе Машинное обучение Azure, для доступа к этой модели в качестве функции Power Query. Дополнительные сведения см. в разделе Назначение ролей Azure с помощью портала Azure.
Войдите на портал Azure.
Перейдите на страницу "Подписки". Вы можете найти страницу "Подписки" в списке "Все службы" в меню области навигации портал Azure.

Выберите свою подписку.
Выберите контроль доступа (IAM) и нажмите кнопку "Добавить".

Выберите читатель в качестве роли. Затем выберите пользователя Power BI, которому вы хотите предоставить доступ к модели Машинное обучение Azure.

Выберите Сохранить.
Повторите шаги три-шесть, чтобы предоставить пользователю доступ читателя для конкретной рабочей области машинного обучения, в котором размещена модель.




Обнаружение схем для моделей машинного обучения
Специалисты по обработке и анализу данных в основном используют Python для разработки и даже развертывания моделей машинного обучения для машинного обучения. Специалист по обработке и анализу данных должен явно создать файл схемы с помощью Python.
Этот файл схемы должен быть включен в развернутую веб-службу для моделей машинного обучения. Чтобы автоматически создать схему для веб-службы, необходимо указать пример входных и выходных данных в скрипте записи для развернутой модели. Дополнительные сведения см. в статье "Развертывание и оценка модели машинного обучения с помощью сетевой конечной точки". Ссылка содержит пример скрипта записи с инструкциями для создания схемы.
В частности, функции @input_schema и @output_schema в скрипте записи ссылались на форматы входных и выходных примеров в переменных input_sample и output_sample. Эти функции используются для создания спецификации OpenAPI (Swagger) для веб-службы во время развертывания.
Эти инструкции по созданию схемы путем обновления скрипта записи также должны применяться к моделям, созданным с помощью автоматизированных экспериментов машинного обучения с пакетом SDK для Машинное обучение Azure.
Примечание.
Модели, созданные с помощью визуального интерфейса Машинное обучение Azure, в настоящее время не поддерживают создание схемы, но в последующих выпусках.
Вызов модели Машинное обучение Azure в Power BI
Вы можете вызвать любую модель Машинное обучение Azure, к которой вы получили доступ, непосредственно из Редактор Power Query в потоке данных. Чтобы получить доступ к моделям Машинное обучение Azure, нажмите кнопку "Изменить таблицу" для таблицы, которую вы хотите дополнить аналитическими сведениями из модели Машинное обучение Azure, как показано на следующем рисунке.

При нажатии кнопки "Изменить таблицу" откроется Редактор Power Query для таблиц в потоке данных.

Нажмите кнопку Аналитика ИИ на ленте и выберите папку Машинное обучение Azure Models в меню области навигации. Все Машинное обучение Azure модели, к которым у вас есть доступ, перечислены здесь как функции Power Query. Кроме того, входные параметры для модели Машинное обучение Azure автоматически сопоставляются как параметры соответствующей функции Power Query.
Чтобы вызвать модель Машинное обучение Azure, можно указать любой из столбцов выбранной таблицы в качестве входных данных из раскрывающегося списка. Можно также указать константное значение, которое будет использоваться в качестве входных данных, переключив значок столбца слева от диалогового окна ввода.

Выберите "Вызвать", чтобы просмотреть предварительный просмотр выходных данных модели Машинное обучение Azure в качестве нового столбца в таблице. Вызов модели отображается как примененный шаг для запроса.

Если модель возвращает несколько выходных параметров, они группируются в виде строки в выходном столбце. Чтобы создать отдельные выходные параметры в отдельных столбцах, можно развернуть столбец.

После сохранения потока данных модель автоматически вызывается при обновлении потока данных для любых новых или обновленных строк в таблице.
Рекомендации и ограничения
- Потоки данных 2-го поколения в настоящее время не интегрируются с автоматизированным машинным обучением.
- Аналитика ИИ (Cognitive Services и модели Машинное обучение Azure) не поддерживается на компьютерах с настройкой проверки подлинности прокси-сервера.
- Машинное обучение Azure модели не поддерживаются для гостевых пользователей.
- Существуют некоторые известные проблемы с использованием шлюза с AutoML и Cognitive Services. Если вам нужно использовать шлюз, рекомендуется сначала создать поток данных, который импортирует необходимые данные через шлюз. Затем создайте другой поток данных, который ссылается на первый поток данных для создания или применения этих моделей и функций искусственного интеллекта.
- Если искусственный интеллект работает с потоками данных, может потребоваться включить быстрое объединение при использовании ИИ с потоками данных. После импорта таблицы и перед добавлением функций ИИ выберите " Параметры " на ленте "Главная" и в окне, которое отображается, установите флажок рядом с разрешением объединения данных из нескольких источников , чтобы включить эту функцию, а затем нажмите кнопку "ОК ", чтобы сохранить выбор. Затем вы можете добавить функции ИИ в поток данных.
Связанный контент
В этой статье представлен обзор автоматизированных Машинное обучение для потоков данных в служба Power BI. Кроме того, могут быть полезны следующие статьи.
- Руководство. Создание модели Машинное обучение в Power BI
- Руководство. Использование Cognitive Services в Power BI
Дополнительные сведения о потоках данных и Power BI см. в следующих статьях.
- Введение в потоки данных и самостоятельную подготовку данных
- Создание потока данных
- Настройка и использование потока данных
- Настройка хранилища потоков данных для использования Azure Data Lake 2-го поколения
- Функции потоков данных уровня "Премиум"
- Рекомендации и ограничения, касающиеся потоков данных
- Рекомендации по потокам данных