Modellanpassning (version 4.0 förhandsversion)
Viktigt!
Den här funktionen är nu inaktuell. Den 10 januari 2025 dras API:et för anpassad bildanalys 4.0 för Azure AI Image Analysis 4.0, anpassad objektidentifiering och förhandsgranskning av produktigenkänning tillbaka. Efter det här datumet misslyckas API-anrop till dessa tjänster.
För att upprätthålla en smidig drift av dina modeller övergår du till Azure AI Custom Vision, som nu är allmänt tillgängligt. Custom Vision erbjuder liknande funktioner som dessa funktioner för att dra tillbaka.
Med modellanpassning kan du träna en specialiserad bildanalysmodell för ditt eget användningsfall. Anpassade modeller kan antingen göra bildklassificering (taggar gäller för hela bilden) eller objektidentifiering (taggar gäller för specifika områden i bilden). När din anpassade modell har skapats och tränats tillhör den din Vision-resurs och du kan anropa den med hjälp av API:et Analysera bild.
Implementera modellanpassning snabbt och enkelt genom att följa en snabbstart:
Viktigt!
Du kan träna en anpassad modell med antingen Custom Vision-tjänsten eller tjänsten Image Analysis 4.0 med modellanpassning. I följande tabell jämförs de två tjänsterna.
| Områden | Custom Vision-tjänsten | Tjänsten Bildanalys 4.0 | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Uppgifter | Objektidentifiering för bildklassificering |
Objektidentifiering för bildklassificering |
||||||||||||||||||||||||||||||||||||
| Basmodell | CNN | Transformeringsmodell | ||||||||||||||||||||||||||||||||||||
| Etikettera | Customvision.ai | AML Studio | ||||||||||||||||||||||||||||||||||||
| Webbportal | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| Bibliotek | REST, SDK | REST, Python-exempel | ||||||||||||||||||||||||||||||||||||
| Minsta träningsdata som behövs | 15 bilder per kategori | 2–5 bilder per kategori | ||||||||||||||||||||||||||||||||||||
| Lagring av träningsdata | Laddas upp till tjänst | Kundens bloblagringskonto | ||||||||||||||||||||||||||||||||||||
| Modellhosting | Moln och gräns | Endast molnvärd, kantcontainervärdar framöver | ||||||||||||||||||||||||||||||||||||
| AI-kvalitet |
|
|
||||||||||||||||||||||||||||||||||||
| Prissättning | Custom Vision-prissättning | Prissättning för bildanalys |
Scenariokomponenter
Huvudkomponenterna i ett modellanpassningssystem är träningsbilderna, COCO-filen, datamängdsobjektet och modellobjektet.
Träningsbilder
Din uppsättning träningsbilder bör innehålla flera exempel på var och en av de etiketter som du vill identifiera. Du vill också samla in några extra bilder för att testa din modell med när den har tränats. Avbildningarna måste lagras i en Azure Storage-container för att vara tillgängliga för modellen.
För att träna din modell effektivt använder du bilder med visuell variation. Välj bilder som varierar beroende på:
- kameravinkel
- belysning
- bakgrund
- visuellt format
- enskilda/grupperade ämnen
- storlek
- type
Se dessutom till att alla träningsbilder uppfyller följande kriterier:
- Bilden måste visas i JPEG-, PNG-, GIF-, BMP-, WEBP-, ICO-, TIFF- eller MPO-format.
- Filstorleken för avbildningen måste vara mindre än 20 MEGABYTE (MB).
- Bildens dimensioner måste vara större än 50 x 50 bildpunkter och mindre än 16 000 x 16 000 bildpunkter.
COCO-fil
COCO-filen refererar till alla träningsbilder och associerar dem med deras etiketteringsinformation. När det gäller objektidentifiering angavs koordinaterna för avgränsningsrutan för varje tagg på varje bild. Den här filen måste vara i COCO-format, vilket är en specifik typ av JSON-fil. COCO-filen ska lagras i samma Azure Storage-container som träningsavbildningarna.
Dricks
Om COCO-filer
COCO-filer är JSON-filer med specifika obligatoriska fält: "images", "annotations"och "categories". En COCO-exempelfil ser ut så här:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
REFERENS FÖR COCO-filfält
Om du genererar en egen COCO-fil från grunden kontrollerar du att alla obligatoriska fält är ifyllda med rätt information. Följande tabeller beskriver varje fält i en COCO-fil:
"bilder"
| Nyckel | Typ | Beskrivning | Obligatorisk? |
|---|---|---|---|
id |
integer | Unikt avbildnings-ID från 1 | Ja |
width |
integer | Bredd på bilden i bildpunkter | Ja |
height |
integer | Bildens höjd i bildpunkter | Ja |
file_name |
sträng | Ett unikt namn för avbildningen | Ja |
absolute_url eller coco_url |
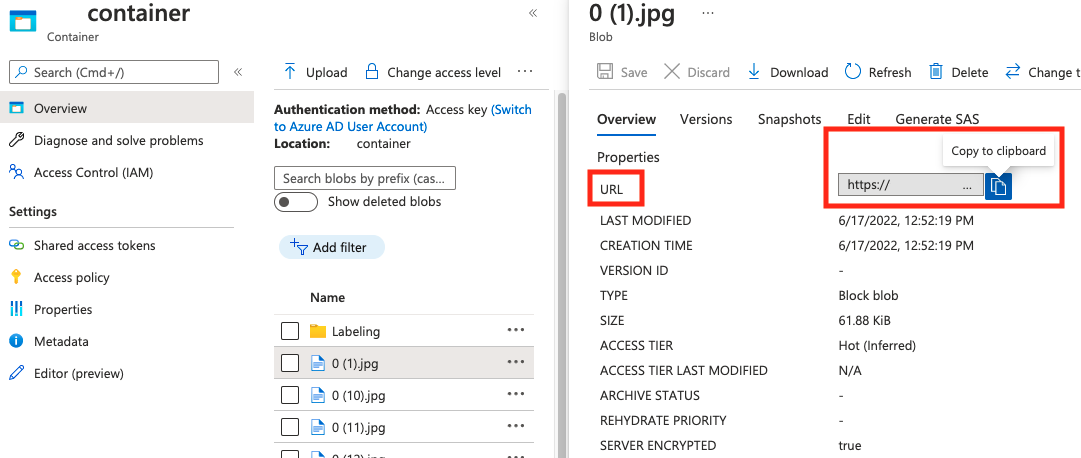
sträng | Bildsökväg som en absolut URI till en blob i en blobcontainer. Vision-resursen måste ha behörighet att läsa anteckningsfilerna och alla refererade bildfiler. | Ja |
Värdet för absolute_url finns i blobcontainerns egenskaper:
"anteckningar"
| Nyckel | Typ | Beskrivning | Obligatorisk? |
|---|---|---|---|
id |
integer | ID för anteckningen | Ja |
category_id |
integer | ID för kategorin som definieras i categories avsnittet |
Ja |
image_id |
integer | ID för avbildningen | Ja |
area |
integer | Värdet för "Width" x "Height" (tredje och fjärde värdet för bbox) |
Nej |
bbox |
list[float] | Relativa koordinater för avgränsningsrutan (0 till 1), i ordningen "Vänster", "Överkant", "Bredd", "Höjd" | Ja |
"kategorier"
| Nyckel | Typ | Beskrivning | Obligatorisk? |
|---|---|---|---|
id |
integer | Unikt ID för varje kategori (etikettklass). Dessa bör finnas i avsnittet annotations . |
Ja |
name |
sträng | Namn på kategorin (etikettklass) | Ja |
VERIFIERING AV COCO-fil
Du kan använda vår Python-exempelkod för att kontrollera formatet på en COCO-fil.
Datamängdsobjekt
Datamängdsobjektet är en datastruktur som lagras av tjänsten Bildanalys som refererar till associationsfilen. Du måste skapa ett datauppsättningsobjekt innan du kan skapa och träna en modell.
Modellobjekt
Modellobjektet är en datastruktur som lagras av tjänsten Bildanalys som representerar en anpassad modell. Den måste vara associerad med en datauppsättning för att kunna utföra den inledande träningen. När den har tränats kan du fråga din modell genom att ange dess namn i model-name frågeparametern för API-anropet Analysera bild.
Kvotgränser
I följande tabell beskrivs gränserna för skalan för dina anpassade modellprojekt.
| Kategori | Allmän bildklassificerare | Allmän objektdetektor |
|---|---|---|
| Max antal träningstimmar | 288 (12 dagar) | 288 (12 dagar) |
| Max # träningsbilder | 1 000 000 | 200 000 |
| Max # utvärderingsbilder | 100,000 | 100,000 |
| Min # träningsbilder per kategori | 2 | 2 |
| Maximalt antal taggar per bild | 1 | Ej tillämpligt |
| Maximalt antal regioner per bild | Ej tillämpligt | 1 000 |
| Maximalt antal kategorier | 2 500 | 1 000 |
| Min #-kategorier | 2 | 1 |
| Maximal bildstorlek (träning) | 20 MB | 20 MB |
| Maximal bildstorlek (förutsägelse) | Synkronisering: 6 MB, Batch: 20 MB | Synkronisering: 6 MB, Batch: 20 MB |
| Maximal bildbredd/höjd (träning) | 10,240 | 10,240 |
| Minsta bildbredd/höjd (förutsägelse) | 50 | 50 |
| Tillgängliga regioner | USA, västra 2, USA, östra, Europa, västra | USA, västra 2, USA, östra, Europa, västra |
| Godkända avbildningstyper | jpg, png, bmp, gif, jpeg | jpg, png, bmp, gif, jpeg |
Vanliga frågor och svar
Varför misslyckas min COCO-filimport när jag importerar från Blob Storage?
För närvarande löser Microsoft ett problem som gör att COCO-filimporten misslyckas med stora datauppsättningar när den initieras i Vision Studio. Om du vill träna med en stor datauppsättning rekommenderar vi att du använder REST-API:et i stället.
Varför tar utbildningen längre/kortare tid än min angivna budget?
Den angivna träningsbudgeten är den kalibrerade beräkningstiden, inte tiden för väggklockan. Några vanliga orsaker till skillnaden visas:
Längre än angiven budget:
- Bildanalys upplever en hög träningstrafik och GPU-resurser kan vara snäva. Jobbet kan vänta i kön eller spärras under träningen.
- Serverdelsträningsprocessen stötte på oväntade fel, vilket resulterade i att logiken provades igen. De misslyckade körningarna förbrukar inte din budget, men det kan leda till längre utbildningstid i allmänhet.
- Dina data lagras i en annan region än visionsresursen, vilket leder till längre dataöverföringstid.
Kortare än angiven budget: Följande faktorer påskyndar träningen på bekostnad av att använda mer budget under viss tid på väggklockan.
- Bildanalys tränar ibland med flera GPU:er beroende på dina data.
- Bildanalys tränar ibland flera utforskningsförsök på flera GPU:er samtidigt.
- Bildanalys använder ibland förstklassiga (snabbare) GPU-SKU:er för att träna.
Varför misslyckas min träning och vad jag bör göra?
Följande är några vanliga orsaker till träningsfel:
diverged: Träningen kan inte lära sig meningsfulla saker från dina data. Några vanliga orsaker är:- Data räcker inte: att tillhandahålla mer data bör vara till hjälp.
- Data är av dålig kvalitet: kontrollera om bilderna har låg upplösning, extrema proportioner eller om anteckningarna är felaktiga.
notEnoughBudget: Din angivna budget räcker inte för storleken på din datauppsättning och modelltyp som du tränar. Ange en större budget.datasetCorrupt: Det innebär vanligtvis att dina angivna bilder inte är tillgängliga eller att anteckningsfilen har fel format.datasetNotFound: Det går inte att hitta datauppsättningenunknown: Det här kan vara ett serverdelsproblem. Kontakta supporten för undersökning.
Vilka mått används för att utvärdera modellerna?
Följande mått används:
- Bildklassificering: Genomsnittlig precision, noggrannhet topp 1, noggrannhet topp 5
- Objektidentifiering: Genomsnittlig genomsnittlig precision @ 30, genomsnittlig genomsnittlig precision @ 50, genomsnittlig genomsnittlig precision @ 75
Varför misslyckas min datauppsättningsregistrering?
API-svaren bör vara tillräckligt informativa. Dessa är:
DatasetAlreadyExists: Det finns en datauppsättning med samma namnDatasetInvalidAnnotationUri: "En ogiltig URI angavs bland antecknings-URI:erna vid registreringstiden för datamängden.
Hur många bilder krävs för rimlig/bra/bästa modellkvalitet?
Även om Florens-modeller har bra kapacitet med få skott (uppnå bra modellprestanda under begränsad datatillgänglighet), gör mer data i allmänhet din tränade modell bättre och mer robust. Vissa scenarier kräver lite data (som att klassificera ett äpple mot en banan), men andra kräver mer (som att upptäcka 200 typer av insekter i en regnskog). Detta gör det svårt att ge en enda rekommendation.
Om din budget för dataetiketter är begränsad är vårt rekommenderade arbetsflöde att upprepa följande steg:
Samla in
Nbilder per klass, därNbilder är enkla att samla in (till exempelN=3)Träna en modell och testa den på din utvärderingsuppsättning.
Om modellprestandan är:
- Tillräckligt bra (prestanda är bättre än förväntat eller prestanda nära ditt tidigare experiment med mindre insamlade data): Stanna här och använd den här modellen.
- Inte bra (prestandan är fortfarande under förväntan eller bättre än ditt tidigare experiment med mindre data som samlats in med en rimlig marginal):
- Samla in fler bilder för varje klass – ett tal som är enkelt att samla in – och gå tillbaka till steg 2.
- Om du märker att prestandan inte förbättras längre efter några iterationer kan det bero på att:
- Det här problemet är inte väldefinierat eller för svårt. Kontakta oss för analys från fall till fall.
- träningsdata kan vara av låg kvalitet: kontrollera om det finns fel anteckningar eller bilder med mycket låg bildpunkt.
Hur mycket träningsbudget ska jag ange?
Du bör ange den övre budgetgränsen som du är villig att använda. Bildanalys använder ett AutoML-system i serverdelen för att prova olika modeller och träningsrecept för att hitta den bästa modellen för ditt användningsfall. Ju mer budget som ges, desto större är chansen att hitta en bättre modell.
AutoML-systemet stoppas också automatiskt om det drar slutsatsen att det inte finns något behov av att prova mer, även om det fortfarande finns kvar budget. Så den uttömmer inte alltid din angivna budget. Du kommer garanterat inte att debiteras över din angivna budget.
Kan jag styra hyperparametrarna eller använda mina egna modeller i träning?
Nej, anpassningstjänsten för bildanalysmodellen använder ett autoML-träningssystem med låg kod som hanterar sökning och basmodellval i serverdelen.
Kan jag exportera min modell efter träningen?
FÖRUTSÄGELSE-API:et stöds endast via molntjänsten.
Varför misslyckas utvärderingen för min objektidentifieringsmodell?
Nedan visas de möjliga orsakerna:
internalServerError: Ett okänt fel inträffade. Försök igen senare.modelNotFound: Det gick inte att hitta den angivna modellen.datasetNotFound: Det gick inte att hitta den angivna datamängden.datasetAnnotationsInvalid: Ett fel uppstod vid försök att ladda ned eller parsa de markanteckningar som är associerade med testdatauppsättningen.datasetEmpty: Testdatauppsättningen innehöll inga anteckningar om "grund sanning".
Vilken är den förväntade svarstiden för förutsägelser med anpassade modeller?
Vi rekommenderar inte att du använder anpassade modeller för affärskritiska miljöer på grund av potentiell hög svarstid. När kunder tränar anpassade modeller i Vision Studio tillhör dessa anpassade modeller den Azure AI Vision-resurs som de har tränats under, och kunden kan göra anrop till dessa modeller med hjälp av API:et Analysera bild . När de gör dessa anrop läses den anpassade modellen in i minnet och förutsägelseinfrastrukturen initieras. Även om detta händer kan kunderna uppleva längre svarstid än förväntat för att få förutsägelseresultat.
Datasekretess och säkerhet
Precis som med alla Azure AI-tjänster bör utvecklare som använder modellanpassning för bildanalys vara medvetna om Microsofts principer för kunddata. Mer information finns på sidan Azure AI-tjänster i Microsoft Trust Center.