Skapa en anpassad bildanalysmodell
Viktigt!
Den här funktionen är nu inaktuell. Den 10 januari 2025 dras API:et för anpassad bildanalys 4.0 för Azure AI Image Analysis 4.0, anpassad objektidentifiering och förhandsgranskning av produktigenkänning tillbaka. Efter det här datumet misslyckas API-anrop till dessa tjänster.
För att upprätthålla en smidig drift av dina modeller övergår du till Azure AI Custom Vision, som nu är allmänt tillgängligt. Custom Vision erbjuder liknande funktioner som dessa funktioner för att dra tillbaka.
Med Bildanalys 4.0 kan du träna en anpassad modell med dina egna träningsbilder. Genom att manuellt märka dina bilder kan du träna en modell att tillämpa anpassade taggar på bilderna (bildklassificering) eller identifiera anpassade objekt (objektidentifiering). Image Analysis 4.0-modeller är särskilt effektiva vid få skottinlärning , så du kan få exakta modeller med mindre träningsdata.
Den här guiden visar hur du skapar och tränar en anpassad bildklassificeringsmodell. De få skillnaderna mellan att träna en bildklassificeringsmodell och objektidentifieringsmodell noteras.
Kommentar
Modellanpassning är tillgängligt via REST API och Vision Studio, men inte via klientspråkets SDK:er.
Förutsättningar
- En Azure-prenumeration. Du kan skapa en kostnadsfritt.
- När du har din Azure-prenumeration skapar du en Vision-resurs i Azure Portal för att hämta din nyckel och slutpunkt. Om du följer den här guiden med Hjälp av Vision Studio måste du skapa din resurs i regionen USA, östra. När den har distribuerats väljer du Gå till resurs. Kopiera nyckeln och slutpunkten till en tillfällig plats för senare användning.
- En Azure Storage-resurs. Skapa en lagringsresurs.
- En uppsättning bilder som du kan träna klassificeringsmodellen med. Du kan använda uppsättningen med exempelbilder på GitHub. Eller så kan du använda dina egna bilder. Du behöver bara cirka 3–5 bilder per klass.
Kommentar
Vi rekommenderar inte att du använder anpassade modeller för affärskritiska miljöer på grund av potentiell hög svarstid. När kunder tränar anpassade modeller i Vision Studio tillhör de anpassade modellerna den Vision-resurs som de har tränats under och kunden kan göra anrop till dessa modeller med hjälp av API:et Analysera bild . När de gör dessa anrop läses den anpassade modellen in i minnet och förutsägelseinfrastrukturen initieras. Även om detta händer kan kunderna uppleva längre svarstid än förväntat för att få förutsägelseresultat.
Skapa en ny anpassad modell
Börja med att gå till Vision Studio och välj fliken Bildanalys. Välj sedan panelen Anpassa modeller.
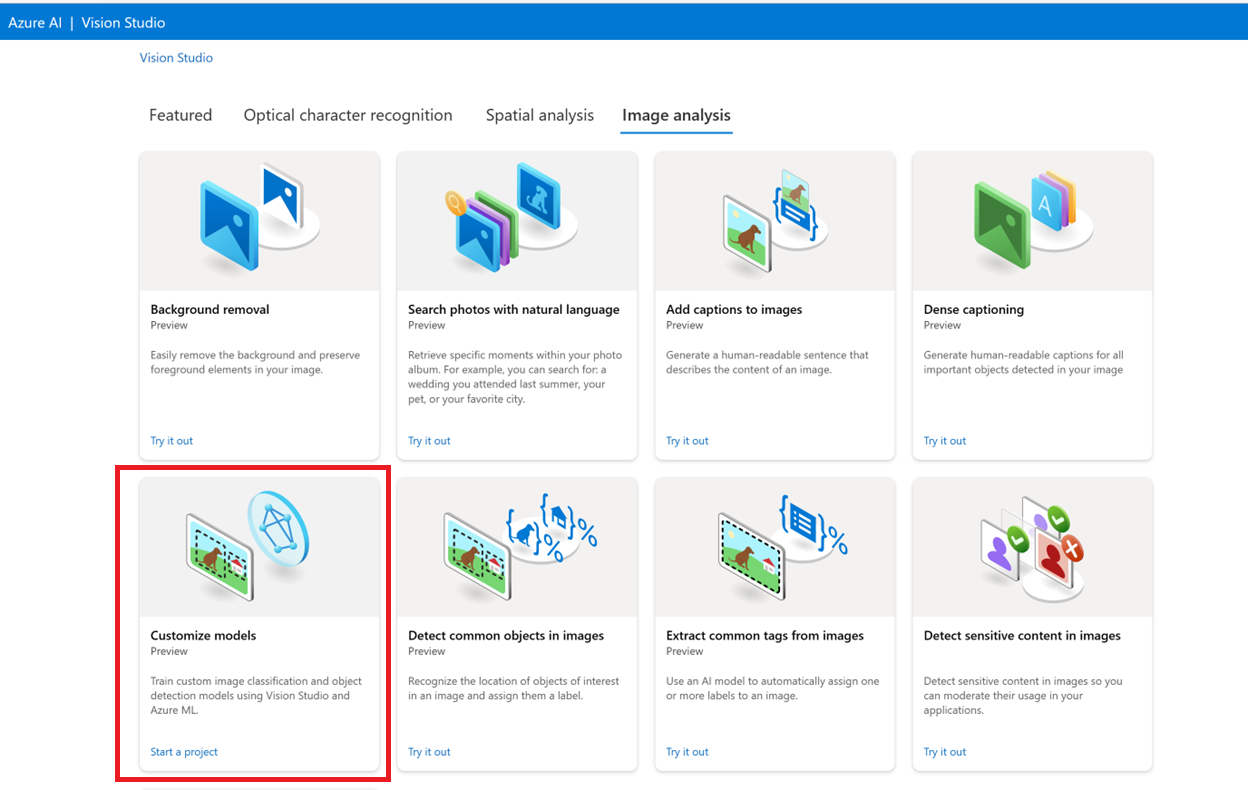
Logga sedan in med ditt Azure-konto och välj din Vision-resurs. Om du inte har en kan du skapa en från den här skärmen.
Förbereda träningsbilder
Du måste ladda upp dina träningsavbildningar till en Azure Blob Storage-container. Gå till lagringsresursen i Azure Portal och gå till fliken Lagringswebbläsare. Här kan du skapa en blobcontainer och ladda upp dina avbildningar. Placera alla i containerns rot.
Lägga till en datauppsättning
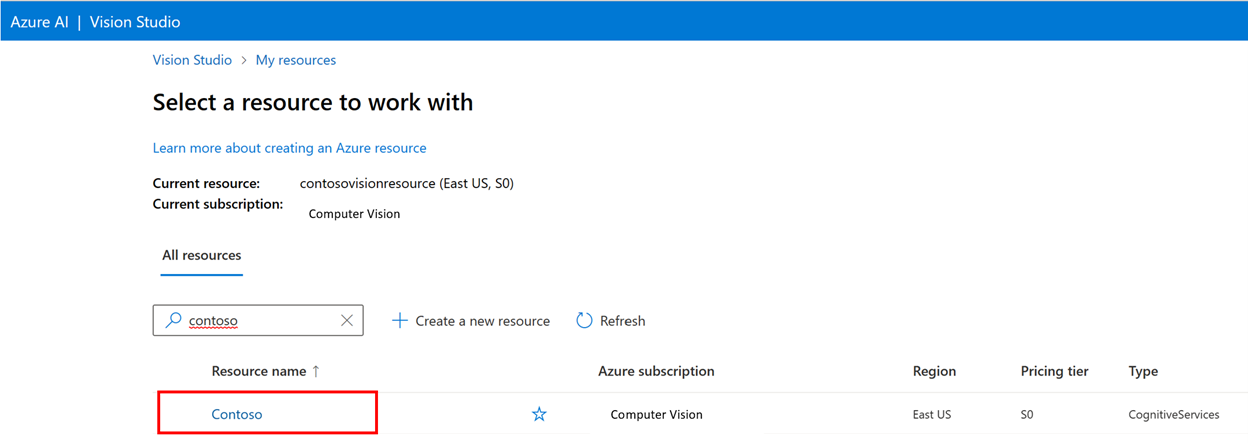
För att träna en anpassad modell måste du associera den med en datauppsättning där du tillhandahåller bilder och deras etikettinformation som träningsdata. I Vision Studio väljer du fliken Datauppsättningar för att visa dina datauppsättningar.
Om du vill skapa en ny datauppsättning väljer du Lägg till ny datauppsättning. I popup-fönstret anger du ett namn och väljer en datauppsättningstyp för ditt användningsfall. Bildklassificeringsmodeller tillämpar innehållsetiketter på hela bilden, medan objektidentifieringsmodeller tillämpar objektetiketter på specifika platser i bilden. Produktigenkänningsmodeller är en underkategori för objektidentifieringsmodeller som är optimerade för att identifiera detaljhandelsprodukter.
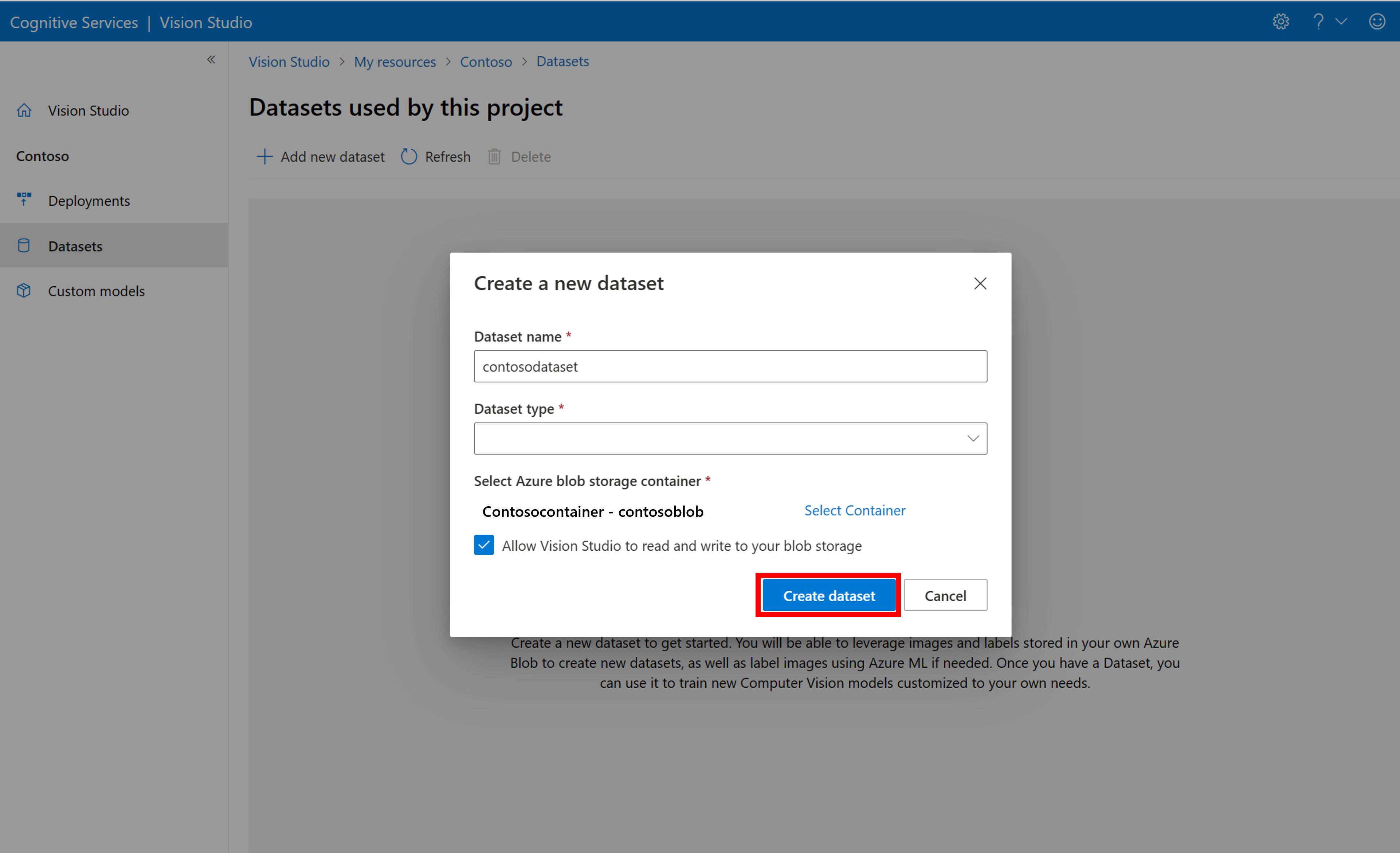
Välj sedan containern från Azure Blob Storage-kontot där du lagrade träningsavbildningarna. Markera kryssrutan för att låta Vision Studio läsa och skriva till bloblagringscontainern. Det här är ett nödvändigt steg för att importera etiketterade data. Skapa datauppsättningen.
Skapa ett Azure Machine Learning-märkningsprojekt
Du behöver en COCO-fil för att förmedla etiketteringsinformationen. Ett enkelt sätt att generera en COCO-fil är att skapa ett Azure Machine Learning-projekt, som levereras med ett arbetsflöde för dataetiketter.
På informationssidan för datamängden väljer du Lägg till ett nytt dataetikettsprojekt. Namnge den och välj Skapa en ny arbetsyta. Då öppnas en ny Azure Portal-flik där du kan skapa Azure Machine Learning-projektet.
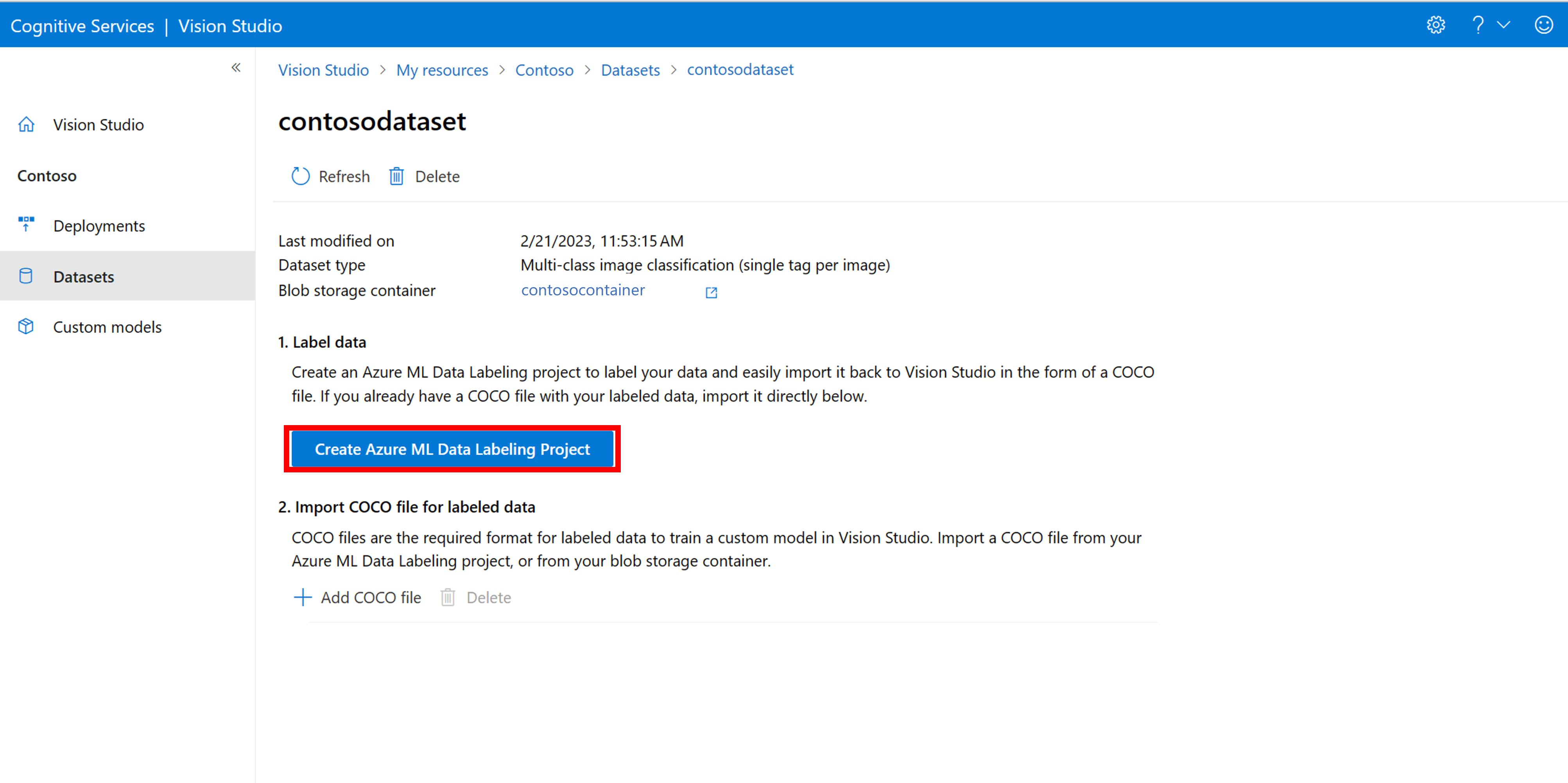
När Azure Machine Learning-projektet har skapats går du tillbaka till fliken Vision Studio och väljer det under Arbetsyta. Azure Machine Learning-portalen öppnas sedan på en ny webbläsarflik.
Skapa etiketter
Börja etikettera genom att följa kommandotolken Lägg till etikettklasser för att lägga till etikettklasser.
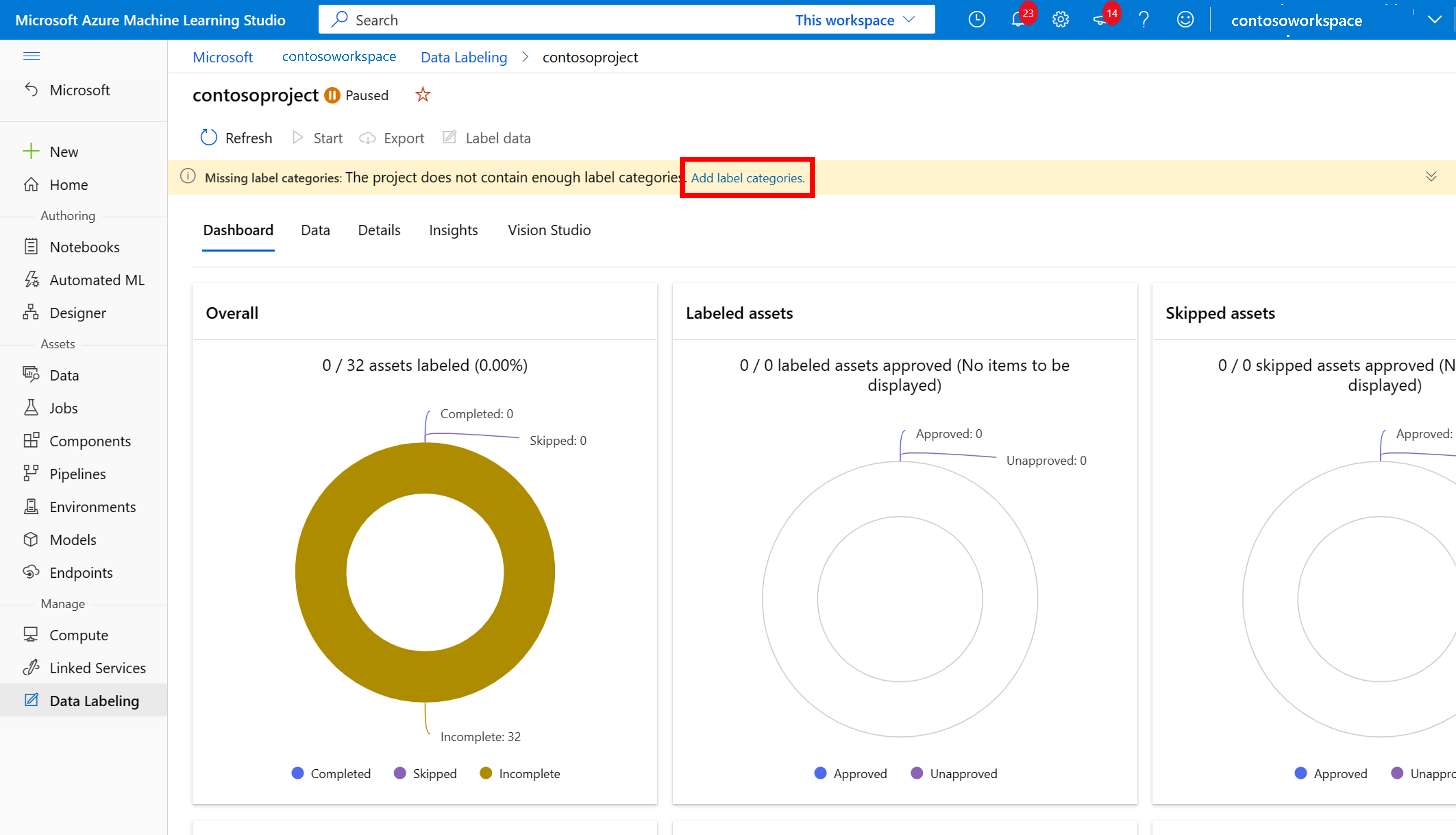
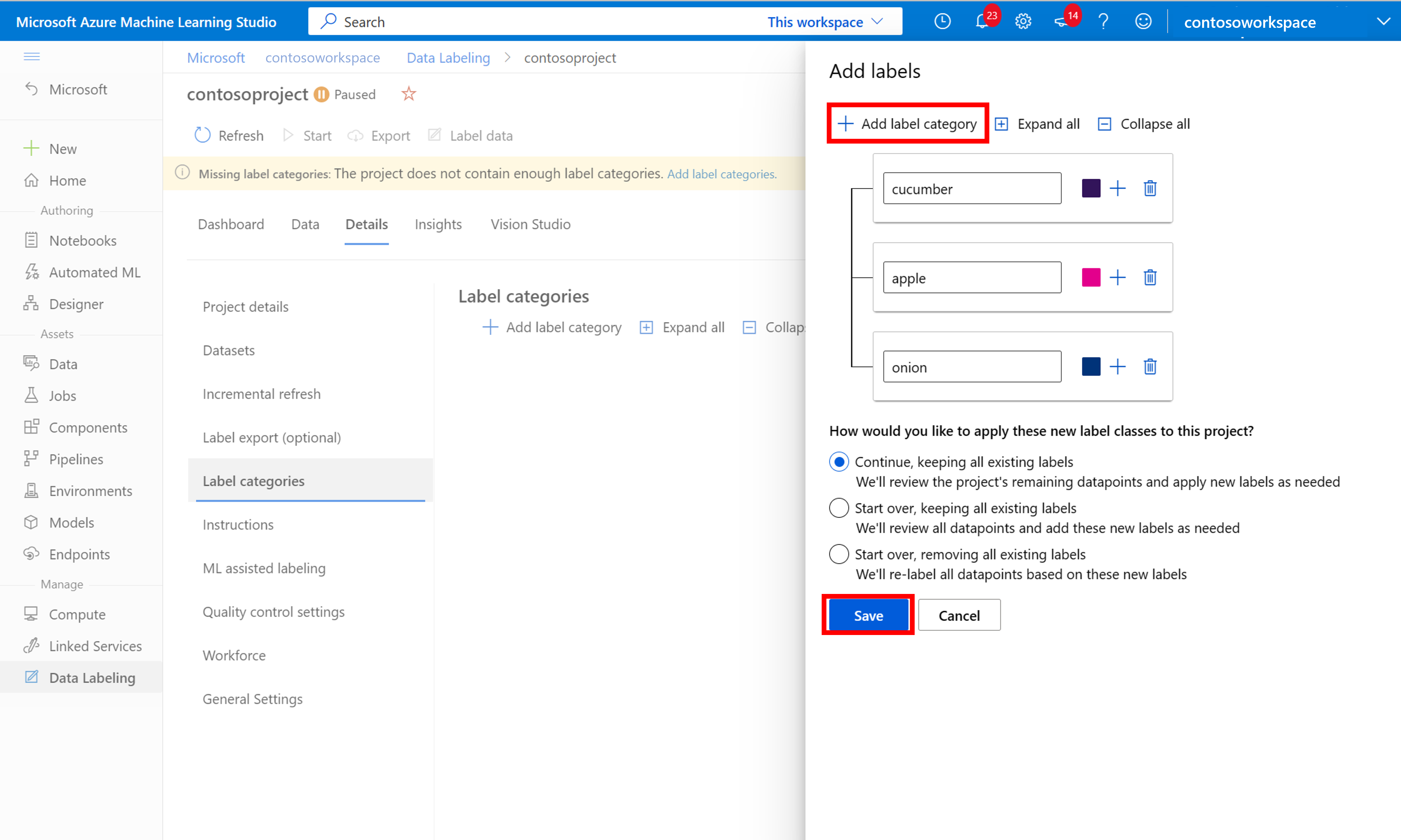
När du har lagt till alla klassetiketter sparar du dem, väljer Starta i projektet och väljer sedan Etikettdata överst.
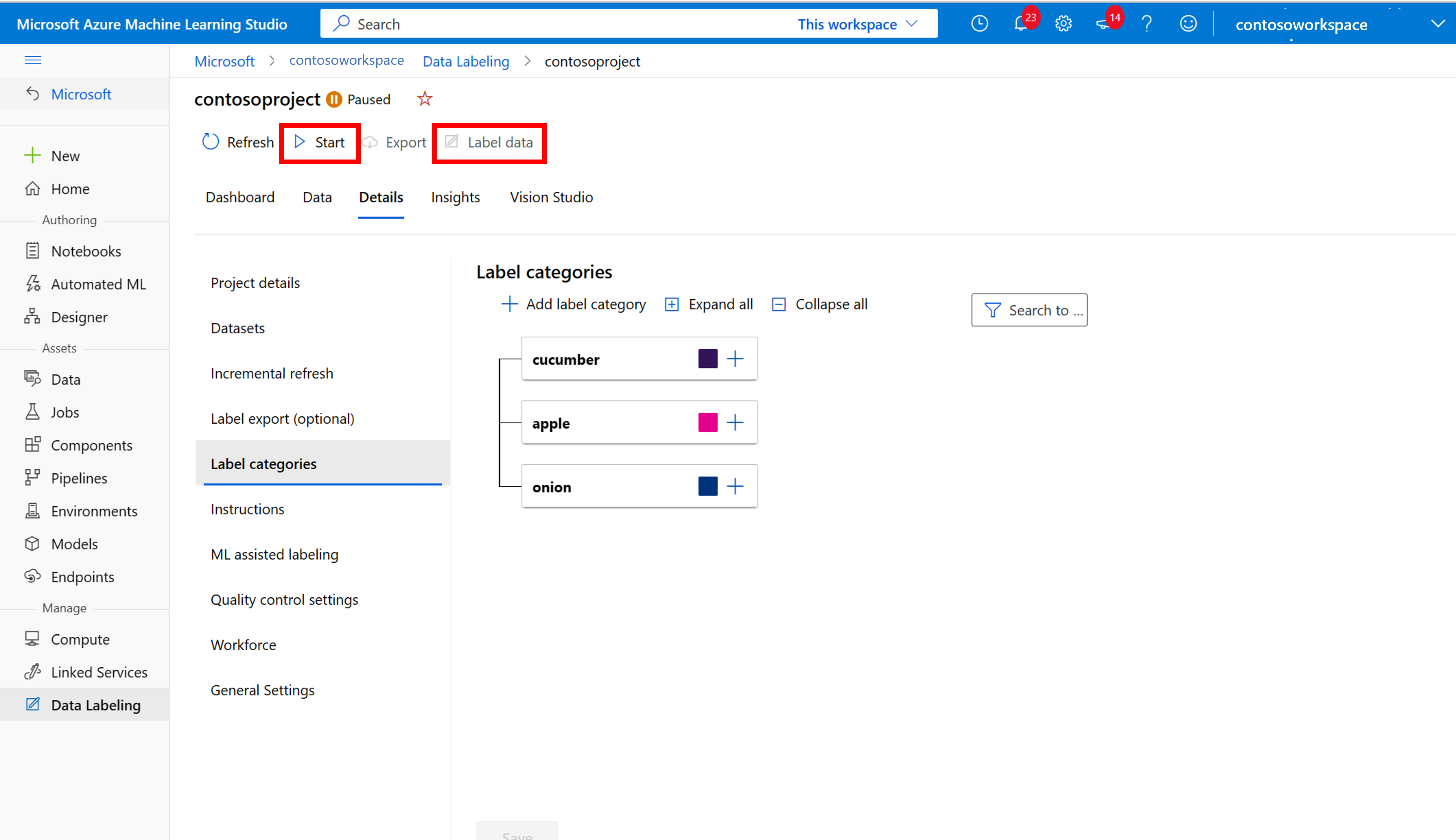
Märka träningsdata manuellt
Välj Starta etikettering och följ anvisningarna för att märka alla dina bilder. När du är klar går du tillbaka till fliken Vision Studio i webbläsaren.
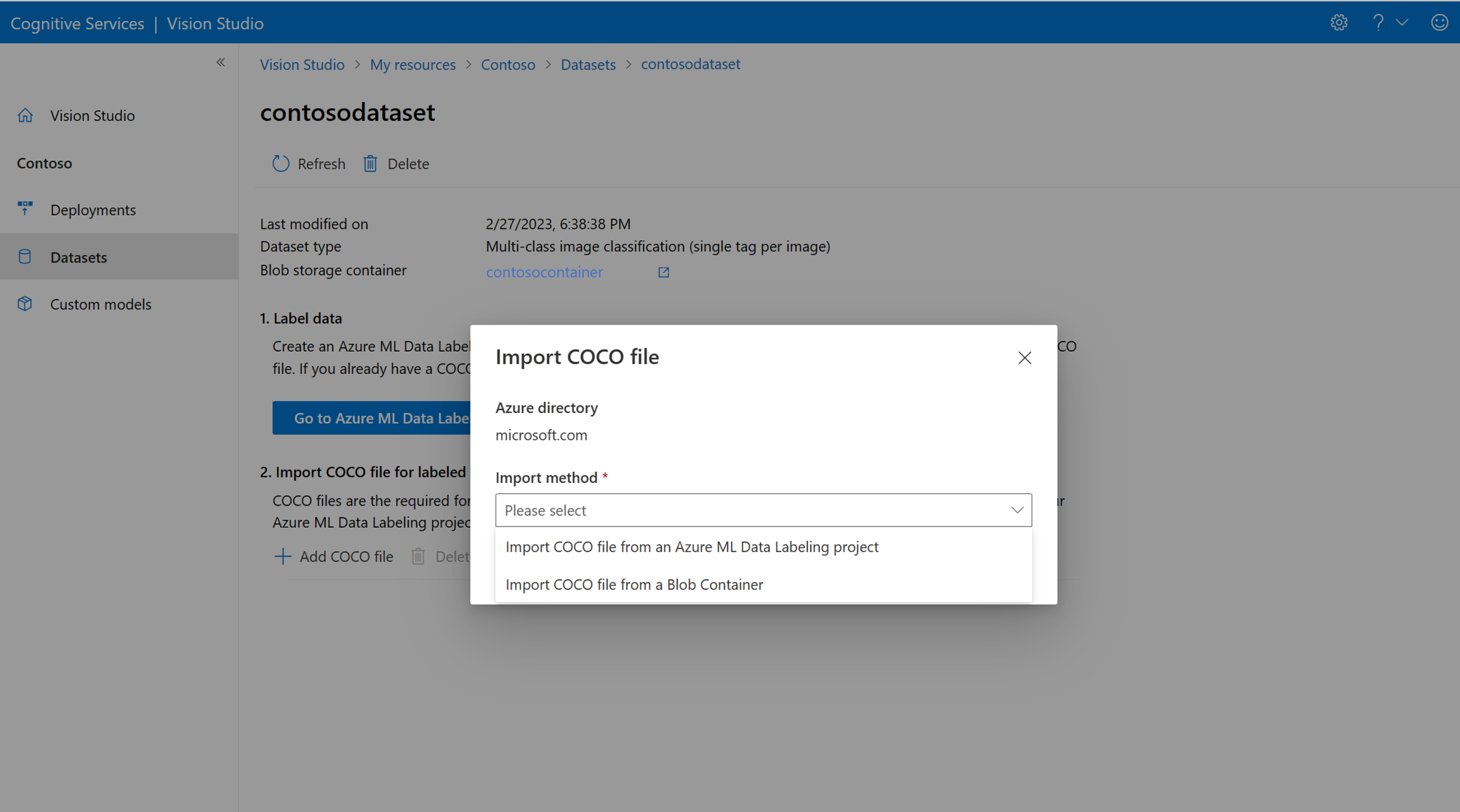
Välj nu Lägg till COCO-fil och välj sedan Importera COCO-fil från ett Azure ML Data Labeling-projekt. Detta importerar etiketterade data från Azure Machine Learning.
Coco-filen som du skapade lagras nu i Azure Storage-containern som du länkade till det här projektet. Du kan nu importera den till arbetsflödet för modellanpassning. Välj den i listrutan. När COCO-filen har importerats till datamängden kan datauppsättningen användas för att träna en modell.
Kommentar
Om du har en färdig COCO-fil som du vill importera går du till fliken Datauppsättningar och väljer Lägg till COCO-filer i den här datamängden. Du kan välja att lägga till en specifik COCO-fil från ett bloblagringskonto eller importera från Azure Machine Learning-etikettprojektet.
För närvarande löser Microsoft ett problem som gör att COCO-filimporten misslyckas med stora datauppsättningar när den initieras i Vision Studio. Om du vill träna med en stor datauppsättning rekommenderar vi att du använder REST-API:et i stället.
Om COCO-filer
COCO-filer är JSON-filer med specifika obligatoriska fält: "images", "annotations"och "categories". En COCO-exempelfil ser ut så här:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
REFERENS FÖR COCO-filfält
Om du genererar en egen COCO-fil från grunden kontrollerar du att alla obligatoriska fält är ifyllda med rätt information. Följande tabeller beskriver varje fält i en COCO-fil:
"bilder"
| Nyckel | Typ | Beskrivning | Obligatorisk? |
|---|---|---|---|
id |
integer | Unikt avbildnings-ID från 1 | Ja |
width |
integer | Bredd på bilden i bildpunkter | Ja |
height |
integer | Bildens höjd i bildpunkter | Ja |
file_name |
sträng | Ett unikt namn för avbildningen | Ja |
absolute_url eller coco_url |
sträng | Bildsökväg som en absolut URI till en blob i en blobcontainer. Vision-resursen måste ha behörighet att läsa anteckningsfilerna och alla refererade bildfiler. | Ja |
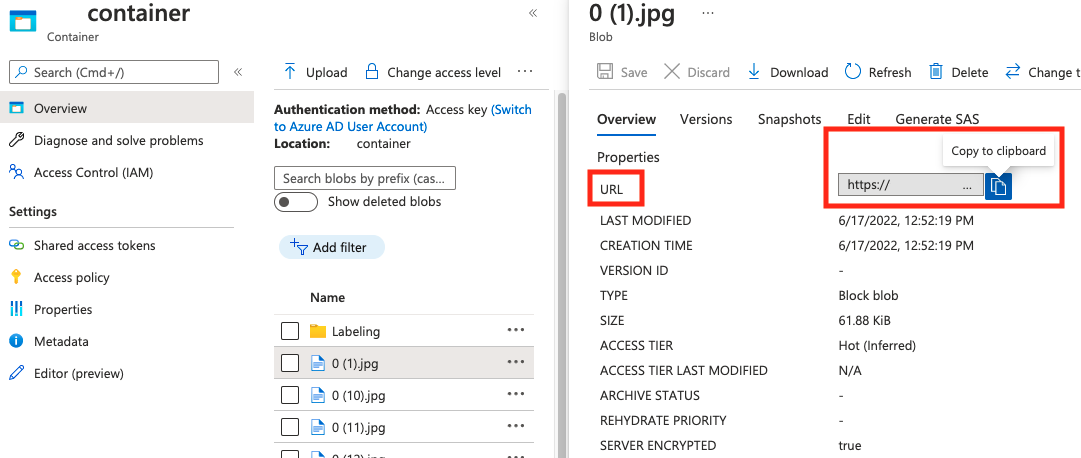
Värdet för absolute_url finns i blobcontainerns egenskaper:
"anteckningar"
| Nyckel | Typ | Beskrivning | Obligatorisk? |
|---|---|---|---|
id |
integer | ID för anteckningen | Ja |
category_id |
integer | ID för kategorin som definieras i categories avsnittet |
Ja |
image_id |
integer | ID för avbildningen | Ja |
area |
integer | Värdet för "Width" x "Height" (tredje och fjärde värdet för bbox) |
Nej |
bbox |
list[float] | Relativa koordinater för avgränsningsrutan (0 till 1), i ordningen "Vänster", "Överkant", "Bredd", "Höjd" | Ja |
"kategorier"
| Nyckel | Typ | Beskrivning | Obligatorisk? |
|---|---|---|---|
id |
integer | Unikt ID för varje kategori (etikettklass). Dessa bör finnas i avsnittet annotations . |
Ja |
name |
sträng | Namn på kategorin (etikettklass) | Ja |
VERIFIERING AV COCO-fil
Du kan använda vår Python-exempelkod för att kontrollera formatet på en COCO-fil.
Träna den anpassade modellen
Om du vill börja träna en modell med din COCO-fil går du till fliken Anpassade modeller och väljer Lägg till en ny modell. Ange ett namn på modellen och välj Image classification eller Object detection som modelltyp.
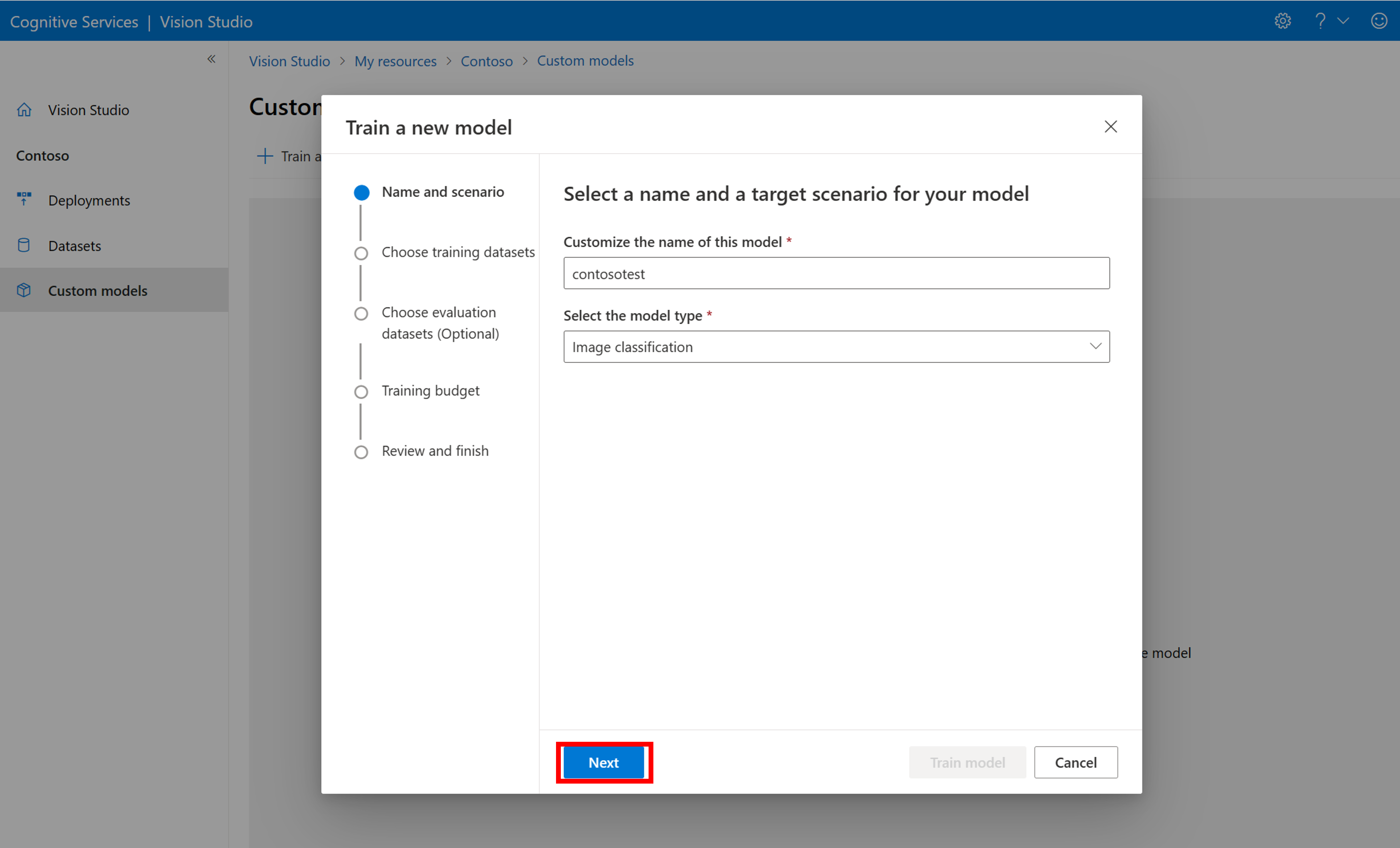
Välj din datauppsättning, som nu är associerad med COCO-filen som innehåller etiketteringsinformationen.
Välj sedan en tidsbudget och träna modellen. För små exempel kan du använda en 1 hour budget.
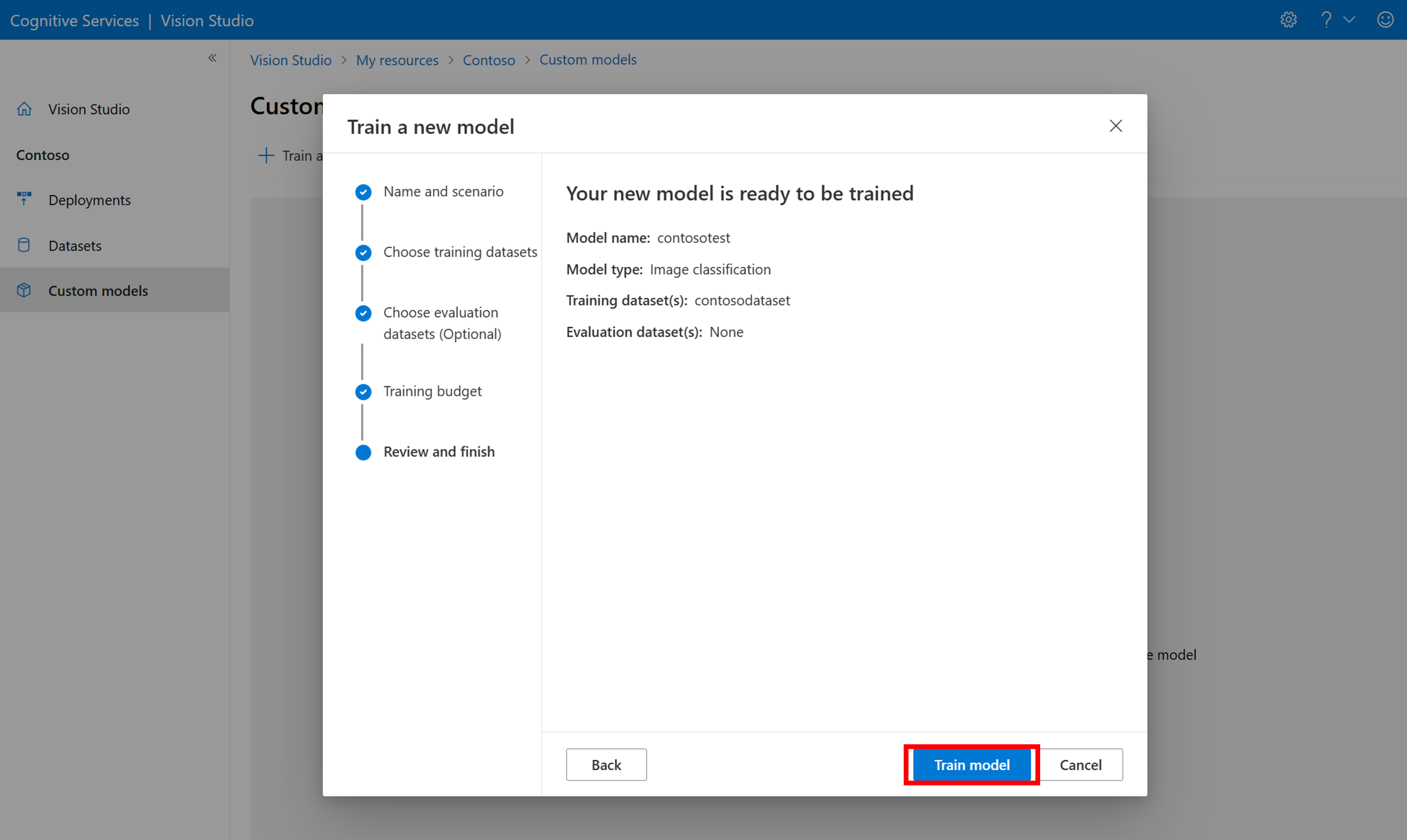
Det kan ta lite tid för träningen att slutföras. Image Analysis 4.0-modeller kan vara korrekta med endast en liten uppsättning träningsdata, men de tar längre tid att träna än tidigare modeller.
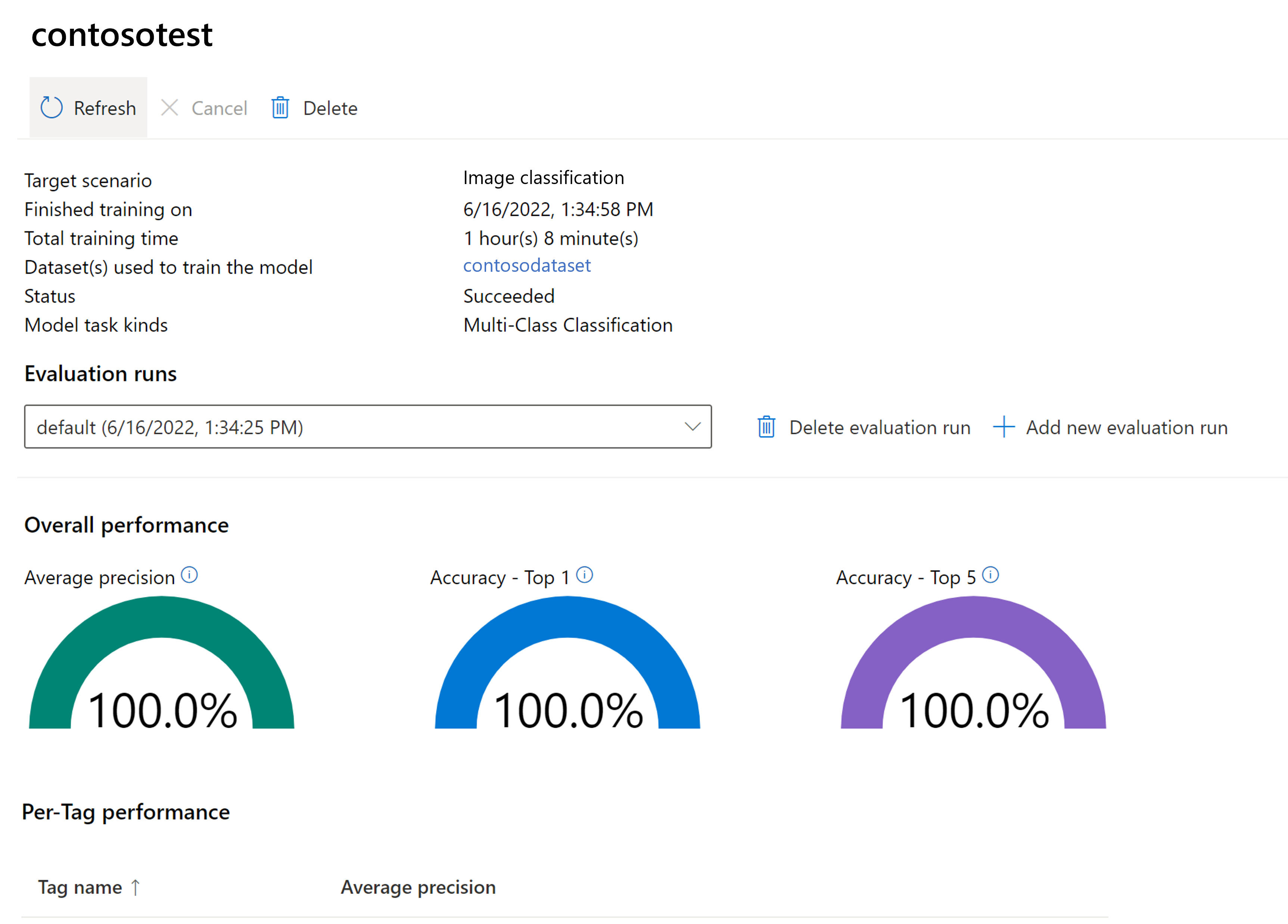
Utvärdera den tränade modellen
När träningen är klar kan du visa modellens prestandautvärdering. Följande mått används:
- Bildklassificering: Genomsnittlig precision, noggrannhet topp 1, noggrannhet topp 5
- Objektidentifiering: Genomsnittlig genomsnittlig precision @ 30, genomsnittlig genomsnittlig precision @ 50, genomsnittlig genomsnittlig precision @ 75
Om en utvärderingsuppsättning inte tillhandahålls när modellen tränas beräknas den rapporterade prestandan baserat på en del av träningsuppsättningen. Vi rekommenderar starkt att du använder en utvärderingsdatauppsättning (med samma process som ovan) för att få en tillförlitlig uppskattning av modellens prestanda.
Testa den anpassade modellen i Vision Studio
När du har skapat en anpassad modell kan du testa genom att välja knappen Prova på modellutvärderingsskärmen.
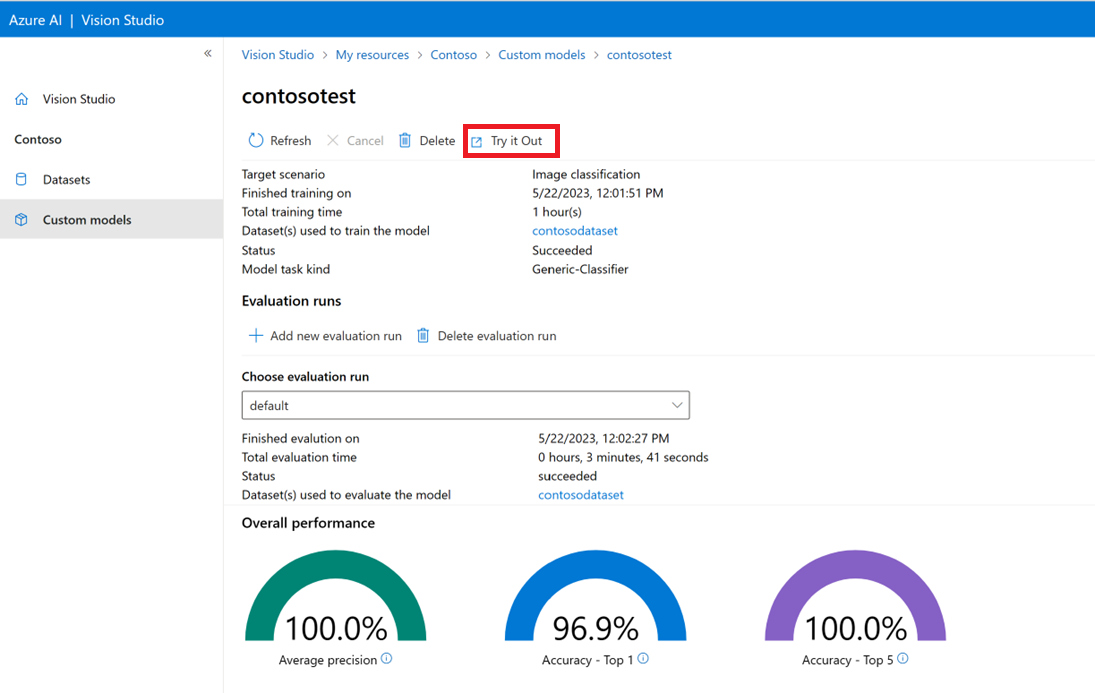
Detta tar dig till sidan Extrahera vanliga taggar från bilder . Välj din anpassade modell på den nedrullningsbara menyn och ladda upp en testbild.
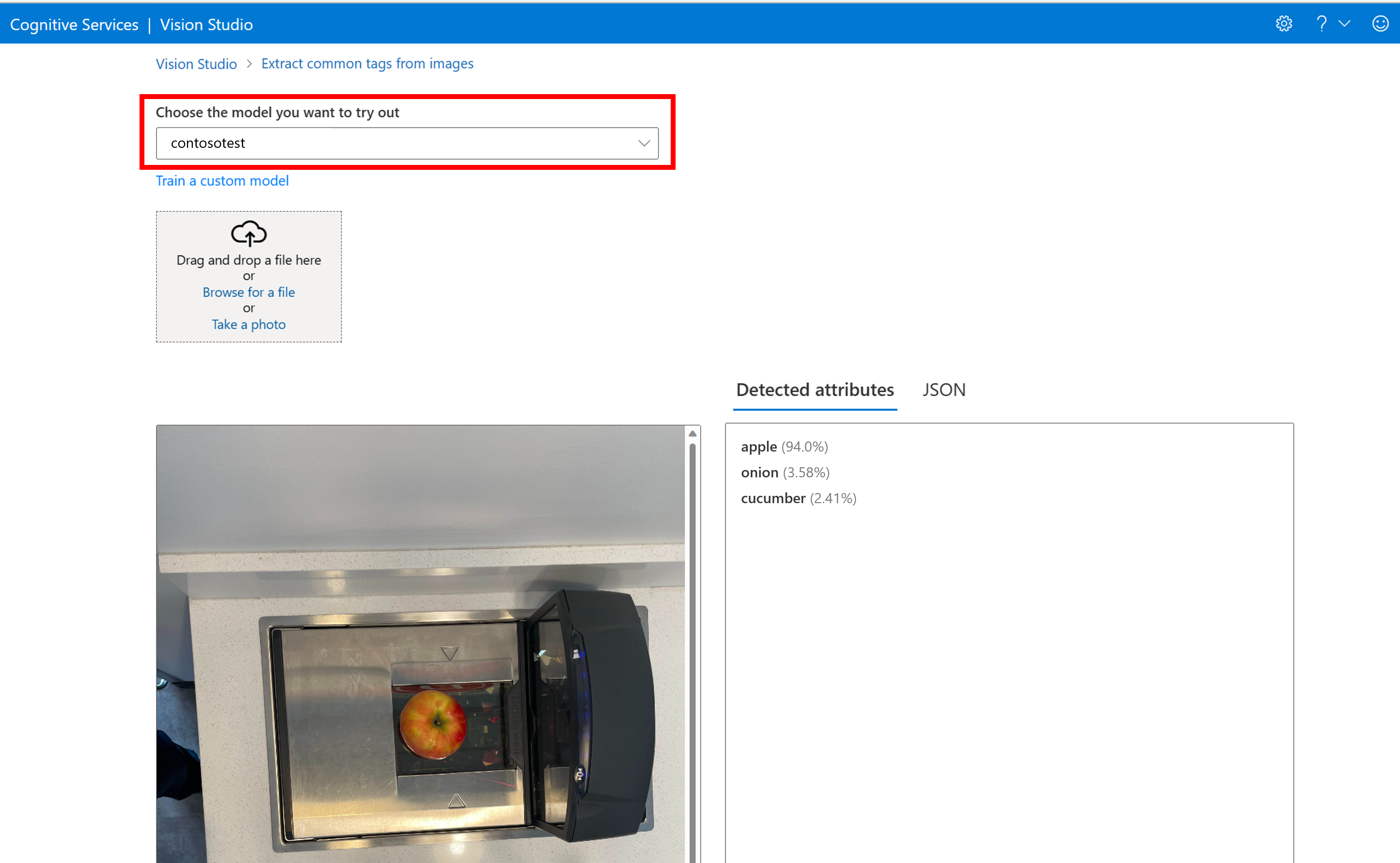
Förutsägelseresultatet visas i den högra kolumnen.
Relaterat innehåll
I den här guiden har du skapat och tränat en anpassad bildklassificeringsmodell med hjälp av bildanalys. Läs mer om API:et Analysera bild 4.0 så att du kan anropa din anpassade modell från ett program med HJÄLP av REST.
- Koncept för modellanpassning
- Anropa API:et Analysera bild