Data anses ofta vara den mest värdefulla delen av en lösning, eftersom de representerar din - och dina kunders - värdefulla affärsinformation. Därför är det viktigt att hantera dina data noggrant. När du planerar lagrings- eller datakomponenter för ett system med flera klienter måste du välja en metod för att dela eller isolera klientorganisationens data.
I den här artikeln ger vi vägledning om viktiga överväganden och krav som är viktiga för lösningsarkitekter när de beslutar om en metod för att lagra data i ett system med flera klienter. Sedan föreslår vi några vanliga mönster för att tillämpa flera klientorganisationer på lagrings- och datatjänster och vissa antimönster att undvika. Slutligen ger vi riktad vägledning för vissa specifika situationer.
Viktiga överväganden och krav
Det är viktigt att tänka på de metoder som du använder för lagrings- och datatjänster ur ett antal perspektiv, inklusive grundpelarna i Azure Well-Architected Framework.
Skala
När du arbetar med tjänster som lagrar dina data bör du tänka på antalet klienter du har och mängden data som du lagrar. Om du har ett litet antal klienter (till exempel fem eller färre) och du lagrar små mängder data för varje klientorganisation är det troligtvis ett slöseri med att planera en mycket skalbar datalagringsmetod eller att skapa en helt automatiserad metod för att hantera dina dataresurser. Men när du växer drar du allt större nytta av att ha en tydlig strategi för att skala dina data och lagringsresurser och tillämpa automatisering på deras hantering. När du har 50 klienter eller fler, eller om du planerar att nå den skalningsnivån, är det särskilt viktigt att utforma data och lagringsmetod, med skalning som ett viktigt övervägande.
Tänk på i vilken utsträckning du planerar att skala och planera tydligt arkitekturmetoden för datalagring för att uppfylla den skalningsnivån.
Prestandaöversägbarhet
Data- och lagringstjänster för flera klientorganisationer är särskilt känsliga för problemet Med bullriga grannar. Det är viktigt att överväga om dina klienter kan påverka varandras prestanda. Har dina klienter till exempel överlappande toppar i sina användningsmönster över tid? Använder alla dina kunder din lösning samtidigt varje dag, eller distribueras begäranden jämnt? Dessa faktorer påverkar den isoleringsnivå som du behöver utforma för, mängden resurser som du behöver etablera och i vilken grad resurser kan delas mellan klienter.
Det är viktigt att ta hänsyn till Azures resurs- och begärandekvoter som en del av det här beslutet. Anta till exempel att du distribuerar ett enda lagringskonto för att innehålla alla dina klientorganisationers data. Om du överskrider ett visst antal lagringsåtgärder per sekund avvisar Azure Storage programmets begäranden och alla dina klienter påverkas. Detta kallas begränsningsbeteende . Det är viktigt att du övervakar för begränsade begäranden. Mer information finns i Vägledning för återförsök för Azure-tjänster.
Dataisolering
När du utformar en lösning som innehåller datatjänster med flera klientorganisationer finns det vanligtvis olika alternativ och nivåer av dataisolering, var och en med sina egna fördelar och kompromisser. Till exempel:
- När du använder Azure Cosmos DB kan du distribuera separata containrar för varje klientorganisation och du kan dela databaser och konton mellan flera klienter. Du kan också överväga att distribuera olika databaser eller till och med konton för varje klientorganisation, beroende på vilken isoleringsnivå som krävs.
- När du använder Azure Storage för blobdata kan du distribuera separata blobcontainrar för varje klientorganisation eller distribuera separata lagringskonton.
- När du använder Azure SQL kan du använda separata tabeller i delade databaser eller distribuera separata databaser eller servrar för varje klientorganisation.
- I alla Azure-tjänster kan du överväga att distribuera resurser i en enda delad Azure-prenumeration, eller så kan du använda flera Azure-prenumerationer – kanske till och med en per klientorganisation.
Det finns ingen enskild lösning som fungerar för varje situation. Vilket alternativ du väljer beror på ett antal faktorer och kraven för dina klienter. Om dina klienter till exempel behöver uppfylla specifika efterlevnads- eller regelstandarder kan du behöva tillämpa en högre nivå av isolering. På samma sätt kan du ha kommersiella krav för att fysiskt isolera dina kunders data, eller så kan du behöva framtvinga isolering för att undvika problem med bullriga grannar. Om klientorganisationer behöver använda sina egna krypteringsnycklar har de dessutom individuella principer för säkerhetskopiering och återställning, eller om de behöver lagra sina data på olika geografiska platser, kan du behöva isolera dem från andra klienter eller gruppera dem med klienter som har liknande principer.
Komplexiteten i implementeringen
Det är viktigt att tänka på komplexiteten i implementeringen. Det är bra att hålla arkitekturen så enkel som möjligt, samtidigt som du uppfyller dina krav. Undvik att engagera dig i en arkitektur som blir allt mer komplex när du skalar, eller en arkitektur som du inte har resurser eller expertis för att utveckla och underhålla.
Om lösningen inte behöver skalas till ett stort antal klienter, eller om du inte har problem med prestanda eller dataisolering, är det på samma sätt bättre att hålla lösningen enkel och undvika att lägga till onödig komplexitet.
Ett särskilt problem för datalösningar med flera klientorganisationer är den anpassningsnivå som du stöder. Kan till exempel en klientorganisation utöka din datamodell eller tillämpa anpassade dataregler? Se till att du utformar för det här kravet i förväg. Undvik att förgrena eller tillhandahålla anpassad infrastruktur för enskilda klientorganisationer. Anpassad infrastruktur hämmar din förmåga att skala, testa din lösning och distribuera uppdateringar. Överväg i stället att använda funktionsflaggor och andra former av klientkonfiguration.
Komplexiteten i hantering och åtgärder
Fundera på hur du planerar att använda din lösning och hur din fleraktiveringsmetod påverkar dina åtgärder och processer. Till exempel:
- Hantering: Överväg hanteringsåtgärder mellan klientorganisationer, till exempel regelbundna underhållsaktiviteter. Hur initierar och övervakar du åtgärderna för varje klientorganisation om du använder flera konton, servrar eller databaser?
- Övervakning och mätning: Om du övervakar eller mäter dina klienter bör du överväga hur din lösning rapporterar mått och om de enkelt kan länkas till den klientorganisation som utlöste begäran.
- Rapportering: Rapportering av data från isolerade klienter kan kräva att varje klient publicerar data till ett centraliserat informationslager, i stället för att köra frågor på varje databas individuellt och sedan aggregera resultaten.
- Schemauppdateringar: Om du använder en databas som tillämpar ett schema ska du planera hur du ska distribuera schemauppdateringar i din egendom. Överväg hur ditt program vet vilken schemaversion som ska användas för en specifik klients databasfrågor.
- Krav: Överväg dina klientorganisationers krav på hög tillgänglighet (till exempel serviceavtal på drifttid eller serviceavtal) och krav på haveriberedskap (till exempel mål för återställningstid eller mål för återställningspunkter och mål för återställningspunkter eller RPM). Kommer du att kunna uppfylla varje klientorganisations krav om klientorganisationen har olika förväntningar?
- Migrering: Hur migrerar du klienter om de behöver flytta till en annan typ av tjänst, en annan distribution eller en annan region?
Kostnad
Ju högre densitet klientorganisationer har i distributionsinfrastrukturen, desto lägre blir kostnaden för att etablera infrastrukturen. Delad infrastruktur ökar dock sannolikheten för problem som problem med den bullriga grannen, så tänk noga på kompromisserna.
Metoder och mönster att tänka på
Flera designmönster från Azure Architecture Center är relevanta för lagrings- och datatjänster med flera klientorganisationer. Du kan välja att följa ett mönster konsekvent. Eller så kan du överväga att blanda och matcha mönster. Du kan till exempel använda en databas med flera klienter för de flesta av dina klienter, men distribuera stämplar med en enda klientorganisation för klienter som betalar mer eller som har ovanliga krav. På samma sätt är det ofta en bra idé att skala med hjälp av distributionsstämplar, även när du använder en databas med flera klientorganisationer eller fragmenterade databaser inom en stämpel.
Mönster för distributionsstämplar
Mer information om hur mönstret Distributionsstämplar kan användas för att stödja en lösning med flera klientorganisationer finns i Översikt.
Delade databaser och fillager för flera klientorganisationer
Du kan överväga att distribuera en delad databas, ett lagringskonto eller en filresurs för flera klienter och dela den i alla dina klienter.
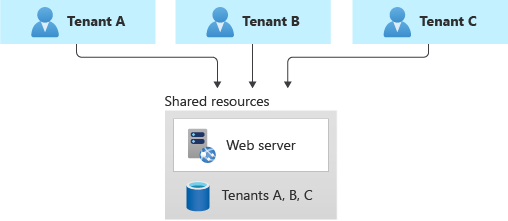
Den här metoden ger den högsta tätheten av klienter till infrastruktur, så den tenderar att komma till lägsta kostnad för alla metoder. Det minskar också ofta hanteringskostnaderna eftersom det finns en enda databas eller resurs att hantera, säkerhetskopiera och skydda.
Men när du arbetar med delad infrastruktur finns det flera varningar att tänka på:
- Skalningsgränser: När du förlitar dig på en enskild resurs bör du överväga den resursens skalning och gränser som stöds. Till exempel blir den maximala storleken på en databas eller fillagring, eller de maximala dataflödesgränserna, så småningom en hård blockerare, om din arkitektur förlitar sig på en enda databas. Överväg noggrant den maximala skalning du behöver uppnå och jämför den med dina nuvarande och framtida gränser innan du väljer det här mönstret.
- Bullriga grannar: Problemet med den bullriga grannen kan bli en faktor, särskilt om du har klienter som är särskilt upptagna eller genererar högre arbetsbelastningar än andra. Överväg att använda begränsningsmönstret eller mönstret Hastighetsbegränsning för att minimera dessa effekter.
- Övervaka varje klientorganisation: Du kan ha svårt att övervaka aktiviteten och mäta förbrukningen för en enda klientorganisation. Vissa tjänster, till exempel Azure Cosmos DB, tillhandahåller rapportering om resursanvändning för varje begäran, så att den här informationen kan spåras för att mäta förbrukningen för varje klientorganisation. Andra tjänster ger inte samma detaljnivå. Till exempel är Azure Files-måtten för filkapacitet tillgängliga per filresursdimension och endast när du använder Premium-resurser. Standardnivån tillhandahåller dock endast måtten på lagringskontonivå.
- Klientorganisationskrav: Klientorganisationer kan ha olika krav för säkerhet, säkerhetskopiering, tillgänglighet eller lagringsplats. Om dessa inte matchar konfigurationen för den enskilda resursen kanske du inte kan hantera dem.
- Schemaanpassning: När du arbetar med en relationsdatabas eller en annan situation där schemat för data är viktigt är schemaanpassning på klientnivå svårt.
Mönster för horisontell partitionering
Sharding-mönstret omfattar distribution av flera separata databaser, så kallade shards, som var och en innehåller en eller flera klientorganisationers data. Till skillnad från distributionsstämplar innebär shards inte att hela infrastrukturen dupliceras. Du kan fragmentera databaser utan att även duplicera eller partitionera annan infrastruktur i din lösning.
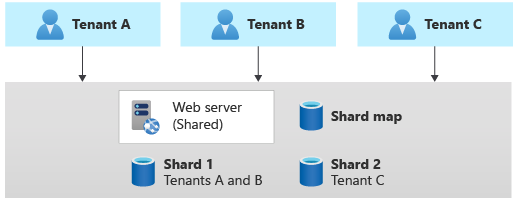
Horisontell partitionering är nära relaterad till partitionering, och termerna används ofta omväxlande. Överväg vägledningen för horisontell, lodrät och funktionell datapartitionering.
Horisontell partitioneringsmönstret kan skalas till ett mycket stort antal klienter. Beroende på din arbetsbelastning kan du dessutom uppnå en hög densitet av klienter till shards, så att kostnaden kan vara attraktiv. Horisontell partitioneringsmönstret kan också användas för att hantera Azure-prenumerations- och tjänstkvoter, gränser och begränsningar.
Vissa datalager, till exempel Azure Cosmos DB, ger inbyggt stöd för horisontell partitionering eller partitionering. När du arbetar med andra lösningar, till exempel Azure SQL, kan det vara mer komplext att skapa en infrastruktur för horisontell partitionering och dirigera begäranden till rätt fragment för en viss klientorganisation.
Horisontell partitionering gör det också svårt att stödja konfigurationsskillnader på klientorganisationsnivå och att göra det möjligt för kunder att tillhandahålla sina egna krypteringsnycklar.
Multitenant-app med dedikerade databaser för varje klientorganisation
En annan vanlig metod är att distribuera ett enda program med flera klienter, med dedikerade databaser för varje klientorganisation.
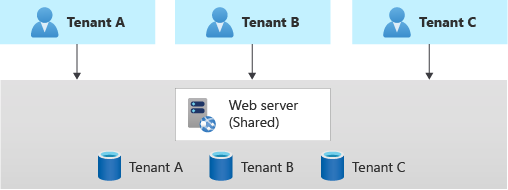
I den här modellen är varje klientorganisations data isolerade från de andra, och du kanske kan stödja viss anpassning för varje klientorganisation.
Eftersom du etablerar dedikerade dataresurser för varje klientorganisation kan kostnaden för den här metoden vara högre än delade värdmodeller. Azure tillhandahåller dock flera alternativ som du kan överväga för att dela kostnaden för att hantera enskilda dataresurser mellan flera klientorganisationer. När du till exempel arbetar med Azure SQL kan du överväga elastiska pooler. För Azure Cosmos DB kan du etablera dataflöde för en databas och dataflödet delas mellan containrarna i databasen, även om den här metoden inte är lämplig när du behöver garanterad prestanda för varje container.
I den här metoden, eftersom endast datakomponenterna distribueras individuellt för varje klientorganisation, kan du förmodligen uppnå hög densitet för de andra komponenterna i din lösning och minska kostnaden för dessa komponenter.
Det är viktigt att använda automatiserade distributionsmetoder när du etablerar databaser för varje klientorganisation.
Geode-mönster
Geode-mönstret är specifikt utformat för geografiskt distribuerade lösningar, inklusive lösningar för flera klientorganisationer. Den stöder hög belastning och hög återhämtningsnivå. Om du implementerar Geode-mönstret måste datanivån kunna replikera data mellan geografiska regioner och ha stöd för skrivningar med flera geografiska områden.
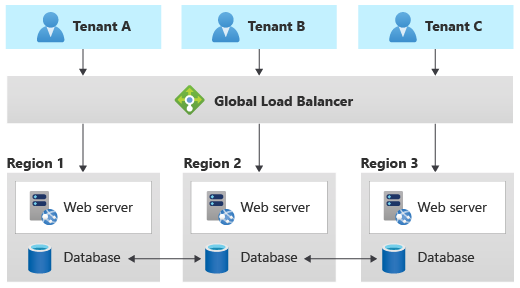
Azure Cosmos DB tillhandahåller skrivningar i flera regioner för att stödja det här mönstret, och Cassandra stöder kluster i flera regioner. Andra datatjänster kan vanligtvis inte stödja det här mönstret, utan betydande anpassning.
Antimönster att undvika
När du skapar datatjänster för flera klientorganisationer är det viktigt att undvika situationer som hämmar din förmåga att skala.
För relationsdatabaser omfattar följande:
- Tabellbaserad isolering. När du arbetar i en enskild databas bör du undvika att skapa enskilda tabeller för varje klientorganisation. En enskild databas kommer inte att kunna stödja ett stort antal klienter när du använder den här metoden, och det blir allt svårare att fråga, hantera och uppdatera data. Överväg i stället att använda en enda uppsättning multitenanttabeller med en kolumn för klientidentifierare. Du kan också använda något av de mönster som beskrivs ovan för att distribuera separata databaser för varje klientorganisation.
- Anpassning av klientorganisation på kolumnnivå. Undvik schemauppdateringar som endast gäller för en enskild klientorganisation. Anta till exempel att du har en enda databas med flera klientorganisationer. Undvik att lägga till en ny kolumn för att uppfylla en specifik klientorganisations krav. Det kan vara acceptabelt för ett litet antal anpassningar, men detta blir snabbt ohanterligt när du har ett stort antal anpassningar att tänka på. Överväg i stället att ändra datamodellen för att spåra anpassade data för varje klientorganisation i en dedikerad tabell.
- Manuella schemaändringar. Undvik att uppdatera databasschemat manuellt, även om du bara har en enda delad databas. Det är enkelt att förlora kontrollen över de uppdateringar som du har tillämpat, och om du behöver skala ut till fler databaser är det svårt att identifiera rätt schema som ska tillämpas. Skapa i stället en automatiserad pipeline för att distribuera dina schemaändringar och använda den konsekvent. Spåra schemaversionen som används för varje klientorganisation i en dedikerad databas eller uppslagstabell.
- Versionsberoenden. Undvik att programmet är beroende av en enda version av databasschemat. När du skalar kan du behöva tillämpa schemauppdateringar vid olika tidpunkter för olika klientorganisationer. Kontrollera i stället att programversionen är bakåtkompatibel med minst en schemaversion och undvik destruktiva schemauppdateringar.
Databaser
Det finns vissa funktioner som kan vara användbara för flera klientorganisationer. Dessa är dock inte tillgängliga i alla databastjänster. Överväg om du behöver dessa när du bestämmer dig för vilken tjänst du ska använda för ditt scenario:
- Säkerhet på radnivå kan ge säkerhetsisolering för specifika klientorganisationers data i en delad databas med flera klienter. Den här funktionen är tillgänglig i Azure SQL och Postgres Flex, men den är inte tillgänglig i andra databaser, till exempel MySQL eller Azure Cosmos DB.
- Kryptering på klientnivå kan krävas för att stödja klienter som tillhandahåller sina egna krypteringsnycklar för sina data. Den här funktionen är tillgänglig i Azure SQL som en del av Always Encrypted. Azure Cosmos DB tillhandahåller kundhanterade nycklar på kontonivå och har även stöd för Always Encrypted.
- Resurspooler ger möjlighet att dela resurser och kostnader mellan flera databaser eller containrar. Den här funktionen är tillgänglig i Azure SQL:s elastiska pooler och hanterade instanser och i Azure Cosmos DB-databasens dataflöde, även om varje alternativ har begränsningar som du bör känna till.
- Partitionering och partitionering har starkare inbyggt stöd i vissa tjänster än andra. Den här funktionen är tillgänglig i Azure Cosmos DB med hjälp av dess logiska och fysiska partitionering. Även om Azure SQL inte har inbyggt stöd för horisontell partitionering, finns det horisontella verktyg som stöder den här typen av arkitektur.
När du arbetar med relationsdatabaser eller andra schemabaserade databaser bör du dessutom överväga var schemauppgraderingsprocessen ska utlösas när du underhåller en databasflotta. I en liten databasegendom kan du överväga att använda en distributionspipeline för att distribuera schemaändringar. När antalet databaser ökar kan det vara bättre för programnivån att identifiera schemaversionen för en specifik databas och initiera uppgraderingsprocessen.
Fil- och bloblagring
Överväg den metod som du använder för att isolera data i ett lagringskonto. Du kan till exempel distribuera separata lagringskonton för varje klientorganisation eller dela lagringskonton och distribuera enskilda containrar. Du kan också skapa delade blobcontainrar och sedan kan du använda blobsökvägen för att separera data för varje klientorganisation. Överväg begränsningar och kvoter för Azure-prenumerationer och planera din tillväxt noggrant för att säkerställa att dina Azure-resurser skalas för att stödja dina framtida behov.
Om du använder delade containrar ska du planera din autentiserings- och auktoriseringsstrategi noggrant för att säkerställa att klientorganisationer inte kan komma åt varandras data. Tänk på Valet Key-mönstret när du ger klienter åtkomst till Azure Storage-resurser.
Kostnadsfördelning
Fundera på hur du ska mäta förbrukning och allokera kostnader till klienter för användning av delade datatjänster. När det är möjligt bör du sträva efter att använda inbyggda mått i stället för att beräkna dina egna. Med delad infrastruktur blir det dock svårt att dela telemetri för enskilda klienter och du kan behöva överväga anpassad avläsning på programnivå.
I allmänhet tillhandahåller molnbaserade tjänster, som Azure Cosmos DB och Azure Blob Storage, mer detaljerade mått för att spåra och modellera användningen för en specifik klientorganisation. Azure Cosmos DB tillhandahåller till exempel det förbrukade dataflödet för varje begäran och svar.
Deltagare
Den här artikeln underhålls av Microsoft. Det har ursprungligen skrivits av följande medarbetare.
Huvudförfattare:
- John Downs | Huvudprogramtekniker
Övriga medarbetare:
- Paul Burpo | Huvudkundtekniker, FastTrack för Azure
- Daniel Scott-Raynsford | Partnerteknikstrateg
- Arsen Vladimirskiy | Huvudkundtekniker, FastTrack för Azure
Om du vill se icke-offentliga LinkedIn-profiler loggar du in på LinkedIn.
Nästa steg
Mer information om flera klientorganisationer och specifika Azure-tjänster finns i: