Övervaka Prestanda för Microsoft Azure SQL Database med dynamiska hanteringsvyer
Gäller för:![]() Azure SQL Database
Azure SQL Database
Med Microsoft Azure SQL Database kan en delmängd av dynamiska hanteringsvyer diagnostisera prestandaproblem som kan orsakas av blockerade eller långvariga frågor, resursflaskhalsar, dåliga frågeplaner med mera.
Den här artikeln innehåller information om hur du identifierar vanliga prestandaproblem genom att köra frågor mot dynamiska hanteringsvyer via T-SQL. Du kan använda valfritt frågeverktyg, till exempel:
- SQL-frågeredigeraren i Azure-portalen
- SQL Server Management Studio (SSMS)
- Azure Data Studio
Behörigheter
I Azure SQL Database, beroende på beräkningsstorlek och distributionsalternativ, kan frågor mot en DMV kräva antingen BEHÖRIGHETEN VISA DATABASTILLSTÅND eller VISA SERVERTILLSTÅND. Den senare behörigheten kan beviljas via medlemskap i serverrollen ##MS_ServerStateReader## .
Om du vill ge behörigheten VIEW DATABASE STATE till en specifik databasanvändare kör du följande fråga som ett exempel:
GRANT VIEW DATABASE STATE TO database_user;
Om du vill bevilja medlemskap till serverrollen ##MS_ServerStateReader## till en inloggning för den logiska servern i Azure ansluter du till master databasen och kör sedan följande fråga som ett exempel:
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login];
I en instans av SQL Server och i Azure SQL Managed Instance returnerar dynamiska hanteringsvyer servertillståndsinformation. I Azure SQL Database returnerar de endast information om din aktuella logiska databas.
Identifiera problem med processorprestanda
Om CPU-förbrukningen är över 80 % under längre tidsperioder bör du överväga följande felsökningssteg om cpu-problemet inträffar nu eller har inträffat tidigare.
Cpu-problemet inträffar nu
Om problemet uppstår just nu finns det två möjliga scenarier:
Många enskilda frågor som kumulativt förbrukar hög CPU
Använd följande fråga för att identifiera de viktigaste fråge-hashvärdena:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--'; SELECT TOP 10 GETDATE() runtime, * FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text" FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats GROUP BY query_hash) AS t ORDER BY Total_Request_Cpu_Time_Ms DESC;
Tidskrävande frågor som använder processorn körs fortfarande
Använd följande fråga för att identifiera dessa frågor:
PRINT '--top 10 Active CPU Consuming Queries by sessions--'; SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY cpu_time DESC; GO
Cpu-problemet inträffade tidigare
Om problemet har uppstått tidigare och du vill göra rotorsaksanalys använder du Query Store. Användare med databasåtkomst kan använda T-SQL för att köra frågor mot Query Store-data. Standardkonfigurationer för Query Store använder en kornighet på 1 timme.
Använd följande fråga för att titta på aktivitet för frågor med hög CPU-användning. Den här frågan returnerar de 15 mest processorkrävande frågorna. Kom ihåg att ändra
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE():-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;När du har identifierat de problematiska frågorna är det dags att justera dessa frågor för att minska CPU-användningen. Om du inte har tid att justera frågorna kan du också välja att uppgradera databasens SLO för att lösa problemet.
Mer information om hur du hanterar processorprestandaproblem i Azure SQL Database finns i Diagnostisera och felsöka hög CPU i Azure SQL Database.
Identifiera problem med I/O-prestanda
När du identifierar prestandaproblem med indata/utdata för lagring (I/O) är de vanligaste väntetyperna som är associerade med I/O-problem:
PAGEIOLATCH_*För I/O-problem med datafiler (inklusive
PAGEIOLATCH_SH,PAGEIOLATCH_EX,PAGEIOLATCH_UP). Om namnet på väntetypen har I/O i sig pekar det på ett I/O-problem. Om det inte finns någon I/O i väntenamnet för sidspärren pekar det på en annan typ av problem (till exempeltempdbkonkurrens).WRITE_LOGFör I/O-problem med transaktionsloggar.
Om I/O-problemet inträffar just nu
Använd sys.dm_exec_requests eller sys.dm_os_waiting_tasks för att se wait_type och wait_time.
Identifiera data och logga I/O-användning
Använd följande fråga för att identifiera data och logga I/O-användning. Om data eller logg-I/O är över 80 %, innebär det att användarna har använt tillgänglig I/O för Azure SQL Database-tjänstnivån.
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'CPU Utilization In % of Limit' = rs.avg_cpu_percent
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
, 'Memory Usage In % of Limit' = rs.avg_memory_usage_percent
, 'In-Memory OLTP Storage in % of Limit' = rs.xtp_storage_percent
, 'Concurrent Worker Threads in % of Limit' = rs.max_worker_percent
, 'Concurrent Sessions in % of Limit' = rs.max_session_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
Fler exempel med hjälp av sys.dm_db_resource_statsfinns i avsnittet Övervaka resursanvändning senare i den här artikeln.
Om I/O-gränsen har nåtts har du två alternativ:
- Uppgradera beräkningsstorleken eller tjänstnivån
- Identifiera och finjustera de frågor som förbrukar mest I/O.
Visa buffertrelaterad I/O med hjälp av Query Store
För alternativ 2 kan du använda följande fråga mot Query Store för buffertrelaterad I/O för att visa de senaste två timmarna av spårad aktivitet:
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
Visa totalt antal logg-I/O för WRITELOG-väntetider
Om väntetypen är WRITELOGanvänder du följande fråga för att visa total logg-I/O efter -instruktion:
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
Identifiera problem med tempdb-prestanda
När du identifierar I/O-prestandaproblem är de vanligaste väntetyperna som är associerade med tempdb problem (inte PAGEIOLATCH_*).PAGELATCH_* Väntetider betyder dock PAGELATCH_* inte alltid att du har tempdb konkurrens. Det kan också bero på konkurrens om en datasida med användarobjekt på grund av konkurrerande begäranden som görs mot samma datasida. Om du vill bekräfta tempdb konkurrensen ytterligare använder du sys.dm_exec_requests för att bekräfta att wait_resource värdet börjar med 2:x:y där 2 är tempdb databas-ID, x är fil-ID och y är sid-ID.
För tempdb konkurrens är en vanlig metod att minska eller skriva om programkod som förlitar sig på tempdb. Vanliga tempdb användningsområden är:
- Temporära tabeller
- Tabellvariabler
- Tabellvärdesparametrar
- Användning av versionsarkiv (associerad med långvariga transaktioner)
- Frågor som har frågeplaner som använder sorteringar, hash-kopplingar och buffertar
Mer information finns i tempdb i Azure SQL.
De vanligaste frågorna som använder tabellvariabler och temporära tabeller
Använd följande fråga för att identifiera de vanligaste frågorna som använder tabellvariabler och temporära tabeller:
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
Identifiera tidskrävande transaktioner
Använd följande fråga för att identifiera långvariga transaktioner. Tidskrävande transaktioner förhindrar rensning av beständiga versionslager (PVS). Mer information finns i Felsöka accelererad databasåterställning.
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
Identifiera problem med att bevilja vänteprestanda för minne
Om din högsta väntetyp är RESOURCE_SEMAPHORE och du inte har problem med hög CPU-användning kan du ha problem med att bevilja minne.
Ta reda på om en RESOURCE_SEMAPHORE väntetid är en toppvänte
Använd följande fråga för att avgöra om en RESOURCE_SEMAPHORE väntetid är en toppvänta. Också vägledande skulle vara en stigande väntetid rangordning i RESOURCE_SEMAPHORE modern historia. Mer information om hur du felsöker problem med att bevilja minnestilldelning finns i Felsöka problem med långsamma prestanda eller minnesbrist som orsakas av minnesbidrag i SQL Server.
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
Identifiera höga minneskrävande instruktioner
Om det uppstår minnesfel i Azure SQL Database läser du sys.dm_os_out_of_memory_events. Mer information finns i Felsöka minnesfel med Azure SQL Database.
Ändra först skriptet nedan för att uppdatera relevanta värden för start_time och end_time. Kör sedan följande fråga för att identifiera höga minneskrävande instruktioner:
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
GO
;WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
Identifiera de 10 främsta aktiva minnestilldelningarna
Använd följande fråga för att identifiera de 10 främsta aktiva minnestilldelningarna:
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
Övervaka anslutningar
Du kan använda vyn sys.dm_exec_connections för att hämta information om anslutningar som upprättats till en specifik databas eller elastisk pool och information om varje anslutning. Dessutom är vyn sys.dm_exec_sessions användbar när du hämtar information om alla aktiva användaranslutningar och interna uppgifter.
Visa aktuella sessioner
Följande fråga hämtar information om den aktuella anslutningen. Om du vill visa alla sessioner tar du WHERE bort satsen.
Du ser endast alla körningssessioner på databasen om du har behörigheten VISA DATABASTILLSTÅND på databasen när du kör vyerna sys.dm_exec_requests och sys.dm_exec_sessions . Annars ser du bara den aktuella sessionen.
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
Övervaka resursanvändning
Du kan övervaka resursanvändningen i Azure SQL Database på frågenivå med hjälp av SQL Database Query Performance Insight i Azure-portalen eller Query Store.
Du kan också övervaka användningen med hjälp av följande vyer:
sys.dm_db_resource_stats
Du kan använda vyn sys.dm_db_resource_stats i varje databas. Vyn sys.dm_db_resource_stats visar senaste resursanvändningsdata i förhållande till tjänstnivån. Genomsnittliga procentandelar för CPU, data-I/O, loggskrivningar och minne registreras var 15:e sekund och underhålls i 1 timme.
Eftersom den här vyn ger en mer detaljerad titt på resursanvändningen använder du sys.dm_db_resource_stats först för alla aktuella tillståndsanalyser eller felsökningar. Den här frågan visar till exempel den genomsnittliga och högsta resursanvändningen för den aktuella databasen under den senaste timmen:
SELECT
Database_Name = DB_NAME(),
tier_limit = COALESCE(rs.dtu_limit, cpu_limit), --DTU or vCore limit
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent'
FROM sys.dm_db_resource_stats AS rs --past hour only
GROUP BY rs.dtu_limit, rs.cpu_limit;
Andra frågor finns i exemplen i sys.dm_db_resource_stats.
sys.resource_stats
Vyn sys.resource_stats i master databasen har ytterligare information som kan hjälpa dig att övervaka databasens prestanda på den specifika tjänstnivån och beräkningsstorleken. Data samlas in var 5:e minut och underhålls i cirka 14 dagar. Den här vyn är användbar för en mer långsiktig historisk analys av hur databasen använder resurser.
Följande diagram visar cpu-resursanvändningen för en Premium-databas med P2-beräkningsstorleken för varje timme i veckan. Det här diagrammet börjar på en måndag, visar fem arbetsdagar och visar sedan en helg, när mycket mindre händer i programmet.
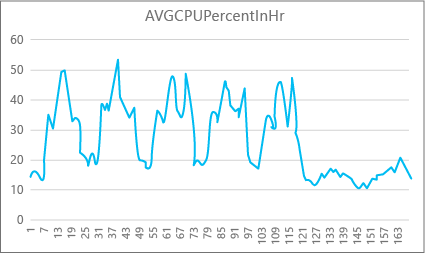
Från data har den här databasen för närvarande en högsta CPU-belastning på drygt 50 procent cpu-användning i förhållande till P2-beräkningsstorleken (middag på tisdag). Om CPU är den dominerande faktorn i programmets resursprofil kan du bestämma att P2 är rätt beräkningsstorlek för att garantera att arbetsbelastningen alltid passar. Om du förväntar dig att ett program ska växa med tiden är det en bra idé att ha en extra resursbuffert så att programmet aldrig når gränsen på prestandanivå. Om du ökar beräkningsstorleken kan du undvika kund synliga fel som kan uppstå när en databas inte har tillräckligt med kraft för att bearbeta begäranden effektivt, särskilt i svarstidskänsliga miljöer. Ett exempel är en databas som stöder ett program som målar webbsidor baserat på resultatet av databasanrop.
Andra programtyper kan tolka samma diagram på olika sätt. Om ett program till exempel försöker bearbeta lönedata varje dag och har samma diagram kan den här typen av "batchjobb"-modell klara sig bra med en P1-beräkningsstorlek. P1-beräkningsstorleken har 100 DTU:er jämfört med 200 DTU:er med P2-beräkningsstorleken. P1-beräkningsstorleken ger hälften av P2-beräkningsstorlekens prestanda. 50 procent av cpu-användningen i P2 är alltså lika med 100 procent cpu-användning i P1. Om programmet inte har tidsgränser kanske det inte spelar någon roll om ett jobb tar 2 timmar eller 2,5 timmar att slutföra, om det görs idag. Ett program i den här kategorin kan förmodligen använda en P1-beräkningsstorlek. Du kan dra nytta av det faktum att det finns tidsperioder under dagen när resursanvändningen är lägre, så att alla "stora toppar" kan spilla över i ett av trågen senare på dagen. P1-beräkningsstorleken kan vara bra för den typen av program (och spara pengar), så länge jobben kan slutföras i tid varje dag.
Databasmotorn exponerar förbrukad resursinformation för varje aktiv databas i sys.resource_stats vyn för master databasen på varje server. Data i tabellen aggregeras för 5-minutersintervall. Med tjänstnivåerna Basic, Standard och Premium kan det ta mer än 5 minuter att visa data i tabellen, så dessa data är mer användbara för historisk analys snarare än analys i nära realtid. sys.resource_stats Fråga vyn för att se den senaste historiken för en databas och för att verifiera om den reservation du valde levererade den prestanda du vill ha när det behövs.
Kommentar
I Azure SQL Database måste du vara ansluten till master databasen för att köra frågor sys.resource_stats i följande exempel.
Det här exemplet visar hur data i den här vyn exponeras:
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
I nästa exempel visas olika sätt att använda sys.resource_stats katalogvyn för att få information om hur databasen använder resurser:
Om du vill titta på den senaste veckans resursanvändning för användardatabasen
userdb1kan du köra den här frågan och ersätta ditt eget databasnamn:SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;För att utvärdera hur väl din arbetsbelastning passar beräkningsstorleken måste du öka detaljnivån för varje aspekt av resursmåtten: CPU, läsningar, skrivningar, antal arbetare och antal sessioner. Här är en reviderad fråga som använder
sys.resource_statsför att rapportera medelvärdet och maxvärdena för dessa resursmått, för varje tjänstnivå som databasen har etablerats för:SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.Storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Average Requests In %' = AVG(rs.max_worker_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Average Sessions In %' = AVG(rs.max_session_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;Med den här informationen om medelvärdet och maxvärdena för varje resursmått kan du utvärdera hur väl din arbetsbelastning passar in i den beräkningsstorlek som du har valt. Vanligtvis ger genomsnittliga värden från
sys.resource_statsdig en bra baslinje att använda mot målstorleken. Det bör vara din primära mätsticka.För DTU-inköpsmodelldatabaser :
Du kan till exempel använda standardtjänstnivån med S2-beräkningsstorlek. Den genomsnittliga användningsprocenten för CPU- och I/O-läsningar och skrivningar är under 40 procent, det genomsnittliga antalet arbetare är under 50 och det genomsnittliga antalet sessioner är under 200. Din arbetsbelastning kan passa in i S1-beräkningsstorleken. Det är enkelt att se om databasen passar i arbets- och sessionsgränserna. Om du vill se om en databas får en lägre beräkningsstorlek delar du upp DTU-numret för den lägre beräkningsstorleken med DTU-numret för din aktuella beräkningsstorlek och multiplicerar sedan resultatet med 100:
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40Resultatet är den relativa prestandaskillnaden mellan de två beräkningsstorlekarna i procent. Om resursanvändningen inte överskrider det här beloppet kan din arbetsbelastning passa in i den lägre beräkningsstorleken. Du måste dock titta på alla intervall med resursanvändningsvärden och i procent fastställa hur ofta databasarbetsbelastningen får plats i den lägre beräkningsstorleken. Följande fråga matar ut fit percentage per resursdimension, baserat på tröskelvärdet på 40 procent som vi beräknade i det här exemplet:
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Baserat på databastjänstnivån kan du bestämma om din arbetsbelastning ska få den lägre beräkningsstorleken. Om målet för databasens arbetsbelastning är 99,9 procent och föregående fråga returnerar värden som är större än 99,9 procent för alla tre resursdimensionerna, passar din arbetsbelastning troligen in i den lägre beräkningsstorleken.
Om du tittar på fit-procentandelen får du också en inblick i om du ska gå över till nästa högre beräkningsstorlek för att uppfylla ditt mål. Till exempel cpu-användningen för en exempeldatabas under den senaste veckan:
Genomsnittlig CPU-procent Maximal cpu-procent 24.5 100.00 Den genomsnittliga processorn är ungefär en fjärdedel av gränsen för beräkningsstorleken, vilket skulle passa bra in i databasens beräkningsstorlek.
För DTU-inköpsmodell och databaser för köpmodell för virtuella kärnor:
Det maximala värdet visar att databasen når gränsen för beräkningsstorleken. Behöver du flytta till nästa högre beräkningsstorlek? Titta på hur många gånger din arbetsbelastning når 100 procent och jämför den sedan med målet för databasens arbetsbelastning.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;De här procentandelarna är antalet exempel som din arbetsbelastning får plats med under den aktuella beräkningsstorleken. Om den här frågan returnerar ett värde som är mindre än 99,9 procent för någon av de tre resursdimensionerna överskred den genomsnittliga arbetsbelastningen i urvalet gränserna. Överväg att antingen flytta till nästa högre beräkningsstorlek eller använda programjusteringstekniker för att minska belastningen på databasen.
Kommentar
För elastiska pooler kan du övervaka individuella databaser i poolen med de tekniker som beskrivs i det här avsnittet. Du kan också övervaka poolen som helhet. Mer information finns i Övervaka och hantera en elastisk pool.
Maximalt antal samtidiga begäranden
Om du vill se det aktuella antalet samtidiga begäranden kör du den här frågan i användardatabasen:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests AS R;
Om du vill analysera arbetsbelastningen för en databas ändrar du den här frågan så att den filtrerar på den specifika databas som du vill analysera. Uppdatera först namnet på databasen från MyDatabase till önskad databas och kör sedan följande fråga för att hitta antalet samtidiga begäranden i databasen:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests AS R
INNER JOIN sys.databases AS D
ON D.database_id = R.database_id
AND D.name = 'MyDatabase';
Det här är bara en ögonblicksbild vid en enda tidpunkt. För att få en bättre förståelse för dina krav på arbetsbelastningar och samtidiga begäranden måste du samla in många exempel över tid.
Maximalt antal samtidiga inloggningshändelser
Du kan analysera användar- och programmönster för att få en uppfattning om frekvensen för inloggningshändelser. Du kan också köra verkliga belastningar i en testmiljö för att se till att du inte når den här eller andra gränser som vi diskuterar i den här artikeln. Det finns inte en enda fråga eller dynamisk hanteringsvy (DMV) som kan visa antalet samtidiga inloggningar eller historik.
Om flera klienter använder samma anslutningssträng autentiserar tjänsten varje inloggning. Om 10 användare samtidigt ansluter till en databas med samma användarnamn och lösenord skulle det finnas 10 samtidiga inloggningar. Den här gränsen gäller endast för varaktigheten för inloggningen och autentiseringen. Om samma 10 användare ansluter till databasen sekventiellt blir antalet samtidiga inloggningar aldrig större än 1.
Kommentar
Den här gränsen gäller för närvarande inte för databaser i elastiska pooler.
Maximalt antal sessioner
Om du vill se antalet aktuella aktiva sessioner kör du den här frågan i databasen:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_connections;
Om du analyserar en SQL Server-arbetsbelastning ändrar du frågan så att den fokuserar på en specifik databas. Den här frågan hjälper dig att fastställa möjliga sessionsbehov för databasen om du överväger att flytta den till Azure. Uppdatera först namnet på databasen från MyDatabase till önskad databas och kör sedan följande fråga:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_connections AS C
INNER JOIN sys.dm_exec_sessions AS S
ON (S.session_id = C.session_id)
INNER JOIN sys.databases AS D
ON (D.database_id = S.database_id)
WHERE D.name = 'MyDatabase';
Återigen returnerar dessa frågor ett antal tidpunkter. Om du samlar in flera exempel över tid har du den bästa förståelsen för din sessionsanvändning.
Du kan hämta historisk statistik om sessioner genom att fråga sys.resource_stats katalogvyn och granska active_session_count kolumnen.
Beräkna databas- och objektstorlekar
Följande fråga returnerar databasens storlek (i MB):
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Följande fråga returnerar storleken på enskilda objekt (i MB) i databasen:
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
Övervaka frågeprestanda
Långsamma eller tidskrävande frågor kan förbruka betydande systemresurser. Det här avsnittet visar hur du använder dynamiska hanteringsvyer för att identifiera några vanliga problem med frågeprestanda med hjälp av sys.dm_exec_query_stats dynamisk hanteringsvy. Vyn innehåller en rad per frågeuttryck i den cachelagrade planen och radernas livslängd är kopplad till själva planen. När en plan tas bort från cachen tas motsvarande rader bort från den här vyn.
Hitta de vanligaste frågorna efter CPU-tid
I följande exempel returneras information om de 15 vanligaste frågorna rangordnade efter genomsnittlig CPU-tid per körning. Det här exemplet aggregerar frågorna enligt deras frågehash, så att logiskt likvärdiga frågor grupperas efter deras kumulativa resursförbrukning.
SELECT TOP 15 query_stats.query_hash AS "Query Hash",
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS "Avg CPU Time",
MIN(query_stats.statement_text) AS "Statement Text"
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY 2 DESC;
Övervaka frågeplaner för kumulativ CPU-tid
En ineffektiv frågeplan kan också öka CPU-förbrukningen. I följande exempel avgörs vilken fråga som använder den mest kumulativa processorn i den senaste historiken.
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
Övervaka blockerade frågor
Långsamma eller långvariga frågor kan bidra till överdriven resursförbrukning och vara en följd av blockerade frågor. Orsaken till blockeringen kan vara dålig programdesign, dåliga frågeplaner, bristen på användbara index och så vidare.
Du kan använda sys.dm_tran_locks vyn för att hämta information om den aktuella låsningsaktiviteten i databasen. Exempel på kod finns i sys.dm_tran_locks. Mer information om felsökning av blockering finns i Förstå och lösa azure SQL-blockeringsproblem.
Övervaka dödlägen
I vissa fall kan två eller flera frågor blockera varandra ömsesidigt, vilket resulterar i ett dödläge.
Du kan skapa en extended events-spårning av en databas i Azure SQL Database för att samla in dödlägeshändelser och sedan hitta relaterade frågor och deras körningsplaner i Query Store. Läs mer i Analysera och förhindra dödlägen i Azure SQL Database, inklusive ett labb för att orsaka ett dödläge i AdventureWorksLT. Läs mer om vilka typer av resurser som kan blockeras.
Nästa steg
- Introduktion till Azure SQL Database och Azure SQL Managed Instance
- Diagnostisera och felsöka hög CPU-användning i Azure SQL Database
- Justera program och databaser för prestanda i Azure SQL Database
- Förstå och lösa blockeringsproblem i Azure SQL Database
- Analysera och förhindra dödlägen i Azure SQL Database