Serverlös beräkningsnivå för Azure SQL Database
Gäller för:![]() Azure SQL Database
Azure SQL Database
Serverlös är en beräkningsnivå för enskilda databaser i Azure SQL Database som automatiskt skalar beräkning baserat på efterfrågan på arbetsbelastningar och fakturor för den mängd beräkning som används per sekund. På den serverlösa beräkningsnivån pausas databaser automatiskt under inaktiva perioder och då faktureras endast lagring. Databaserna startas igen automatiskt när aktiviteten återupptas. Den serverlösa beräkningsnivån är tillgänglig på tjänstnivån Generell användning och tjänstnivån Hyperskala .
Kommentar
Automatisk pausning och automatisk återupptagning stöds för närvarande endast på tjänstnivån Generell användning.
Översikt
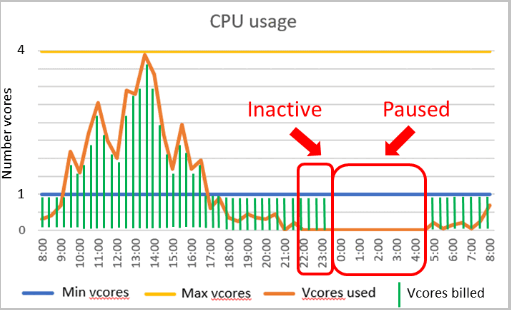
Ett beräkningsintervall för automatisk skalning och en fördröjning med automatisk paus är viktiga parametrar för den serverlösa beräkningsnivån. Konfigurationen av dessa parametrar formar databasens prestandaupplevelse och beräkningskostnad.
Prestandakonfiguration
- Minsta virtuella kärnor och maximala virtuella kärnor är konfigurerbara parametrar som definierar det tillgängliga beräkningskapacitetsintervallet för databasen. Minnes- och I/O-gränser är proportionella mot det angivna vCore-intervallet.
- Fördröjningen för automatisk paus är en konfigurerbar parameter som definierar hur lång tid databasen måste vara inaktiv innan den pausas automatiskt. Databasen återupptas automatiskt när nästa inloggning eller annan aktivitet inträffar. Du kan också inaktivera automatisk pausning.
Kostnad
- Kostnaden för en serverlös databas är sammanfattningen av beräkningskostnaden och lagringskostnaden.
- När beräkningsanvändningen ligger mellan de minsta och högsta gränser som konfigurerats baseras beräkningskostnaden på virtuell kärna och minne som används.
- När beräkningsanvändningen ligger under de minimigränser som konfigurerats baseras beräkningskostnaden på minsta virtuella kärnor och minsta konfigurerade minne.
- När databasen pausas är beräkningskostnaden noll och endast lagringskostnader uppstår.
- Lagringskostnaden bestäms på samma sätt som på den etablerade beräkningsnivån.
Mer kostnadsinformation finns i Fakturering.
Scenarier
Nivån med serverlös databehandling är pris/prestanda-optimerad för enstaka databaser med oförutsägbart användningsmönster som inte störs av viss fördröjning i databehandlingen efter inaktiva perioder. Den etablerade beräkningsnivån är däremot prisprestandaoptimerad för enskilda databaser eller flera databaser i elastiska pooler med högre genomsnittlig användning som inte har råd med någon fördröjning i beräkningsuppvärmningen.
Scenarier som passar bra för serverlös beräkning
- Enkla databaser med tillfälliga och oförutsägbara användningsmönster, blandat med perioder av inaktivitet och lägre genomsnittlig databehandling.
- Enkla databaser på nivån med etablerad databehandling som ofta skalas om och kunder som föredrar att delegera omskalningen till tjänsten.
- Nya enkla databaser utan användningshistorik där beräkningsstorleken är svår eller inte går att uppskatta före distributionen i en Azure SQL Database.
Scenarier som passar bra för etablerad beräkning
- Enkla databaser med mer regelbundna, förutsägbara användningsmönster och högre genomsnittlig beräkningsanvändning över tid.
- Databaser som inte kan tolerera avvägningar av prestanda till följd av mer frekvent minnestrimning eller fördröjningar i återupptagandet från ett pausat tillstånd.
- Flera databaser med tillfälliga, oförutsägbara användningsmönster som kan konsolideras i elastiska pooler för bättre pris-prestandaoptimering.
Jämföra beräkningsnivåer
I följande tabell sammanfattas skillnaderna mellan den serverlösa beräkningsnivån och den etablerade beräkningsnivån:
| Serverlös databearbetning | Etablerad beräkning | |
|---|---|---|
| Mönster för databasanvändning | Tillfällig, oförutsägbar användning med lägre genomsnittlig beräkningsanvändning över tid. | Mer regelbundna användningsmönster med högre genomsnittlig beräkningsanvändning över tid eller flera databaser med elastiska pooler. |
| Arbete med prestandahantering | Lower | Högre |
| Beräkningsskalning | Automatisk | Manuell |
| Svarstid för beräkning | Lägre efter inaktiva perioder | Omedelbara |
| Faktureringskornighet | Per sekund | Per timme |
Inköpsmodell och tjänstnivå
I följande tabell beskrivs serverlöst stöd baserat på inköpsmodell, tjänstnivåer och maskinvara:
| Kategori | Stöds | Stöds ej |
|---|---|---|
| Inköpsmodell | virtuell kärna | DTU |
| Tjänstenivå | Generell användning Hyperskala |
Affärskritisk |
| Maskinvara | Standardserie (Gen5) | All annan maskinvara |
Automatisk skalning
Skalningsresponsivitet
Serverlösa databaser körs på en dator med tillräcklig kapacitet för att uppfylla resursbehovet utan avbrott för den mängd beräkning som begärs inom de gränser som anges av det maximala värdet för virtuella kärnor. Ibland sker belastningsutjämning automatiskt om datorn inte kan uppfylla resursbehovet inom några minuter. Om resursbehovet till exempel är 4 virtuella kärnor, men endast 2 virtuella kärnor är tillgängliga, kan det ta upp till några minuter att belastningssaldot innan 4 virtuella kärnor tillhandahålls. Databasen förblir online under belastningsutjämning med undantag för en kort period i slutet av åtgärden när anslutningar tas bort.
Minneshantering
På tjänstnivåerna Generell användning och Hyperskala frigörs minne för serverlösa databaser oftare än för etablerade beräkningsdatabaser. Det här beteendet är viktigt för att kontrollera kostnader i serverlösa och kan påverka prestanda.
Cacheåtertagning
Till skillnad från etablerade beräkningsdatabaser frigörs minne från SQL-cachen från en serverlös databas när processoranvändningen eller den aktiva cacheanvändningen är låg.
- Aktiv cacheanvändning anses vara låg när den totala storleken på de senast använda cacheposterna understiger ett tröskelvärde under en tidsperiod.
- När cacheåterhämtning utlöses minskas målcachestorleken stegvis till en bråkdel av dess tidigare storlek och återtagandet fortsätter bara om användningen förblir låg.
- När cacheåtertagning inträffar är principen för att välja cacheposter som ska avlägsnas samma urvalsprincip som för etablerade beräkningsdatabaser när minnesbelastningen är hög.
- Cachestorleken minskas aldrig under den minsta minnesgräns som definieras av minsta virtuella kärnor.
I både serverlösa och etablerade beräkningsdatabaser kan cacheposter tas bort om allt tillgängligt minne används.
När processoranvändningen är låg kan aktiv cacheanvändning förbli hög beroende på användningsmönstret och förhindra minnesåtertagning. Det kan också uppstå andra fördröjningar när användaraktiviteten stoppas innan minnesåtertagning sker på grund av periodiska bakgrundsprocesser som svarar på tidigare användaraktivitet. Borttagningsåtgärder och rensningsuppgifter i Query Store genererar till exempel spökposter som har markerats för borttagning, men som inte tas bort fysiskt förrän rensningsprocessen för spöken körs. Ghost-rensning kan innebära att läsa datasidor i cacheminnet.
Cache hydrering
SQL-minnescachen växer när data hämtas från disken på samma sätt och med samma hastighet som för etablerade databaser. När databasen är upptagen tillåts cacheminnet växa obehindrat medan det finns tillgängligt minne.
Hantering av diskcache
På tjänstnivån Hyperskala för både serverlösa och etablerade beräkningsnivåer använder varje beräkningsreplik en RBPEX-cache (Resilient Buffer Pool Extension), som lagrar datasidor på lokal SSD för att förbättra I/O-prestanda. I den serverlösa beräkningsnivån för Hyperskala växer RBPEX-cachen för varje beräkningsreplik automatiskt och krymper som svar på ökande och minskande efterfrågan på arbetsbelastningar. Den maximala storleken som RBPEX-cachen kan öka till är tre gånger så mycket minne som har konfigurerats för databasen. Mer information om maximalt minne och begränsningar för automatisk skalning av RBPEX i serverlösa finns i Resursgränser för serverlös Hyperskala.
Pausa automatiskt och återuppta automatiskt
För närvarande stöds serverlös automatisk pausning och automatisk återupptagning endast på nivån Generell användning.
Pausa automatiskt
Automatisk pausning utlöses om alla följande villkor är uppfyllda under fördröjningen av automatisk paus:
- Antal sessioner = 0
- CPU = 0 för användararbetsbelastning som körs i användarresurspoolen
Ett alternativ finns för att inaktivera automatisk pausning om du vill.
Följande funktioner stöder inte automatisk pausning, men stöder automatisk skalning. Om någon av följande funktioner används måste automatisk pausning inaktiveras och databasen förblir online oavsett varaktigheten för databasens inaktivitet:
- Geo-replikering (aktiva geo-replikerings - och redundansgrupper).
- Långsiktig kvarhållning av säkerhetskopior (LTR).
- Synkroniseringsdatabasen som används i SQL Data Sync. Till skillnad från synkroniseringsdatabaser stöder hubb- och medlemsdatabaser automatisk pausning.
- DNS-alias som skapats för den logiska servern som innehåller en serverlös databas.
- Elastiska jobb (förhandsversion), Automatisk pausning av aktiverad serverlös databas stöds inte som en jobbdatabas. Serverlösa databaser som omfattas av elastiska jobb stöder automatisk pausning. Jobbanslutningar återupptar en databas.
Automatisk pausning förhindras tillfälligt under distributionen av vissa tjänstuppdateringar, vilket kräver att databasen är online. I sådana fall tillåts automatisk pausning igen när tjänstuppdateringen har slutförts.
Automatisk pausning av felsökning
Om automatisk pausning är aktiverat och funktioner som blockerar automatisk pausning inte används, men en databas inte pausas automatiskt efter fördröjningsperioden, kan program- eller användarsessionerna förhindra automatisk pausning.
Du kan se om det finns några program- eller användarsessioner som för närvarande är anslutna till databasen genom att ansluta till databasen med valfritt klientverktyg och köra följande fråga:
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
Dricks
När du har kört frågan måste du koppla från databasen. Annars förhindrar den öppna session som används av frågan automatisk pausning.
- Om resultatuppsättningen inte är snål anger det att det för närvarande finns sessioner som förhindrar automatisk pausning.
- Om resultatuppsättningen är tom är det fortfarande möjligt att sessionerna har varit öppna, möjligen under en kort tid, någon gång tidigare under fördröjningsperioden för automatisk paus. Om du vill söka efter aktivitet under fördröjningsperioden kan du använda Azure SQL-granskning och granska granskningsdata för den aktuella perioden.
Viktigt!
Att det förekommer öppna sessioner, med eller utan samtidig processoranvändning i användarresurspoolen, är den vanligaste orsaken till att en serverlös databas inte pausar automatiskt som förväntat.
Återuppta automatiskt
Automatisk återupptagning utlöses om något av följande villkor är sant när som helst:
| Funktion | Utlösare för automatisk återupptagning |
|---|---|
| Autentisering och auktorisering | Logga in |
| Hotidentifiering | Aktivera/inaktivera inställningar för hotidentifiering på databas- eller servernivå. Ändra inställningar för hotidentifiering på databas- eller servernivå. |
| Identifiering och klassificering av data | Lägga till, ändra, ta bort eller visa känslighetsetiketter |
| Granskning | Visa granskningsposter. Uppdatera eller visa en granskningsprincip. |
| Datamaskning | Lägga till, ändra, ta bort eller visa datamaskeringsregler |
| Transparent datakryptering | Visa tillstånd eller status för transparent datakryptering |
| Sårbarhetsbedömning | Ad hoc-genomsökningar och periodiska genomsökningar om de är aktiverade |
| Frågedatalager (prestanda) | Ändra eller visa inställningar för frågearkiv |
| Prestandarekommendationer | Visa eller tillämpa prestandarekommendationer |
| Automatisk justering | Program och verifiering av rekommendationer för automatisk justering, till exempel automatisk indexering |
| Databaskopiering | Skapa en kopia ave en databas. Exportera till en BACPAC-fil. |
| SQL Data Sync | Synkronisering mellan hubb- och medlemsdatabaser som körs enligt ett konfigurerbart schema eller utförs manuellt |
| Ändra vissa databasmetadata | Lägga till nya databastaggar. Ändra maximalt antal virtuella kärnor, minsta virtuella kärnor eller automatisk pausningsfördröjning. |
| SQL Server Management Studio (SSMS) | När du använder SSMS-versioner tidigare än 18.1 och öppnar ett nytt frågefönster för alla databaser på servern återupptas alla automatiskt pausade databaser på samma server. Det här beteendet inträffar inte om du använder SSMS version 18.1 eller senare. |
- Övervakning, hantering eller andra lösningar som utför någon av de här åtgärderna i listan utlöser automatisk återupptagning.
- Automatisk återupptagning utlöses också under distributionen av vissa tjänstuppdateringar som kräver att databasen är online.
Anslutning
Om en serverlös databas har pausats återupptar den första inloggningsaktiviteten databasen och returnerar ett fel som anger att databasen inte är tillgänglig med felkoden 40613. När databasen har återupptagits kan du försöka logga in igen för att upprätta anslutningen. Databasklienter med rekommenderad logik för anslutningsförsök behöver inte ändras. Rekommenderade mönster för logik för återförsök av anslutningar finns i:
- Prova logik igen i SqlClient
- Prova logiken igen i SQL Database med Entity Framework Core
- Prova logiken igen i SQL Database med Entity Framework 6
- Prova logiken igen i SQL Database med hjälp av ADO.NET
Svarstid
Svarstiden för att automatiskt återuppta och automatiskt pausa en serverlös databas är vanligtvis i storleksordningen 1 minut för att återuppta automatiskt och 1–10 minuter efter att fördröjningsperioden har löpt ut för automatisk pausning.
Kundhanterad transparent datakryptering (BYOK)
Borttagning eller återkallande av nycklar
Om du använder kundhanterad transparent datakryptering (BYOK) och den serverlösa databasen pausas automatiskt när nyckeln tas bort eller återkallas förblir databasen i automatiskt pausat tillstånd. I det här fallet blir databasen otillgänglig inom cirka 10 minuter efter att databasen har återupptagits. När databasen blir otillgänglig är återställningsprocessen densamma som för etablerade beräkningsdatabaser. Om den serverlösa databasen är online när nyckeln tas bort eller återkallas blir databasen också otillgänglig inom cirka 10 minuter på samma sätt som med etablerade beräkningsdatabaser.
Nyckelrotation
Om du använder kundhanterad transparent datakryptering (BYOK) och den serverlösa databasen pausas automatiskt skjuts automatisk nyckelrotation upp tills databasen återupptas automatiskt.
Skapa en ny serverlös databas
Att skapa en ny databas eller flytta en befintlig databas till en serverlös beräkningsnivå följer samma mönster som att skapa en ny databas på den etablerade beräkningsnivån och omfattar följande två steg:
Ange tjänstmålet. Tjänstmålet anger tjänstnivå, maskinvarukonfiguration och maximalt antal virtuella kärnor. Information om alternativ för tjänstmål finns i Serverlösa resursgränser
Du kan också ange minsta virtuella kärnor och automatisk pausfördröjning för att ändra standardvärdena. I följande tabell visas tillgängliga värden för dessa parametrar.
Parameter Värdeval Standardvärde Lägsta antal virtuella kärnor Beror på maximalt antal virtuella kärnor som konfigurerats – se resursgränser. 0,5 virtuella kärnor Fördröjning för automatisk paus Minst: 60 minuter (1 timme)
Maximalt: 10 080 minuter (7 dagar)
Steg: 10 minuter
Inaktivera automatisk paus: -160 minuter
I följande exempel skapas en ny databas på den serverlösa beräkningsnivån.
Använda Azure-portalen
Se Snabbstart: Skapa en enkel databas i Azure SQL Database med hjälp av Azure-portalen.
Använda PowerShell
Skapa en ny serverlös databas för generell användning med följande PowerShell-exempel:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
Använda Azure CLI
Skapa en ny serverlös databas för generell användning med följande Azure CLI-exempel:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
Använda Transact-SQL (T-SQL)
När du använder T-SQL för att skapa en ny serverlös databas tillämpas standardvärden för minsta virtuella kärnor och fördröjning av automatisk paus. De kan senare ändras från Azure-portalen eller via andra hanterings-API:er (PowerShell, Azure CLI, REST API).
Mer information finns i SKAPA DATABAS.
Skapa en ny serverlös databas för generell användning med följande T-SQL-exempel:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
Flytta en databas mellan beräkningsnivåer
Det går att flytta databasen från den etablerade beräkningsnivån till den serverlösa beräkningsnivån och tillbaka igen.
Kommentar
Det går också att uppgradera databasen på nivån Generell användning till Hyperskala-nivån. Mer information finns i Hantera Hyperskala-databaser .
När du flyttar databasen mellan beräkningsnivåer anger du parametern Beräkningsmodell som antingen Serverless eller Provisioned när du använder PowerShell och Azure CLI och beräkningsstorleken för SERVICE_OBJECTIVE när du använder T-SQL. Granska resursgränserna för att identifiera lämplig beräkningsstorlek.
Exemplen i det här avsnittet visar hur du flyttar din etablerade databas till serverlös. Ändra tjänstmålet efter behov, eftersom de här exemplen anger maximalt antal virtuella kärnor till 4.
Använda PowerShell
Flytta en etablerad beräkningsdatabas för generell användning till den serverlösa beräkningsnivån med följande PowerShell-exempel:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
Använda Azure CLI
Flytta en etablerad beräkningsdatabas för generell användning till den serverlösa beräkningsnivån med följande Azure CLI-exempel:
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
Använda Transact-SQL (T-SQL)
När du använder T-SQL för att flytta en databas mellan beräkningsnivåer tillämpas standardvärden för minsta virtuella kärnor och fördröjning av automatisk paus. De kan senare ändras från Azure-portalen eller via andra hanterings-API:er (PowerShell, Azure CLI, REST API). Mer information finns i ALTER DATABASE.
Flytta en etablerad beräkningsdatabas för generell användning till den serverlösa beräkningsnivån med följande T-SQL-exempel:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
Ändra serverlös konfiguration
Använda PowerShell
Använd Set-AzSqlDatabase för att ändra maximalt eller minsta antal virtuella kärnor och automatisk pausningsfördröjning. Använd argumenten MaxVcore, MinVcoreoch AutoPauseDelayInMinutes . Serverlös automatisk pausning stöds för närvarande inte på Hyperskala-nivån, så argumentet för automatisk pausfördröjning gäller endast för nivån Generell användning.
Använda Azure CLI
Använd az sql db update för att ändra den maximala eller minsta virtuella kärnor och automatisk pausa fördröjningen. Använd argumenten capacity, min-capacityoch auto-pause-delay . Serverlös automatisk pausning stöds för närvarande inte på Hyperskala-nivån, så argumentet för automatisk pausfördröjning gäller endast för nivån Generell användning.
Övervaka
Resurser som används och faktureras
Resurserna i en serverlös databas omfattar apppaketet, SQL-instansen och entiteterna för användarresurspoolen.
Apppaket
Apppaketet är den yttre gränsen för resurshantering för en databas, oavsett om databasen finns på en serverlös eller etablerad beräkningsnivå. Apppaketet innehåller SQL-instansen och externa tjänster som fulltextsökning som alla tillsammans omfattar alla användar- och systemresurser som används av en databas i SQL Database. SQL-instansen dominerar vanligtvis den totala resursanvändningen i apppaketet.
Användarresurspool
Användarresurspoolen är en inre resurshanteringsgräns för en databas, oavsett om databasen finns på en serverlös eller etablerad beräkningsnivå. Användarresurspoolen omfattar cpu- och I/O-frågor för användararbetsbelastningar som genereras av DDL-frågor (CREATE och ALTER) och DML (INSERT, UPDATE, DELETE och MERGE och SELECT). Dessa frågor representerar vanligtvis den mest betydande andelen användning i apppaketet.
Mått
Följande tabell innehåller mått för övervakning av resursanvändningen för apppaketet och användarresurspoolen för en serverlös databas, inklusive eventuella geo-repliker:
| Enhet | Mätvärde | Beskrivning | Units |
|---|---|---|---|
| Apppaket | app_cpu_percent | Procentandel virtuella kärnor som används av appen i förhållande till maximalt antal virtuella kärnor som tillåts för appen. För serverlös Hyperskala exponeras det här måttet för alla primära repliker, namngivna repliker och geo-repliker. | Procent |
| Apppaket | app_cpu_billed | Mängden beräkning som debiteras för appen under rapporteringsperioden. Det belopp som betalats under den här perioden är produkten av det här måttet och enhetspriset för virtuella kärnor. Värdena för det här måttet bestäms genom att du aggregerar det maximala antal processorer som används och det minne som används varje sekund. Om det belopp som används är mindre än det minsta belopp som har etablerats enligt minsta antal virtuella kärnor och minsta minne debiteras det minsta etablerade beloppet. För att kunna jämföra CPU med minne i faktureringssyfte normaliseras minnet till enheter med virtuella kärnor genom att mängden minne i GB skalas om med 3 GB per virtuell kärna. För serverlös Hyperskala exponeras det här måttet för den primära repliken och eventuella namngivna repliker. |
vCore-sekunder |
| Apppaket | app_cpu_billed_HA_replicas | Gäller endast för serverlös hyperskala. Summan av den beräkning som faktureras för alla appar för HA-repliker under rapportperioden. Den här summan är begränsad till ha-repliker som tillhör den primära repliken eller ha-replikerna som tillhör en viss namngiven replik. Innan du beräknar den här summan för HA-repliker bestäms mängden beräkning som faktureras för en enskild HA-replik på samma sätt som för den primära repliken eller en namngiven replik. För serverlös Hyperskala exponeras det här måttet för alla primära repliker, namngivna repliker och geo-repliker. Det belopp som betalas under rapporteringsperioden är produkten av det här måttet och enhetspriset för virtuella kärnor. | vCore-sekunder |
| Apppaket | app_memory_percent | Procentandel minne som används av appen i förhållande till maximalt minne som tillåts för appen. För serverlös Hyperskala exponeras det här måttet för alla primära repliker, namngivna repliker och geo-repliker. | Procent |
| Användarresurspool | cpu_percent | Procentandel virtuella kärnor som används av användararbetsbelastningen i förhållande till maximalt antal virtuella kärnor som tillåts för användararbetsbelastningen. | Procent |
| Användarresurspool | data_IO_percent | Procentandel av data-IOPS som används av användararbetsbelastningen i förhållande till maximalt antal data som IOPS tillåts för användararbetsbelastning. | Procent |
| Användarresurspool | log_IO_percent | Procentandel av logg-MB/s som används av användararbetsbelastningen i förhållande till maximalt antal logg-MB/s som tillåts för användararbetsbelastningen. | Procent |
| Användarresurspool | workers_percent | Procentandel arbetare som används av användararbetsbelastningen i förhållande till maximalt antal arbetare som tillåts för användararbetsbelastningar. | Procent |
| Användarresurspool | sessions_percent | Procentandel sessioner som används av användararbetsbelastningen i förhållande till maximalt antal sessioner som tillåts för användararbetsbelastningen. | Procent |
Pausa och återuppta status
I Azure-portalen visas databasstatusen i översiktsfönstret på servern som visar de databaser som den innehåller. Databasstatusen visas också i översiktsfönstret för databasen.
Använd följande kommandon för att fråga efter statusen pausa och återuppta en databas:
Använda PowerShell
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
Använda Azure CLI
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
Resursgränser
Information om resursgränser finns i serverlös beräkningsnivå.
Fakturering
Mängden beräkning som faktureras för en serverlös databas är det maximala antal processorer som används och det minne som används varje sekund. Om mängden processor och minne som används är mindre än det minsta belopp som har etablerats för varje resurs debiteras det etablerade beloppet. För att jämföra CPU med minne för faktureringsändamål normaliseras minnet till enheter med virtuella kärnor genom att beräkna om antalet GB med 3 GB per virtuell kärna.
- Resurs fakturerad: CPU och minne
- Fakturerat belopp: enhetspris för virtuell kärna * maximalt (minsta virtuella kärnor, virtuella kärnor som används, minsta minne GB * 1/3, minnes-GB som används * 1/3)
- Faktureringsfrekvens: Per sekund
Enhetspriset för virtuella kärnor är kostnaden per virtuell kärna per sekund. För Hyperskala är enhetspriset för virtuell kärna för en HA-replik eller namngiven replik lägre än för den primära repliken.
Information om specifika enhetspriser i en viss region finns på sidan med priser för Azure SQL Database.
Mängden beräkning som faktureras i serverlös för en databas för generell användning eller en primär hyperskala eller namngiven replik exponeras med följande mått:
- Mått: app_cpu_billed (vCore-sekunder)
- Definition: maximum (minsta virtuella kärnor, virtuella kärnor som används, minsta minne GB * 1/3, minne GB används * 1/3)
- Rapporteringsfrekvens: Per minut baserat på mått per sekund aggregerade över 1 minut.
Mängden beräkning som faktureras i serverlös för Hyperskala HA-repliker som tillhör den primära repliken eller någon namngiven replik exponeras med följande mått:
- Mått: app_cpu_billed_HA_replicas (sekunder med virtuella kärnor)
- Definition: Summan av maximalt (minsta virtuella kärnor, virtuella kärnor som används, minsta minne GB * 1/3, minne GB används * 1/3) för alla HA-repliker som tillhör deras överordnade resurs.
- Överordnad resurs och måttslutpunkt: Den primära repliken och alla namngivna repliker exponerar var för sig det här måttet, som mäter den beräkning som faktureras för eventuella associerade HA-repliker.
- Rapporteringsfrekvens: Per minut baserat på mått per sekund aggregerade över 1 minut.
Minsta beräkningsfaktura
Om en serverlös databas har pausats är beräkningsfakturan noll. Om en serverlös databas inte pausas är den minsta beräkningsfakturan inte mindre än mängden virtuella kärnor baserat på maximalt (minsta virtuella kärnor, minsta minne GB * 1/3).
Exempel:
- Anta att en serverlös databas på nivån Generell användning inte har pausats och konfigurerats med högst 8 virtuella kärnor och 1 minsta virtuella kärnor som motsvarar minst 3,0 GB minne. Sedan baseras den minsta beräkningsfakturan på maximalt (1 virtuell kärna, 3,0 GB * 1 virtuell kärna/3 GB) = 1 virtuell kärna.
- Anta att en serverlös databas på nivån Generell användning inte har pausats och konfigurerats med 4 maximala virtuella kärnor och 0,5 minsta virtuella kärnor som motsvarar minst 2,1 GB minne. Sedan baseras den minsta beräkningsfakturan på maximalt (0,5 virtuella kärnor, 2,1 GB * 1 virtuell kärna/3 GB) = 0,7 virtuella kärnor.
- Anta att en serverlös databas på Hyperskala-nivån har en primär replik med en HA-replik och en namngiven replik utan HA-repliker. Anta att varje replik är konfigurerad med 8 maximala virtuella kärnor och 1 minsta virtuella kärnor som motsvarar 3 GB minsta minne. Sedan baseras den minsta beräkningsfakturan för den primära repliken, HA-repliken och den namngivna repliken på maximalt (1 virtuell kärna, 3 GB * 1 virtuell kärna/3 GB) = 1 virtuell kärna.
Priskalkylatorn för Azure SQL Database för serverlös kan användas för att fastställa det minsta minne som kan konfigureras baserat på antalet konfigurerade maximala och minsta virtuella kärnor. Om det minsta antalet virtuella kärnor som konfigurerats är större än 0,5 virtuella kärnor är den minsta beräkningsfakturan i regel oberoende av det minsta minne som konfigurerats och baseras endast på antalet minsta virtuella kärnor som konfigurerats.
Scenarioexempel
Överväg en serverlös databas på nivån Generell användning som har konfigurerats med minst 1 virtuell kärna och 4 maximala virtuella kärnor. Den här konfigurationen motsvarar cirka 3 GB minsta minne och maximalt minne på 12 GB. Anta att fördröjningen för automatisk paus är inställd på 6 timmar och att databasarbetsbelastningen är aktiv under de första 2 timmarna av en 24-timmarsperiod och i övrigt inaktiv.
I det här fallet debiteras databasen för beräkning och lagring under de första 8 timmarna. Även om databasen är inaktiv från och med den andra timmen debiteras den fortfarande för beräkning under de följande 6 timmarna baserat på den minsta beräkning som etablerats när databasen är online. Endast lagring faktureras under resten av 24-timmarsperioden medan databasen pausas.
Mer exakt beräknas beräkningsfakturan i det här exemplet på följande sätt:
| Tidsintervall | virtuella kärnor som används varje sekund | GB används varje sekund | Beräkningsdimension fakturerad | vCore sekunder faktureras över tidsintervall |
|---|---|---|---|---|
| 0:00-1:00 | 4 | 9 | virtuella kärnor som används | 4 virtuella kärnor * 3 600 sekunder = 1 4400 vCore-sekunder |
| 1:00-2:00 | 1 | 12 | Minnesanvändning | 12 GB * 1/3 * 3 600 sekunder = 1 4400 vCore-sekunder |
| 2:00-8:00 | 0 | 0 | Minsta antal minne som har etablerats | 3 GB * 1/3 * 21600 sekunder = 21600 vCore sekunder |
| 8:00-24:00 | 0 | 0 | Ingen beräkning fakturerades när den pausades | 0 sekunder med virtuella kärnor |
| Totalt antal virtuella kärnor som fakturerats under 24 timmar | 50 400 virtuella kärnor sekunder |
Anta att priset för beräkningsenheten är 0,000145 USD/vCore/sekund. Sedan är den beräkning som faktureras för den här 24-timmarsperioden produkten av beräkningsenhetspriset och virtuella kärnor som faktureras: $0.000145/vCore/second * 50400 vCore seconds ~ $7.31.
Azure Hybrid-förmån och reserverad kapacitet
Azure Hybrid-förmån (AHB) och rabatter för reserverad kapacitet gäller inte för den serverlösa beräkningsnivån.
Tillgängliga regioner
Serverlösa för nivåerna Generell användning och Hyperskala med stöd för upp till 40 maximala virtuella kärnor är tillgängligt över hela världen förutom följande regioner:
- Kina, östra
- Kina, norra
- Tyskland, centrala
- Tyskland, nordöstra
- USA Gov, centrala (Iowa)
Regioner som stöder 80 maximala virtuella kärnor utan tillgänglighetszoner för generell användning och Hyperskala
För närvarande stöds för närvarande 80 maximala virtuella kärnor i serverlösa nivåer för generell användning och hyperskala i följande regioner:
- Australien, östra
- Australien, sydöstra
- Brasilien, södra
- Kanada, centrala
- Central US
- Asien, östra
- East US
- USA, östra 2
- Frankrike, centrala
- Frankrike, södra
- Tyskland, västra centrala
- Indien, centrala
- Indien, syd
- Japan, östra
- Japan, västra
- USA, norra centrala
- Europa, norra
- Norge, östra
- Qatar, centrala
- Sydafrika, norra
- USA, södra centrala
- Schweiz, norra
- Storbritannien, södra
- Storbritannien, västra
- Europa, västra
- Västra centrala USA
- USA, västra
- USA, västra 2
- USA, västra 3
Regioner som stöder 80 maximala virtuella kärnor med tillgänglighetszoner för generell användning
För närvarande tillhandahålls 80 maximala virtuella kärnor med stöd för tillgänglighetszoner i serverlösa för nivån Generell användning i följande regioner med fler planerade regioner:
- East US
- Europa, norra
- Europa, västra
- Västra USA 2
Regioner som stöder 80 maximala virtuella kärnor med tillgänglighetszoner för Hyperskala
För närvarande tillhandahålls 80 maximala virtuella kärnor med stöd för tillgänglighetszoner i serverlöst för Hyperskala-nivån i följande regioner med fler planerade regioner:
- Central US
- East US
- Europa, norra
- Europa, västra
- USA, västra 2
- USA, västra 3
Relaterat innehåll
- Kom igång genom att läsa Snabbstart: Skapa en enkel databas – Azure SQL Database.
- Information om alternativ på serverlös tjänstnivå finns i Generell användning och Hyperskala.