Metodtips för HADR-konfiguration (SQL Server på virtuella Azure-datorer)
Gäller för:![]() SQL Server på en virtuell Azure-dator
SQL Server på en virtuell Azure-dator
Ett Windows Server-redundanskluster används för hög tillgänglighet och haveriberedskap (HADR) med SQL Server på virtuella Azure-datorer (VM).
Den här artikeln innehåller metodtips för klusterkonfiguration för både redundansklusterinstanser (FCIs) och tillgänglighetsgrupper när du använder dem med SQL Server på virtuella Azure-datorer.
Mer information finns i de andra artiklarna i den här serien: Checklista, VM-storlek, Lagring, Säkerhet, HADR-konfiguration, Samla in baslinje.
Checklista
Gå igenom följande checklista för en kort översikt över hadr-metodtipsen som resten av artikeln beskriver mer detaljerat.
Funktioner för hög tillgänglighet och haveriberedskap (HADR), till exempel AlwaysOn-tillgänglighetsgruppen och redundansklusterinstansen förlitar sig på underliggande Windows Server-redundansklusterteknik. Granska metodtipsen för att ändra DINA HADR-inställningar för att bättre stödja molnmiljön.
Överväg följande metodtips för ditt Windows-kluster:
- Distribuera dina virtuella SQL Server-datorer till flera undernät när det är möjligt för att undvika beroendet av en Azure Load Balancer eller ett distribuerat nätverksnamn (DNN) för att dirigera trafik till din HADR-lösning.
- Ändra klustret till mindre aggressiva parametrar för att undvika oväntade avbrott från tillfälliga nätverksfel eller Azure-plattformsunderhåll. Mer information finns i inställningar för pulsslag och tröskelvärden. Använd följande rekommenderade värden för Windows Server 2012 och senare:
- SameSubnetDelay: 1 sekund
- SameSubnetThreshold: 40 pulsslag
- CrossSubnetDelay: 1 sekund
- CrossSubnetThreshold: 40 pulsslag
- Placera dina virtuella datorer i en tillgänglighetsuppsättning eller i olika tillgänglighetszoner. Mer information finns i Tillgänglighetsinställningar för virtuella datorer.
- Använd ett enda nätverkskort per klusternod.
- Konfigurera klusterkvorumröstning för att använda 3 eller fler udda antal röster. Tilldela inte röster till DR-regioner.
- Övervaka resursbegränsningar noggrant för att undvika oväntade omstarter eller redundansväxlingar på grund av resursbegränsningar.
- Se till att operativsystemet, drivrutinerna och SQL Server är de senaste versionerna.
- Optimera prestanda för SQL Server på virtuella Azure-datorer. Läs de andra avsnitten i den här artikeln om du vill veta mer.
- Minska eller sprida ut arbetsbelastningen för att undvika resursgränser.
- Flytta till en virtuell dator eller disk som hans högre gränser för att undvika begränsningar.
För sql Server-tillgänglighetsgruppen eller redundansklusterinstansen bör du överväga följande metodtips:
- Om du får ofta oväntade fel följer du de metodtips för prestanda som beskrivs i resten av den här artikeln.
- Om optimeringen av prestanda för virtuella SQL Server-datorer inte löser dina oväntade redundansväxlingar kan du överväga att lätta på övervakningen för tillgänglighetsgruppen eller redundansklusterinstansen. Detta kan dock inte åtgärda den underliggande källan till problemet och kan maskera symtom genom att minska sannolikheten för fel. Du kan fortfarande behöva undersöka och åtgärda den underliggande rotorsaken. Använd följande rekommenderade värden för Windows Server 2012 eller senare:
- Tidsgräns för lån: Använd den här ekvationen för att beräkna det maximala tidsgränsvärdet för lån:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Börja med 40 sekunder. Om du använder de avslappnadeSameSubnetThresholdvärden ochSameSubnetDelayvärden som rekommenderades tidigare ska du inte överskrida 80 sekunder för tidsgränsvärdet för lån. - Maximalt antal fel under en angiven period: Ange det här värdet till 6.
- Tidsgräns för lån: Använd den här ekvationen för att beräkna det maximala tidsgränsvärdet för lån:
- När du använder det virtuella nätverksnamnet (VNN) och en Azure Load Balancer för att ansluta till DIN HADR-lösning anger du
MultiSubnetFailover = truei anslutningssträng, även om klustret bara sträcker sig över ett undernät.- Om klienten inte stöder
MultiSubnetFailover = Truekan du behöva angeRegisterAllProvidersIP = 0ochHostRecordTTL = 300cachelagrar klientens autentiseringsuppgifter under kortare tidsperioder. Detta kan dock orsaka ytterligare frågor till DNS-servern.
- Om klienten inte stöder
- Om du vill ansluta till DIN HADR-lösning med hjälp av det distribuerade nätverksnamnet (DNN) bör du tänka på följande:
- Du måste använda en klientdrivrutin som stöder
MultiSubnetFailover = True, och den här parametern måste finnas i anslutningssträng. - Använd en unik DNN-port i anslutningssträng när du ansluter till DNN-lyssnaren för en tillgänglighetsgrupp.
- Du måste använda en klientdrivrutin som stöder
- Använd en databasspegling anslutningssträng för en grundläggande tillgänglighetsgrupp för att kringgå behovet av en lastbalanserare eller DNN.
- Verifiera sektorstorleken för dina virtuella hårddiskar innan du distribuerar din lösning för hög tillgänglighet för att undvika feljusterade I/Os. Mer information finns i KB3009974 .
- Om SQL Server-databasmotorn, AlwaysOn-tillgänglighetsgruppens lyssnare eller hälsoavsökningen för redundansklusterinstanser är konfigurerade att använda en port mellan 49 152 och 65 536 (standardintervallet för dynamisk port för TCP/IP) lägger du till ett undantag för varje port. Detta förhindrar att andra system tilldelas samma port dynamiskt. I följande exempel skapas ett undantag för port 59999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Information om hur du jämför HADR-checklistan med andra metodtips finns i den omfattande checklistan för metodtips för prestanda.
Inställningar för VM-tillgänglighet
Om du vill minska effekten av stilleståndstid bör du överväga följande inställningar för bästa tillgänglighet för virtuella datorer:
- Använd närhetsplaceringsgrupper tillsammans med accelererat nätverk för lägsta svarstid.
- Placera klusternoder för virtuella datorer i separata tillgänglighetszoner för att skydda mot fel på datacenternivå eller i en enda tillgänglighetsuppsättning för redundans med lägre svarstid i samma datacenter.
- Använd premiumhanterade operativsystem och datadiskar för virtuella datorer i en tillgänglighetsuppsättning.
- Konfigurera varje programnivå i separata tillgänglighetsuppsättningar.
Kvorum
Även om ett kluster med två noder fungerar utan en kvorumresurs är kunderna strikt skyldiga att använda en kvorumresurs för att ha produktionsstöd. Klusterverifieringen skickar inget kluster utan en kvorumresurs.
Tekniskt sett kan ett kluster med tre noder överleva en enskild nodförlust (ned till två noder) utan en kvorumresurs, men när klustret är nere på två noder, om det finns en annan nodförlust eller kommunikationsfel, finns det en risk att klustrade resurser går offline för att förhindra ett scenario med delad hjärna. Genom att konfigurera en kvorumresurs kan klustret fortsätta online med endast en nod online.
Diskvittnet är det mest motståndskraftiga kvorumalternativet, men om du vill använda ett diskvittne på en SQL Server på en virtuell Azure-dator måste du använda en Delad Azure-disk, vilket medför vissa begränsningar för lösningen med hög tillgänglighet. Använd därför ett diskvittne när du konfigurerar din redundansklusterinstans med Azure Shared Disks, annars använder du ett molnvittne när det är möjligt.
I följande tabell visas de kvorumalternativ som är tillgängliga för SQL Server på virtuella Azure-datorer:
| Molnvittne | Diskvittne | Filresursvittne | |
|---|---|---|---|
| Operativsystem som stöds | Windows Server 2016+ | Alla | Alla |
- Molnvittnet är perfekt för distributioner på flera platser, flera zoner och flera regioner. Använd ett molnvittne när det är möjligt, såvida du inte använder en klusterlösning för delad lagring.
- Diskvittnet är det mest motståndskraftiga kvorumalternativet och föredras för alla kluster som använder Delade Azure-diskar (eller någon lösning för delad disk som delad SCSI, iSCSI eller fiberkanal-SAN). En klustrad delad volym kan inte användas som diskvittne.
- Fildelningsvittnet är lämpligt för när diskvittnet och molnvittnet inte är tillgängliga.
Information om hur du kommer igång finns i Konfigurera klusterkvorum.
Kvorumröstning
Det går att ändra kvorumrösten för en nod som deltar i ett Windows Server-redundanskluster.
När du ändrar inställningarna för nodröstning följer du dessa riktlinjer:
| Riktlinjer för kvorumröstning |
|---|
| Börja med att varje nod inte har någon röst som standard. Varje nod ska bara ha en röst med explicit motivering. |
| Aktivera röster för klusternoder som är värdar för den primära repliken av en tillgänglighetsgrupp eller de önskade ägarna till en redundansklusterinstans. |
| Aktivera röster för automatiska redundansägare. Varje nod som kan vara värd för en primär replik eller FCI till följd av en automatisk redundansväxling bör ha en röst. |
| Om en tillgänglighetsgrupp har fler än en sekundär replik aktiverar du bara röster för de repliker som har automatisk redundansväxling. |
| Inaktivera röster för noder som finns på sekundära haveriberedskapsplatser. Noder på sekundära platser bör inte bidra till beslutet att ta ett kluster offline om det inte är något fel med den primära platsen. |
| Ha ett udda antal röster, med minst tre kvorumröster. Lägg till ett kvorumvittne för ytterligare omröstning om det behövs i ett kluster med två noder. |
| Utvärderar om rösttilldelningar efter redundansväxling. Du vill inte redundansväxla till en klusterkonfiguration som inte stöder ett felfritt kvorum. |
Anslutning
Om du vill matcha den lokala upplevelsen för att ansluta till din tillgänglighetsgruppslyssnare eller redundansklusterinstans distribuerar du dina virtuella SQL Server-datorer till flera undernät i samma virtuella nätverk. Att ha flera undernät nektar behovet av det extra beroendet av en Azure Load Balancer eller ett distribuerat nätverksnamn för att dirigera trafiken till lyssnaren.
För att förenkla DIN HADR-lösning distribuerar du dina virtuella SQL Server-datorer till flera undernät när det är möjligt. Mer information finns i Ag för flera undernät och FCI för flera undernät.
Om dina virtuella SQL Server-datorer finns i ett enda undernät går det att konfigurera antingen ett virtuellt nätverksnamn (VNN) och en Azure Load Balancer eller ett distribuerat nätverksnamn (DNN) för både redundansklusterinstanser och lyssnare för tillgänglighetsgrupper.
Det distribuerade nätverksnamnet är det rekommenderade anslutningsalternativet när det är tillgängligt:
- Lösningen från slutpunkt till slutpunkt är mer robust eftersom du inte längre behöver underhålla lastbalanserarens resurs.
- Om lastbalanserarens avsökningar elimineras minimeras redundansvaraktigheten.
- DNN förenklar etablering och hantering av redundansklusterinstansen eller tillgänglighetsgruppens lyssnare med SQL Server på virtuella Azure-datorer.
Tänk på följande begränsningar finns:
- Klientdrivrutinen måste ha stöd för parametern
MultiSubnetFailover=True. - DNN-funktionen är tillgänglig från och med SQL Server 2016 SP3, SQL Server 2017 CU25 och SQL Server 2019 CU8 på Windows Server 2016 och senare.
Mer information finns i översikten över Windows Server-redundanskluster.
Information om hur du konfigurerar anslutningen finns i följande artiklar:
- Tillgänglighetsgrupp: Konfigurera DNN, Konfigurera VNN
- Redundansklusterinstans: Konfigurera DNN, Konfigurera VNN.
De flesta SQL Server-funktioner fungerar transparent med FCI- och tillgänglighetsgrupper när du använder DNN, men det finns vissa funktioner som kan kräva särskild hänsyn. Mer information finns i FCI- och DNN-samverkan och AG- och DNN-samverkan .
Dricks
Ange parametern MultiSubnetFailover = true i anslutningssträng även för HADR-lösningar som sträcker sig över ett enda undernät för att stödja framtida spanning av undernät utan att behöva uppdatera anslutningssträng.
Pulsslag och tröskelvärde
Ändra inställningar för klustrets pulsslag och tröskelvärde till avslappnade inställningar. Standardinställningarna för pulsslag och tröskelvärdeskluster är utformade för mycket finjusterade lokala nätverk och överväger inte möjligheten till ökad svarstid i en molnmiljö. Pulsslagsnätverket underhålls med UDP 3343, som traditionellt är mycket mindre tillförlitligt än TCP och mer benägna att ofullständiga konversationer.
När du kör klusternoder för SQL Server på virtuella Azure-datorer med hög tillgänglighet ändrar du därför klusterinställningarna till ett mer avslappnat övervakningstillstånd för att undvika tillfälliga fel på grund av den ökade risken för nätverksfördröjning eller fel, Azure-underhåll eller resursflaskhalsar.
Inställningarna för fördröjning och tröskelvärde har en kumulativ effekt på den totala hälsoidentifieringen. Om du till exempel anger CrossSubnetDelay till att skicka ett pulsslag var 2:e sekund och anger CrossSubnetThreshold till 10 missade pulsslag innan återställningen sker innebär det att klustret kan ha en total nätverkstolerans på 20 sekunder innan återställningsåtgärden vidtas. I allmänhet är det bra att fortsätta att skicka frekventa pulsslag, men att ha högre tröskelvärden.
För att säkerställa återställning under legitima avbrott samtidigt som du ger större tolerans för tillfälliga problem kan du minska dina inställningar för fördröjning och tröskelvärde till de rekommenderade värden som beskrivs i följande tabell:
| Inställning | Windows Server 2012 eller senare | Windows Server 2008 R2 |
|---|---|---|
| SameSubnetDelay | 1 sekund | 2 sekunder |
| SameSubnetThreshold | 40 pulsslag | 10 pulsslag (max) |
| CrossSubnetDelay | 1 sekund | 2 sekunder |
| CrossSubnetThreshold | 40 pulsslag | 20 pulsslag (max) |
Använd PowerShell för att ändra dina klusterparametrar:
(get-cluster).SameSubnetThreshold = 40
(get-cluster).CrossSubnetThreshold = 40
Använd PowerShell för att verifiera dina ändringar:
get-cluster | fl *subnet*
Tänk på följande:
- Den här ändringen sker omedelbart och du behöver inte starta om klustret eller några resurser.
- Samma undernätsvärden får inte vara större än värden mellan undernät.
- SameSubnetThreshold <= CrossSubnetThreshold
- SameSubnetDelay <= CrossSubnetDelay
Välj avslappnade värden baserat på hur mycket stilleståndstid som är acceptabel och hur lång tid innan en korrigerande åtgärd ska inträffa beroende på ditt program, dina affärsbehov och din miljö. Om du inte kan överskrida standardvärdena för Windows Server 2019 kan du åtminstone försöka matcha dem, om möjligt:
Som referens beskriver följande tabell standardvärdena:
| Inställning | Windows Server 2019 | Windows Server 2016 | Windows Server 2008 – 2012 R2 |
|---|---|---|---|
| SameSubnetDelay | 1 sekund | 1 sekund | 1 sekund |
| SameSubnetThreshold | 20 pulsslag | 10 pulsslag | 5 pulsslag |
| CrossSubnetDelay | 1 sekund | 1 sekund | 1 sekund |
| CrossSubnetThreshold | 20 pulsslag | 10 pulsslag | 5 pulsslag |
Mer information finns i Justera tröskelvärden för redundansklusternätverk.
Avslappnad övervakning
Om du inte har tillräcklig tolerans för att justera inställningarna för klustrets pulsslag och tröskelvärden och du fortfarande ser redundansväxlingar på grund av tillfälliga problem i stället för verkliga avbrott, kan du konfigurera tillgänglighetsgruppen eller FCI-övervakningen så att den blir mer avslappnad. I vissa scenarier kan det vara fördelaktigt att tillfälligt lätta på övervakningen under en viss tidsperiod med tanke på aktivitetsnivån. Du kanske till exempel vill lätta på övervakningen när du utför I/O-intensiva arbetsbelastningar, till exempel säkerhetskopior av databaser, indexunderhåll, DBCC CHECKDB osv. När aktiviteten är klar ställer du in övervakningen på mindre avslappnade värden.
Varning
Att ändra de här inställningarna kan maskera ett underliggande problem och bör användas som en tillfällig lösning för att minska risken för fel i stället för att eliminera. Underliggande problem bör fortfarande undersökas och åtgärdas.
Börja med att öka följande parametrar från standardvärdena för avslappnad övervakning och justera efter behov:
| Parameter | Default value | Avslappnat värde | Description |
|---|---|---|---|
| Tidsgräns för hälsokontroll | 30000 | 60000 | Avgör hälsotillståndet för den primära repliken eller noden. Klusterresursens DLL sp_server_diagnostics returnerar resultat med ett intervall som är lika med 1/3 av tröskelvärdet för hälsokontroll. Om sp_server_diagnostics det är långsamt eller inte returnerar information väntar resurs-DLL:n på det fullständiga intervallet för tidsgränsen för hälsokontroll innan du fastställer att resursen inte svarar och initierar en automatisk redundansväxling om den har konfigurerats för att göra det. |
| Felvillkorsnivå | 3 | 2 | Villkor som utlöser en automatisk redundansväxling. Det finns fem felvillkorsnivåer, som sträcker sig från den minst restriktiva (nivå ett) till den mest restriktiva (nivå fem) |
Använd Transact-SQL (T-SQL) för att ändra hälsokontroll- och felvillkoren för både AG:er och FCI:er.
För tillgänglighetsgrupper:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);
För redundansklusterinstanser:
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY HealthCheckTimeout = 60000;
ALTER SERVER CONFIGURATION SET FAILOVER CLUSTER PROPERTY FailureConditionLevel = 2;
Specifik för tillgänglighetsgrupper, börja med följande rekommenderade parametrar och justera efter behov:
| Parameter | Default value | Avslappnat värde | Description |
|---|---|---|---|
| Tidsgräns för lån | 20000 | 40000 | Förhindrar split-brain. |
| Tidsgräns för sessioner | 10000 | 20000 | Kontrollerar kommunikationsproblem mellan repliker. Tidsgränsen för sessionen är en replikegenskap som styr hur länge (i sekunder) en tillgänglighetsreplik väntar på ett ping-svar från en ansluten replik innan anslutningen har misslyckats. Som standard väntar en replik i 10 sekunder på ett ping-svar. Den här replikegenskapen gäller endast för anslutningen mellan en viss sekundär replik och tillgänglighetsgruppens primära replik. |
| Maximalt antal fel under den angivna perioden | 2 | 6 | Används för att undvika obegränsad förflyttning av en klustrad resurs inom flera nodfel. För lågt värde kan leda till att tillgänglighetsgruppen är i ett feltillstånd. Öka värdet för att förhindra korta avbrott i prestandaproblem eftersom ett för lågt värde kan leda till att tillgänglighetsgruppen är i ett feltillstånd. |
Tänk på följande innan du gör några ändringar:
- Sänk inte några timeout-värden under standardvärdena.
- Använd den här ekvationen för att beräkna det maximala tidsgränsvärdet för lån:
Lease timeout < (2 * SameSubnetThreshold * SameSubnetDelay).
Börja med 40 sekunder. Om du använder de avslappnadeSameSubnetThresholdvärden ochSameSubnetDelayvärden som rekommenderades tidigare ska du inte överskrida 80 sekunder för tidsgränsvärdet för lån. - Om du ändrar sessionstimeout till ett högt värde för synkrona incheckningsrepliker kan det öka HADR_sync_commit väntetider.
Tidsgräns för lån
Använd Klusterhanteraren för växling vid fel för att ändra tidsgränsinställningarna för lån för din tillgänglighetsgrupp. Mer information finns i dokumentationen om hälsokontroll för SQL Server-tillgänglighetsgruppslån.
Tidsgräns för sessioner
Använd Transact-SQL (T-SQL) för att ändra tidsgränsen för sessionen för en tillgänglighetsgrupp:
ALTER AVAILABILITY GROUP AG1
MODIFY REPLICA ON 'INSTANCE01' WITH (SESSION_TIMEOUT = 20);
Maximalt antal fel under den angivna perioden
Använd Klusterhanteraren för växling vid fel för att ändra maxfel i angivet periodvärde :
- Välj Roller i navigeringsfönstret.
- Under Roller högerklickar du på den klustrade resursen och väljer Egenskaper.
- Välj fliken Redundans och öka maxfelen i angivet periodvärde efter behov.
Resursgränser
Begränsningar för virtuella datorer eller diskar kan resultera i en resursflaskhals som påverkar klustrets hälsotillstånd och hindrar hälsokontrollen. Om du har problem med resursbegränsningar bör du tänka på följande:
- Se till att operativsystemet, drivrutinerna och SQL Server är de senaste versionerna.
- Optimera SQL Server på en virtuell Azure-datormiljö enligt beskrivningen i prestandariktlinjerna för SQL Server på virtuella Azure-datorer
- Minska eller sprida ut arbetsbelastningen för att minska användningen utan att överskrida resursgränserna
- Justera SQL Server-arbetsbelastningen om det finns några möjligheter, till exempel
- Lägga till/optimera index
- Uppdatera statistik om det behövs och om möjligt med fullständig genomsökning
- Använd funktioner som resursguvernör (från och med SQL Server 2014, endast företag) för att begränsa resursanvändningen under specifika arbetsbelastningar, till exempel säkerhetskopior eller indexunderhåll.
- Flytta till en virtuell dator eller disk som har högre gränser för att uppfylla eller överskrida arbetsbelastningens krav.
Nätverk
Distribuera dina virtuella SQL Server-datorer till flera undernät när det är möjligt för att undvika beroendet av en Azure Load Balancer eller ett distribuerat nätverksnamn (DNN) för att dirigera trafik till din HADR-lösning.
Använd ett enda nätverkskort per server (klusternod). Azure-nätverk har fysisk redundans, vilket gör ytterligare nätverkskort onödiga i ett gästkluster för virtuella Azure-datorer. Klusterverifieringsrapporten varnar dig om att noderna endast kan nås i ett enda nätverk. Du kan ignorera den här varningen på gästredundanskluster för virtuella Azure-datorer.
Bandbreddsgränser för en viss virtuell dator delas mellan nätverkskort och tillägg av ytterligare nätverkskort förbättrar inte tillgänglighetsgruppens prestanda för SQL Server på virtuella Azure-datorer. Därför behöver du inte lägga till ett andra nätverkskort.
Dhcp-tjänsten som inte är RFC-kompatibel i Azure kan orsaka att vissa redundansklusterkonfigurationer skapas. Det här felet inträffar eftersom klustrets nätverksnamn tilldelas en duplicerad IP-adress, till exempel samma IP-adress som en av klusternoderna. Det här är ett problem när du använder tillgänglighetsgrupper, som är beroende av funktionen windows-redundanskluster.
Tänk på scenariot när ett kluster med två noder skapas och tas online:
- Klustret är online och sedan begär NODE1 en dynamiskt tilldelad IP-adress för klustrets nätverksnamn.
- DHCP-tjänsten ger ingen annan IP-adress än NODE1:s egen IP-adress eftersom DHCP-tjänsten känner igen att begäran kommer från själva NODE1.
- Windows identifierar att en dubblettadress tilldelas både till NODE1 och till redundansklustrets nätverksnamn, och standardklustergruppen kan inte komma online.
- Standardklustergruppen flyttas till NODE2. NODE2 behandlar NODE1:s IP-adress som kluster-IP-adress och gör att standardklustergruppen är online.
- När NODE2 försöker upprätta anslutning med NODE1 lämnar paket som riktas mot NODE1 aldrig NODE2 eftersom det matchar NODE1:s IP-adress till sig själv. NODE2 kan inte upprätta anslutning med NODE1 och förlorar kvorum och stänger sedan av klustret.
- NODE1 kan skicka paket till NODE2, men NODE2 kan inte svara. NODE1 förlorar kvorum och stänger av klustret.
Du kan undvika det här scenariot genom att tilldela en oanvänd statisk IP-adress till klustrets nätverksnamn för att kunna ansluta klustrets nätverksnamn och lägga till IP-adressen i Azure Load Balancer.
Om SQL Server-databasmotorn, lyssnaren för AlwaysOn-tillgänglighetsgruppen, hälsoavsökningen för redundansklusterinstansen, slutpunkten för databasspegling, klusterkärnans IP-resurs eller någon annan SQL-resurs har konfigurerats för att använda en port mellan 49 152 och 65 536 (standardintervallet för dynamisk port för TCP/IP) lägger du till ett undantag för varje port. Detta förhindrar att andra systemprocesser tilldelas samma port dynamiskt. I följande exempel skapas ett undantag för port 59999:
netsh int ipv4 add excludedportrange tcp startport=59999 numberofports=1 store=persistent
Det är viktigt att konfigurera portundantag när porten inte används, annars misslyckas kommandot med ett meddelande som "Processen kan inte komma åt filen eftersom den används av en annan process".
Om du vill bekräfta att undantagen har konfigurerats korrekt använder du följande kommando: netsh int ipv4 show excludedportrange tcp.
Om du anger det här undantaget för IP-avsökningsporten för tillgänglighetsgrupprollen bör du förhindra händelser som händelse-ID: 1069 med status 10048. Den här händelsen visas i windows redundansklusterhändelser med följande meddelande:
Cluster resource '<IP name in AG role>' of type 'IP Address' in cluster role '<AG Name>' failed.
An Event ID: 1069 with status 10048 can be identified from cluster logs with events like:
Resource IP Address 10.0.1.0 called SetResourceStatusEx: checkpoint 5. Old state OnlinePending, new state OnlinePending, AppSpErrorCode 0, Flags 0, nores=false
IP Address <IP Address 10.0.1.0>: IpaOnlineThread: **Listening on probe port 59999** failed with status **10048**
Status [**10048**](/windows/win32/winsock/windows-sockets-error-codes-2) refers to: **This error occurs** if an application attempts to bind a socket to an **IP address/port that has already been used** for an existing socket.
Detta kan orsakas av en intern process som tar samma port som definieras som avsökningsport. Kom ihåg att avsökningsporten används för att kontrollera statusen för en serverdelspoolinstans från Azure Load Balancer.
Om hälsoavsökningen inte hämtar ett svar från en serverdelsinstans skickas inga nya anslutningar till den serverdelsinstansen förrän hälsoavsökningen lyckas igen.
Kända problem
Granska lösningarna för några vanliga problem och fel.
Resurskonkurrens (i synnerhet I/O) orsakar redundans
Uttömd I/O- eller CPU-kapacitet för den virtuella datorn kan göra att tillgänglighetsgruppen redundansväxlar. Att identifiera den konkurrens som inträffar precis före redundansväxlingen är det mest tillförlitliga sättet att identifiera vad som orsakar automatisk redundans. Övervaka Azure Virtual Machines för att titta på måtten för lagrings-I/O-användning för att förstå svarstiden på virtuell dator eller disknivå.
Följ de här stegen för att granska den övergripande I/O-överbelastningshändelsen för virtuella Azure-datorer:
Navigera till den virtuella datorn i Azure-portalen – inte till de virtuella SQL-datorerna.
Välj Mått under Övervakning för att öppna sidan Mått .
Välj Lokal tid för att ange det tidsintervall som du är intresserad av och tidszonen, antingen lokal för den virtuella datorn eller UTC/GMT.
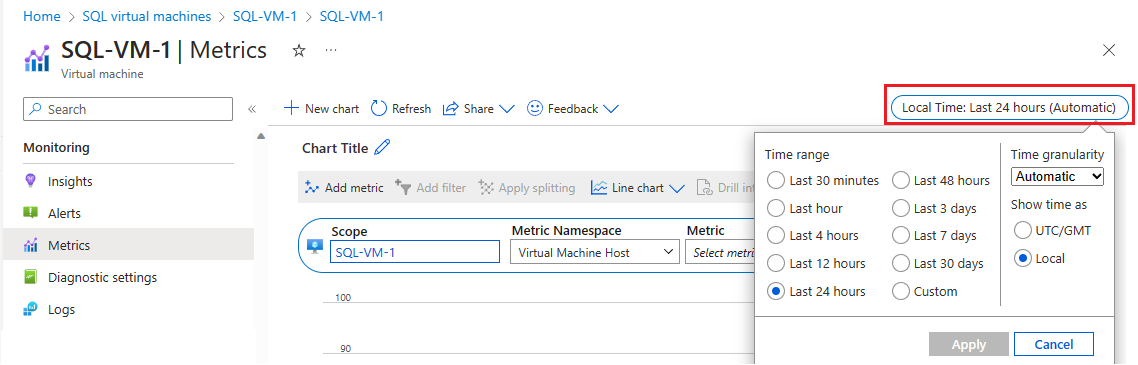
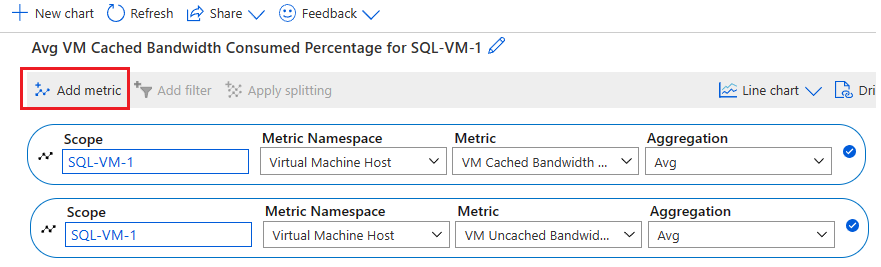
Välj Lägg till mått för att lägga till följande två mått för att se diagrammet:
- Förbrukad vm-cachelagrad bandbredd i procent
- Procentandel ej cachelagrad bandbredd för VM förbrukad
Azure VM HostEvents orsakar redundans
Det är möjligt att en Azure VM HostEvent gör att din tillgänglighetsgrupp redundansväxlar. Om du tror att en Azure VM HostEvent orsakade en redundansväxling kan du kontrollera Azure Monitor-aktivitetsloggen och översikten över Azure VM Resource Health.
Azure Monitor-aktivitetsloggen är en plattformslogg i Azure som ger insikter om händelser på prenumerationsnivå. Aktivitetsloggen innehåller information som när en resurs ändras eller om en virtuell dator startas. Du kan visa aktivitetsloggen i Azure-portalen eller hämta poster med PowerShell och Azure CLI.
Följ dessa steg för att kontrollera Aktivitetsloggen för Azure Monitor:
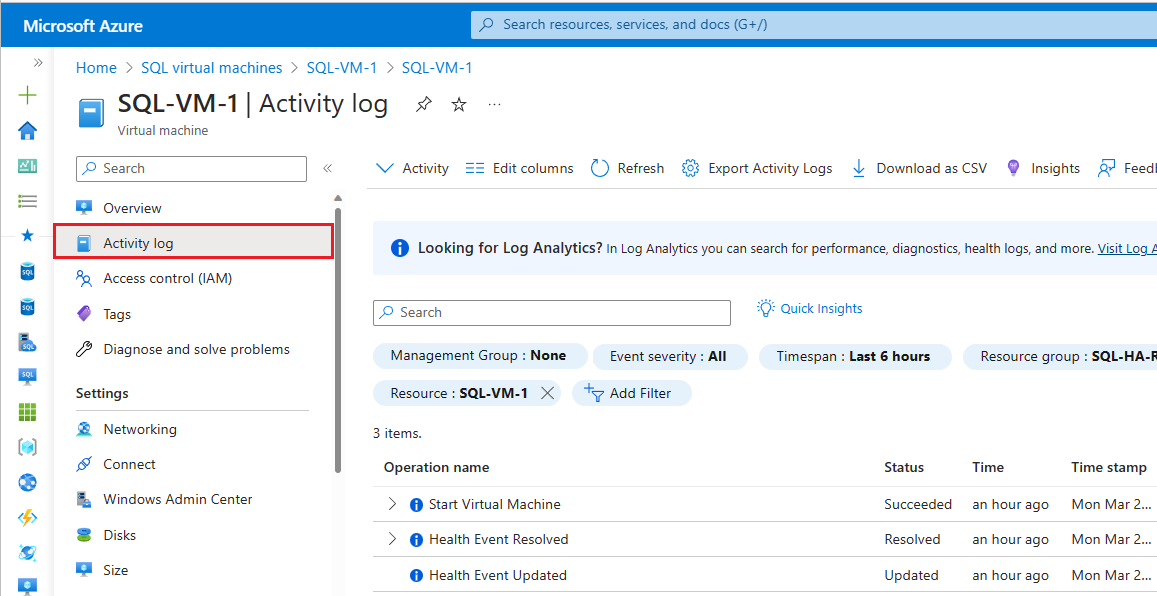
Navigera till den virtuella datorn i Azure-portalen
Välj Aktivitetslogg i fönstret Virtuell dator
Välj Tidsintervall och välj sedan tidsramen när tillgänglighetsgruppen redväxade. Välj Använd.
Om Azure har ytterligare information om rotorsaken till en plattformsinitierad otillgänglighet kan den informationen publiceras på översiktssidan För den virtuella Azure-datorn – Resource Health upp till 72 timmar efter den första otillgängligheten. Den här informationen är endast tillgänglig för virtuella datorer för tillfället.
- Navigera till den virtuella datorn i Azure-portalen
- Välj Resurshälsa under fönstret Hälsa .
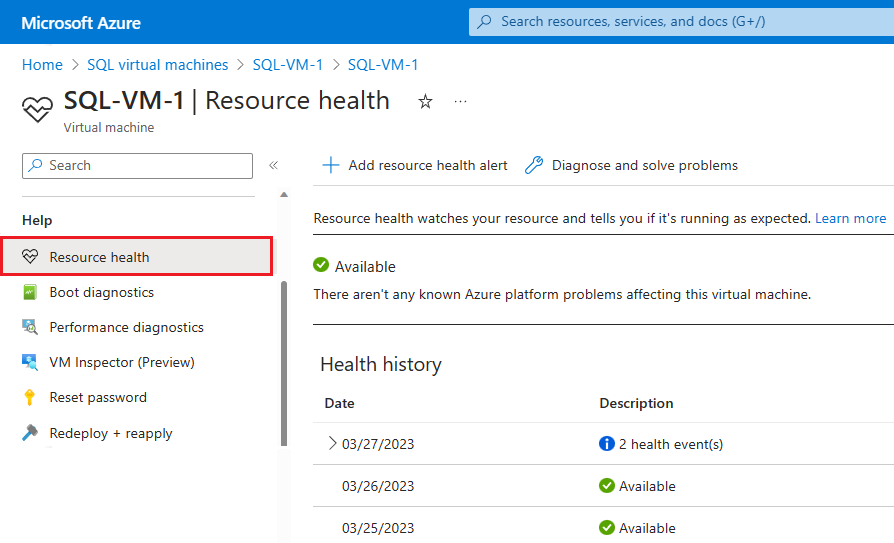
Du kan också konfigurera aviseringar baserat på hälsohändelser från den här sidan.
Klusternoden har tagits bort från medlemskapet
Om inställningarna för Windows-klusters pulsslag och tröskelvärden är för aggressiva för din miljö kan följande meddelande visas ofta i systemhändelseloggen.
Error 1135
Cluster node 'Node1' was removed from the active failover cluster membership.
The Cluster service on this node may have stopped. This could also be due to the node having
lost communication with other active nodes in the failover cluster. Run the Validate a
Configuration Wizard to check your network configuration. If the condition persists, check
for hardware or software errors related to the network adapters on this node. Also check for
failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Mer information finns i Felsöka klusterproblem med händelse-ID 1135.
Lånet har upphört att gälla/Lånet är inte längre giltigt
Om övervakningen är för aggressiv för din miljö kan du se frekventa tillgänglighetsgrupper eller FCI-omstarter, fel eller redundansväxlingar. För tillgänglighetsgrupper kan du dessutom se följande meddelanden i SQL Server-felloggen:
Error 19407: The lease between availability group 'PRODAG' and the Windows Server Failover Cluster has expired.
A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster.
To determine whether the availability group is failing over correctly, check the corresponding availability group
resource in the Windows Server Failover Cluster
Error 19419: The renewal of the lease between availability group '%.*ls' and the Windows Server Failover Cluster
failed because the existing lease is no longer valid.
Tidsgräns för anslutning
Om tidsgränsen för sessionen är för aggressiv för din tillgänglighetsgruppsmiljö kan följande meddelanden visas ofta:
Error 35201: A connection timeout has occurred while attempting to establish a connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or firewall issue exists,
or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
Error 35206
A connection timeout has occurred on a previously established connection to availability
replica 'replicaname' with ID [availability_group_id]. Either a networking or a firewall issue
exists, or the availability replica has transitioned to the resolving role.
Gruppen reder inte över
Om värdet Maximalt antal fel i den angivna perioden är för lågt och det uppstår tillfälliga fel på grund av tillfälliga problem kan tillgänglighetsgruppen hamna i ett feltillstånd. Öka det här värdet för att tolerera mer tillfälliga fel.
Not failing over group <Resource name>, failoverCount 3, failoverThresholdSetting <Number>, computedFailoverThreshold 2.
Händelse 1196 – Nätverksnamnresursen kunde inte registrera associerat DNS-namn
- Gå igenom inställningarna för nätverkskortet för varje klusternod och kontrollera att det inte finns några externa DNS-poster
- Kontrollera att A-posten för klustret finns på dina interna DNS-servrar. Om inte skapar du en ny A-post i DNS-servern för objektet för klusteråtkomstkontroll och markerar kryssrutan för att tillåta autentiserade användare att uppdatera DNS-poster med samma ägarnamn.
- Koppla från resursen ”klusternamn” med IP-resursen och åtgärda den.
Händelse 157 – Disken har tagits bort.
Detta kan inträffa om egenskapen AutomaticClusteringEnabled för lagringsutrymmen är inställd på True för en miljö med tillgänglighetsgrupper (AG). Ändra den till False. En valideringsrapport som körs med lagringsalternativet kan också utlösa diskåterställningen eller den oväntade borttagningshändelsen. Begränsningar i lagringssystemet kan också utlösa den oväntade diskborttagningshändelsen.
Händelse 1206 – Klusternätverksnamnresursen kan inte anslutas.
Det gick inte att uppdatera datorobjektet som är associerat med resursen i domänen. Kontrollera att du har rätt behörigheter för domänen
Windows-klusterfel
Du kan stöta på problem när du konfigurerar ett Windows-redundanskluster eller dess anslutning om du inte har klustertjänstportar öppna för kommunikation.
Om du använder Windows Server 2019 och inte ser någon WINDOWS-kluster-IP har du konfigurerat det distribuerade nätverksnamnet, som endast stöds på SQL Server 2019. Om du har tidigare versioner av SQL Server kan du ta bort och återskapa klustret med nätverksnamnet.
Granska andra fel i Windows-redundansklustringshändelser och deras lösningar här
Nästa steg
Mer information finns i:
- HADR-inställningar för SQL Server på virtuella Azure-datorer
- Windows Server-redundanskluster med SQL Server på virtuella Azure-datorer
- AlwaysOn-tillgänglighetsgrupper med SQL Server på virtuella Azure-datorer
- Windows Server-redundanskluster med SQL Server på virtuella Azure-datorer
- Redundansklusterinstanser med SQL Server på virtuella Azure-datorer
- Översikt över redundansklusterinstans