Excel-filformat i Azure Data Factory och Azure Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Följ den här artikeln när du vill parsa Excel-filerna. Tjänsten stöder både ".xls" och ".xlsx".
Excel-format stöds för följande anslutningsappar: Amazon S3, Amazon S3 Compatible Storage, Azure Blob, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, Google Cloud Storage, HDFS, HTTP, Oracle Cloud Storage och SFTP. Det stöds som källa men inte mottagare.
Kommentar
Formatet ".xls" stöds inte vid användning av HTTP.
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln Datauppsättningar . Det här avsnittet innehåller en lista över egenskaper som stöds av Excel-datauppsättningen.
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till Excel. | Ja |
| plats | Platsinställningar för filen eller filerna. Varje filbaserad anslutningsapp har en egen platstyp och egenskaper som stöds under location. |
Ja |
| sheetName | Excel-kalkylbladets namn för att läsa data. | Ange sheetName eller sheetIndex |
| sheetIndex | Excel-kalkylbladsindexet för att läsa data från och med 0. | Ange sheetName eller sheetIndex |
| intervall | Cellområdet i det angivna kalkylbladet för att hitta selektiva data, t.ex. – Inte angivet: läser hela kalkylbladet som en tabell från den första icke-tomma raden och kolumnen - A3: läser en tabell från den angivna cellen, identifierar dynamiskt alla rader nedan och alla kolumner till höger- A3:H5: läser det här fasta intervallet som en tabell- A3:A3: läser den här enskilda cellen |
Nej |
| firstRowAsHeader | Anger om den första raden i det angivna kalkylbladet/intervallet ska behandlas som en rubrikrad med namn på kolumner. Tillåtna värden är true och false (standard). |
Nej |
| nullValue | Anger strängrepresentationen av null-värdet. Standardvärdet är tom sträng. |
Nej |
| komprimering | Grupp med egenskaper för att konfigurera filkomprimering. Konfigurera det här avsnittet när du vill utföra komprimering/dekomprimering under aktivitetskörningen. | Nej |
| type (under compression) |
Komprimeringskodcen som används för att läsa/skriva JSON-filer. Tillåtna värden är bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy eller lz4. Standardvärdet komprimeras inte. Observera att kopieringsaktiviteten för närvarande inte stöder "snappy" och "lz4", och mappning av dataflödet stöder inte "ZipDeflate", "TarGzip" och "Tar". Obs! När du använder kopieringsaktivitet för att expandera ZipDeflate-filer och skriva till filbaserat datalager för mottagare extraheras filerna till mappen: <path specified in dataset>/<folder named as source zip file>/. |
Nej. |
| nivå (under compression) |
Komprimeringsförhållandet. Tillåtna värden är optimala eller snabbaste. - Snabbast: Komprimeringsåtgärden bör slutföras så snabbt som möjligt, även om den resulterande filen inte komprimeras optimalt. - Optimal: Komprimeringsåtgärden bör komprimeras optimalt, även om åtgärden tar längre tid att slutföra. Mer information finns i avsnittet Komprimeringsnivå . |
Nej |
Nedan visas ett exempel på Excel-datauppsättning i Azure Blob Storage:
{
"name": "ExcelDataset",
"properties": {
"type": "Excel",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"sheetName": "MyWorksheet",
"range": "A3:H5",
"firstRowAsHeader": true
}
}
}
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av Excel-källan.
Excel som källa
Följande egenskaper stöds i avsnittet kopieringsaktivitet *källa* .
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till ExcelSource. | Ja |
| storeSettings | En grupp med egenskaper för hur du läser data från ett datalager. Varje filbaserad anslutningsapp har egna läsinställningar som stöds under storeSettings. |
Nej |
"activities": [
{
"name": "CopyFromExcel",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ExcelSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
...
}
...
}
]
Mappa dataflödesegenskaper
När du mappar dataflöden kan du läsa Excel-format i följande datalager: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Amazon S3 och SFTP. Du kan peka på Excel-filer antingen med hjälp av Excel-datauppsättningen eller med hjälp av en infogad datauppsättning.
Källegenskaper
Tabellen nedan visar de egenskaper som stöds av en Excel-källa. Du kan redigera dessa egenskaper på fliken Källalternativ . När du använder infogad datauppsättning visas ytterligare filinställningar, som är samma som egenskaperna som beskrivs i avsnittet egenskaper för datamängd.
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Sökvägar för jokertecken | Alla filer som matchar sökvägen för jokertecken bearbetas. Åsidosätter den mapp och filsökväg som angetts i datauppsättningen. | nej | Sträng[] | wildcardPaths |
| Partitionsrotsökväg | För fildata som är partitionerade kan du ange en partitionsrotsökväg för att läsa partitionerade mappar som kolumner | nej | String | partitionRootPath |
| Lista över filer | Om källan pekar på en textfil som visar filer som ska bearbetas | nej | true eller false |
fileList |
| Kolumn för att lagra filnamn | Skapa en ny kolumn med källfilens namn och sökväg | nej | String | rowUrlColumn |
| Efter slutförande | Ta bort eller flytta filerna efter bearbetningen. Filsökvägen startar från containerroten | nej | Ta bort: true eller false Flytta: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filtrera efter senast ändrad | Välj att filtrera filer baserat på när de senast ändrades | nej | Tidsstämpel | modifiedAfter modifiedBefore |
| Tillåt att inga filer hittas | Om sant utlöses inte ett fel om inga filer hittas | nej | true eller false |
ignoreNoFilesFound |
Källexempel
Bilden nedan är ett exempel på en Excel-källkonfiguration i mappning av dataflöden med hjälp av datauppsättningsläge.
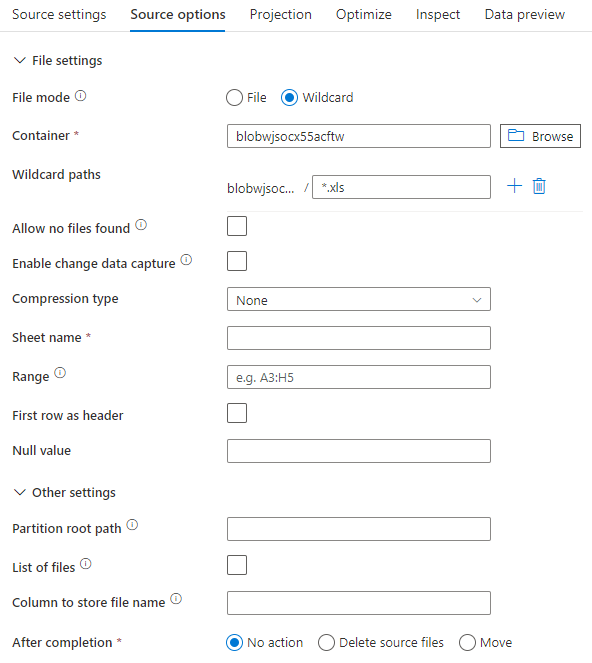
Det associerade dataflödesskriptet är:
source(allowSchemaDrift: true,
validateSchema: false,
wildcardPaths:['*.xls']) ~> ExcelSource
Om du använder infogad datauppsättning visas följande källalternativ i mappning av dataflöde.
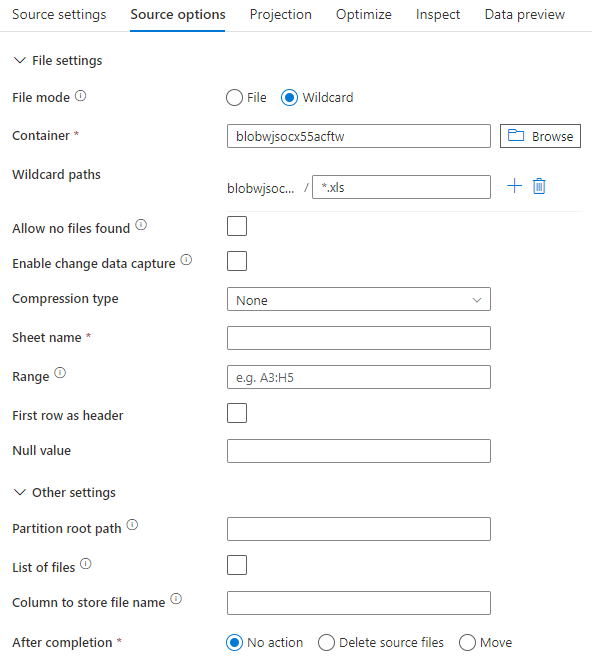
Det associerade dataflödesskriptet är:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'excel',
fileSystem: 'container',
folderPath: 'path',
fileName: 'sample.xls',
sheetName: 'worksheet',
firstRowAsHeader: true) ~> ExcelSourceInlineDataset
Hantera mycket stora Excel-filer
Excel-anslutningsappen stöder inte direktuppspelningsläsning för kopieringsaktiviteten och måste läsa in hela filen i minnet innan data kan läsas. Om du vill importera schema, förhandsgranska data eller uppdatera en Excel-datauppsättning måste data returneras före tidsgränsen för http-begäran (100-talet). För stora Excel-filer kanske dessa åtgärder inte slutförs inom den tidsramen, vilket orsakar ett tidsgränsfel. Om du vill flytta stora Excel-filer (>100 MB) till ett annat datalager kan du använda något av följande alternativ för att kringgå den här begränsningen:
- Använd den lokala integrationskörningen (SHIR) och använd sedan aktiviteten Kopiera för att flytta den stora Excel-filen till ett annat datalager med SHIR.
- Dela upp den stora Excel-filen i flera mindre och använd sedan aktiviteten Kopiera för att flytta mappen som innehåller filerna.
- Använd en dataflödesaktivitet för att flytta den stora Excel-filen till ett annat datalager. Dataflöde stöder direktuppläsning för Excel och kan snabbt flytta/överföra stora filer.
- Konvertera den stora Excel-filen manuellt till CSV-format och använd sedan en kopieringsaktivitet för att flytta filen.