Kopiera data från Oracle Cloud Storage med Hjälp av Azure Data Factory eller Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du kopierar data från Oracle Cloud Storage. Mer information finns i introduktionsartiklarna för Azure Data Factory och Synapse Analytics.
Funktioner som stöds
Den här Oracle Cloud Storage-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| Kopieringsaktivitet (källa/-) | (1) (2) |
| Sökningsaktivitet | (1) (2) |
| GetMetadata-aktivitet | (1) (2) |
| Ta bort aktivitet | (1) (2) |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
Mer specifikt stöder den här Oracle Cloud Storage-anslutningsappen kopiering av filer som är eller parsning av filer med de filformat och komprimeringskodex som stöds. Den drar nytta av Oracle Cloud Storages S3-kompatibla samverkan.
Förutsättningar
Om du vill kopiera data från Oracle Cloud Storage kan du läsa de krav och behörigheter som krävs här .
Komma igång
Om du vill utföra kopieringsaktiviteten med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
Skapa en länkad tjänst till Oracle Cloud Storage med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad tjänst till Oracle Cloud Storage i Användargränssnittet för Azure-portalen.
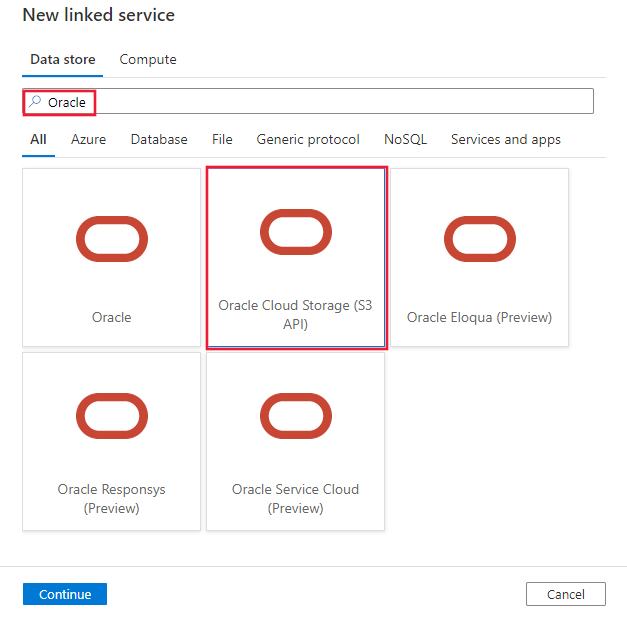
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter Oracle och välj Oracle Cloud Storage-anslutningsappen.
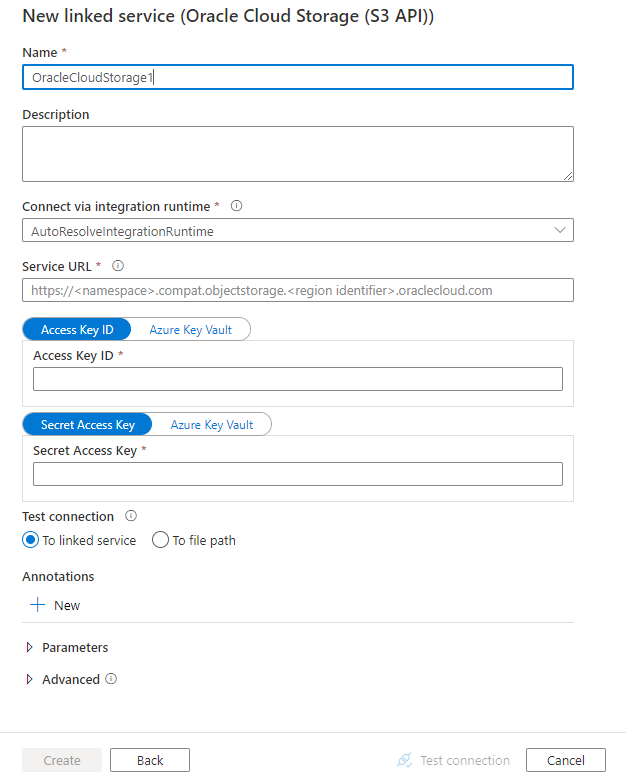
Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som används för att definiera entiteter som är specifika för Oracle Cloud Storage.
Länkade tjänstegenskaper
Följande egenskaper stöds för länkade Oracle Cloud Storage-tjänster:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste vara inställd på OracleCloudStorage. | Ja |
| accessKeyId | ID för den hemliga åtkomstnyckeln. Information om hur du hittar åtkomstnyckeln och hemligheten finns i Krav. | Ja |
| secretAccessKey | Själva den hemliga åtkomstnyckeln. Markera det här fältet som SecureString för att lagra det på ett säkert sätt eller referera till en hemlighet som lagras i Azure Key Vault. | Ja |
| serviceUrl | Ange den anpassade slutpunkten som https://<namespace>.compat.objectstorage.<region identifier>.oraclecloud.com. Mer information finns här |
Ja |
| connectVia | Den integrationskörning som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller integrationskörningen med egen värd (om ditt datalager finns i ett privat nätverk). Om den här egenskapen inte har angetts använder tjänsten standardkörningen för Azure-integrering. | Nej |
Här är ett exempel:
{
"name": "OracleCloudStorageLinkedService",
"properties": {
"type": "OracleCloudStorage",
"typeProperties": {
"accessKeyId": "<access key id>",
"secretAccessKey": {
"type": "SecureString",
"value": "<secret access key>"
},
"serviceUrl": "https://<namespace>.compat.objectstorage.<region identifier>.oraclecloud.com"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för datauppsättning
Azure Data Factory stöder följande filformat. Se varje artikel för formatbaserade inställningar.
- Avro-format
- Binärt format
- Avgränsat textformat
- Excel-format
- JSON-format
- ORC-format
- Parquet-format
- XML-format
Följande egenskaper stöds för Oracle Cloud Storage under location inställningar i en formatbaserad datauppsättning:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen under location i datamängden måste anges till OracleCloudStorageLocation. |
Ja |
| bucketName | Bucketnamnet för Oracle Cloud Storage. | Ja |
| folderPath | Sökvägen till mappen under den angivna bucketen. Om du vill använda ett jokertecken för att filtrera mappen hoppar du över den här inställningen och anger den i inställningarna för aktivitetskällan. | Nej |
| fileName | Filnamnet under den angivna bucketen och mappsökvägen. Om du vill använda ett jokertecken för att filtrera filerna hoppar du över den här inställningen och anger det i inställningarna för aktivitetskällan. | Nej |
Exempel:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Oracle Cloud Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "OracleCloudStorageLocation",
"bucketName": "bucketname",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som Oracle Cloud Storage-källan stöder.
Oracle Cloud Storage som källtyp
Azure Data Factory stöder följande filformat. Se varje artikel för formatbaserade inställningar.
- Avro-format
- Binärt format
- Avgränsat textformat
- Excel-format
- JSON-format
- ORC-format
- Parquet-format
- XML-format
Följande egenskaper stöds för Oracle Cloud Storage under storeSettings inställningar i en formatbaserad kopieringskälla:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen under storeSettings måste vara inställd på OracleCloudStorageReadSettings. |
Ja |
| Leta upp filerna som ska kopieras: | ||
| ALTERNATIV 1: statisk sökväg |
Kopiera från den angivna bucketen eller mapp-/filsökvägen som anges i datauppsättningen. Om du vill kopiera alla filer från en bucket eller mapp anger du wildcardFileName dessutom som *. |
|
| ALTERNATIV 2: Oracle Cloud Storage-prefix -prefix |
Prefix för Oracle Cloud Storage-nyckelnamnet under den angivna bucketen som konfigurerats i datauppsättningen för att filtrera Oracle Cloud Storage-källfiler. Oracle Cloud Storage-nycklar vars namn börjar med bucket_in_dataset/this_prefix har valts. Den använder Oracle Cloud Storages filter på tjänstsidan, vilket ger bättre prestanda än ett jokerteckenfilter. |
Nej |
| ALTERNATIV 3: jokertecken - jokerteckenFolderPath |
Mappsökvägen med jokertecken under den angivna bucketen som konfigurerats i en datauppsättning för att filtrera källmappar. Tillåtna jokertecken är: * (matchar noll eller fler tecken) och ? (matchar noll eller enskilt tecken). Använd ^ för att fly om mappnamnet har ett jokertecken eller det här escape-tecknet inuti. Se fler exempel i exempel på mapp- och filfilter. |
Nej |
| ALTERNATIV 4: jokertecken - jokerteckenFileName |
Filnamnet med jokertecken under den angivna bucket- och mappsökvägen (eller sökvägen till jokerteckenmappen) för att filtrera källfiler. Tillåtna jokertecken är: * (matchar noll eller fler tecken) och ? (matchar noll eller enskilt tecken). Använd ^ för att fly om filnamnet har ett jokertecken eller det här escape-tecknet inuti. Se fler exempel i exempel på mapp- och filfilter. |
Ja |
| ALTERNATIV 5: en lista över filer – fileListPath |
Anger att en angiven filuppsättning ska kopieras. Peka på en textfil som innehåller en lista över filer som du vill kopiera, en fil per rad, vilket är den relativa sökvägen till sökvägen som konfigurerats i datauppsättningen. När du använder det här alternativet ska du inte ange filnamnet i datauppsättningen. Se fler exempel i fillisteexempel. |
Nej |
| Ytterligare inställningar: | ||
| rekursiv | Anger om data läse rekursivt från undermapparna eller endast från den angivna mappen. Observera att när rekursivt är inställt på sant och mottagaren är ett filbaserat arkiv kopieras eller skapas inte en tom mapp eller undermapp i mottagaren. Tillåtna värden är sanna (standard) och falska. Den här egenskapen gäller inte när du konfigurerar fileListPath. |
Nej |
| deleteFilesAfterCompletion | Anger om de binära filerna kommer att tas bort från källarkivet när de har flyttats till målarkivet. Filborttagningen är per fil, så när kopieringsaktiviteten misslyckas ser du att vissa filer redan har kopierats till målet och tagits bort från källan, medan andra fortfarande finns kvar i källarkivet. Den här egenskapen är endast giltig i scenariot med kopiering av binära filer. Standardvärdet: false. |
Nej |
| modifiedDatetimeStart | Filer filtreras baserat på attributet: senast ändrad. Filerna väljs om deras senaste ändringstid är större än eller lika med modifiedDatetimeStart och mindre än modifiedDatetimeEnd. Tiden tillämpas på UTC-tidszonen i formatet "2018-12-01T05:00:00Z". Egenskaperna kan vara NULL, vilket innebär att inget filattributfilter tillämpas på datamängden. När modifiedDatetimeStart har ett datetime-värde men modifiedDatetimeEnd är NULL väljs de filer vars senast ändrade attribut är större än eller lika med datetime-värdet. När modifiedDatetimeEnd har ett datetime-värde men modifiedDatetimeStart är NULL väljs de filer vars senast ändrade attribut är mindre än datetime-värdet.Den här egenskapen gäller inte när du konfigurerar fileListPath. |
Nej |
| modifiedDatetimeEnd | Samma som ovan. | Nej |
| enablePartitionDiscovery | För filer som är partitionerade anger du om partitionerna ska parsas från filsökvägen och lägga till dem som ytterligare källkolumner. Tillåtna värden är false (standard) och true. |
Nej |
| partitionRootPath | När partitionsidentifiering är aktiverat anger du den absoluta rotsökvägen för att läsa partitionerade mappar som datakolumner. Om det inte anges, som standard, – När du använder filsökvägen i datauppsättningen eller listan över filer på källan är partitionsrotsökvägen den sökväg som konfigurerats i datauppsättningen. – När du använder mappfilter för jokertecken är partitionsrotsökvägen undersökvägen före det första jokertecknet. Anta till exempel att du konfigurerar sökvägen i datauppsättningen som "root/folder/year=2020/month=08/day=27": – Om du anger partitionsrotsökväg som "root/folder/year=2020" genererar kopieringsaktiviteten ytterligare två kolumner month och day med värdet "08" respektive "27", utöver kolumnerna i filerna.– Om partitionsrotsökvägen inte har angetts genereras ingen extra kolumn. |
Nej |
| maxConcurrentConnections | Den övre gränsen för samtidiga anslutningar som upprättats till datalagret under aktivitetskörningen. Ange endast ett värde när du vill begränsa samtidiga anslutningar. | Nej |
Exempel:
"activities":[
{
"name": "CopyFromOracleCloudStorage",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "OracleCloudStorageReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Exempel på mapp- och filfilter
I det här avsnittet beskrivs det resulterande beteendet för mappsökvägen och filnamnet med jokerteckenfilter.
| hink | key | rekursiv | Källmappens struktur och filterresultat (filer i fetstil hämtas) |
|---|---|---|---|
| hink | Folder*/* |
falskt | hink MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| hink | Folder*/* |
true | hink MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| hink | Folder*/*.csv |
falskt | hink MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
| hink | Folder*/*.csv |
true | hink MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Exempel på fillista
I det här avsnittet beskrivs det resulterande beteendet med att använda en sökväg för en fillista i kopieringsaktivitetskällan.
Anta att du har följande källmappstruktur och vill kopiera filerna i fetstil:
| Exempel på källstruktur | Innehåll i FileListToCopy.txt | Konfiguration |
|---|---|---|
| hink MappA File1.csv File2.json Undermapp1 File3.csv File4.json File5.csv Metadata FileListToCopy.txt |
File1.csv Undermapp1/File3.csv Undermapp1/File5.csv |
I datauppsättning: -Hink: bucket– Mappsökväg: FolderAI kopieringsaktivitetskällan: – Sökväg till fillista: bucket/Metadata/FileListToCopy.txt Sökvägen till fillistan pekar på en textfil i samma datalager som innehåller en lista över filer som du vill kopiera, en fil per rad, med den relativa sökvägen till sökvägen som konfigurerats i datauppsättningen. |
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Egenskaper för GetMetadata-aktivitet
Mer information om egenskaperna finns i GetMetadata-aktiviteten.
Ta bort aktivitetsegenskaper
Information om egenskaperna finns i Ta bort aktivitet.
Relaterat innehåll
En lista över datalager som kopieringsaktiviteten stöder som källor och mottagare finns i Datalager som stöds.