JSON-format i Azure Data Factory och Azure Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Följ den här artikeln när du vill parsa JSON-filerna eller skriva data i JSON-format.
JSON-format stöds för följande anslutningsappar:
- Amazon S3
- Amazon S3-kompatibel lagring,
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- Filsystem
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln Datauppsättningar . Det här avsnittet innehåller en lista över egenskaper som stöds av JSON-datauppsättningen.
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till Json. | Ja |
| plats | Platsinställningar för filen eller filerna. Varje filbaserad anslutningsapp har en egen platstyp och egenskaper som stöds under location. Mer information finns i artikeln om anslutningsappar –> avsnittet Egenskaper för datauppsättning. |
Ja |
| encodingName | Kodningstypen som används för att läsa/skriva testfiler. Tillåtna värden är följande: "UTF-8",UTF-8 utan BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM86"4", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859 -3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". |
Nej |
| komprimering | Grupp med egenskaper för att konfigurera filkomprimering. Konfigurera det här avsnittet när du vill utföra komprimering/dekomprimering under aktivitetskörningen. | Nej |
| type (under compression) |
Komprimeringskodcen som används för att läsa/skriva JSON-filer. Tillåtna värden är bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy eller lz4. Standardvärdet komprimeras inte. Observera att kopieringsaktiviteten för närvarande inte stöder "snappy" och "lz4", och mappning av dataflöde stöder inte "ZipDeflate", "TarGzip" och "Tar". Observera att när du använder kopieringsaktivitet för att dekomprimera ZipDeflate/TarGzip/Tar-filer och skriva till filbaserade mottagardatalager extraheras som standardfiler till mappen: <path specified in dataset>/<folder named as source compressed file>/, använd/preserveCompressionFileNameAsFolder preserveZipFileNameAsFolderpå kopieringsaktivitetskällan för att kontrollera om namnet på de komprimerade filerna ska behållas som mappstruktur. |
Nej. |
| nivå (under compression) |
Komprimeringsförhållandet. Tillåtna värden är optimala eller snabbaste. - Snabbast: Komprimeringsåtgärden bör slutföras så snabbt som möjligt, även om den resulterande filen inte komprimeras optimalt. - Optimal: Komprimeringsåtgärden bör komprimeras optimalt, även om åtgärden tar längre tid att slutföra. Mer information finns i avsnittet Komprimeringsnivå . |
Nej |
Nedan visas ett exempel på JSON-datauppsättning i Azure Blob Storage:
{
"name": "JSONDataset",
"properties": {
"type": "Json",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compression": {
"type": "gzip"
}
}
}
}
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av JSON-källan och mottagaren.
Lär dig mer om hur du extraherar data från JSON-filer och mappar till datalager/-format eller vice versa från schemamappning.
JSON som källa
Följande egenskaper stöds i avsnittet kopieringsaktivitet *källa* .
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till JSONSource. | Ja |
| formatInställningar | En grupp med egenskaper. Läs inställningstabellen för JSON nedan. | Nej |
| storeSettings | En grupp med egenskaper för hur du läser data från ett datalager. Varje filbaserad anslutningsapp har egna läsinställningar som stöds under storeSettings. Mer information finns i artikeln om anslutningsappar –> avsnittet Kopiera aktivitetsegenskaper. |
Nej |
JSON-läsinställningar som stöds under formatSettings:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typen av formatInställningar måste anges till JsonReadSettings. | Ja |
| compressionProperties | En grupp med egenskaper för hur du dekomprimeras data för en viss komprimeringskodc. | Nej |
| preserveZipFileNameAsFolder (under compressionProperties->type som ZipDeflateReadSettings) |
Gäller när indatauppsättningen konfigureras med ZipDeflate-komprimering . Anger om käll-zip-filnamnet ska behållas som mappstruktur under kopiering. – När värdet är true (standard) skriver tjänsten uppackade filer till <path specified in dataset>/<folder named as source zip file>/.– När värdet är falskt skriver tjänsten uppackade filer direkt till <path specified in dataset>. Kontrollera att du inte har duplicerade filnamn i olika zip-källfiler för att undvika racing eller oväntat beteende. |
Nej |
| preserveCompressionFileNameAsFolder (under compressionProperties->type som TarGZipReadSettings eller TarReadSettings) |
Gäller när indatauppsättningen konfigureras med TarGzip/Tar-komprimering. Anger om källans komprimerade filnamn ska bevaras som mappstruktur under kopieringen. – När värdet är true (standard) skriver tjänsten dekomprimerade filer till <path specified in dataset>/<folder named as source compressed file>/. – När värdet är falskt skriver tjänsten dekomprimerade filer direkt till <path specified in dataset>. Kontrollera att du inte har duplicerade filnamn i olika källfiler för att undvika racing eller oväntat beteende. |
Nej |
JSON som mottagare
Följande egenskaper stöds i avsnittet kopieringsaktivitet *mottagare* .
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till JSONSink. | Ja |
| formatInställningar | En grupp med egenskaper. Se tabellen för JSON-skrivinställningar nedan. | Nej |
| storeSettings | En grupp med egenskaper för hur du skriver data till ett datalager. Varje filbaserad anslutningsapp har egna skrivinställningar som stöds under storeSettings. Mer information finns i artikeln om anslutningsappar –> avsnittet Kopiera aktivitetsegenskaper. |
Nej |
JSON-skrivinställningar som stöds under formatSettings:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typen av formatInställningar måste anges till JsonWriteSettings. | Ja |
| filePattern | Ange mönstret för de data som lagras i varje JSON-fil. Tillåtna värden är: setOfObjects (JSON Lines) och arrayOfObjects. Standardvärdet är setOfObjects. Detaljerad information om dessa mönster finns i avsnittet om JSON-filmönster. | Nej |
JSON-filmönster
När du kopierar data från JSON-filer kan kopieringsaktivitet automatiskt identifiera och parsa följande mönster för JSON-filer. När du skriver data till JSON-filer kan du konfigurera filmönstret på kopieringsaktivitetsmottagaren.
Typ I: setOfObjects
Varje fil innehåller enskilda objekt, JSON-rader eller sammanfogade objekt.
Exempel på JSON med enskilda objekt
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }JSON-rader (standard för mottagare)
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}Exempel med sammanfogad JSON
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Typ II: arrayOfObjects
Varje fil innehåller en matris med objekt.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Mappa dataflödesegenskaper
När du mappar dataflöden kan du läsa och skriva till JSON-format i följande datalager: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 och SFTP, och du kan läsa JSON-format i Amazon S3.
Källegenskaper
Tabellen nedan visar de egenskaper som stöds av en json-källa. Du kan redigera dessa egenskaper på fliken Källalternativ .
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Sökvägar för jokertecken | Alla filer som matchar sökvägen för jokertecken bearbetas. Åsidosätter den mapp och filsökväg som angetts i datauppsättningen. | nej | Sträng[] | wildcardPaths |
| Partitionsrotsökväg | För fildata som är partitionerade kan du ange en partitionsrotsökväg för att läsa partitionerade mappar som kolumner | nej | String | partitionRootPath |
| Lista över filer | Om källan pekar på en textfil som visar filer som ska bearbetas | nej | true eller false |
fileList |
| Kolumn för att lagra filnamn | Skapa en ny kolumn med källfilens namn och sökväg | nej | String | rowUrlColumn |
| Efter slutförande | Ta bort eller flytta filerna efter bearbetningen. Filsökvägen startar från containerroten | nej | Ta bort: true eller false Flytta: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filtrera efter senast ändrad | Välj att filtrera filer baserat på när de senast ändrades | nej | Tidsstämpel | modifiedAfter modifiedBefore |
| Enskilt dokument | Mappa dataflöden läs ett JSON-dokument från varje fil | nej | true eller false |
singleDocument |
| Namn på ociterade kolumner | Om namn på ociterade kolumner är markerade läser mappning av dataflöden JSON-kolumner som inte omges av citattecken. | nej | true eller false |
unquotedColumnNames |
| Har kommentarer | Välj Har kommentarer om JSON-data har C- eller C++-formatkommenteringar | nej | true eller false |
asComments |
| Enkel citerad | Läser JSON-kolumner som inte omges av citattecken | nej | true eller false |
singleQuoted |
| Omvänt snedstreck har undantagit | Välj Omvänt snedstreck undantagna om omvänt snedstreck används för att undkomma tecken i JSON-data | nej | true eller false |
backslashEscape |
| Tillåt att inga filer hittas | Om sant utlöses inte ett fel om inga filer hittas | nej | true eller false |
ignoreNoFilesFound |
Infogad datauppsättning
Mappning av dataflöden stöder "infogade datauppsättningar" som ett alternativ för att definiera din källa och mottagare. En infogad JSON-datauppsättning definieras direkt i dina käll- och mottagartransformeringar och delas inte utanför det definierade dataflödet. Det är användbart för att parametrisera datamängdsegenskaper direkt i ditt dataflöde och kan dra nytta av bättre prestanda jämfört med delade ADF-datauppsättningar.
När du läser ett stort antal källmappar och filer kan du förbättra prestandan för identifiering av dataflödesfiler genom att ange alternativet "Användarprojekterat schema" i Projektion | Dialogrutan Schemaalternativ. Det här alternativet inaktiverar automatisk identifiering av ADF-standardschemat och förbättrar prestandan för filidentifiering avsevärt. Innan du anger det här alternativet måste du importera JSON-projektionen så att ADF har ett befintligt schema för projektion. Det här alternativet fungerar inte med schemaavvikelse.
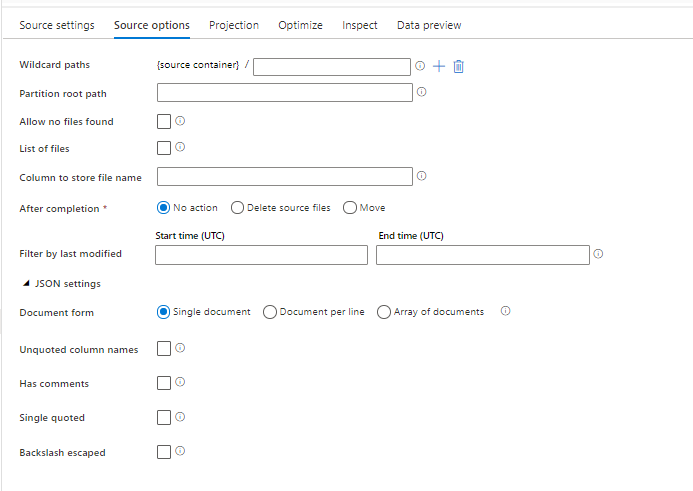
Alternativ för källformat
Om du använder en JSON-datauppsättning som källa i dataflödet kan du ange ytterligare fem inställningar. De här inställningarna finns under JSON-inställningarnas dragspel på fliken Källalternativ . För inställningen Dokumentformulär kan du välja ett av dokumenttyperna Enskilt dokument, Dokument per rad och Matris .
Standardvärde
Som standard läss JSON-data i följande format.
{ "json": "record 1" }
{ "json": "record 2" }
{ "json": "record 3" }
Enskilt dokument
Om Ett enskilt dokument är markerat läser mappning av dataflöden ett JSON-dokument från varje fil.
File1.json
{
"json": "record 1"
}
File2.json
{
"json": "record 2"
}
File3.json
{
"json": "record 3"
}
Om Dokument per rad är markerat läser mappning av dataflöden ett JSON-dokument från varje rad i en fil.
File1.json
{"json": "record 1"}
File2.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
File3.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}
Om matris med dokument har valts läser mappning av dataflöden en matris med dokument från en fil.
File.json
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
Kommentar
Om dataflöden utlöser ett fel som anger "corrupt_record" när du förhandsgranskar dina JSON-data, är det troligt att dina data innehåller ett enda dokument i JSON-filen. Om du anger "enskilt dokument" bör det felet rensas.
Namn på ociterade kolumner
Om namn på ociterade kolumner är markerade läser mappning av dataflöden JSON-kolumner som inte omges av citattecken.
{ json: "record 1" }
{ json: "record 2" }
{ json: "record 3" }
Har kommentarer
Välj Har kommentarer om JSON-data har C- eller C++-formatkommenteringar.
{ "json": /** comment **/ "record 1" }
{ "json": "record 2" }
{ /** comment **/ "json": "record 3" }
Enkel citerad
Välj Enkel citerad om JSON-fälten och värdena använder enkla citattecken i stället för dubbla citattecken.
{ 'json': 'record 1' }
{ 'json': 'record 2' }
{ 'json': 'record 3' }
Omvänt snedstreck har undantagit
Välj Omvänt snedstreck undantaget om omvänt snedstreck används för att undkomma tecken i JSON-data.
{ "json": "record 1" }
{ "json": "\} \" \' \\ \n \\n record 2" }
{ "json": "record 3" }
Egenskaper för mottagare
Tabellen nedan visar de egenskaper som stöds av en json-mottagare. Du kan redigera de här egenskaperna på fliken Inställningar .
| Name | beskrivning | Obligatoriskt | Tillåtna värden | Egenskap för dataflödesskript |
|---|---|---|---|---|
| Rensa mappen | Om målmappen rensas före skrivning | nej | true eller false |
trunkera |
| Filnamnsalternativ | Namngivningsformatet för de data som skrivits. Som standard är en fil per partition i format part-#####-tid-<guid> |
nej | Mönster: Sträng Per partition: String[] Som data i kolumnen: Sträng Utdata till en enskild fil: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Skapa JSON-strukturer i en härledd kolumn
Du kan lägga till en komplex kolumn i dataflödet via uttrycksverktyget för härledda kolumner. I omvandlingen av den härledda kolumnen lägger du till en ny kolumn och öppnar uttrycksverktyget genom att klicka på den blå rutan. Om du vill göra en kolumn komplex kan du ange JSON-strukturen manuellt eller använda UX för att lägga till underkolumner interaktivt.
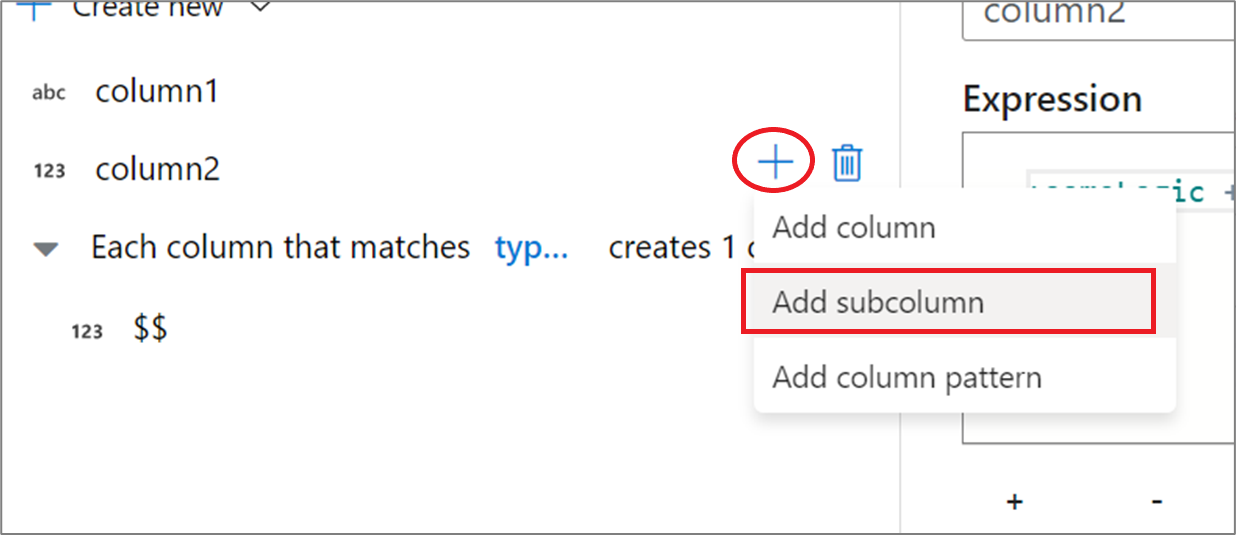
Använda uttrycksverktygets UX
Hovra över en kolumn i fönstret för utdataschemat och klicka på plusikonen. Välj Lägg till underkolumn för att göra kolumnen till en komplex typ.
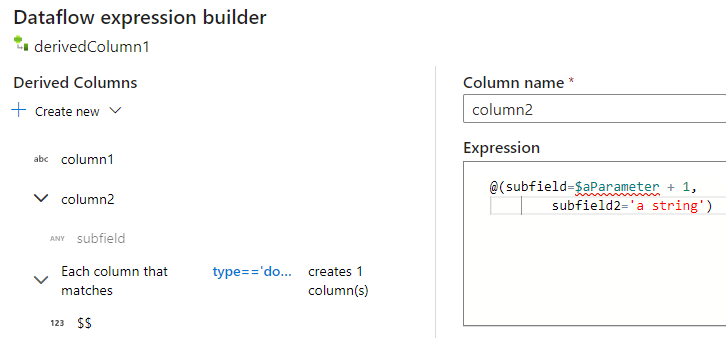
Du kan lägga till ytterligare kolumner och underkolumner på samma sätt. För varje icke-komplext fält kan ett uttryck läggas till i uttrycksredigeraren till höger.
Ange JSON-strukturen manuellt
Om du vill lägga till en JSON-struktur manuellt lägger du till en ny kolumn och anger uttrycket i redigeraren. Uttrycket följer följande allmänna format:
@(
field1=0,
field2=@(
field1=0
)
)
Om det här uttrycket angavs för en kolumn med namnet "complexColumn" skulle det skrivas till mottagaren som följande JSON:
{
"complexColumn": {
"field1": 0,
"field2": {
"field1": 0
}
}
}
Exempel på manuellt skript för fullständig hierarkisk definition
@(
title=Title,
firstName=FirstName,
middleName=MiddleName,
lastName=LastName,
suffix=Suffix,
contactDetails=@(
email=EmailAddress,
phone=Phone
),
address=@(
line1=AddressLine1,
line2=AddressLine2,
city=City,
state=StateProvince,
country=CountryRegion,
postCode=PostalCode
),
ids=[
toString(CustomerID), toString(AddressID), rowguid
]
)
Relaterade anslutningsappar och format
Här följer några vanliga anslutningsappar och format som är relaterade till JSON-formatet: