Installera notebook-beroenden
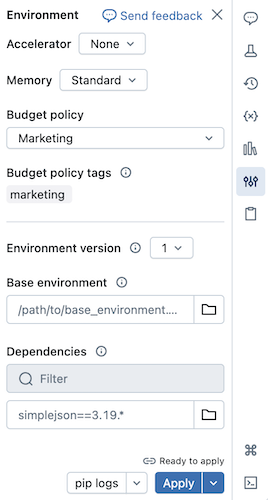
Du kan installera Python-beroenden för serverlösa notebook-filer med hjälp av panelen På miljösidan . Den här panelen innehåller en enda plats där du kan redigera, visa och exportera en notebook-fils bibliotekskrav. Dessa beroenden kan läggas till med hjälp av en basmiljö eller individuellt.
Information om uppgifter som inte är notebook-uppgifter finns i Konfigurera miljöer och beroenden för uppgifter som inte är notebook-uppgifter.
Viktigt!
Installera inte PySpark eller något bibliotek som installerar PySpark som ett beroende av dina serverlösa notebook-filer. Om du gör det stoppas sessionen och det resulterar i ett fel. Om detta inträffar, ta bort biblioteket och återställ din miljö.
Konfigurera en basmiljö
En basmiljö är en YAML-fil som lagras som en arbetsytefil eller på en Unity Catalog-volym som anger ytterligare miljöberoenden. Basmiljöer kan delas mellan notebook-filer. Så här konfigurerar du en basmiljö:
Skapa en YAML-fil som definierar inställningar för en virtuell Python-miljö. I följande exempel definierar YAML, som baseras på miljöspecifikationen för MLflow-projekt, en basmiljö med några biblioteksberoenden:
client: "1" dependencies: - --index-url https://pypi.org/simple - -r "/Workspace/Shared/requirements.txt" - my-library==6.1 - "/Workspace/Shared/Path/To/simplejson-3.19.3-py3-none-any.whl" - git+https://github.com/databricks/databricks-cliLadda upp YAML-filen som en arbetsytefil eller till en Unity Catalog-volym. Se Importera en fil eller Ladda upp filer till en Unity Catalog-volym.
Till höger om anteckningsboken klickar du på
 -knappen för att expandera Miljö-sidopanelen. Den här knappen visas bara när en notebook-fil är ansluten till serverlös beräkning.
-knappen för att expandera Miljö-sidopanelen. Den här knappen visas bara när en notebook-fil är ansluten till serverlös beräkning.I fältet Base Environment anger du sökvägen till den uppladdade YAML-filen eller navigerar till den och väljer den.
Klicka på Använd. Detta installerar beroendena i den virtuella notebook-miljön och startar om Python-processen.
Användare kan åsidosätta de beroenden som anges i basmiljön genom att installera beroenden individuellt.
Konfigurera notebook-miljön
Du kan också installera beroenden på en notebook som är ansluten till serverlös beräkning med hjälp av sidopanelen för Miljö.
- Till höger om anteckningsboken klickar du på knappen för att expandera Miljö sidopanelen. Den här knappen visas bara när en notebook-fil är ansluten till serverlös beräkning.
- Välj miljöversionen i listrutan Miljöversion. Se serverlösa miljöversioner. Databricks rekommenderar att du väljer den senaste versionen för att få ut mesta möjliga up-to-date notebook-funktioner.
- I avsnittet Beroenden klickar du på Lägg till beroende och anger sökvägen till biblioteksberoendet i fältet . Du kan ange ett beroende i valfritt format som är giltigt i en requirements.txt fil.
- Klicka på Använd. Detta installerar beroendena i den virtuella notebook-miljön och startar om Python-processen.
Kommentar
Ett jobb med serverlös beräkning installerar miljöspecifikationen för notebook-filen innan du kör notebook-koden. Det innebär att du inte behöver lägga till beroenden när du schemalägger notebook-filer som jobb. Se Konfigurera miljöer och beroenden.
Visa installerade beroenden och pip-loggar
Om du vill visa installerade beroenden klickar du på Installerat i panelen Miljöer för en notebook-fil. pip-installationsloggar för notebook-miljön är också tillgängliga genom att klicka på länken pip-loggar längst ned på panelen.
Återställa miljön
Om notebook-filen är ansluten till serverlös beräkning cachelagrar Databricks automatiskt innehållet i notebook-filens virtuella miljö. Det innebär att du vanligtvis inte behöver installera om Python-beroenden som anges i Miljö sidopanelen när du öppnar en befintlig notebook, även om den har kopplats bort på grund av inaktivitet.
Cachelagring av virtuell Python-miljö gäller även för jobb. När ett jobb körs är alla uppgifter i jobbet som delar samma uppsättning beroenden som en slutförd aktivitet i den körningen snabbare, eftersom nödvändiga beroenden redan är tillgängliga.
Kommentar
Om du ändrar implementeringen av ett anpassat Python-paket som används i ett jobb i en serverlös miljö måste du också uppdatera dess versionsnummer så att jobben kan hämta den senaste implementeringen.
För att rensa cacheminnet för miljön och utföra en ny installation av de beroenden som anges i sidopanelen för miljö i en notebook-fil som är ansluten till serverlös beräkning, klicka på pilen bredvid Använd och klicka sedan på Återställ miljö.
Kommentar
Återställ den virtuella miljön om du installerar paket som bryter eller ändrar kärnanteckningsboken eller Apache Spark-miljön. Att koppla från notebook-filen från serverlös beräkning och koppla om den rensar inte nödvändigtvis hela miljöcachen. Om du återställer miljön installeras alla beroenden som anges i Miljö sidopanelen, så se till att problematiska paket tas bort innan miljön återställs.
Konfigurera miljöer och beroenden för uppgifter som inte är notebook-uppgifter
För andra aktivitetstyper som stöds, till exempel Python-skript, Python-hjul eller dbt-uppgifter, innehåller en standardmiljö installerade Python-bibliotek. Om du vill se listan över installerade bibliotek läser du avsnittet Installerade Python-bibliotek i klientversionen som du använder. Se serverlösa miljöversioner. Om en uppgift kräver ett Python-bibliotek som inte är installerat kan du installera biblioteket från arbetsytefiler, Unity Catalog volymereller offentliga paketlagringsplatser. Så här lägger du till ett bibliotek när du skapar eller redigerar en uppgift:
I listrutan Miljö och bibliotek klickar du bredvidEdit Iconstandardmiljön eller klickar på + Lägg till ny miljö.

Välj miljöversionen i listrutan Miljöversion. Se serverlösa miljöversioner. Databricks rekommenderar att du väljer den senaste versionen för att få ut mesta möjliga up-to-date-funktioner.
I dialogrutan Konfigurera miljö klickar du på + Lägg till bibliotek.
Välj typ av beroende från rullgardinsmenyn under Bibliotek.
I textrutan Filsökväg anger du sökvägen till biblioteket.
För ett Python-hjul i en arbetsytefil bör sökvägen vara absolut och börja med
/Workspace/.För ett Python-hjul i en Unity Catalog-volym ska sökvägen vara
/Volumes/<catalog>/<schema>/<volume>/<path>.whl.För en
requirements.txtfil väljer du PyPi och anger-r /path/to/requirements.txt.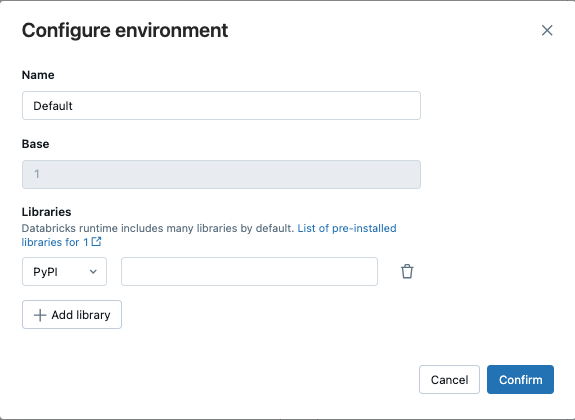
- Klicka på Bekräfta eller + Lägg till bibliotek för att lägga till ett annat bibliotek.
- Om du lägger till en aktivitet klickar du på Skapa aktivitet. Om du redigerar en uppgift klickar du på Spara uppgift.
Konfigurera standardlagringsplatser för Python-paket
Administratörer kan konfigurera privata eller autentiserade paketlagringsplatser på arbetsytor som standardkonfiguration för både serverlösa notebook-filer och serverlösa jobb. På så sätt kan användare installera paket från interna Python-lagringsplatser utan att uttryckligen definiera index-url eller extra-index-url. Men om dessa värden anges i kod eller i en notebook-fil har de företräde framför standardinställningarna för arbetsytan.
Den här konfigurationen utnyttjar Databricks-hemligheter för att lagra och hantera url:er och autentiseringsuppgifter för lagringsplatsen på ett säkert sätt. Administratörer kan ställa in konfigurationen med hjälp av arbetsytans administratörsinställningar, ett fördefinierat hemligt omfång och Databricks CLI-kommandona för hemligheter eller REST API .
Konfigurera med hjälp av sidan administratörsinställningar för arbetsytan
Arbetsyteadministratörer kan lägga till eller ta bort standardlagringsplatserna för Python-paket med hjälp av sidan administratörsinställningar för arbetsytan.
- Som arbetsyteadministratör loggar du in på Databricks-arbetsytan.
- Klicka på ditt användarnamn i det övre fältet på Databricks-arbetsytan och välj Inställningar.
- Klicka på fliken Compute.
- Bredvid standard paketlagringsplatserklickar du på Hantera.
- (Valfritt) Lägg till eller ta bort en index-URL, extra index-URL:er eller ett anpassat SSL-certifikat.
- Klicka på Spara för att spara ändringarna.
Kommentar
Ändringar eller borttagningar av hemligheter tillämpas efter att serverlös beräkning har kopplats till notebook-filer eller kört de serverlösa jobben igen.
Konfigurera med hjälp av hemligheterna CLI eller REST API
Om du vill konfigurera standardlagringsplatser för Python-paket med HJÄLP av CLI eller REST API skapar du ett fördefinierat hemligt omfång och konfigurerar åtkomstbehörigheter och lägger sedan till paketlagringsplatsens hemligheter.
Fördefinierat namn för hemligt område
Arbetsyteadministratörer kan ange standard-PIP-index-URL:er eller extra index-URL:er tillsammans med autentiseringstoken och hemligheter i ett särskilt hemligt omfång under fördefinierade nycklar:
- Hemligt räckviddsnamn:
databricks-package-management - Hemlig nyckel för index-url:
pip-index-url - Hemlig nyckel för extra index-url:ar:
pip-extra-index-urls - Hemlig nyckel för SSL-certifieringsinnehåll:
pip-cert
Skapa det hemliga omfånget
Du kan skapa ett hemligt omfång med hjälp av kommandona för Databricks CLI-hemligheter eller REST API-. När du har skapat det hemliga omfånget konfigurerar du åtkomstkontrollistor för att ge alla arbetsyteanvändare läsåtkomst. Detta säkerställer att lagringsplatsen förblir säker och inte kan ändras av enskilda användare. Hemlighetsomfånget måste använda det fördefinierade hemlighetsomfångsnamnet databricks-package-management.
databricks secrets create-scope databricks-package-management
databricks secrets put-acl databricks-package-management admins MANAGE
databricks secrets put-acl databricks-package-management users READ
Lägga till hemligheter för Python-paketlagringsplatsen
Lägg till information om Python-paketlagringsplatsen med hjälp av de fördefinierade hemliga nyckelnamnen, där alla tre fälten är valfria.
# Add index URL.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-index-url", "string_value":"<index-url-value>"}'
# Add extra index URLs. If you have multiple extra index URLs, separate them using white space.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-extra-index-urls", "string_value":"<extra-index-url-1 extra-index-url-2>"}'
# Add cert content. If you want to pip configure a custom SSL certificate, put the cert file content here.
databricks secrets put-secret --json '{"scope": "databricks-package-management", "key": "pip-cert", "string_value":"<cert-content>"}'
Ändra eller ta bort privata PyPI-lagringshemligheter
Om du vill ändra PyPI-lagringsplatshemligheter använder du kommandot put-secret. Om du vill ta bort PyPI-lagringsplatshemligheter använder du delete-secret enligt nedan:
# delete secret
databricks secrets delete-secret databricks-package-management pip-index-url
databricks secrets delete-secret databricks-package-management pip-extra-index-urls
databricks secrets delete-secret databricks-package-management pip-cert
# delete scope
databricks secrets delete-scope databricks-package-management