Vad är hantering av informationslagring i Azure Databricks?
Datalager avser insamling och lagring av data från flera källor så att de snabbt kan nås för affärsinsikter och rapportering. Den här artikeln innehåller viktiga begrepp för att skapa ett informationslager i ditt datasjöhus.
Datalagerhantering i ditt sjöhus
Lakehouse-arkitekturen och Databricks SQL ger molndatalagerfunktioner till dina datasjöar. Med hjälp av välbekanta datastrukturer, relationer och hanteringsverktyg kan du modellera ett mycket högpresterande och kostnadseffektivt informationslager som körs direkt på din datasjö. Mer information finns i Vad är ett datasjöhus?
Precis som med ett traditionellt informationslager modellerar du data enligt affärskrav och betjänar dem sedan till slutanvändarna för analys och rapporter. Till skillnad från ett traditionellt informationslager kan du undvika att siloisera dina affärsanalysdata eller skapa redundanta kopior som snabbt blir inaktuella.
Genom att skapa ett informationslager i lakehouse kan du föra in alla dina data i ett enda system och dra nytta av funktioner som Unity Catalog och Delta Lake.
Unity Catalog lägger till en enhetlig styrningsmodell så att du kan skydda och granska dataåtkomst och tillhandahålla ursprungsinformation i underordnade tabeller. Delta Lake lägger till ACID-transaktioner och schemautveckling, bland andra kraftfulla verktyg för att hålla dina data tillförlitliga, skalbara och av hög kvalitet.
Vad är Databricks SQL?
Kommentar
Databricks SQL Serverless är inte tillgängligt i Azure Kina. Databricks SQL är inte tillgängligt i Azure Government-regioner.
Databricks SQL är en samling tjänster som ger datalagerfunktioner och prestanda till dina befintliga datasjöar. Databricks SQL har stöd för öppna format och ANSI SQL som standard. Med en SQL-redigerare och instrumentpanelsverktyg på plattformen kan gruppmedlemmar samarbeta med andra Databricks-användare direkt på arbetsytan. Databricks SQL integreras också med en mängd olika verktyg så att analytiker kan skapa frågor och instrumentpaneler i sina favoritmiljöer utan att anpassa sig till en ny plattform.
Databricks SQL tillhandahåller allmänna beräkningsresurser som körs mot tabellerna i lakehouse. Databricks SQL drivs av SQL-lager, tidigare kallade SQL-slutpunkter, som erbjuder skalbara SQL-beräkningsresurser som är frikopplade från lagring.
Mer information om standardvärden och alternativ för SQL Warehouse finns i Ansluta till ett SQL-lager .
Databricks SQL integreras med Unity Catalog så att du kan identifiera, granska och styra datatillgångar från en plats. Mer information finns i Vad är Unity Catalog?
Datamodellering på Azure Databricks
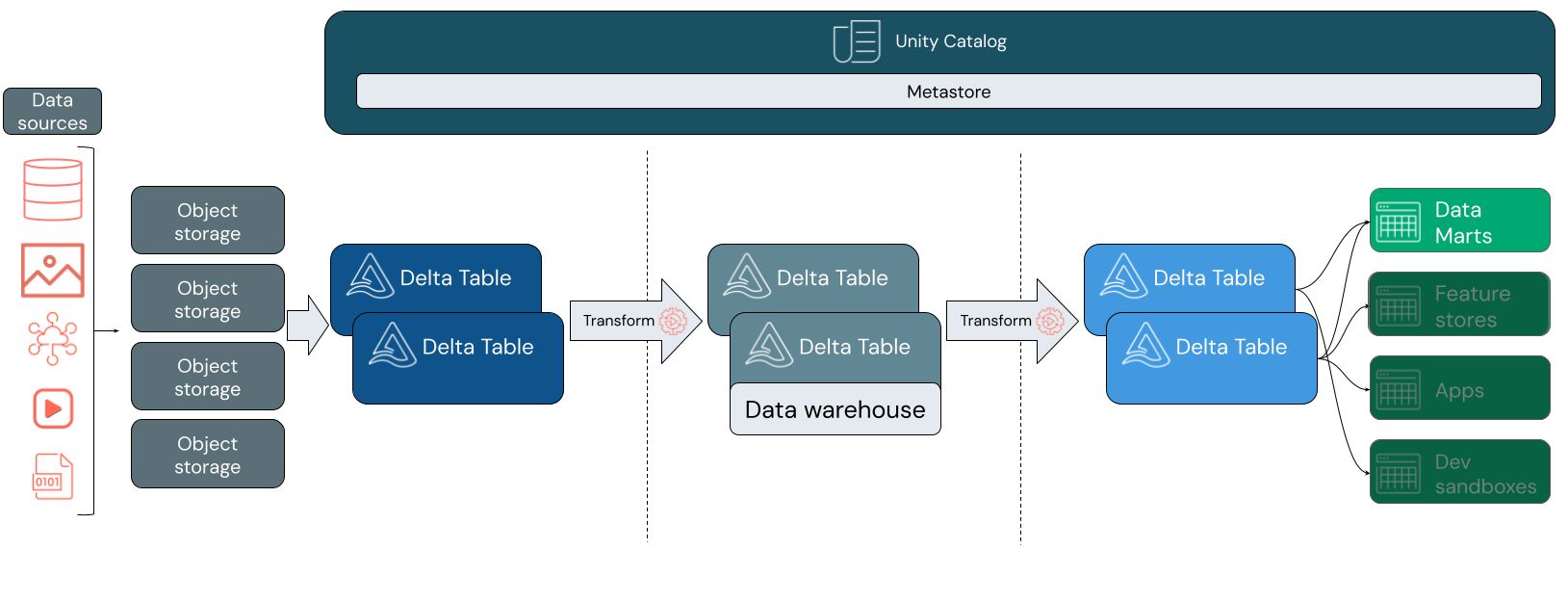
Ett sjöhus har stöd för en mängd olika modelleringsstilar. Följande bild visar hur data kureras och modelleras när de rör sig genom olika lager i ett sjöhus.
Medallion-arkitektur
Medaljongarkitekturen är ett mönster för datadesign som beskriver en serie inkrementellt förfinade datalager som ger en grundläggande struktur i sjöhuset. Lagren brons, silver och guld betyder att datakvaliteten ökar på varje nivå, med guld som representerar högsta kvalitet. Mer information finns i Vad är arkitekturen i medallion lakehouse?.
I ett sjöhus kan varje lager innehålla en eller flera tabeller. Informationslagret modelleras på silverskiktet och matar specialiserade data marts i guldskiktet.
Bronsskikt
Data kan ange lakehouse i valfritt format och genom valfri kombination av batchtransaktioner eller ångande transaktioner. Bronsskiktet ger landningsutrymmet för alla dina rådata i sitt ursprungliga format. Dessa data konverteras till Delta-tabeller.
Silverskikt
Silverlagret för samman data från olika källor. För den del av verksamheten som fokuserar på datavetenskap och maskininlärningsprogram är det här du börjar kurera meningsfulla datatillgångar. Den här processen präglas ofta av fokus på hastighet och flexibilitet.
Silverlagret är också där du noggrant kan integrera data från olika källor för att skapa ett informationslager i enlighet med dina befintliga affärsprocesser. Dessa data följer ofta en 3NF-modell (Third Normal Form) eller Data Vault. Genom att ange primära och sekundärnyckelbegränsningar kan slutanvändarna förstå tabellrelationer när de använder Unity Catalog. Ditt informationslager bör fungera som en enda sanningskälla för dina data marts.
Själva informationslagret är schema-on-write och atomisk. Det är optimerat för förändring, så du kan snabbt ändra informationslagret så att det matchar dina aktuella behov när dina affärsprocesser ändras eller utvecklas.
Guldskikt
Det guldfärgade lagret är presentationslagret, som kan innehålla en eller flera data marts. Ofta är data marts dimensionsmodeller i form av en uppsättning relaterade tabeller som samlar in ett specifikt affärsperspektiv.
Guldskiktet innehåller också avdelnings- och datavetenskapssandlådor för att möjliggöra självbetjäningsanalys och datavetenskap i hela företaget. Om du tillhandahåller dessa sandbox-miljöer och egna separata beräkningskluster hindrar affärsteamen från att skapa kopior av data utanför lakehouse.
Gå vidare
Mer information om principer och metodtips för att implementera och driva ett sjöhus med Databricks finns i Introduktion till det välarkitekterade datasjöhuset.