Skala Azure HDInsight-kluster automatiskt
Azure HDInsights kostnadsfria autoskalningsfunktion kan automatiskt öka eller minska antalet arbetsnoder i klustret baserat på de klustermått och skalningsprinciper som kunderna har antagit. Funktionen Autoskalning fungerar genom att skala antalet noder inom förinställda gränser baserat på antingen prestandamått eller ett definierat schema för skalnings- och nedskalningsåtgärder.
Hur det fungerar
Funktionen Autoskalning använder två typer av villkor för att utlösa skalningshändelser: tröskelvärden för olika klusterprestandamått (kallas belastningsbaserad skalning) och tidsbaserade utlösare (kallas schemabaserad skalning). Belastningsbaserad skalning ändrar antalet noder i klustret, inom ett intervall som du anger, för att säkerställa optimal CPU-användning och minimera driftskostnaderna. Schemabaserad skalning ändrar antalet noder i klustret baserat på ett schema med uppskalnings- och nedskalningsåtgärder.
Följande video ger en översikt över de utmaningar som autoskalning löser och hur det kan hjälpa dig att kontrollera kostnaderna med HDInsight.
Välja belastningsbaserad eller schemabaserad skalning
Schemabaserad skalning kan användas:
- När dina jobb förväntas köras enligt fasta scheman och under en förutsägbar varaktighet eller När du förväntar dig låg användning under specifika tider på dagen. Till exempel test- och utvecklingsmiljöer i jobb efter arbetstid och slut på dagen.
Belastningsbaserad skalning kan användas:
- När belastningsmönstren varierar avsevärt och oförutsägbart under dagen. Du kan till exempel beställa databearbetning med slumpmässiga variationer i belastningsmönster baserat på olika faktorer.
Klustermått
Autoskalning övervakar kontinuerligt klustret och samlar in följande mått:
| Mätvärde | Beskrivning |
|---|---|
| Total väntande PROCESSOR | Det totala antalet kärnor som krävs för att starta körningen av alla väntande containrar. |
| Totalt väntande minne | Det totala minne (i MB) som krävs för att starta körningen av alla väntande containrar. |
| Total kostnadsfri PROCESSOR | Summan av alla oanvända kärnor på de aktiva arbetsnoderna. |
| Totalt ledigt minne | Summan av oanvänt minne (i MB) på de aktiva arbetsnoderna. |
| Använt minne per nod | Belastningen på en arbetsnod. En arbetsnod där 10 GB minne används anses vara under mer belastning än en arbetare med 2 GB använt minne. |
| Antal programhanterare per nod | Antalet AM-containrar (Application Master) som körs på en arbetsnod. En arbetsnod som är värd för två AM-containrar anses vara viktigare än en arbetsnod som är värd för noll AM-containrar. |
Ovanstående mått kontrolleras var 60:e sekund. Autoskalning fattar beslut om uppskalning och nedskalning baserat på dessa mått.
En fullständig lista över klustermått finns i Mått som stöds för Microsoft.HDInsight/clusters.
Belastningsbaserade skalningsvillkor
När följande villkor identifieras utfärdar autoskalning en skalningsbegäran:
| Skala upp | Skala ned |
|---|---|
| Den totala väntande processorn är större än den totala kostnadsfria processorn i mer än 3–5 minuter. | Den totala väntande processorn är mindre än den totala kostnadsfria processorn i mer än 3–5 minuter. |
| Totalt väntande minne är större än det totala lediga minnet i mer än 3–5 minuter. | Totalt väntande minne är mindre än totalt ledigt minne i mer än 3–5 minuter. |
Vid uppskalning utfärdar autoskalning en uppskalningsbegäran för att lägga till det antal noder som krävs. Uppskalningen baseras på hur många nya arbetsnoder som behövs för att uppfylla de aktuella processor- och minneskraven.
Vid nedskalning utfärdar autoskalning en begäran om att ta bort vissa noder. Nedskalningen baseras på antalet AM-containrar (Application Master) per nod. Och de aktuella processor- och minneskraven. Tjänsten identifierar också vilka noder som är kandidater för borttagning baserat på aktuell jobbkörning. Skalningsåtgärden inaktiverar först noderna och tar sedan bort dem från klustret.
Ambari DB-storleksöverväganden för automatisk skalning
Vi rekommenderar att Ambari DB har rätt storlek för att dra nytta av fördelarna med autoskalning. Kunder bör använda rätt DB-nivå och använda den anpassade Ambari DB för stora kluster. Läs storleksrekommendationerna för databas och huvudnod.
Klusterkompatibilitet
Viktigt!
Autoskalningsfunktionen i Azure HDInsight släpptes för allmän tillgänglighet den 7 november 2019 för Spark- och Hadoop-kluster och innehöll förbättringar som inte var tillgängliga i förhandsversionen av funktionen. Om du skapade ett Spark-kluster före den 7 november 2019 och vill använda funktionen Autoskalning i klustret är den rekommenderade sökvägen att skapa ett nytt kluster och enable Autoscale på det nya klustret.
Autoskalning för interaktiv fråga (LLAP) släpptes för allmän tillgänglighet för HDI 4.0 den 27 augusti 2020. Autoskalning är endast tillgängligt i Spark-, Hadoop- och Interactive Query-kluster
I följande tabell beskrivs de klustertyper och versioner som är kompatibla med funktionen Autoskalning.
| Version | Spark | Hive | Interaktiv fråga | HBase | Kafka |
|---|---|---|---|---|---|
| HDInsight 4.0 utan ESP | Ja | Ja | Ja* | Nej | Nej |
| HDInsight 4.0 med ESP | Ja | Ja | Ja* | Nej | Nej |
| HDInsight 5.0 utan ESP | Ja | Ja | Ja* | Nej | Nej |
| HDInsight 5.0 med ESP | Ja | Ja | Ja* | Nej | Nej |
* Interaktiva frågekluster kan bara konfigureras för schemabaserad skalning, inte belastningsbaserad.
Kom igång
Skapa ett kluster med belastningsbaserad autoskalning
Om du vill aktivera funktionen Autoskalning med belastningsbaserad skalning utför du följande steg som en del av den normala processen för att skapa kluster:
På fliken Konfiguration + prissättning markerar du kryssrutan
Enable autoscale.Välj Belastningsbaserad under Autoskalningstyp.
Ange de avsedda värdena för följande egenskaper:
- Initialt antal noder för arbetsnoden.
- Minsta antal arbetsnoder.
- Maximalt antal arbetsnoder.
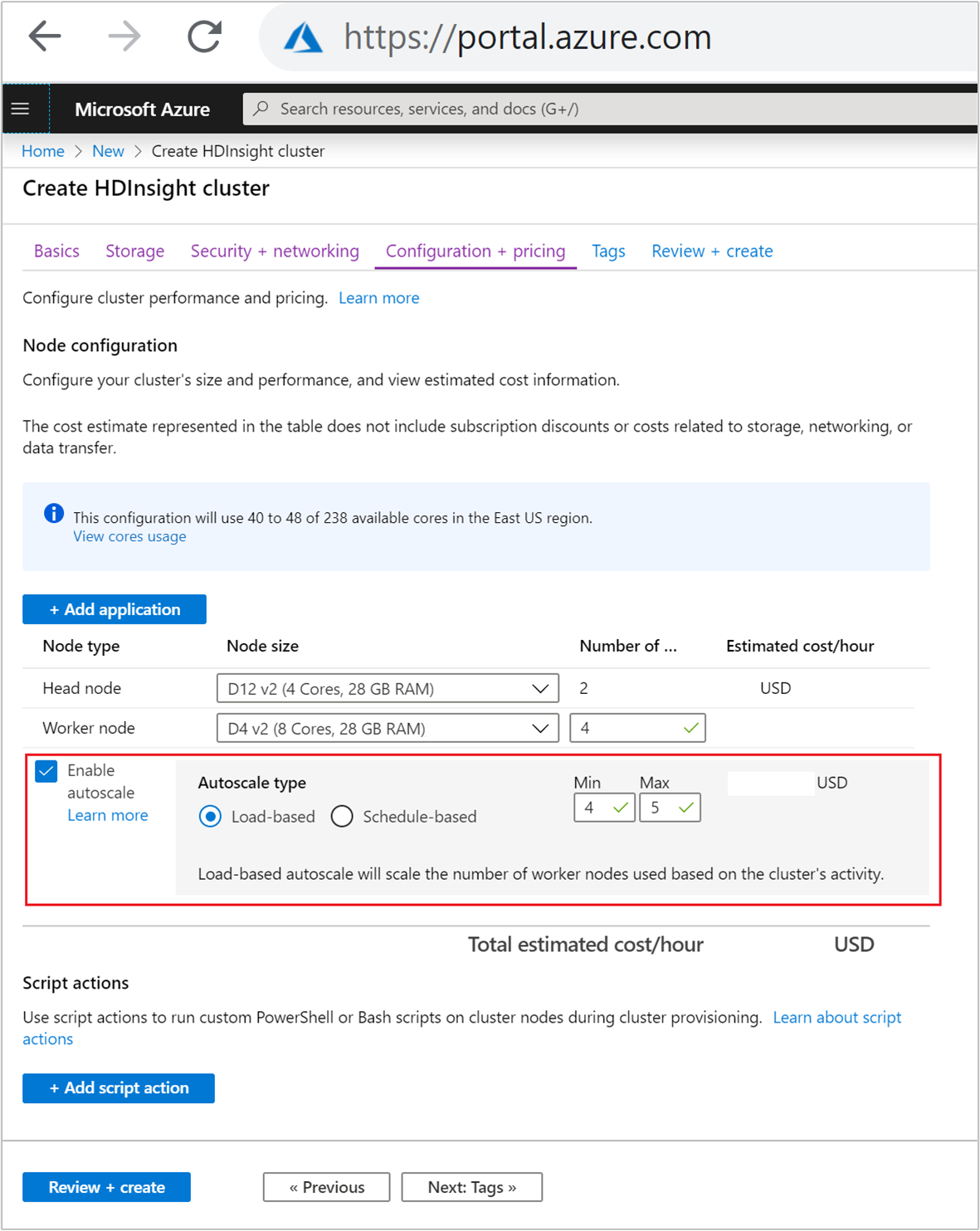
Det inledande antalet arbetsnoder måste ligga mellan det lägsta och högsta, inkluderande. Det här värdet definierar den ursprungliga storleken på klustret när det skapas. Det minsta antalet arbetsnoder ska anges till tre eller fler. Om klustret skalas till färre än tre noder kan det leda till att det fastnar i felsäkert läge på grund av otillräcklig filreplikering. Mer information finns i Fastna i felsäkert läge.
Skapa ett kluster med schemabaserad autoskalning
Om du vill aktivera funktionen Autoskalning med schemabaserad skalning utför du följande steg som en del av den normala processen för att skapa kluster:
Markera kryssrutan på
Enable autoscalefliken Konfiguration + prissättning.Ange Antalet noder för arbetsnoden, som styr gränsen för att skala upp klustret.
Välj alternativet Schemabaserat under Autoskalningstyp.
Välj Konfigurera för att öppna fönstret Autoskalningskonfiguration .
Välj tidszonen och klicka sedan på + Lägg till villkor
Välj de veckodagar som det nya villkoret ska gälla för.
Redigera den tid villkoret ska börja gälla och antalet noder som klustret ska skalas till.
Lägg till fler villkor om det behövs.
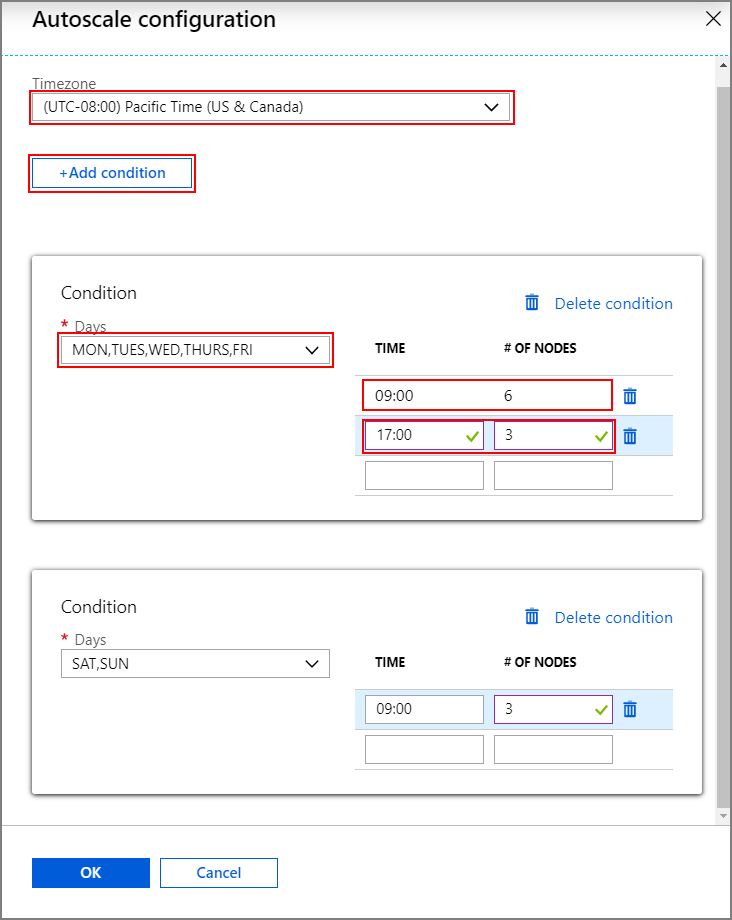
Antalet noder måste vara mellan 3 och det maximala antalet arbetsnoder som du angav innan du lägger till villkor.
Sista stegen för att skapa
Välj VM-typ för arbetsnoder genom att välja en virtuell dator i listrutan under Nodstorlek. När du har valt VM-typ för varje nodtyp kan du se det uppskattade kostnadsintervallet för hela klustret. Justera vm-typerna så att de passar din budget.
Din prenumeration har en kapacitetskvot för varje region. Det totala antalet kärnor i huvudnoderna och maximalt antal arbetsnoder får inte överskrida kapacitetskvoten. Den här kvoten är dock en mjuk gräns. Du kan alltid skapa ett supportärende så att det blir enklare att öka.
Kommentar
Om du överskrider den totala kärnkvotgränsen får du ett felmeddelande om att "den maximala noden överskred de tillgängliga kärnorna i den här regionen, välj en annan region eller kontakta supporten för att öka kvoten".
Mer information om hur du skapar HDInsight-kluster med hjälp av Azure-portalen finns i Skapa Linux-baserade kluster i HDInsight med hjälp av Azure-portalen.
Skapa ett kluster med en Resource Manager-mall
Belastningsbaserad autoskalning
Du kan skapa ett HDInsight-kluster med belastningsbaserad autoskalning av en Azure Resource Manager-mall genom att lägga till>workernode computeProfileen autoscale nod i avsnittet med egenskaperna minInstanceCount och maxInstanceCount enligt json-kodfragmentet. En fullständig Resource Manager-mall finns i Snabbstartsmall : Distribuera Spark-kluster med belastningsbaserad autoskalning aktiverad.
{
"name": "workernode",
"targetInstanceCount": 4,
"autoscale": {
"capacity": {
"minInstanceCount": 3,
"maxInstanceCount": 10
}
},
"hardwareProfile": {
"vmSize": "Standard_D13_V2"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
},
"virtualNetworkProfile": null,
"scriptActions": []
}
Schemabaserad autoskalning
Du kan skapa ett HDInsight-kluster med schemabaserad autoskalning av en Azure Resource Manager-mall genom att lägga till en autoscale nod i computeProfile>workernode avsnittet. Noden autoscale innehåller en som har en recurrence timezone och schedule som beskriver när ändringen sker. En fullständig Resource Manager-mall finns i Distribuera Spark-kluster med schemabaserad autoskalning aktiverad.
{
"autoscale": {
"recurrence": {
"timeZone": "Pacific Standard Time",
"schedule": [
{
"days": [
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday"
],
"timeAndCapacity": {
"time": "11:00",
"minInstanceCount": 10,
"maxInstanceCount": 10
}
}
]
}
},
"name": "workernode",
"targetInstanceCount": 4
}
Aktivera och inaktivera autoskalning för ett kluster som körs
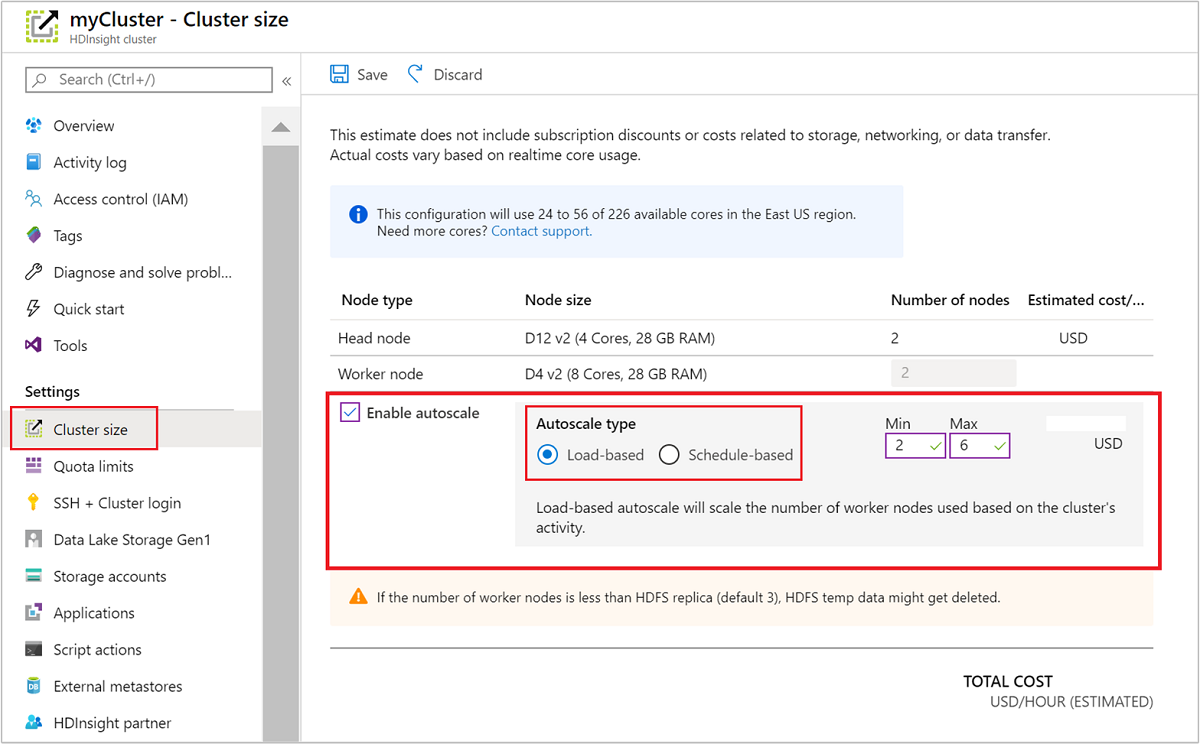
Med hjälp av Azure-portalen
Om du vill aktivera autoskalning i ett kluster som körs väljer du Klusterstorlek under Inställningar. Välj Enable autoscalesedan . Välj den typ av autoskalning som du vill använda och ange alternativen för belastningsbaserad eller schemabaserad skalning. Välj slutligen Spara.
Använda REST API
Om du vill aktivera eller inaktivera autoskalning i ett kluster som körs med hjälp av REST-API:et gör du en POST-begäran till autoskalningsslutpunkten:
https://management.azure.com/subscriptions/{subscription Id}/resourceGroups/{resourceGroup Name}/providers/Microsoft.HDInsight/clusters/{CLUSTERNAME}/roles/workernode/autoscale?api-version=2018-06-01-preview
Använd lämpliga parametrar i nyttolasten för begäran. Följande json-nyttolast kan användas för enable Autoscale. Använd nyttolasten {autoscale: null} för att inaktivera autoskalning.
{ "autoscale": { "capacity": { "minInstanceCount": 3, "maxInstanceCount": 5 } } }
Se föregående avsnitt om hur du aktiverar belastningsbaserad autoskalning för en fullständig beskrivning av alla nyttolastparametrar. Vi rekommenderar inte att du inaktiverar autoskalningstjänsten kraftfullt i ett kluster som körs.
Övervaka autoskalningsaktiviteter
Klusterstatus
Klusterstatusen i Azure-portalen kan hjälpa dig att övervaka aktiviteter för autoskalning.
Alla klusterstatusmeddelanden som du kan se förklaras i följande lista.
| Klusterstatus | beskrivning |
|---|---|
| Körs | Klustret fungerar normalt. Alla tidigare autoskalningsaktiviteter har slutförts. |
| Uppdatera | Autoskalningskonfigurationen för klustret uppdateras. |
| HDInsight-konfiguration | En klusterskalnings- eller nedskalningsåtgärd pågår. |
| Uppdateringsfel | HDInsight stötte på problem under konfigurationsuppdateringen för autoskalning. Kunder kan välja att antingen försöka uppdatera igen eller inaktivera autoskalning. |
| Fel | Något är fel med klustret och det går inte att använda. Ta bort det här klustret och skapa ett nytt. |
Om du vill visa det aktuella antalet noder i klustret går du till diagrammet Klusterstorlek på sidan Översikt för klustret. Eller välj Klusterstorlek under Inställningar.
Åtgärdshistorik
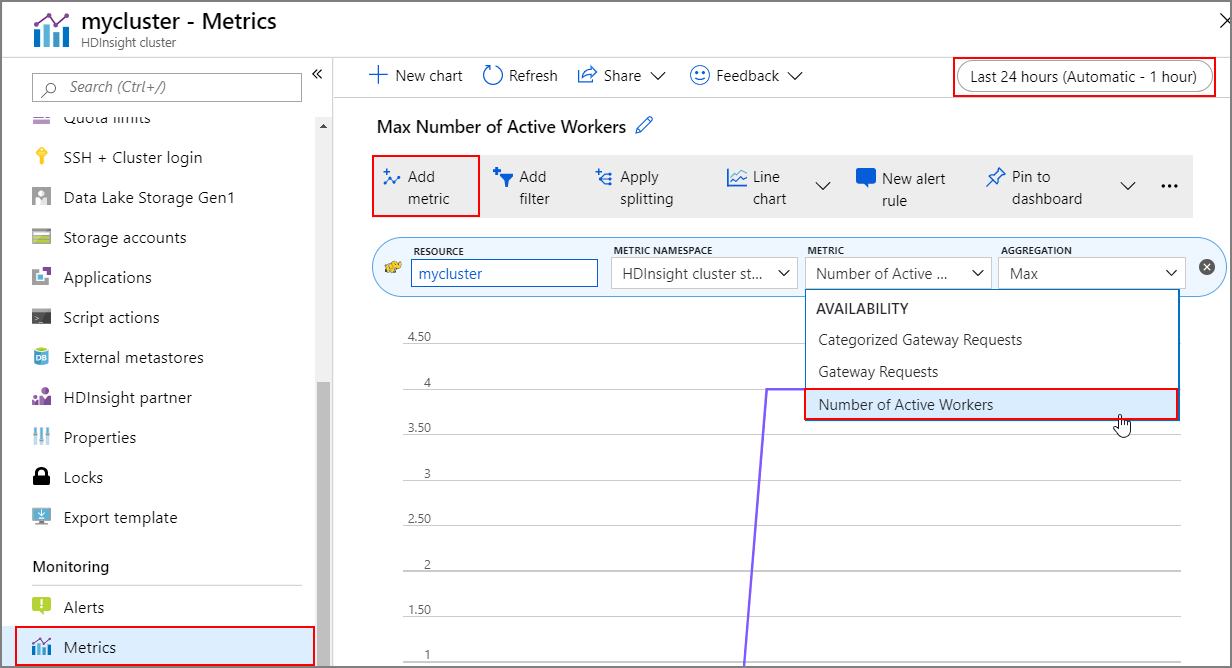
Du kan visa historiken för klusterskalning och nedskalning som en del av klustermåtten. Du kan också visa en lista över alla skalningsåtgärder under den senaste dagen, veckan eller andra tidsperioder.
Välj Mått under Övervakning. Välj sedan Lägg till mått och Antal aktiva arbetare i listrutan Mått . Välj knappen i det övre högra hörnet för att ändra tidsintervallet.
Bästa praxis
Överväg svarstiden för att skala upp och skala ned åtgärder
Det kan ta 10 till 20 minuter innan den övergripande skalningsåtgärden slutförs. När du konfigurerar ett anpassat schema planerar du för den här fördröjningen. Om du till exempel behöver klusterstorleken 20 kl. 09:00 ställer du in schemautlösaren på en tidigare tid, till exempel 08:30 eller tidigare, så att skalningsåtgärden har slutförts kl. 09:00.
Förbereda för nedskalning
Under nedskalningsprocessen för klustret inaktiverar Autoskalning noderna för att uppfylla målstorleken. Vid inläsningsbaserad autoskalning väntar autoskalning tills aktiviteterna har slutförts för Spark- och Hadoop-kluster om aktiviteter körs på dessa noder. Eftersom varje arbetsnod också har en roll i HDFS flyttas de tillfälliga data till de återstående arbetsnoderna. Kontrollera att det finns tillräckligt med utrymme på de återstående noderna för att vara värd för alla temporära data.
Kommentar
När det gäller schemabaserad autoskalningsskalning stöds inte graciös avaktivering. Detta kan orsaka jobbfel under en nedskalningsåtgärd och vi rekommenderar att du planerar scheman baserat på de förväntade jobbschemamönstren för att inkludera tillräckligt med tid för att de pågående jobben ska slutföras. Du kan ange de scheman som tittar på historisk spridning av slutförandetider för att undvika jobbfel.
Konfigurera schemabaserad autoskalning baserat på användningsmönster
Du måste förstå ditt klusteranvändningsmönster när du konfigurerar schemabaserad autoskalning. Grafana-instrumentpanelen kan hjälpa dig att förstå dina frågeinläsnings- och körningsfack. Du kan hämta tillgängliga körfack och totala körfack från instrumentpanelen.
Här är ett sätt att uppskatta hur många arbetsnoder som behövs. Vi rekommenderar att du ger ytterligare 10 % buffert för att hantera varianten av arbetsbelastningen.
Antal körfack som används = Totalt antal körfack – Totalt antal tillgängliga körfack.
Antal arbetsnoder som krävs = Antal körfack som faktiskt används / (hive.llap.daemon.num.executors + hive.llap.daemon.task.scheduler.wait.queue.size).
*hive.llap.daemon.num.executors kan konfigureras och standardvärdet är 4.
*hive.llap.daemon.task.scheduler.wait.queue.size är konfigurerbar och standardvärdet är 10.
Åtgärder med anpassade skript
Anpassade skriptåtgärder används främst för att anpassa noderna (HeadNode/WorkerNodes) som gör det möjligt för våra kunder att konfigurera vissa bibliotek och verktyg som används av dem. Ett vanligt användningsfall är de jobb som körs i klustret kan ha vissa beroenden i biblioteket från tredje part, som ägs av kunden, och det bör vara tillgängligt på noder för att jobbet ska lyckas. För autoskalning har vi för närvarande stöd för anpassade skriptåtgärder, som sparas, och varje gång de nya noderna läggs till i klustret som en del av uppskalningsåtgärden körs de här beständiga skriptåtgärderna och efter att containrarna eller jobben allokeras på dem. Även om anpassade skriptåtgärder hjälper till att starta de nya noderna rekommenderar vi att du håller det minimalt eftersom det skulle ge den övergripande svarstiden för uppskalning och kan orsaka påverkan på de schemalagda jobben.
Tänk på den minsta klusterstorleken
Skala inte ned klustret till färre än tre noder. Om klustret skalas till färre än tre noder kan det leda till att det fastnar i felsäkert läge på grund av otillräcklig filreplikering. Mer information finns i Fastna i felsäkert läge.
Microsoft Entra Domain Services och skalningsåtgärder
Om du använder ett HDInsight-kluster med Enterprise Security Package (ESP) som är anslutet till en hanterad Domän för Microsoft Entra Domain Services rekommenderar vi att du begränsar belastningen på Microsoft Entra Domain Services. I komplexa katalogstrukturer som är begränsade till synkronisering rekommenderar vi att du undviker påverkan på skalningsåtgärder.
Ange Maximalt antal samtidiga frågor i Hive-konfigurationen för scenariot med hög användning
Autoskalningshändelser ändrar inte Hive-konfigurationen Maximalt antal samtidiga frågor i Ambari. Det innebär att Hive Server 2 Interactive Service endast kan hantera det angivna antalet samtidiga frågor när som helst, även om antalet interaktiva frågedaemoner skalas upp och ned baserat på belastning och schema. Den allmänna rekommendationen är att ange den här konfigurationen för scenariot med hög användning för att undvika manuella åtgärder.
Du kan dock uppleva ett omstartsfel för Hive Server 2 om det bara finns några få arbetsnoder och värdet för maximalt antal samtidiga frågor har konfigurerats för högt. Du behöver minst det minsta antal arbetsnoder som kan hantera det angivna antalet Tez Ams (lika med konfigurationen Maximalt totalt antal samtidiga frågor).
Begränsningar
Antal interaktiva frågedaemoner
Om autoskalningsaktiverade interaktiva frågekluster skalas upp/ned automatiskt även antalet interaktiva frågedaemoner till antalet aktiva arbetsnoder. Ändringen av antalet daemoner sparas inte i konfigurationen num_llap_nodes i Ambari. Om Hive-tjänster startas om manuellt återställs antalet interaktiva frågedaemoner enligt konfigurationen i Ambari.
Om tjänsten Interaktiv fråga startas om manuellt måste du manuellt ändra konfigurationen num_llap_node (antalet noder som behövs för att köra Hive Interactive Query-daemon) under Advanced hive-interactive-env för att matcha det aktuella antalet aktiva arbetsnoder. Interaktivt frågekluster stöder endast schemabaserad autoskalning.
Nästa steg
Läs mer om riktlinjer för att skala kluster manuellt i riktlinjerna för skalning.