Skala Azure HDInsight-kluster manuellt
HDInsight ger elasticitet med alternativ för att skala upp och skala ned antalet arbetsnoder i dina kluster. Med den här elasticiteten kan du krympa ett kluster efter timmar eller på helger. Och expandera den under höga affärsbehov.
Skala upp klustret före periodisk batchbearbetning så att klustret har tillräckliga resurser. När bearbetningen har slutförts och användningen går ned skalar du ned HDInsight-klustret till färre arbetsnoder.
Du kan skala ett kluster manuellt med någon av följande metoder. Du kan också använda autoskalningsalternativ för att automatiskt skala upp och ned som svar på vissa mått.
Kommentar
Endast kluster med HDInsight version 3.1.3 eller senare stöds. Om du är osäker på vilken version av klustret du har kan du kontrollera sidan Egenskaper.
Verktyg för att skala kluster
Microsoft tillhandahåller följande verktyg för att skala kluster:
| Verktyg | beskrivning |
|---|---|
| PowerShell Az | Set-AzHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| PowerShell AzureRM | Set-AzureRmHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| Azure CLI | az hdinsight resize --resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE |
| Klassiska Azure CLI | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Azure-portalen | Öppna fönstret HDInsight-kluster, välj Klusterstorlek på den vänstra menyn. I fönstret Klusterstorlek skriver du in antalet arbetsnoder och väljer Spara. |
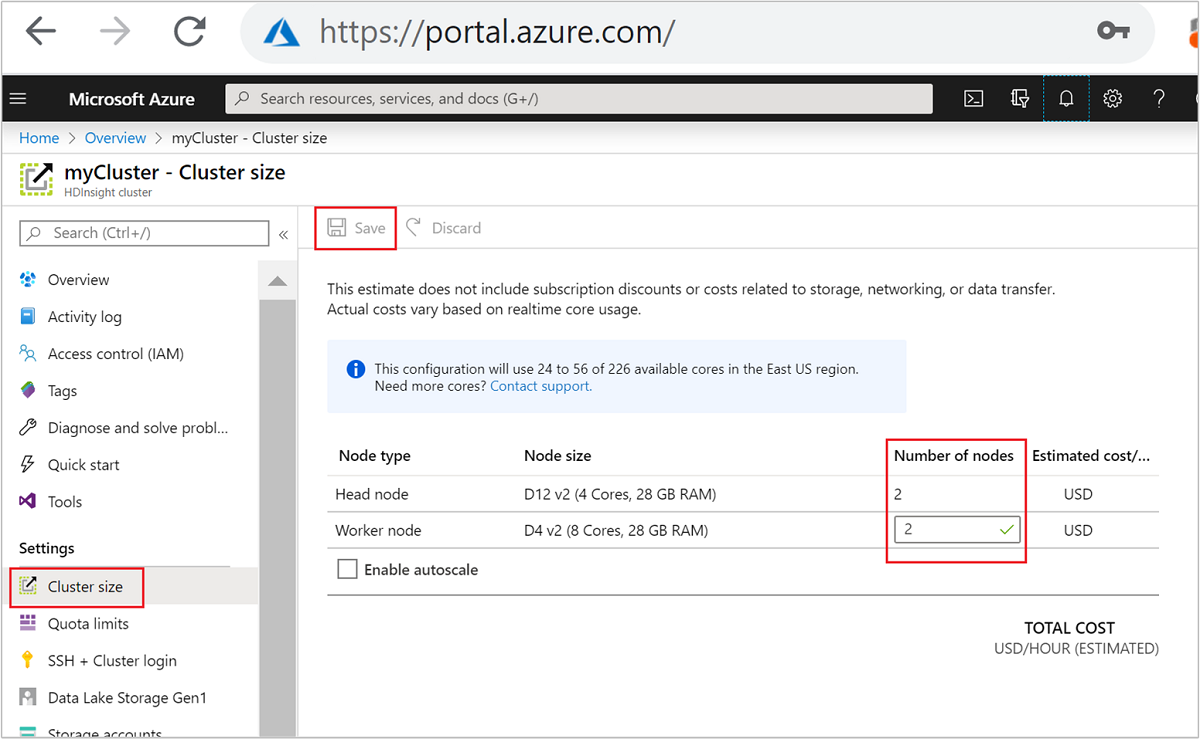
Med någon av dessa metoder kan du skala upp eller ned HDInsight-klustret inom några minuter.
Viktigt!
- Det klassiska Azure CLI är inaktuellt och bör endast användas med den klassiska distributionsmodellen. Använd Azure CLI för alla andra distributioner.
- PowerShell AzureRM-modulen är inaktuell. Använd Az-modulen när det är möjligt.
Påverkan av skalningsåtgärder
När du lägger till noder i det HDInsight-kluster som körs (skalas upp) påverkas inte jobben. Nya jobb kan skickas på ett säkert sätt medan skalningsprocessen körs. Om skalningsåtgärden misslyckas lämnar felet klustret i ett funktionellt tillstånd.
Om du tar bort noder (skala ned) misslyckas väntande eller pågående jobb när skalningsåtgärden är klar. Det här felet beror på att vissa av tjänsterna startas om under skalningsprocessen. Klustret kan fastna i felsäkert läge under en manuell skalningsåtgärd.
Effekten av att ändra antalet datanoder varierar för varje typ av kluster som stöds av HDInsight:
Apache Hadoop
Du kan sömlöst öka antalet arbetsnoder i ett Hadoop-kluster som körs utan att påverka några jobb. Nya jobb kan också skickas medan åtgärden pågår. Fel i en skalningsåtgärd hanteras korrekt. Klustret är alltid i ett funktionellt tillstånd.
När ett Hadoop-kluster skalas ned med färre datanoder startas vissa tjänster om. Det här beteendet gör att alla jobb som körs och väntar misslyckas när skalningsåtgärden har slutförts. Du kan dock skicka jobben igen när åtgärden är klar.
Apache HBase
Du kan sömlöst lägga till eller ta bort noder i ditt HBase-kluster när det körs. Regionala servrar balanseras automatiskt inom några minuter efter att skalningsåtgärden har slutförts. Du kan dock balansera de regionala servrarna manuellt. Logga in på klusterhuvudnoden och kör följande kommandon:
pushd %HBASE_HOME%\bin hbase shell balancerMer information om hur du använder HBase-gränssnittet finns i Komma igång med ett Apache HBase-exempel i HDInsight.
Kommentar
Inte tillämpligt för Kafka-kluster.
Apache Hive LLAP
Efter skalning till
Narbetsnoder ställer HDInsight automatiskt in följande konfigurationer och startar om Hive.- Maximalt antal samtidiga frågor:
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Antal noder som används av Hive:s LLAP:
num_llap_nodes = N - Antal noder för att köra Hive LLAP-daemon:
num_llap_nodes_for_llap_daemons = N
- Maximalt antal samtidiga frågor:
Så här skalar du ned ett kluster på ett säkert sätt
Skala ned ett kluster med jobb som körs
För att undvika att dina jobb som körs misslyckas under en nedskalningsåtgärd kan du prova tre saker:
- Vänta tills jobben har slutförts innan du skalar ned klustret.
- Avsluta jobben manuellt.
- Skicka jobben igen när skalningsåtgärden har slutförts.
Om du vill se en lista över väntande och pågående jobb kan du använda YARN Resource Manager-användargränssnittet genom att följa dessa steg:
Välj ditt kluster från Azure Portal. Klustret öppnas i en ny portalsida.
Från huvudvyn går du till Ambari-startsidan för klusterinstrumentpaneler>. Ange dina autentiseringsuppgifter för klustret.
I Ambari-användargränssnittet väljer du YARN i listan över tjänster på den vänstra menyn.
På sidan YARN väljer du Snabblänkar och hovra över den aktiva huvudnoden och sedan Resource Manager-användargränssnittet.
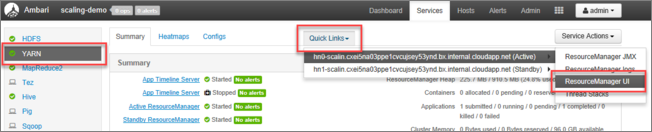
Du kan komma åt Resource Manager-användargränssnittet direkt med https://<HDInsightClusterName>.azurehdinsight.net/yarnui/hn/cluster.
Du ser en lista över jobb, tillsammans med deras aktuella tillstånd. På skärmbilden körs ett jobb:
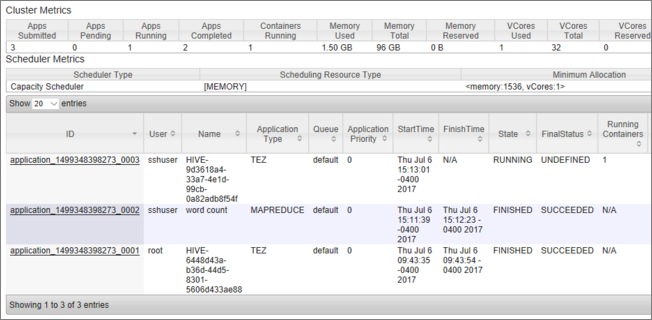
Om du vill avsluta det program som körs manuellt kör du följande kommando från SSH-gränssnittet:
yarn application -kill <application_id>
Till exempel:
yarn application -kill "application_1499348398273_0003"
Fastna i felsäkert läge
När du skalar ned ett kluster använder HDInsight Apache Ambari-hanteringsgränssnitt för att först inaktivera de extra arbetsnoderna. Noderna replikerar sina HDFS-block till andra online worker-noder. Därefter skalar HDInsight ned klustret på ett säkert sätt. HDFS försätts i felsäkert läge under skalningsåtgärden. HDFS ska komma ut när skalningen är klar. I vissa fall fastnar DOCK HDFS i felsäkert läge under en skalningsåtgärd på grund av filblock under replikering.
Som standard konfigureras HDFS med inställningen dfs.replication 1, som styr hur många kopior av varje filblock som är tillgängliga. Varje kopia av ett filblock lagras på en annan nod i klustret.
När det förväntade antalet blockkopior inte är tillgängligt går HDFS in i felsäkert läge och Ambari genererar aviseringar. HDFS kan gå in i felsäkert läge för en skalningsåtgärd. Klustret kan fastna i felsäkert läge om det nödvändiga antalet noder inte identifieras för replikering.
Exempelfel när felsäkert läge är aktiverat
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.cloudapp.net:10001 [active-headnode-name.servername. internal.cloudapp.net/1.1.1.1] failed: Connection refused
Du kan granska namnnodloggarna från /var/log/hadoop/hdfs/ mappen, nära den tidpunkt då klustret skalades, för att se när det gick in i felsäkert läge. Loggfilerna heter Hadoop-hdfs-namenode-<active-headnode-name>.*.
Rotorsaken var att Hive är beroende av tillfälliga filer i HDFS när frågor körs. När HDFS går in i felsäkert läge kan Hive inte köra frågor eftersom det inte kan skriva till HDFS. Temporära filer i HDFS finns på den lokala enheten som är monterad på de enskilda virtuella datorerna för arbetsnoden. Filerna replikeras bland andra arbetsnoder med tre repliker, minst.
Så här förhindrar du att HDInsight fastnar i felsäkert läge
Det finns flera sätt att förhindra att HDInsight lämnas i felsäkert läge:
- Stoppa alla Hive-jobb innan du skalar ned HDInsight. Alternativt kan du schemalägga nedskalningsprocessen för att undvika konflikter med att köra Hive-jobb.
- Rensa Hive:s scratch-katalogfiler
tmpi HDFS manuellt innan du skalar ned. - Skala bara ned HDInsight till tre arbetsnoder, minst. Undvik att gå så lågt som en arbetsnod.
- Kör kommandot för att lämna felsäkert läge om det behövs.
I följande avsnitt beskrivs de här alternativen.
Stoppa alla Hive-jobb
Stoppa alla Hive-jobb innan du skalar ned till en arbetsnod. Om din arbetsbelastning är schemalagd kör du nedskalning efter att Hive-arbetet har utförts.
Stoppa Hive-jobben innan du skalar, hjälper till att minimera antalet scratch-filer i tmp-mappen (om det finns några).
Rensa Hive:s scratch-filer manuellt
Om Hive har lämnat kvar temporära filer kan du manuellt rensa filerna innan du skalar ned för att undvika felsäkert läge.
Kontrollera vilken plats som används för temporära Hive-filer genom att titta på konfigurationsegenskapen
hive.exec.scratchdir. Den här parametern anges i/etc/hive/conf/hive-site.xml:<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>Stoppa Hive-tjänster och se till att alla frågor och jobb har slutförts.
Visa en lista över innehållet i den scratch-katalog som finns ovan för
hdfs://mycluster/tmp/hive/att se om den innehåller några filer:hadoop fs -ls -R hdfs://mycluster/tmp/hive/hiveHär är ett exempel på utdata när det finns filer:
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.infoOm du vet att Hive är klar med dessa filer kan du ta bort dem. Se till att Hive inte har några frågor som körs genom att titta på sidan Yarn Resource Manager-användargränssnitt.
Exempel på kommandorad för att ta bort filer från HDFS:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
Skala HDInsight till tre eller fler arbetsnoder
Om dina kluster fastnar i felsäkert läge ofta när du skalar ned till färre än tre arbetsnoder behåller du minst tre arbetsnoder.
Det är dyrare att ha tre arbetsnoder än att bara skala ned till en arbetsnod. Den här åtgärden förhindrar dock att klustret fastnar i felsäkert läge.
Skala ned HDInsight till en arbetsnod
Även när klustret skalas ned till en nod överlever arbetarnod 0 fortfarande. Arbetsnod 0 kan aldrig inaktiveras.
Kör kommandot för att lämna felsäkert läge
Det sista alternativet är att köra kommandot lämna felsäkert läge. Om HDFS har angett felsäkert läge på grund av Hive-filens underreplikering kör du följande kommando för att lämna felsäkert läge:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
Skala ned ett Apache HBase-kluster
Regionservrar balanseras automatiskt inom några minuter efter att en skalningsåtgärd har slutförts. Utför följande steg för att manuellt balansera regionservrar:
Anslut till HDInsight-klustret med hjälp av SSH. Mer information finns i Use SSH with HDInsight (Använda SSH med HDInsight).
Starta HBase-gränssnittet:
hbase shellAnvänd följande kommando för att manuellt balansera regionservrarna:
balancer
Nästa steg
Specifik information om hur du skalar ditt HDInsight-kluster finns i: