Självstudie: Skapa ett Apache Spark-maskininlärningsprogram i Azure HDInsight
I den här självstudien lär du dig att använda Jupyter Notebook för att skapa ett Apache Spark-maskininlärningsprogram för Azure HDInsight.
MLlib är Sparks anpassningsbara maskininlärningsbibliotek som består av vanliga inlärningsalgoritmer och verktyg. (Klassificering, regression, klustring, samarbetsfiltrering och minskning av dimensionalitet. Underliggande optimeringspri primitiver.)
I den här självstudien lär du dig att:
- Utveckla ett Apache Spark-maskininlärningsprogram
Förutsättningar
Ett Apache Spark-kluster i HDInsight. Se Skapa ett Apache Spark-kluster.
Kunskaper om Jupyter Notebooks med Spark på HDInsight. Mer information finns i Läsa in data och köra frågor med Apache Spark i HDInsight.
Förstå datauppsättningen
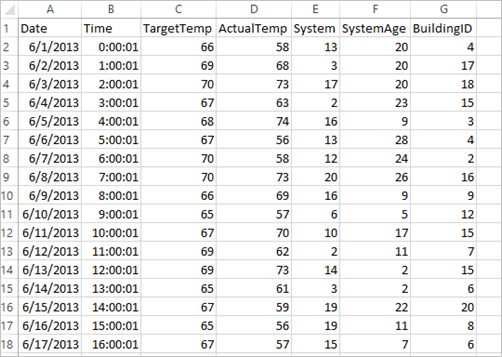
Programmet använder exempeldata HVAC.csv som är tillgängliga i alla kluster som standard. Filen finns på \HdiSamples\HdiSamples\SensorSampleData\hvac. Data visar måltemperaturen och den faktiska temperaturen för några byggnader som har installerade HVAC-system. Kolumnen System representerar system-ID:t, och kolumnen SystemAge representerar antalet år som HVAC-systemet har funnits i byggnaden. Du kan förutsäga om en byggnad blir varmare eller kallare baserat på måltemperaturen, givet system-ID och systemålder.
Utveckla ett Spark-maskininlärningsprogram med Spark MLlib
Det här programmet använder en Spark ML-pipeline för att göra en dokumentklassificering. ML-pipelines ger en enhetlig uppsättning api:er på hög nivå som bygger på DataFrames. DataFrames hjälper användarna att skapa och finjustera praktiska maskininlärningspipelines. I pipelinen delar du upp dokumentet i ord, konverterar orden till en numerisk funktionsvektor och slutligen skapa en förutsägelsemodell med funktionsvektorer och etiketter. Gör följande för att skapa programmet.
Skapa en Jupyter Notebook med hjälp av PySpark-kerneln. Anvisningarna finns i Skapa en Jupyter Notebook-fil.
Importera de typer som krävs för det här scenariot. Klistra in följande kodfragment i en tom cell och tryck sedan på SKIFT+RETUR.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayLäs in data (hvac.csv), parsa dem och använd dem för att träna modellen.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()I kodfragmentet definierar du en funktion som jämför den faktiska temperaturen med måltemperaturen. Om den faktiska temperaturen är högre är byggnaden varm, vilket markeras med värdet 1.0. Annars är byggnaden kall, vilket visas av värdet 0.0.
Konfigurera Spark-maskininlärningspipelinen som består av tre steg:
tokenizer,hashingTFochlr.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])Mer information om pipeline och hur det fungerar finns i avsnittet om Apache Spark-maskininlärnings-pipeline.
Anpassa pipelinen till utbildningsdokumentet.
model = pipeline.fit(training)Verifiera utbildningsdokumentet för att kontrollera din utveckling med programmet.
training.show()Utdatan liknar följande:
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+Jämföra utdata med CSV-råfilen. Den första raden i CSV-filen har dessa data till exempel:

Lägg märke till att den faktiska temperaturen är lägre än måltemperaturen, vilket indikerar att byggnaden är kall. Värdet för etiketten på den första raden är 0,0, vilket innebär att byggnaden inte är varm.
Förbered en datauppsättning att köra träningsmodellen mot. För att göra det skickar du ett system-ID och en systemålder (som anges som SystemInfo i träningsutdata). Modellen förutsäger om byggnaden med det system-ID:t och systemåldern kommer att vara varmare (anges med 1,0) eller svalare (anges med 0,0).
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()Gör slutligen förutsägelser på testdata.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)Utdatan liknar följande:
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))Observera den första raden i förutsägelsen. För ett HVAC-system med ID 20 och en systemålder på 25 år är byggnaden het (förutsägelse=1,0). Det första värdet för DenseVector (0,49999) motsvarar förutsägelsen 0.0 och det andra värdet (0,5001) motsvarar förutsägelsen 1.0. I utdata, trots att det andra värdet bara är marginellt högre, visar modellen förutsägelse=1.0.
Stäng anteckningsboken för att frigöra resurser. Du gör det genom att välja Stäng och stoppa i anteckningsbokens Fil-meny. Åtgärden stänger anteckningsboken.
Använda Anaconda scikit-bibliotek för Spark machine learning
Apache Spark-kluster i HDInsight innehåller Anaconda-bibliotek. Det innehåller också scikit-learn-bibliotek för machine learning. Biblioteket innehåller också olika datauppsättningar som du kan använda för att skapa exempelprogram direkt från en Jupyter Notebook. För exempel på hur du använder scikit-learn-biblioteket, se https://scikit-learn.org/stable/auto_examples/index.html.
Rensa resurser
Om du inte kommer att fortsätta att använda det här programmet tar du bort klustret som du skapade med följande steg:
Logga in på Azure-portalen.
I rutan Sök längst upp skriver du HDInsight.
Välj HDInsight-kluster under Tjänster.
I listan över HDInsight-kluster som visas väljer du ... bredvid klustret som du skapade för den här självstudien.
Välj Ta bort. Välj Ja.
Nästa steg
I den här självstudien har du lärt dig hur du använder Jupyter Notebook för att skapa ett Apache Spark-maskininlärningsprogram för Azure HDInsight. Gå vidare till nästa självstudie om du vill lära dig hur du använder IntelliJ IDEA för Spark-jobb.