Självstudie: Analysera Apache Spark-data med Power BI i HDInsight
I den här självstudien får du lära dig hur du använder Microsoft Power BI för att visualisera data i ett Apache Spark-kluster i Azure HDInsight.
I den här självstudien lär du dig att:
- Visualisera Spark-data med Power BI
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
Slutför artikeln Självstudie: Läs in data och kör frågor på ett Apache Spark-kluster i Azure HDInsight.
Valfritt: Power BI-utvärderingsprenumeration.
Kontrollera datan
Den Jupyter Notebook-anteckningsbok som du skapade i föregående självstudie innehåller kod för att skapa en hvac-tabell. Den här tabellen baseras på CSV-filen som är tillgänglig på alla HDInsight Spark-kluster på \HdiSamples\HdiSamples\SensorSampleData\hvac\hvac.csv. Följ stegen nedan för att verifiera datan.
Från Jupyter Notebook klistrar du in följande kod och trycker sedan på SKIFT + RETUR. Koden kontrollerar att tabellerna finns.
%%sql SHOW TABLESUtdata ser ut så här:
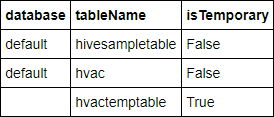
Om du har stängt anteckningsboken innan du startar självstudien så har
hvactemptablerensats, så den ingår inte i utdatan. Endast Hive-tabeller som lagras i metaarkivet (anges med False under kolumnen isTemporary) kan nås från BI-verktygen. I den här självstudien kommer du ansluta till hvac-tabellen som du skapade.Klistra in följande kod i en tom cell och tryck sedan på SKIFT+RETUR. Koden verifierar datan i tabellen.
%%sql SELECT * FROM hvac LIMIT 10Utdata ser ut så här:
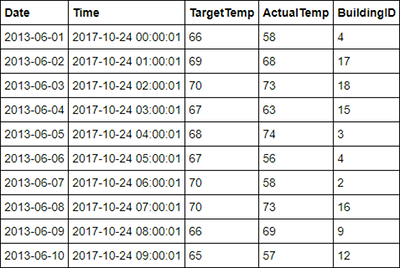
Välj Stäng och stoppa på anteckningsbokens Arkiv-meny. Stäng anteckningsboken för att frigöra resurser.
Visualisera datan
I det här avsnittet använder du Power BI för att skapa visualiseringar, rapporter och instrumentpaneler från Spark-klusterdata.
Skapa en rapport i Power BI Desktop
De första stegen i att arbeta med Spark är att ansluta till klustret i Power BI Desktop, läsa in data från klustret och skapa en grundläggande visualisering baserat på dessa data.
Öppna Power BI Desktop. Stäng välkomstskärmen för start om den öppnas.
Gå till Hämta data>mer på fliken Start...
Ange
Sparki sökrutan, välj Azure HDInsight Spark och välj sedan Anslut.
Ange din kluster-URL (i formuläret
mysparkcluster.azurehdinsight.net) i textrutan Server .Under Dataanslutningsläge väljer du DirectQuery. Välj sedan OK.
Du kan använda valfritt dataanslutningsläge med Spark. Om du använder DirectQuery visas ändringarna i rapporter utan att hela datamängden uppdateras. Om du importerar data måste du uppdatera datamängden för att se ändringarna. Mer information om hur och när du ska använda DirectQuery finns i Använda DirectQuery i Power BI.
Ange information om HDInsight-inloggningskontot och välj sedan Anslut. Standardkontonamnet är admin.
Välj tabellen
hvac, vänta och se en förhandsgranskning av data och välj sedan Läs in.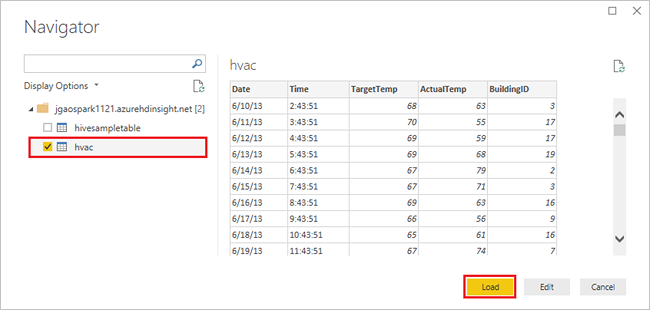
Power BI Desktop har den information som behövs för att ansluta till Spark-klustret och läsa in data från
hvac-tabellen. Tabellen och dess kolumner visas i fönstret Fält.Visualisera skillnaden mellan måltemperatur och faktisk temperatur för varje byggnad:
I fönstret VISUALISERINGAR väljer du Ytdiagram.
Dra fältet BuildingID till Axel och dra fälten ActualTemp och TargetTemp till Värde.
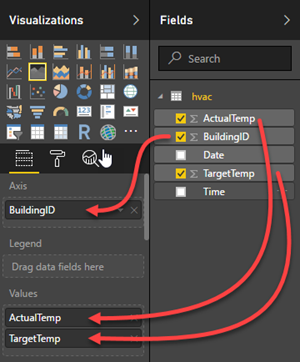
Diagrammet ser ut så här:
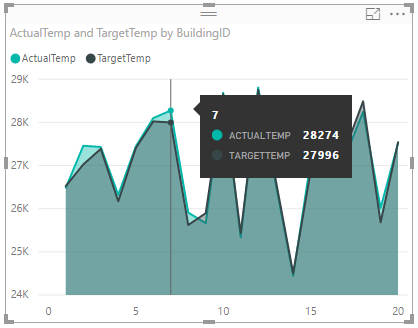
Som standard visar visualiseringen summan för ActualTemp och TargetTemp. Välj nedåtpilen bredvid ActualTemp och TargetTemp i fönstret Visualiseringar. Du kan se att Summa har valts.
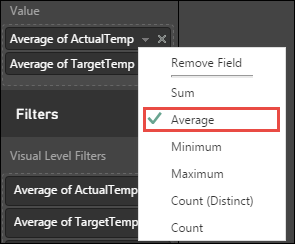
Välj nedåtpilarna bredvid ActualTemp och TargetTemp i fönstret Visualiseringar, välj Genomsnitt för att få ett genomsnitt av faktiska temperaturer och måltemperaturer för varje byggnad.
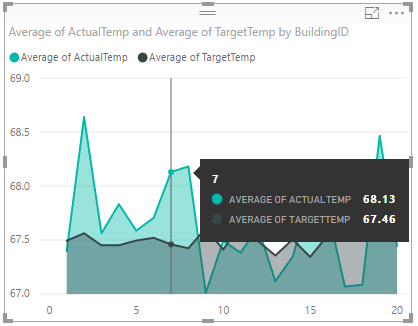
Din datavisualisering bör likna den på skärmbilden. Flytta markören över visualiseringen för att få verktygstips med relevanta data.
Gå till Spara fil>, ange namnet
BuildingTemperaturepå filen och välj sedan Spara.
Publicera rapporten till Power BI-tjänsten (valfritt)
Med Power BI-tjänsten kan du dela rapporter och instrumentpaneler i din organisation. I det här avsnittet publicerar du först datamängden och rapporten. Sedan fäster du rapporten på en instrumentpanel. Instrumentpaneler används vanligtvis för att fokusera på en delmängd data i en rapport. Du har bara en visualisering i rapporten, men det är fortfarande användbart att gå igenom stegen.
Öppna Power BI Desktop.
Från fliken Start, välj Publicera.

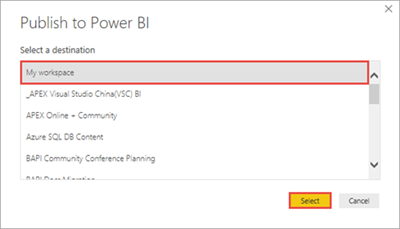
Välj en arbetsyta som du vill publicera datamängden och rapporten till och välj sedan Välj. I följande bild är standardinställningen Min arbetsyta markerad.
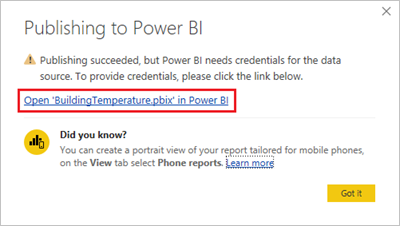
När publiceringen har slutförts väljer du Öppna "BuildingTemperature.pbix" i Power BI.
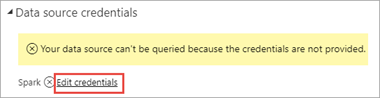
I Power BI-tjänst väljer du Ange autentiseringsuppgifter.

Välj Redigera autentiseringsuppgifter.
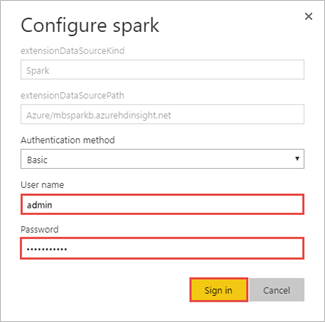
Ange information om HDInsight-inloggningskontot och välj sedan Logga in. Standardkontonamnet är admin.
I den vänstra rutan går du till Arbetsytor>Mina arbetsyterapporter> och väljer sedan BuildingTemperature.
Du bör också se BuildingTemperature under DATAMÄNGDER i den vänstra rutan.
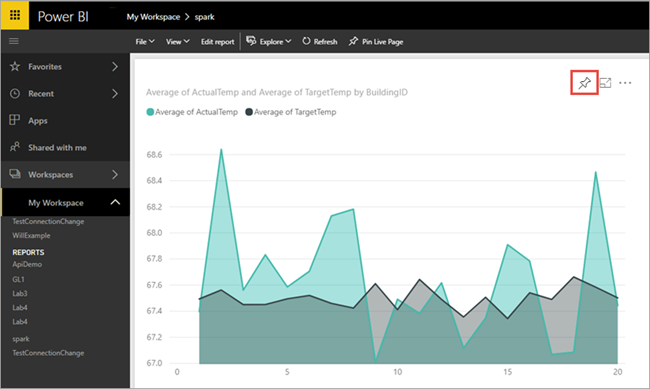
Det visuella objektet som du skapade i Power BI Desktop är nu tillgängligt i Power BI-tjänsten.
Hovra markören över visualiseringen och välj sedan fästikonen i det övre högra hörnet.
Välj "Ny instrumentpanel", ange namnet
Building temperatureoch välj sedan Fäst.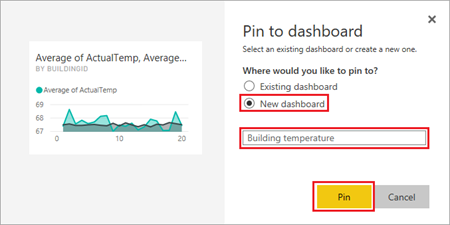
I rapporten väljer du Gå till instrumentpanel.
Ditt visuella objekt är fastsatt på instrumentpanelen. Du kan lägga till fler visuella objekt i rapporten och fästa dem på samma instrumentpanel. Mer information om rapporter och instrumentpaneler finns i Rapporter i Power BI och Instrumentpaneler i Power BI.
Rensa resurser
När du har slutfört vägledningen kanske du vill ta bort klustret. Med HDInsight lagras dina data i Azure Storage, så att du på ett säkert sätt kan ta bort ett kluster när de inte används. Du debiteras också för ett HDInsight-kluster, även om det inte används. Eftersom avgifterna för klustret är många gånger högre än avgifterna för lagring är det ekonomiskt klokt att ta bort kluster när de inte används.
Information om hur du tar bort ett kluster finns i Ta bort ett HDInsight-kluster med webbläsaren, PowerShell eller Azure CLI.
Nästa steg
I den här självstudien har du lärt dig hur du använder Microsoft Power BI för att visualisera data i ett Apache Spark-kluster i Azure HDInsight. Gå vidare till nästa artikel för att se att du kan skapa ett maskininlärningsprogram.