Träna PyTorch-modell
Den här artikeln beskriver hur du använder komponenten Train PyTorch Model i Azure Mašinsko učenje designer för att träna PyTorch-modeller som DenseNet. Träningen sker när du har definierat en modell och angett dess parametrar och kräver etiketterade data.
För närvarande stöder Train PyTorch Model-komponenten både enskild nod och distribuerad träning.
Så här använder du Train PyTorch Model
Lägg till DenseNet-komponenten eller ResNet i pipelineutkastet i designern.
Lägg till komponenten Train PyTorch Model i pipelinen. Du hittar den här komponenten under kategorin Modellträning . Expandera Träna och dra sedan komponenten Train PyTorch Model till din pipeline.
Kommentar
Train PyTorch Model-komponenten körs bättre på GPU-typberäkning för stora datamängder, annars misslyckas pipelinen. Du kan välja beräkning för en specifik komponent i komponentens högra fönster genom att ange Använd andra beräkningsmål.
Bifoga en otränad modell till vänster. Koppla träningsdatauppsättningen och valideringsdatauppsättningen till mitten och höger indata för Train PyTorch Model.
För en otränad modell måste den vara en PyTorch-modell som DenseNet. Annars utlöses "InvalidModelDirectoryError".
För datauppsättningen måste träningsdatauppsättningen vara en märkt avbildningskatalog. Se Konvertera till avbildningskatalog för hur du hämtar en märkt avbildningskatalog. Om den inte är märkt utlöses "NotLabeledDatasetError".
Träningsdatauppsättningen och valideringsdatauppsättningen har samma etikettkategorier, annars genereras en InvalidDatasetError.
För epoker anger du hur många epoker du vill träna. Hela datamängden itereras i varje epok, som standard 5.
För Batch-storlek anger du hur många instanser som ska tränas i en batch, som standard 16.
För Stegnummer för uppvärmning anger du hur många epoker du vill värma upp träningen, om den inledande inlärningsfrekvensen är något för stor för att börja konvergera, som standard 0.
För Inlärningsfrekvens anger du ett värde för inlärningsfrekvensen och standardvärdet är 0,001. Inlärningshastigheten styr storleken på det steg som används i optimeraren, till exempel sgd varje gång modellen testas och korrigeras.
Genom att ställa in hastigheten mindre testar du modellen oftare, med risk för att du fastnar i en lokal platå. Genom att ange en högre hastighet kan du konvergera snabbare, med risk för att överskrida den sanna minima.
Kommentar
Om träningsförlusten blir nan under träningen, vilket kan orsakas av för stor inlärningshastighet, kan det hjälpa att minska inlärningshastigheten. I distribuerad träning, för att hålla gradient descent stabil, beräknas den faktiska inlärningsfrekvensen med
lr * torch.distributed.get_world_size()eftersom batchstorleken för processgruppen är världsstorlekstider som för en enskild process. Polynominlärningshastighet tillämpas och kan hjälpa till att resultera i en modell med bättre prestanda.För Slumpmässigt frö kan du ange ett heltalsvärde som ska användas som frö. Vi rekommenderar att du använder ett frö om du vill säkerställa att experimentet kan återskapas mellan jobben.
För Tålamod anger du hur många epoker som ska stoppa träningen tidigt om valideringsförlusten inte minskar i följd. som standard 3.
För Utskriftsfrekvens anger du utskriftsfrekvens för träningsloggar över iterationer i varje epok, som standard 10.
Skicka pipelinen. Om din datauppsättning har större storlek tar det en stund och GPU-beräkningen rekommenderas.
Distribuerad träning
I distribuerad träning delas arbetsbelastningen för att träna en modell upp och delas mellan flera miniprocessorer, så kallade arbetsnoder. Dessa arbetsnoder fungerar parallellt för att påskynda modellträningen. Designern stöder för närvarande distribuerad utbildning för Train PyTorch Model-komponenten .
Träningstid
Distribuerad träning gör det möjligt att träna på en stor datamängd som ImageNet (1 000 klasser, 1,2 miljoner bilder) på bara flera timmar med Train PyTorch Model. I följande tabell visas träningstid och prestanda under träning av 50 epoker av Resnet50 på ImageNet från grunden baserat på olika enheter.
| Enheter | Träningstid | Träningsdataflöde | Topp 1-valideringsnoggrannhet | Topp-5 Valideringsnoggrannhet |
|---|---|---|---|---|
| 16 V100 GPU:er | 6h22min | ~3 200 bilder/s | 68.83% | 88.84% |
| 8 V100 GPU:er | 12h21min | ~1 670 bilder/s | 68.84% | 88.74% |
Klicka på den här komponentens fliken Mått och se diagram över träningsmått, till exempel "Träna bilder per sekund" och "Top 1 accuracy".

Så här aktiverar du distribuerad utbildning
Om du vill aktivera distribuerad träning för Train PyTorch Model-komponenten kan du ange jobbinställningarna i komponentens högra fönster. Endast AML Compute-kluster stöds för distribuerad träning.
Kommentar
Flera GPU:er krävs för att aktivera distribuerad träning eftersom komponenten NCCL-backend Train PyTorch Model använder cuda.
Välj komponenten och öppna den högra panelen. Expandera avsnittet Jobbinställningar .
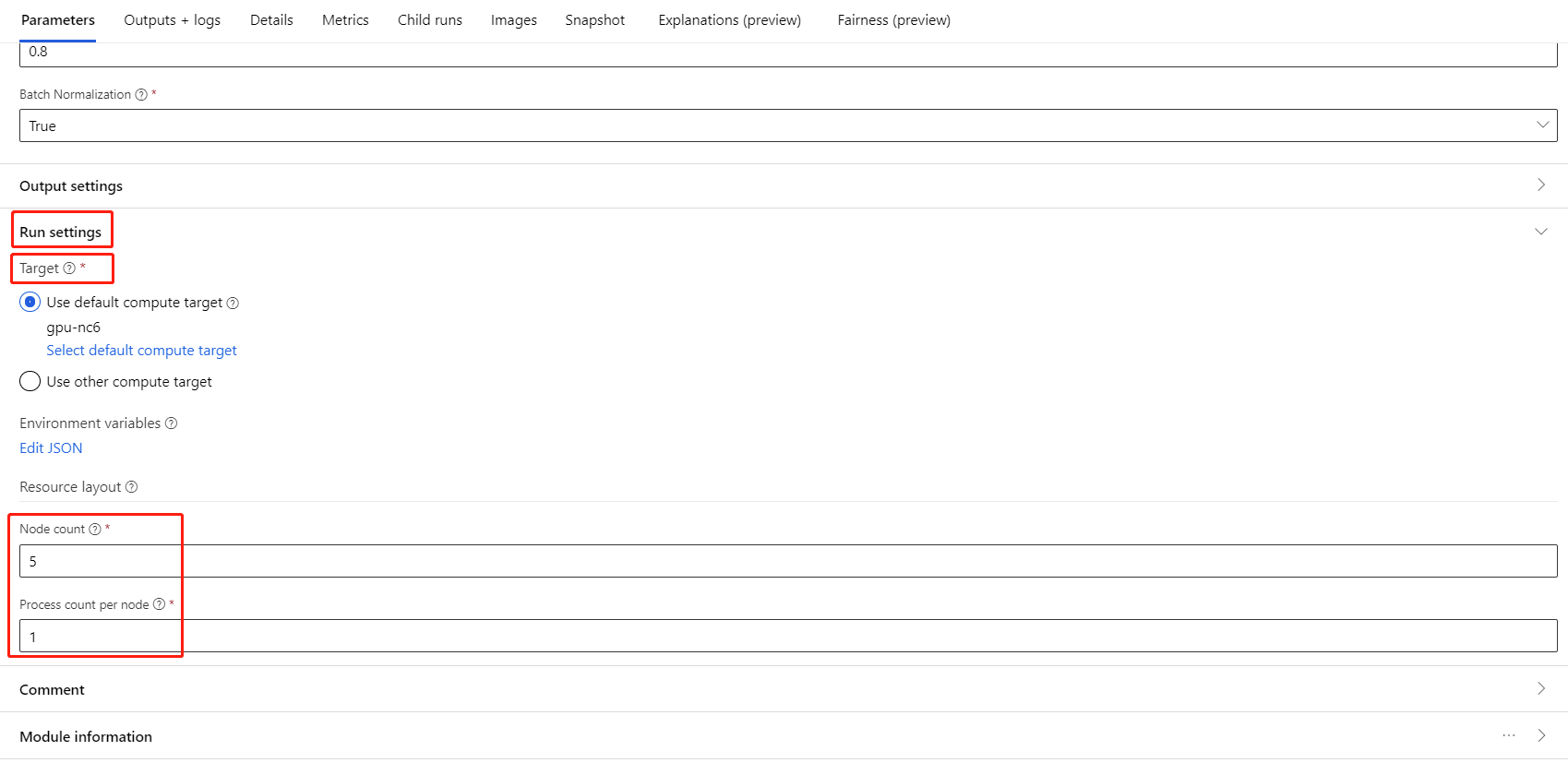
Kontrollera att du har valt AML-beräkning för beräkningsmålet.
I avsnittet Resurslayout måste du ange följande värden:
Antal noder: Antal noder i beräkningsmålet som används för träning. Den bör vara mindre än eller lika med det maximala antalet noder i beräkningsklustret. Som standard är det 1, vilket innebär jobb med en enda nod.
Antal processer per nod: Antal processer som utlöses per nod. Den bör vara mindre än eller lika med bearbetningsenheten för din beräkning. Som standard är det 1, vilket innebär ett enda processjobb.
Du kan kontrollera maximalt antal noder och bearbetningsenhet för din beräkning genom att klicka på beräkningsnamnet på sidan med beräkningsinformation.



Du kan läsa mer om distribuerad utbildning i Azure Mašinsko učenje här.
Felsökning för distribuerad utbildning
Om du aktiverar distribuerad utbildning för den här komponenten finns det drivrutinsloggar för varje process. 70_driver_log_0 är för huvudprocess. Du kan kontrollera drivrutinsloggarna för felinformation om varje process under fliken Utdata+loggar i den högra rutan.

Om den komponentaktiverade distribuerade träningen misslyckas utan några 70_driver loggar kan du söka efter 70_mpi_log felinformation.
I följande exempel visas ett vanligt fel, vilket är att antalet processer per nod är större än bearbetningsenheten för beräkningen.

Mer information om komponentfelsökning finns i den här artikeln.
Resultat
När pipelinejobbet har slutförts ansluter du Train PyTorch Model till Score Image Model för att förutsäga värden för nya indataexempel för att använda modellen för bedömning.
Tekniska anteckningar
Förväntade indata
| Namn | Type | Beskrivning |
|---|---|---|
| Otränad modell | UntrainedModelDirectory | Otränad modell, kräv PyTorch |
| Träningsdatauppsättning | ImageDirectory | Träningsdatauppsättning |
| Datauppsättning för validering | ImageDirectory | Valideringsdatauppsättning för utvärdering varje epok |
Komponentparametrar
| Name | Intervall | Typ | Standardvärde | beskrivning |
|---|---|---|---|---|
| Epoker | >0 | Integer | 5 | Välj den kolumn som innehåller etiketten eller utfallskolumnen |
| Batchstorlek | >0 | Integer | 16 | Hur många instanser som ska tränas i en batch |
| Stegnummer för uppvärmning | >=0 | Integer | 0 | Hur många epoker för att värma upp träningen |
| Inlärningstakt | >=dubbel. Epsilon | Flyttal | 0,1 | Den initiala inlärningsfrekvensen för stochastic Gradient Descent-optimeraren. |
| Slumpmässigt startvärde | Alla | Integer | 1 | Fröet för slumptalsgeneratorn som används av modellen. |
| Tålamod | >0 | Integer | 3 | Hur många epoker till tidig stoppträning |
| Utskriftsfrekvens | >0 | Integer | 10 | Utskriftsfrekvens för träningsloggar över iterationer i varje epok |
Utdata
| Namn | Type | Beskrivning |
|---|---|---|
| Tränad modell | ModelDirectory | Tränad modell |
Nästa steg
Se den uppsättning komponenter som är tillgängliga för Azure Mašinsko učenje.