Vad är Designer (v1) i Azure Mašinsko učenje?
Azure Mašinsko učenje-designern är ett dra och släpp-gränssnitt som används för att träna och distribuera modeller i Azure Mašinsko učenje Studio. Den här artikeln beskriver de uppgifter du kan utföra i designern.
Viktigt!
Designer i Azure Mašinsko učenje stöder två typer av pipelines som använder klassiska fördefinierade (v1) eller anpassade (v2) komponenter. De två komponenttyperna är inte kompatibla i pipelines och designer v1 är inte kompatibel med CLI v2 och SDK v2. Den här artikeln gäller för pipelines som använder klassiska fördefinierade (v1) komponenter.
Klassiska fördefinierade komponenter (v1) omfattar typiska databearbetnings- och maskininlärningsuppgifter som regression och klassificering. Azure Mašinsko učenje fortsätter att stödja de befintliga klassiska fördefinierade komponenterna, men inga nya fördefinierade komponenter läggs till. Distributionen av klassiska fördefinierade (v1) komponenter stöder inte hanterade onlineslutpunkter (v2).
Med anpassade komponenter (v2) kan du omsluta din egen kod som komponenter, vilket möjliggör delning mellan arbetsytor och sömlös redigering i Azure Mašinsko učenje studio-, CLI v2- och SDK v2-gränssnitt. Det är bäst att använda anpassade komponenter för nya projekt eftersom de är kompatibla med Azure Mašinsko učenje v2 och fortsätter att ta emot nya uppdateringar. Mer information om anpassade komponenter och Designer (v2) finns i Azure Mašinsko učenje designer (v2).
Följande animerade GIF visar hur du kan skapa en pipeline visuellt i Designer genom att dra och släppa tillgångar och ansluta dem.

Mer information om de komponenter som är tillgängliga i designern finns i referensen Algoritm och komponent. Information om hur du kommer igång med designern finns i Självstudie: Träna en regressionsmodell utan kod.
Modellträning och distribution
Designern använder din Azure Mašinsko učenje-arbetsyta för att organisera delade resurser, till exempel:
- Pipelines
- Data
- Beräkningsresurser
- Registrerade modeller
- Publicerade pipelinejobb
- Realtidsslutpunkter
Följande diagram visar hur du kan använda designern för att skapa ett maskininlärningsarbetsflöde från slutpunkt till slutpunkt. Du kan träna, testa och distribuera modeller i designergränssnittet.
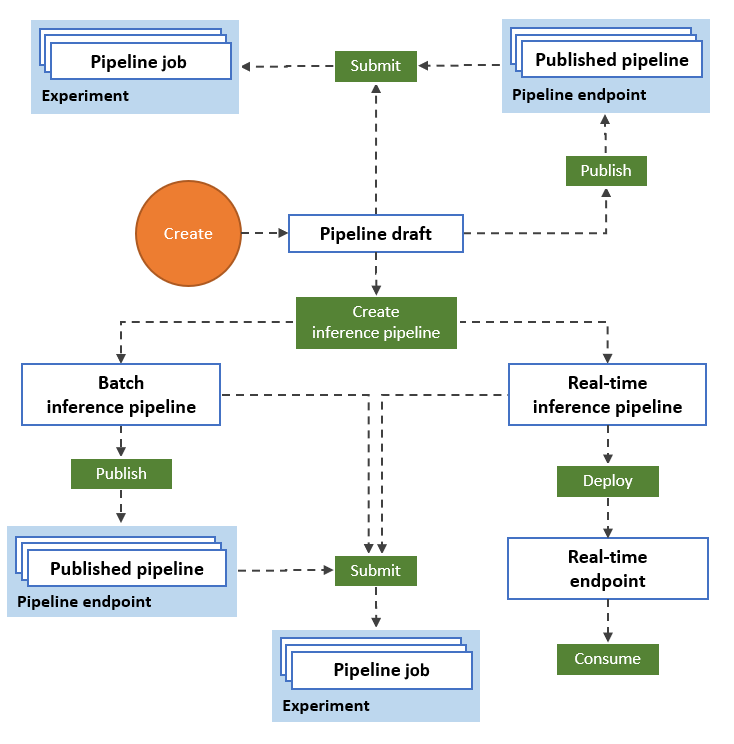
- Dra och släpp datatillgångar och komponenter till den visuella designerarbetsytan och anslut komponenterna för att skapa ett pipeline-utkast.
- Skicka ett pipelinejobb som använder beräkningsresurserna i din Azure Mašinsko učenje-arbetsyta.
- Konvertera dina träningspipelines till slutsatsdragningspipelines.
- Publicera dina pipelines till en REST-pipelineslutpunkt för att skicka nya pipelines som körs med olika parametrar och datatillgångar.
- Publicera en träningspipeline för att återanvända en enda pipeline för att träna flera modeller samtidigt som parametrar och datatillgångar ändras.
- Publicera en pipeline för batchinferens för att göra förutsägelser om nya data med hjälp av en tidigare tränad modell.
- Distribuera en pipeline för slutsatsdragning i realtid till en onlineslutpunkt för att göra förutsägelser om nya data i realtid.
Data
En maskininlärningsdatatillgång gör det enkelt att komma åt och arbeta med dina data. Designern innehåller flera exempeldatatillgångar som du kan experimentera med. Du kan registrera fler datatillgångar när du behöver dem.
Komponenter
En komponent är en algoritm som du kan köra på dina data. Designern har flera komponenter som sträcker sig från funktioner för dataingress till tränings-, bedömnings- och valideringsprocesser.
En komponent kan ha parametrar som du använder för att konfigurera komponentens interna algoritmer. När du väljer en komponent på arbetsytan visas komponentens parametrar och andra inställningar i ett egenskapsfönster till höger om arbetsytan. Du kan ändra parametrarna och ange beräkningsresurserna för enskilda komponenter i fönstret.
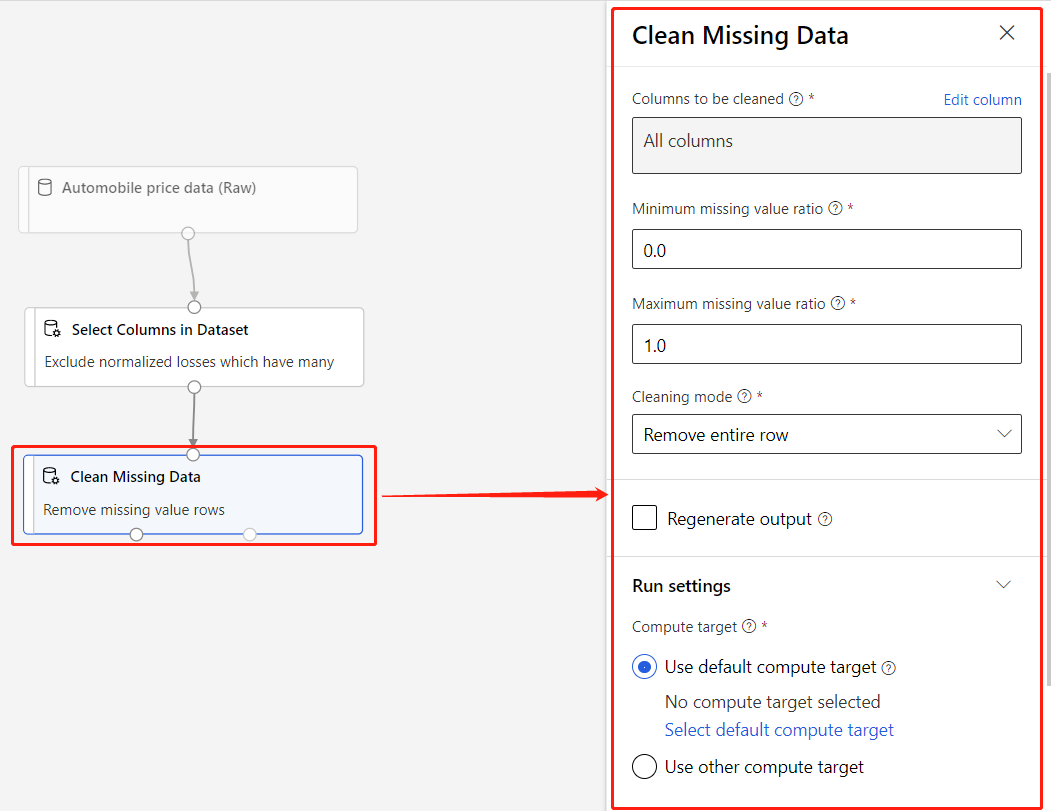
Mer information om biblioteket med tillgängliga maskininlärningsalgoritmer finns i referensen Algoritm och komponent. Mer information om hur du väljer en algoritm finns i azure Mašinsko učenje-algoritmens fuskblad.
Pipelines
En pipeline består av datatillgångar och analytiska komponenter som du ansluter. Pipelines hjälper dig att återanvända ditt arbete och organisera dina projekt.
Pipelines har många användningsområden. Du kan skapa pipelines som:
- Träna en enda modell.
- Träna flera modeller.
- Gör förutsägelser i realtid eller i batch.
- Rensa endast data.
Pipelineutkast
När du redigerar en pipeline i designern sparas förloppet som ett pipelineutkast. Du kan redigera ett pipelineutkast när som helst genom att lägga till eller ta bort komponenter, konfigurera beräkningsmål eller ange parametrar.
En giltig pipeline har följande egenskaper:
- Datatillgångar kan endast ansluta till komponenter.
- Komponenter kan bara ansluta till datatillgångar eller till andra komponenter.
- Alla indataportar för komponenter måste ha en viss anslutning till dataflödet.
- Alla obligatoriska parametrar för varje komponent måste anges.
När du är redo att köra pipelineutkastet sparar du pipelinen och skickar ett pipelinejobb.
Pipelinejobb
Varje gång du kör en pipeline lagras konfigurationen av pipelinen och dess resultat på din arbetsyta som ett pipelinejobb. Pipelinejobb grupperas i experiment för att organisera jobbhistorik.
Du kan gå tillbaka till alla pipelinejobb för att inspektera det för felsökning eller granskning. Klona ett pipelinejobb för att skapa ett nytt pipelineutkast som ska redigeras.
Beräkningsresurser
Beräkningsmål är kopplade till din Azure Mašinsko učenje-arbetsyta i Azure Mašinsko učenje Studio. Använd beräkningsresurser från arbetsytan för att köra pipelinen och vara värd för dina distribuerade modeller som onlineslutpunkter eller som pipelineslutpunkter för batchinferens. De beräkningsmål som stöds är följande:
| Beräkningsmål | Utbildning | Distribution |
|---|---|---|
| Azure Mašinsko učenje-beräkning | ✓ | |
| Azure Kubernetes Service (AKS) | ✓ |
Distribuera
Om du vill utföra realtidsinferenser måste du distribuera en pipeline som en onlineslutpunkt. Onlineslutpunkten skapar ett gränssnitt mellan ett externt program och din bedömningsmodell. Slutpunkten baseras på REST, ett populärt arkitekturval för webbprogrammeringsprojekt. Ett anrop till en onlineslutpunkt returnerar förutsägelseresultat till programmet i realtid.
Om du vill göra ett anrop till en onlineslutpunkt skickar du den API-nyckel som skapades när du distribuerade slutpunkten. Onlineslutpunkter måste distribueras till ett AKS-kluster. Information om hur du distribuerar din modell finns i Självstudie: Distribuera en maskininlärningsmodell med designern.
Publicera
Du kan också publicera en pipeline till en pipelineslutpunkt. På samma sätt som en onlineslutpunkt kan du med en pipelineslutpunkt skicka nya pipelinejobb från externa program med hjälp av REST-anrop. Du kan dock inte skicka eller ta emot data i realtid med hjälp av en pipelineslutpunkt.
Publicerade pipelineslutpunkter är flexibla och kan användas för att träna eller träna om modeller, göra batchinferenser eller bearbeta nya data. Du kan publicera flera pipelines till en enda pipelineslutpunkt och ange vilken pipelineversion som ska köras.
En publicerad pipeline körs på de beräkningsresurser som du definierar i pipelineutkastet för varje komponent. Designern skapar samma PublishedPipeline-objekt som SDK:t.
Relaterat innehåll
- Lär dig grunderna i förutsägelseanalys och maskininlärning med Självstudie: Förutsäga bilpriser med designern.
- Lär dig hur du ändrar befintliga designerexempel för att anpassa dem efter dina behov.