Konfigurera ett bildetikettprojekt
Lär dig hur du skapar och kör dataetiketteringsprojekt för att märka bilder i Azure Machine Learning. Använd maskininlärning (ML)-assisterad dataetikettering eller etikettering för människa i loopen för att hjälpa till med uppgiften.
Konfigurera etiketter för klassificering, objektidentifiering (avgränsningsruta), instanssegmentering (polygon) eller semantisk segmentering (förhandsversion).
Du kan också använda verktyget för dataetiketter i Azure Machine Learning för att skapa ett textetikettprojekt.
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Förhandsversionen tillhandahålls utan ett serviceavtal och rekommenderas inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Funktioner för bildetiketter
Azure Machine Learning-dataetiketter är ett verktyg som du kan använda för att skapa, hantera och övervaka dataetiketteringsprojekt. Använd portalen om du vill:
- Samordna data, etiketter och teammedlemmar för att effektivt hantera etiketteringsuppgifterna.
- Spåra förloppet och underhålla kön med ofullständiga etiketteringsuppgifter.
- Starta och stoppa projektet och kontrollera förloppet för etikettering.
- Granska och exportera etiketterade data som en Azure Machine Learning-datauppsättning.
Viktigt!
De databilder som du arbetar med i Azure Machine Learning-dataetikettverktyget måste vara tillgängliga i ett Azure Blob Storage-datalager. Om du inte har något befintligt datalager kan du ladda upp dina datafiler till ett nytt datalager när du skapar ett projekt.
Bilddata kan vara alla filer som har något av dessa filnamnstillägg:
.jpg.jpeg.png.jpe.jfif.bmp.tif.tiff.dcm.dicom
Varje fil är ett objekt som ska märkas.
Du kan också använda en MLTable datatillgång som indata till ett bildetikettprojekt, så länge bilderna i tabellen är ett av ovanstående format. Mer information finns i Använda MLTable datatillgångar.
Förutsättningar
Du använder dessa objekt för att konfigurera bildetiketter i Azure Machine Learning:
- De data som du vill märka, antingen i lokala filer eller i Azure Blob Storage.
- Den uppsättning etiketter som du vill använda.
- Instruktionerna för etikettering.
- En Azure-prenumeration. Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar.
- En Azure Machine Learning-arbetsyta. Se Skapa en Azure Machine Learning-arbetsyta.
Skapa etiketteringsprojekt för avbildningar
Etiketteringsprojekt administreras i Azure Machine Learning. Använd sidan Dataetiketter i Machine Learning för att hantera dina projekt.
Om dina data redan finns i Azure Blob Storage kontrollerar du att de är tillgängliga som ett datalager innan du skapar etikettprojektet.
Om du vill skapa ett projekt väljer du Lägg till projekt.
Som Projektnamn anger du ett namn för projektet.
Du kan inte återanvända projektnamnet, även om du tar bort projektet.
Om du vill skapa ett projekt för bildetiketter väljer du Bild för Medietyp.
För Aktivitetstyp för etikettering väljer du ett alternativ för ditt scenario:
- Om du bara vill använda en enskild etikett på en bild från en uppsättning etiketter väljer du Bildklassificering Flera klasser.
- Om du vill använda en eller flera etiketter på en bild från en uppsättning etiketter väljer du Multi-label för bildklassificering. Till exempel kan ett foto av en hund märkas med både hund och dagtid.
- Om du vill tilldela en etikett till varje objekt i en bild och lägga till avgränsningsrutor väljer du Objektidentifiering (avgränsningsruta).
- Om du vill tilldela en etikett till varje objekt i en bild och rita en polygon runt varje objekt väljer du Polygon (instanssegmentering).
- Om du vill rita masker på en bild och tilldela en etikettklass på pixelnivå väljer du Semantisk segmentering (förhandsversion).
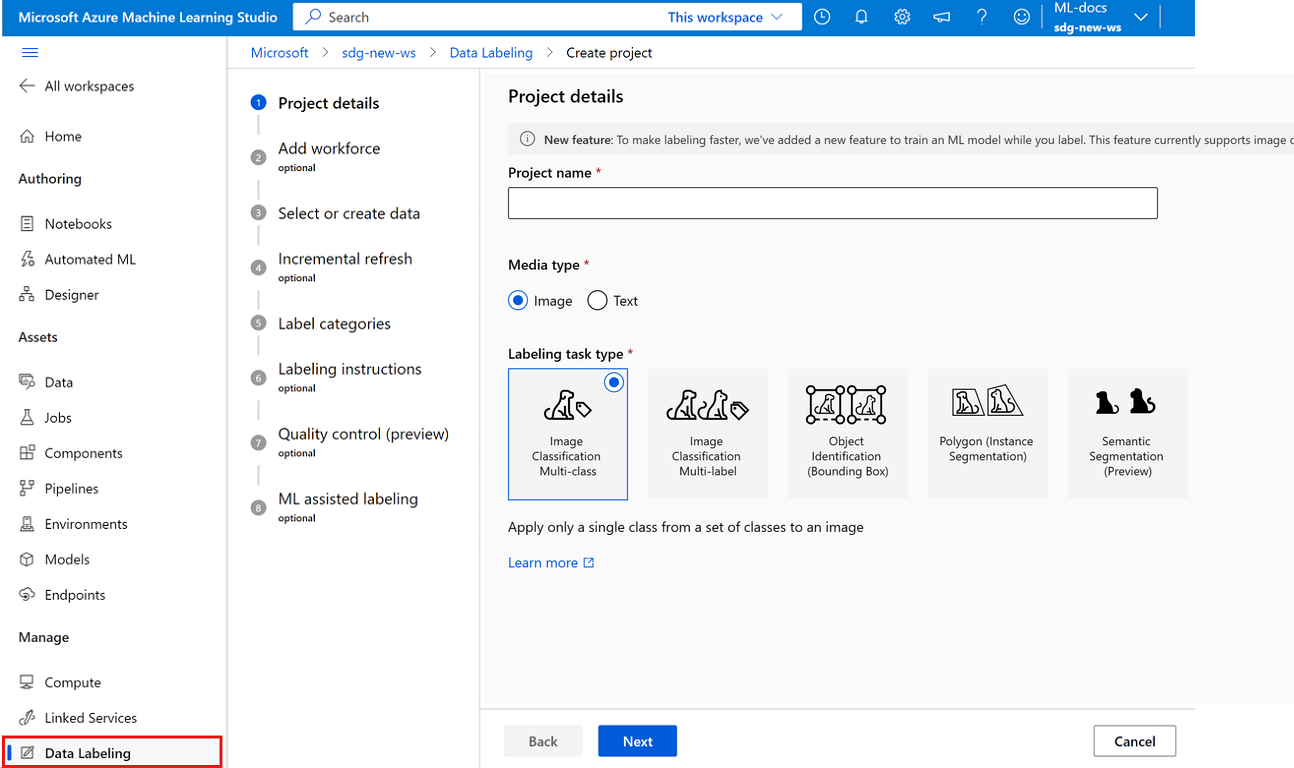
Klicka på Nästa när du vill fortsätta.
Lägg till personal (valfritt)
Välj Använd ett leverantörsetikettföretag från Azure Marketplace endast om du har anlitat ett dataetikettföretag från Azure Marketplace. Välj sedan leverantören. Om leverantören inte visas i listan avmarkerar du det här alternativet.
Se till att du först kontaktar leverantören och signerar ett kontrakt. Mer information finns i Arbeta med ett leverantörsföretag för dataetiketter (förhandsversion).
Klicka på Nästa när du vill fortsätta.
Ange de data som ska märkas
Om du redan har skapat en datauppsättning som innehåller dina data väljer du datauppsättningen i listrutan Välj en befintlig datauppsättning .
Du kan också välja Skapa en datauppsättning för att använda ett befintligt Azure-datalager eller för att ladda upp lokala filer.
Kommentar
Ett projekt får inte innehålla fler än 500 000 filer. Om datamängden överskrider det här antalet filer läses endast de första 500 000 filerna in.
Datakolumnmappning (förhandsversion)
Om du väljer en MLTable-datatillgång visas ett annat steg för datakolumnmappning där du kan ange kolumnen som innehåller bild-URL:erna.
Du måste ange en kolumn som mappar till fältet Bild . Du kan också mappa andra kolumner som finns i data. Om dina data till exempel innehåller en etikettkolumn kan du mappa dem till fältet Kategori . Om dina data innehåller en konfidenskolumn kan du mappa dem till fältet Konfidens .
Om du importerar etiketter från ett tidigare projekt måste etiketterna ha samma format som de etiketter som du skapar. Om du till exempel skapar etiketter för avgränsningsrutor måste etiketterna som du importerar också vara avgränsningsetiketter.
Importalternativ (förhandsversion)
När du inkluderar en kategorikolumn i steget Datakolumnmappning använder du Importalternativ för att ange hur du ska behandla etiketterade data.
Du måste ange en kolumn som mappar till fältet Bild . Du kan också mappa andra kolumner som finns i data. Om dina data till exempel innehåller en etikettkolumn kan du mappa dem till fältet Kategori . Om dina data innehåller en konfidenskolumn kan du mappa dem till fältet Konfidens .
Om du importerar etiketter från ett tidigare projekt måste etiketterna ha samma format som de etiketter som du skapar. Om du till exempel skapar etiketter för avgränsningsrutor måste etiketterna som du importerar också vara avgränsningsetiketter.
Skapa en datauppsättning från ett Azure-datalager
I många fall kan du ladda upp lokala filer. Azure Storage Explorer ger dock ett snabbare och mer robust sätt att överföra en stor mängd data. Vi rekommenderar Storage Explorer som standard sätt att flytta filer.
Så här skapar du en datauppsättning från data som redan lagras i Blob Storage:
- Välj Skapa.
- Som Namn anger du ett namn för datauppsättningen. Skriv en beskrivning om du vill.
- Kontrollera att datauppsättningstypen är inställd på Arkiv. Endast fildatauppsättningstyper stöds för bilder.
- Välj Nästa.
- Välj Från Azure Storage och välj sedan Nästa.
- Välj datalagringen och välj sedan Nästa.
- Om dina data finns i en undermapp i Blob Storage väljer du Bläddra för att välja sökvägen.
- Om du vill inkludera alla filer i undermapparna för den valda sökvägen lägger du
/**till i sökvägen. - Om du vill inkludera alla data i den aktuella containern och dess undermappar lägger du
**/*.*till i sökvägen.
- Om du vill inkludera alla filer i undermapparna för den valda sökvägen lägger du
- Välj Skapa.
- Välj den datatillgång som du skapade.
Skapa en datauppsättning från uppladdade data
Så här laddar du upp dina data direkt:
- Välj Skapa.
- Som Namn anger du ett namn för datauppsättningen. Skriv en beskrivning om du vill.
- Kontrollera att datauppsättningstypen är inställd på Arkiv. Endast fildatauppsättningstyper stöds för bilder.
- Välj Nästa.
- Välj Från lokala filer och välj sedan Nästa.
- (Valfritt) Välj ett datalager. Du kan också lämna standardvärdet för att ladda upp till standardbloblagringen (workspaceblobstore) för din Machine Learning-arbetsyta.
- Välj Nästa.
- Välj Överför>uppladdningsfiler eller ladda upp>uppladdningsmapp för att välja de lokala filer eller mappar som ska laddas upp.
- Leta reda på dina filer eller mappar i webbläsarfönstret och välj sedan Öppna.
- Fortsätt att välja Ladda upp tills du anger alla filer och mappar.
- Du kan också välja att markera kryssrutan Skriv över om den redan finns . Kontrollera listan över filer och mappar.
- Välj Nästa.
- Bekräfta informationen. Välj Tillbaka för att ändra inställningarna eller välj Skapa för att skapa datauppsättningen.
- Välj slutligen den datatillgång som du skapade.
Konfigurera inkrementell uppdatering
Om du planerar att lägga till nya datafiler i datauppsättningen använder du inkrementell uppdatering för att lägga till filerna i projektet.
När Aktivera inkrementell uppdatering med jämna mellanrum anges, kontrolleras datauppsättningen regelbundet för att nya filer ska läggas till i ett projekt baserat på märkningens slutförandefrekvens. Kontrollen av nya data stoppas när projektet innehåller högst 500 000 filer.
Välj Aktivera inkrementell uppdatering med jämna mellanrum när du vill att projektet kontinuerligt ska övervaka nya data i datalagringen.
Avmarkera markeringen om du inte vill att nya filer i datalagringen ska läggas till automatiskt i projektet.
Viktigt!
När inkrementell uppdatering är aktiverad ska du inte skapa en ny version för den datauppsättning som du vill uppdatera. Om du gör det visas inte uppdateringarna eftersom dataetikettprojektet är fäst på den ursprungliga versionen. Använd i stället Azure Storage Explorer för att ändra dina data i lämplig mapp i Blob Storage.
Ta inte heller bort data. Om du tar bort data från datauppsättningen som används i ditt projekt uppstår ett fel i projektet.
När projektet har skapats använder du fliken Information för att ändra inkrementell uppdatering, visa tidsstämpeln för den senaste uppdateringen och begära en omedelbar uppdatering av data.
Ange etikettklasser
På sidan Etikettkategorier anger du en uppsättning klasser för att kategorisera dina data.
Etiketternas noggrannhet och hastighet påverkas av deras möjlighet att välja mellan klasser. I stället för att till exempel stava ut hela släktet och arterna för växter eller djur, använder du en fältkod eller förkortar släktet.
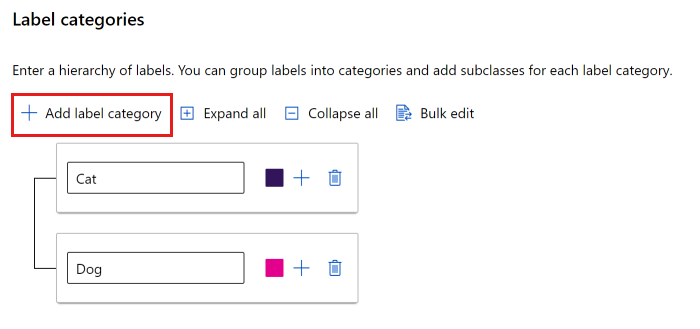
Du kan antingen använda en platt lista eller skapa grupper med etiketter.
Om du vill skapa en platt lista väljer du Lägg till etikettkategori för att skapa varje etikett.
Om du vill skapa etiketter i olika grupper väljer du Lägg till etikettkategori för att skapa etiketter på den översta nivån. Välj sedan plustecknet (+) under varje översta nivå för att skapa nästa nivå av etiketter för den kategorin. Du kan skapa upp till sex nivåer för gruppering.
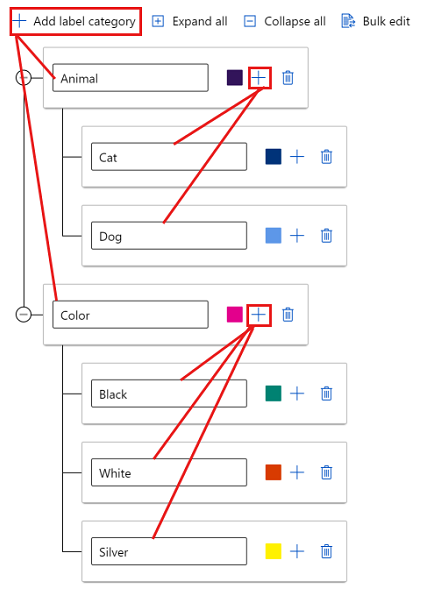
Du kan välja etiketter på valfri nivå under taggningsprocessen. Etiketterna Animal, , Animal/CatAnimal/Dog, Color, , Color/Black, Color/Whiteoch Color/Silver är till exempel alla tillgängliga alternativ för en etikett. I ett projekt med flera etiketter finns det inget krav på att välja en av varje kategori. Om det är din avsikt måste du inkludera den här informationen i dina instruktioner.
Beskriva uppgiften för bildetiketter
Det är viktigt att tydligt förklara etikettuppgiften. På sidan Etiketteringsinstruktioner kan du lägga till en länk till en extern webbplats med etiketteringsinstruktioner, eller så kan du ange instruktioner i redigeringsrutan på sidan. Håll instruktionerna uppgiftsorienterade och lämpliga för målgruppen. Tänk på följande frågor:
- Vilka etiketter kommer etiketterna att se och hur väljer de bland dem? Finns det en referenstext att referera till?
- Vad ska de göra om ingen etikett verkar lämplig?
- Vad ska de göra om flera etiketter verkar lämpliga?
- Vilket förtroendetröskelvärde ska de gälla för en etikett? Vill du ha etikettens bästa gissning om de inte är säkra?
- Vad ska de göra med delvis ockluderade eller överlappande objekt av intresse?
- Vad ska de göra om ett objekt av intresse klipps av bildens kant?
- Vad ska de göra om de tror att de gjorde ett misstag när de har skickat in en etikett?
- Vad ska de göra om de upptäcker problem med bildkvalitet, inklusive dåliga ljusförhållanden, reflektioner, förlust av fokus, oönstrade bakgrund ingår, onormala kameravinklar och så vidare?
- Vad ska de göra om flera granskare har olika åsikter om att tillämpa en etikett?
För avgränsningsrutor är viktiga frågor:
- Hur definieras avgränsningsrutan för den här uppgiften? Ska det stanna helt på insidan av objektet eller ska det vara på utsidan? Bör den beskäras så nära som möjligt, eller är något godkännande acceptabelt?
- Vilken nivå av omsorg och konsekvens förväntar du dig att etiketterna ska tillämpas i definitionen av avgränsningsrutor?
- Vad är den visuella definitionen för varje etikettklass? Kan du ange en lista över normala fall, kantfall och räknarfall för varje klass?
- Vad ska etiketterna göra om objektet är litet? Ska den märkas som ett objekt eller ska de ignorera det objektet som bakgrund?
- Hur ska etiketter hantera ett objekt som bara visas delvis i bilden?
- Hur ska etiketter hantera ett objekt som delvis täcks av ett annat objekt?
- Hur ska etiketter hantera ett objekt som inte har någon tydlig gräns?
- Hur ska etiketter hantera ett objekt som inte är objektklassen av intresse, men som har visuella likheter med en relevant objekttyp?
Kommentar
Etiketter kan välja de första nio etiketterna med hjälp av nummernycklarna 1 till 9. Du kanske vill inkludera den här informationen i dina instruktioner.
Kvalitetskontroll (förhandsversion)
Om du vill få mer exakta etiketter använder du sidan Kvalitetskontroll för att skicka varje objekt till flera etiketter.
Viktigt!
Konsensusetiketter finns för närvarande i offentlig förhandsversion.
Förhandsversionen tillhandahålls utan ett serviceavtal och rekommenderas inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade.
Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Om du vill att varje objekt ska skickas till flera etiketter väljer du Aktivera konsensusetiketter (förhandsversion). Ange sedan värden för Minsta etiketter och Maximalt antal etiketter för att ange hur många etiketter som ska användas. Se till att du har så många etiketter som möjligt som ditt maximala antal. Du kan inte ändra de här inställningarna när projektet har startats.
Om en konsensus uppnås från det minsta antalet etiketter är objektet märkt. Om en konsensus inte nås skickas objektet till fler etiketter. Om det inte finns någon konsensus när objektet har gått till det maximala antalet etiketter är dess status Behovsgranskning och projektägaren ansvarar för att märka objektet.
Kommentar
Instanssegmenteringsprojekt kan inte använda konsensusetiketter.
Använda ML-assisterad dataetikettering
För att påskynda etiketteringsuppgifterna kan du på sidan med ML-assisterad etikettering utlösa automatiska maskininlärningsmodeller. Medicinska bilder (filer som har ett .dcm tillägg) ingår inte i assisterad etikettering. Om projekttypen är semantisk segmentering (förhandsversion) är ML-assisterad etikettering inte tillgänglig.
I början av ditt etikettprojekt blandas objekten i en slumpmässig ordning för att minska potentiella fördomar. Den tränade modellen återspeglar dock eventuella fördomar som finns i datamängden. Om till exempel 80 procent av dina objekt är av en enda klass hamnar cirka 80 procent av de data som används för att träna modellen i den klassen.
Om du vill aktivera assisterad etikettering väljer du Aktivera ML-assisterad etikettering och anger en GPU. Om du inte har en GPU på arbetsytan skapas ett GPU-kluster (resursnamn: DefLabelNC6v3, vmsize: Standard_NC6s_v3) åt dig och läggs till i arbetsytan. Klustret skapas med minst noll noder, vilket innebär att det inte kostar något när det inte används.
ML-assisterad etikettering består av två faser:
- Klustring
- Prelabeling
Antalet märkta dataobjekt som behövs för att starta assisterad etikettering är inte ett fast nummer. Det här antalet kan variera avsevärt från ett etikettprojekt till ett annat. För vissa projekt är det ibland möjligt att se prelabel- eller klusteraktiviteter när 300 objekt har etiketterats manuellt. ML-assisterad etikettering använder en teknik som kallas överföringsinlärning. Överföringsinlärning använder en förtränad modell för att få igång träningsprocessen. Om datamängdens klasser liknar klasserna i den förträrade modellen kan prelabels bli tillgängliga efter bara några hundra manuellt märkta objekt. Om din datauppsättning skiljer sig avsevärt från de data som används för att träna modellen i förväg kan processen ta längre tid.
När du använder konsensusetiketter används konsensusetiketten för träning.
Eftersom de slutliga etiketterna fortfarande förlitar sig på indata från etiketten kallas den här tekniken ibland för etikettering av människa i loopen .
Kommentar
ML-assisterad dataetikettering stöder inte standardlagringskonton som skyddas bakom ett virtuellt nätverk. Du måste använda ett lagringskonto som inte är standard för ML-assisterad dataetikettering. Lagringskontot som inte är standard kan skyddas bakom det virtuella nätverket.
Klustring
När du har skickat några etiketter börjar klassificeringsmodellen gruppera liknande objekt. Dessa liknande bilder visas för etiketter på samma sida för att göra manuell taggning mer effektiv. Klustring är särskilt användbart när en etikett visar ett rutnät med fyra, sex eller nio bilder.
När en maskininlärningsmodell har tränats på dina manuellt märkta data trunkeras modellen till det senaste helt anslutna lagret. Omärkta bilder skickas sedan genom den trunkerade modellen i en process som kallas inbäddning eller funktionalisering. Den här processen bäddar in varje bild i ett högdimensionellt utrymme som modellskiktet definierar. Andra bilder i det utrymme som är närmast avbildningen används för klustringsuppgifter.
Klustringsfasen visas inte för objektidentifieringsmodeller eller textklassificering.
Prelabeling
När du har skickat tillräckligt med etiketter för träning förutsäger antingen en klassificeringsmodell taggar eller så förutsäger en objektidentifieringsmodell avgränsningsrutor. Etiketten ser nu sidor som innehåller förutsagda etiketter som redan finns på varje objekt. För objektidentifiering visas även förutsagda rutor. Uppgiften innebär att granska dessa förutsägelser och korrigera eventuella felaktigt märkta bilder innan sidan skickas in.
När en maskininlärningsmodell har tränats på dina manuellt märkta data utvärderas modellen på en testuppsättning med manuellt märkta objekt. Utvärderingen hjälper till att fastställa modellens noggrannhet vid olika förtroendetrösklar. Utvärderingsprocessen anger ett förtroendetröskelvärde som modellen är tillräckligt exakt för att visa prelabels. Modellen utvärderas sedan mot omärkta data. Objekt med förutsägelser som är mer säkra än tröskelvärdet används för prelabeling.
Initiera bildetikettprojektet
När etikettprojektet har initierats är vissa aspekter av projektet oföränderliga. Du kan inte ändra aktivitetstyp eller datauppsättning. Du kan ändra etiketter och URL:en för aktivitetsbeskrivningen. Granska inställningarna noggrant innan du skapar projektet. När du har skickat projektet går du tillbaka till översiktssidan för dataetiketter , som visar projektet som Initierande.
Kommentar
Översiktssidan kanske inte uppdateras automatiskt. Efter en paus uppdaterar du sidan manuellt för att se projektets status som Skapad.
Felsökning
Information om problem med att skapa ett projekt eller komma åt data finns i Felsöka dataetiketter.