Skapa och kör Machine Learning-pipelines med Azure Machine Learning SDK
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
I den här artikeln får du lära dig hur du skapar och kör maskininlärningspipelines med hjälp av Azure Mašinsko učenje SDK. Använd ML-pipelines för att skapa ett arbetsflöde som sammanfogar olika ML-faser. Publicera sedan pipelinen för senare åtkomst eller delning med andra. Spåra ML-pipelines för att se hur din modell presterar i verkligheten och för att identifiera dataavvikelser. ML-pipelines är idealiska för batchbedömningsscenarier, med hjälp av olika beräkningar, återanvändning av steg i stället för att köra dem igen och dela ML-arbetsflöden med andra.
Den här artikeln är inte en självstudie. Vägledning om hur du skapar din första pipeline finns i Självstudie: Skapa en Azure Mašinsko učenje pipeline för batchbedömning eller Använd automatiserad ML i en Azure Mašinsko učenje pipeline i Python.
Du kan använda en annan typ av pipeline som kallas azure pipeline för CI/CD-automatisering av ML-uppgifter, men den typen av pipeline lagras inte på din arbetsyta. Jämför dessa olika pipelines.
DE ML-pipelines som du skapar är synliga för medlemmarna i din Azure Mašinsko učenje-arbetsyta.
ML-pipelines körs på beräkningsmål (se Vad är beräkningsmål i Azure Mašinsko učenje). Pipelines kan läsa och skriva data till och från Azure Storage-platser som stöds.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Mašinsko učenje.
Förutsättningar
En Azure Machine Learning-arbetsyta. Skapa arbetsyteresurser.
Konfigurera utvecklingsmiljön för att installera Azure Mašinsko učenje SDK eller använd en Azure Mašinsko učenje beräkningsinstans med SDK:t redan installerat.
Börja med att ansluta din arbetsyta:
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config()
Konfigurera maskininlärningsresurser
Skapa de resurser som krävs för att köra en ML-pipeline:
Konfigurera ett datalager som används för att komma åt de data som behövs i pipelinestegen.
Konfigurera ett
Datasetobjekt så att det pekar på beständiga data som finns i eller är tillgängliga i ett datalager. Konfigurera ettOutputFileDatasetConfigobjekt för temporära data som skickas mellan pipelinesteg.Konfigurera de beräkningsmål som pipelinestegen ska köras på.
Konfigurera ett datalager
Ett datalager lagrar data som pipelinen kan komma åt. Varje arbetsyta har ett standarddatalager. Du kan registrera fler datalager.
När du skapar din arbetsyta är Azure Files och Azure Blob Storage anslutna till arbetsytan. Ett standarddatalager registreras för att ansluta till Azure Blob Storage. Mer information finns i Bestämma när du ska använda Azure Files, Azure Blobs eller Azure Disks.
# Default datastore
def_data_store = ws.get_default_datastore()
# Get the blob storage associated with the workspace
def_blob_store = Datastore(ws, "workspaceblobstore")
# Get file storage associated with the workspace
def_file_store = Datastore(ws, "workspacefilestore")
Steg förbrukar vanligtvis data och producerar utdata. Ett steg kan skapa data som en modell, en katalog med modell och beroende filer eller tillfälliga data. Dessa data är sedan tillgängliga för andra steg senare i pipelinen. Mer information om hur du ansluter din pipeline till dina data finns i artiklarna How to Access Data and How to Register Datasets (Så här kommer du åt data och hur du registrerar datamängder).
Konfigurera data med Dataset och OutputFileDatasetConfig objekt
Det bästa sättet att tillhandahålla data till en pipeline är ett datauppsättningsobjekt . Objektet Dataset pekar på data som finns i eller är tillgängliga från ett datalager eller på en webb-URL. Klassen Dataset är abstrakt, så du skapar en instans av antingen en FileDataset (refererar till en eller flera filer) eller en TabularDataset som skapas av från en eller flera filer med avgränsade datakolumner.
Du skapar en Dataset med metoder som from_files eller from_delimited_files.
from azureml.core import Dataset
my_dataset = Dataset.File.from_files([(def_blob_store, 'train-images/')])
Mellanliggande data (eller utdata från ett steg) representeras av ett OutputFileDatasetConfig-objekt . output_data1 genereras som utdata från ett steg. Du kan också registrera dessa data som en datauppsättning genom att anropa register_on_complete. Om du skapar ett OutputFileDatasetConfig i ett steg och använder det som indata till ett annat steg skapar databeroendet mellan stegen en implicit körningsordning i pipelinen.
OutputFileDatasetConfig objekt returnerar en katalog och skriver som standard utdata till arbetsytans standarddatalager.
from azureml.data import OutputFileDatasetConfig
output_data1 = OutputFileDatasetConfig(destination = (datastore, 'outputdataset/{run-id}'))
output_data_dataset = output_data1.register_on_complete(name = 'prepared_output_data')
Viktigt!
Mellanliggande data som lagras med tas OutputFileDatasetConfig inte bort automatiskt av Azure.
Du bör antingen programmatiskt ta bort mellanliggande data i slutet av en pipelinekörning, använda ett datalager med en kort princip för datakvarhållning eller regelbundet rensa manuellt.
Dricks
Ladda bara upp filer som är relevanta för det aktuella jobbet. Eventuella ändringar i filer i datakatalogen ses som anledning att köra om steget nästa gång pipelinen körs, även om du anger återanvändning.
Konfigurera ett beräkningsmål
I Azure Mašinsko učenje refererar termen beräkning (eller beräkningsmål) till de datorer eller kluster som utför beräkningsstegen i din maskininlärningspipeline. Se beräkningsmål för modellträning för en fullständig lista över beräkningsmål och Skapa beräkningsmål för hur du skapar och kopplar dem till din arbetsyta. Processen för att skapa och eller koppla ett beräkningsmål är densamma oavsett om du tränar en modell eller kör ett pipelinesteg. När du har skapat och bifogat beräkningsmålet använder du ComputeTarget objektet i pipelinesteget.
Viktigt!
Det går inte att utföra hanteringsåtgärder på beräkningsmål inifrån fjärrjobb. Eftersom ML-pipelines skickas som ett fjärrjobb ska du inte använda hanterings åtgärder på beräkningsmål inifrån pipelinen.
Azure Mašinsko učenje-beräkning
Du kan skapa en Azure-Mašinsko učenje beräkning för att köra dina steg. Koden för andra beräkningsmål är liknande, med lite olika parametrar, beroende på typ.
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "aml-compute"
vm_size = "STANDARD_NC6"
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print('Found compute target: ' + compute_name)
else:
print('Creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size=vm_size, # STANDARD_NC6 is GPU-enabled
min_nodes=0,
max_nodes=4)
# create the compute target
compute_target = ComputeTarget.create(
ws, compute_name, provisioning_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current cluster status, use the 'status' property
print(compute_target.status.serialize())
Konfigurera träningskörningens miljö
Nästa steg är att se till att fjärrträningskörningen har alla beroenden som krävs av träningsstegen. Beroenden och körningskontexten anges genom att skapa och konfigurera ett RunConfiguration objekt.
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import Environment
aml_run_config = RunConfiguration()
# `compute_target` as defined in "Azure Machine Learning compute" section above
aml_run_config.target = compute_target
USE_CURATED_ENV = True
if USE_CURATED_ENV :
curated_environment = Environment.get(workspace=ws, name="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu")
aml_run_config.environment = curated_environment
else:
aml_run_config.environment.python.user_managed_dependencies = False
# Add some packages relied on by data prep step
aml_run_config.environment.python.conda_dependencies = CondaDependencies.create(
conda_packages=['pandas','scikit-learn'],
pip_packages=['azureml-sdk', 'azureml-dataset-runtime[fuse,pandas]'],
pin_sdk_version=False)
Koden ovan visar två alternativ för hantering av beroenden. Som vi ser USE_CURATED_ENV = Truebaseras konfigurationen på en kuraterad miljö. Kuraterade miljöer "förbakas" med vanliga interberoende bibliotek och kan vara snabbare att ta online. Utvalda miljöer har fördefinierade Docker-avbildningar i Microsoft Container Registry. Mer information finns i Azure Mašinsko učenje kuraterade miljöer.
Sökvägen om du ändrar USE_CURATED_ENV till False visar mönstret för att uttryckligen ange dina beroenden. I det scenariot skapas och registreras en ny anpassad Docker-avbildning i ett Azure Container Registry i resursgruppen (se Introduktion till privata Docker-containerregister i Azure). Det kan ta ganska många minuter att skapa och registrera den här avbildningen.
Skapa pipelinestegen
När du har skapat beräkningsresursen och miljön är du redo att definiera pipelinens steg. Det finns många inbyggda steg som är tillgängliga via Azure Mašinsko učenje SDK, som du kan se i referensdokumentationen azureml.pipeline.steps för paketet. Den mest flexibla klassen är PythonScriptStep, som kör ett Python-skript.
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Koden ovan visar ett typiskt inledande pipelinesteg. Koden för förberedelse av data finns i en underkatalog (i det här exemplet "prepare.py" i katalogen "./dataprep.src"). Som en del av pipelineskapandeprocessen zippaderas och laddas den här katalogen upp till compute_target och steget kör skriptet som anges som värde för script_name.
Värdena arguments anger indata och utdata för steget. I exemplet ovan är baslinjedata datauppsättningen my_dataset . Motsvarande data laddas ned till beräkningsresursen eftersom koden anger den som as_download(). Skriptet prepare.py gör de datatransformeringsuppgifter som är lämpliga för den aktuella aktiviteten och matar ut data till output_data1, av typen OutputFileDatasetConfig. Mer information finns i Flytta data till och mellan ML-pipelinesteg (Python).
Steget körs på den dator som definieras av , med hjälp av compute_targetkonfigurationen aml_run_config.
Återanvändning av tidigare resultat (allow_reuse) är nyckeln när du använder pipelines i en samarbetsmiljö eftersom det är smidigt att eliminera onödiga omkörningar. Återanvändning är standardbeteendet när script_name, indata och parametrarna för ett steg förblir desamma. När återanvändning tillåts skickas resultat från föregående körning omedelbart till nästa steg. Om allow_reuse är inställt på Falsegenereras alltid en ny körning för det här steget under pipelinekörningen.
Det går att skapa en pipeline med ett enda steg, men nästan alltid väljer du att dela upp den övergripande processen i flera steg. Du kan till exempel ha steg för förberedelse av data, träning, modelljämförelse och distribution. Man kan till exempel tänka sig att nästa steg kan vara träning efter ovanstående data_prep_step :
train_source_dir = "./train_src"
train_entry_point = "train.py"
training_results = OutputFileDatasetConfig(name = "training_results",
destination = def_blob_store)
train_step = PythonScriptStep(
script_name=train_entry_point,
source_directory=train_source_dir,
arguments=["--prepped_data", output_data1.as_input(), "--training_results", training_results],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Koden ovan liknar koden i steget för förberedelse av data. Träningskoden finns i en katalog som är separat från koden för förberedelse av data. Utdata OutputFileDatasetConfig från steget för output_data1 förberedelse av data används som indata till träningssteget. Ett nytt OutputFileDatasetConfig objekt training_results skapas för att lagra resultatet för en senare jämförelse eller distributionssteg.
För andra kodexempel, se hur du skapar en tvåstegs ML-pipeline och hur du skriver tillbaka data till datalager när körningen är klar.
När du har definierat dina steg skapar du pipelinen med hjälp av några eller alla dessa steg.
Kommentar
Ingen fil eller data laddas upp till Azure Mašinsko učenje när du definierar stegen eller skapar pipelinen. Filerna laddas upp när du anropar Experiment.submit().
# list of steps to run (`compare_step` definition not shown)
compare_models = [data_prep_step, train_step, compare_step]
from azureml.pipeline.core import Pipeline
# Build the pipeline
pipeline1 = Pipeline(workspace=ws, steps=[compare_models])
Använda en datauppsättning
Datauppsättningar som skapats från Azure Blob Storage, Azure Files, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure SQL Database och Azure Database for PostgreSQL kan användas som indata till alla pipelinesteg. Du kan skriva utdata till en DataTransferStep, DatabricksStep eller om du vill skriva data till ett visst datalager använder du OutputFileDatasetConfig.
Viktigt!
Du kan bara skriva utdata tillbaka till ett datalager med OutputFileDatasetConfig med Azure Blob, Azure File-resurser, ADLS Gen 1- och Gen 2-datalager.
dataset_consuming_step = PythonScriptStep(
script_name="iris_train.py",
inputs=[iris_tabular_dataset.as_named_input("iris_data")],
compute_target=compute_target,
source_directory=project_folder
)
Sedan hämtar du datamängden i pipelinen med hjälp av ordlistan Run.input_datasets .
# iris_train.py
from azureml.core import Run, Dataset
run_context = Run.get_context()
iris_dataset = run_context.input_datasets['iris_data']
dataframe = iris_dataset.to_pandas_dataframe()
Run.get_context() Linjen är värd att markera. Den här funktionen hämtar en Run som representerar den aktuella experimentella körningen. I exemplet ovan använder vi det för att hämta en registrerad datauppsättning. En annan vanlig användning av Run objektet är att hämta både själva experimentet och arbetsytan där experimentet finns:
# Within a PythonScriptStep
ws = Run.get_context().experiment.workspace
Mer information, inklusive alternativa sätt att skicka och komma åt data finns i Flytta data till och mellan ML-pipelinesteg (Python).
Cachelagring och återanvändning
Om du vill optimera och anpassa beteendet för dina pipelines kan du göra några saker kring cachelagring och återanvändning. Du kan till exempel välja att:
- Inaktivera standardåteranvändningen av stegkörningens utdata genom att ange
allow_reuse=Falseunder stegdefinitionen. Återanvändning är nyckeln när du använder pipelines i en samarbetsmiljö eftersom det är smidigt att eliminera onödiga körningar. Du kan dock avanmäla dig från återanvändning. - Framtvinga regenerering av utdata för alla steg i en körning med
pipeline_run = exp.submit(pipeline, regenerate_outputs=True)
Som standard allow_reuse är steg aktiverade och den source_directory som anges i stegdefinitionen hashas. Så om skriptet för ett visst steg förblir detsamma (script_name, indata och parametrarna), och inget annat i source_directory har ändrats, återanvänds utdata från en tidigare stegkörning, jobbet skickas inte till beräkningen och resultaten från föregående körning är omedelbart tillgängliga för nästa steg i stället.
step = PythonScriptStep(name="Hello World",
script_name="hello_world.py",
compute_target=aml_compute,
source_directory=source_directory,
allow_reuse=False,
hash_paths=['hello_world.ipynb'])
Kommentar
Om namnen på dataindata ändras körs steget igen, även om underliggande data inte ändras. Du måste uttryckligen ange fältet name för indata (data.as_input(name=...)). Om du inte uttryckligen anger det här värdet name anges fältet till ett slumpmässigt guid och stegets resultat återanvänds inte.
Skicka pipelinen
När du skickar pipelinen kontrollerar Azure Mašinsko učenje beroendena för varje steg och laddar upp en ögonblicksbild av den angivna källkatalogen. Om ingen källkatalog har angetts laddas den aktuella lokala katalogen upp. Ögonblicksbilden lagras också som en del av experimentet på din arbetsyta.
Viktigt!
Om du vill förhindra att onödiga filer tas med i ögonblicksbilden skapar du en ignorerande fil (.gitignore eller .amlignore) i katalogen. Lägg till de filer och kataloger som ska undantas i den här filen. Mer information om syntaxen som ska användas i den här filen finns i syntax och mönster för .gitignore. Filen .amlignore använder samma syntax. Om båda filerna finns .amlignore används filen och .gitignore filen används inte.
Mer information finns i Ögonblicksbilder.
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run1 = Experiment(ws, 'Compare_Models_Exp').submit(pipeline1)
pipeline_run1.wait_for_completion()
När du först kör en pipeline Mašinsko učenje Azure:
Laddar ned projektögonblicksbilden till beräkningsmålet från bloblagringen som är associerad med arbetsytan.
Skapar en Docker-avbildning som motsvarar varje steg i pipelinen.
Laddar ned Docker-avbildningen för varje steg till beräkningsmålet från containerregistret.
Konfigurerar åtkomst till
DatasetochOutputFileDatasetConfigobjekt. Föras_mount()åtkomstläge används FUSE för att ge virtuell åtkomst. Om monteringen inte stöds eller om användaren har angett åtkomst somas_upload()kopieras data i stället till beräkningsmålet.Kör steget i beräkningsmålet som anges i stegdefinitionen.
Skapar artefakter, till exempel loggar, stdout och stderr, mått och utdata som anges i steget. Dessa artefakter laddas sedan upp och sparas i användarens standarddatalager.

Mer information finns i referensen för experimentklassen .
Använda pipelineparametrar för argument som ändras vid slutsatsdragningstid
Ibland relaterar argumenten till enskilda steg i en pipeline till utveckling och träningsperiod: saker som träningsfrekvens och momentum, eller sökvägar till data eller konfigurationsfiler. När en modell distribueras vill du dock dynamiskt skicka de argument som du härleder (det vill: den fråga som du skapade modellen för att besvara!). Du bör göra dessa typer av argument pipelineparametrar. Om du vill göra detta i Python använder du azureml.pipeline.core.PipelineParameter klassen enligt följande kodfragment:
from azureml.pipeline.core import PipelineParameter
pipeline_param = PipelineParameter(name="pipeline_arg", default_value="default_val")
train_step = PythonScriptStep(script_name="train.py",
arguments=["--param1", pipeline_param],
target=compute_target,
source_directory=project_folder)
Så här fungerar Python-miljöer med pipelineparametrar
Som vi beskrev tidigare i Konfigurera träningskörningens miljö, miljötillstånd och Python-biblioteksberoenden anges med hjälp av ett Environment -objekt. I allmänhet kan du ange en befintlig Environment genom att referera till dess namn och, om du vill, en version:
aml_run_config = RunConfiguration()
aml_run_config.environment.name = 'MyEnvironment'
aml_run_config.environment.version = '1.0'
Men om du väljer att använda PipelineParameter objekt för att dynamiskt ange variabler vid körning för pipelinestegen kan du inte använda den här tekniken för att referera till en befintlig Environment. Om du i stället vill använda PipelineParameter objekt måste du ange environment fältet för RunConfiguration objektet till ett Environment objekt. Det är ditt ansvar att se till att en Environment sådan har sina beroenden på externa Python-paket korrekt inställda.
Visa resultat av en pipeline
Se listan över alla dina pipelines och deras körningsinformation i studion:
Logga in på Azure Mašinsko učenje Studio.
Till vänster väljer du Pipelines för att se alla pipelinekörningar.
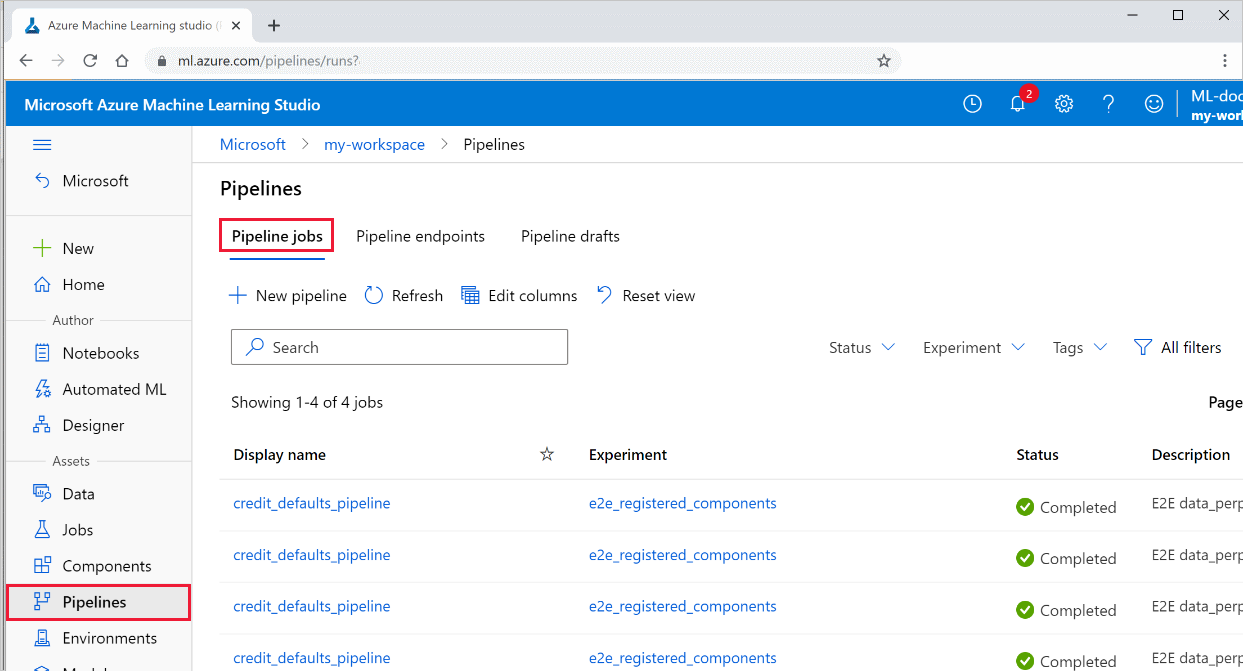
Välj en specifik pipeline för att se körningsresultatet.
Git-spårning och integrering
När du startar en träningskörning där källkatalogen är en lokal Git-lagringsplats lagras information om lagringsplatsen i körningshistoriken. Mer information finns i Git-integrering för Azure Mašinsko učenje.
Nästa steg
- Information om hur du delar din pipeline med kollegor eller kunder finns i Publicera maskininlärningspipelines
- Använd de här Jupyter-notebook-filerna på GitHub för att utforska maskininlärningspipelines ytterligare
- Se SDK-referenshjälpen för paketet azureml-pipelines-core och paketet azureml-pipelines-steps
- Se anvisningar för tips om felsökning och felsökning av pipelines=
- Lär dig att köra notebook-filer genom att följa artikeln Använda Jupyter-notebooks till att utforska tjänsten.