Dataomvandling med Apache Spark-pooler (inaktuell)
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
Varning
Azure Synapse Analytics-integreringen med Azure Mašinsko učenje, som är tillgänglig i Python SDK v1, är inaktuell. Användare kan fortfarande använda Synapse-arbetsytan, registrerad med Azure Mašinsko učenje, som en länkad tjänst. Men en ny Synapse-arbetsyta kan inte längre registreras med Azure Machine Learning som en länkad tjänst. Vi rekommenderar att du använder serverlös Spark-beräkning och anslutna Synapse Spark-pooler, som är tillgängliga i CLI v2 och Python SDK v2. Mer information finns på https://aka.ms/aml-spark.
I den här artikeln får du lära dig hur du interaktivt utför dataomvandlingsuppgifter i en dedikerad Synapse-session som drivs av Azure Synapse Analytics i en Jupyter-anteckningsbok. Dessa uppgifter förlitar sig på Azure Mašinsko učenje Python SDK. Mer information om Azure Mašinsko učenje pipelines finns i Använda Apache Spark (drivs av Azure Synapse Analytics) i din maskininlärningspipeline (förhandsversion). Mer information om hur du använder Azure Synapse Analytics med en Synapse-arbetsyta finns i kom igång-serien för Azure Synapse Analytics.
Azure Mašinsko učenje- och Azure Synapse Analytics-integrering
Med Azure Synapse Analytics-integreringen med Azure Mašinsko učenje (förhandsversion) kan du bifoga en Apache Spark-pool som backas upp av Azure Synapse för interaktiv datautforskning och förberedelse. Med den här integreringen kan du ha en dedikerad beräkningsresurs för dataomvandling i stor skala, allt i samma Python-notebook-fil som du använder för att träna dina maskininlärningsmodeller.
Förutsättningar
Konfigurera utvecklingsmiljön för att installera Azure Mašinsko učenje SDK eller använd en Azure Mašinsko učenje-beräkningsinstans med SDK:t redan installerat
Skapa en Apache Spark-pool med Hjälp av Azure-portalen, webbverktyg eller Synapse Studio
azureml-synapseInstallera paketet (förhandsversion) med den här koden:pip install azureml-synapseLänka din Azure Mašinsko učenje-arbetsyta och Azure Synapse Analytics-arbetsyta med Azure Mašinsko učenje Python SDK eller med Azure Mašinsko učenje Studio
Bifoga en Synapse Spark-pool som beräkningsmål
Starta Synapse Spark-poolen för dataomvandlingsuppgifter
Om du vill starta dataförberedelsen med Apache Spark-poolen anger du det anslutna Spark Synapse-beräkningsnamnet. Du hittar det här namnet med Azure Mašinsko učenje Studio under fliken Anslutna beräkningar.
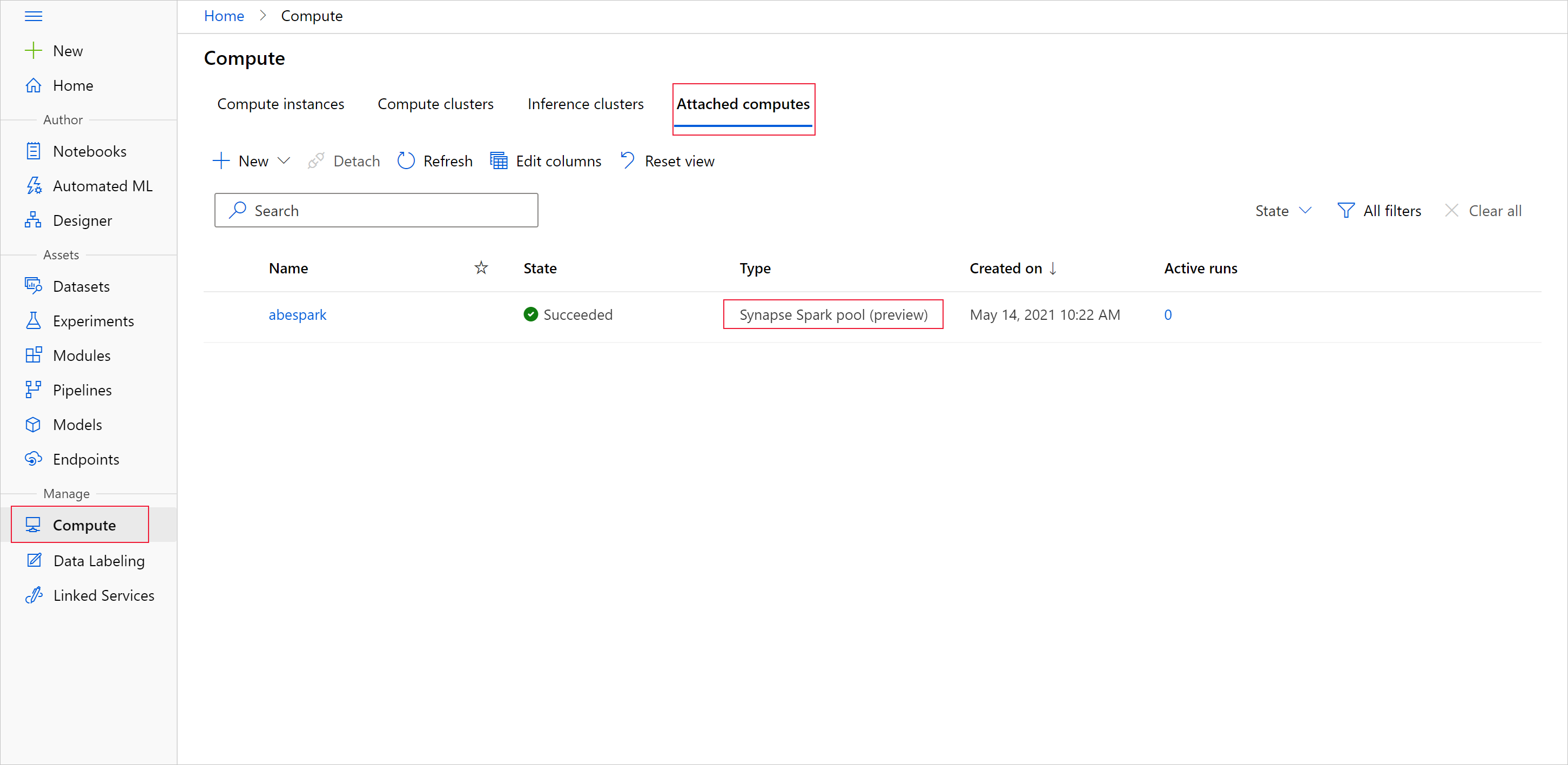
Viktigt!
Om du vill fortsätta använda Apache Spark-poolen måste du ange vilken beräkningsresurs som ska användas i dina dataomvandlingsuppgifter. Används %synapse för enstaka kodrader och %%synapse för flera rader:
%synapse start -c SynapseSparkPoolAlias
När sessionen har startat kan du kontrollera sessionens metadata:
%synapse meta
Du kan ange en Azure-Mašinsko učenje miljö som ska användas under Apache Spark-sessionen. Endast Conda-beroenden som anges i miljön börjar gälla. Docker-avbildningar stöds inte.
Varning
Python-beroenden som anges i miljön Conda-beroenden stöds inte i Apache Spark-pooler. För närvarande stöds endast fasta Python-versioner Inkludera sys.version_info i skriptet för att kontrollera din Python-version
Den här koden skaparmyenv miljövariabeln för att installera azureml-core version 1.20.0 och numpy version 1.17.0 innan sessionen startas. Du kan sedan inkludera den här miljön i apache Spark-sessionssatsen start .
from azureml.core import Workspace, Environment
# creates environment with numpy and azureml-core dependencies
ws = Workspace.from_config()
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core==1.20.0")
env.python.conda_dependencies.add_conda_package("numpy==1.17.0")
env.register(workspace=ws)
Om du vill starta dataförberedelser med Apache Spark-poolen i din anpassade miljö anger du både namnet på Apache Spark-poolen och miljön som ska användas under Apache Spark-sessionen. Du kan ange ditt prenumerations-ID, resursgruppen för maskininlärningsarbetsytan och namnet på arbetsytan för maskininlärning.
%synapse start -c SynapseSparkPoolAlias -e myenv -s AzureMLworkspaceSubscriptionID -r AzureMLworkspaceResourceGroupName -w AzureMLworkspaceName
Läsa in data från lagring
När Apache Spark-sessionen har startat läser du in de data som du vill förbereda. Datainläsning stöds för Azure Blob Storage och Azure Data Lake Storage Generation 1 och 2.
Du har två alternativ för att läsa in data från dessa lagringstjänster:
Läs in data direkt från lagring med dess sökväg för Hadoop Distributed Files System (HDFS)
Läsa in data från en befintlig Azure Mašinsko učenje-datauppsättning
För att få åtkomst till dessa lagringstjänster behöver du behörigheter för Storage Blob Data Reader . Om du vill skriva tillbaka data till dessa lagringstjänster behöver du behörigheter för Storage Blob Data Contributor . Läs mer om lagringsbehörigheter och roller.
Läsa in data med sökvägen Hadoop Distributed Files System (HDFS)
Om du vill läsa in och läsa data från lagring med motsvarande HDFS-sökväg behöver du dina autentiseringsuppgifter för dataåtkomst tillgängliga. Dessa autentiseringsuppgifter varierar beroende på din lagringstyp. Det här kodexemplet visar hur du läser data från en Azure Blob Storage till en Spark-dataram med antingen din SAS-token (signatur för delad åtkomst) eller åtkomstnyckel:
%%synapse
# setup access key or SAS token
sc._jsc.hadoopConfiguration().set("fs.azure.account.key.<storage account name>.blob.core.windows.net", "<access key>")
sc._jsc.hadoopConfiguration().set("fs.azure.sas.<container name>.<storage account name>.blob.core.windows.net", "<sas token>")
# read from blob
df = spark.read.option("header", "true").csv("wasbs://demo@dprepdata.blob.core.windows.net/Titanic.csv")
Det här kodexemplet visar hur du läser data från Azure Data Lake Storage Generation 1 (ADLS Gen 1) med autentiseringsuppgifterna för tjänstens huvudnamn:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.access.token.provider.type","ClientCredential")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.client.id", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.credential", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.refresh.url",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("adl://<storage account name>.azuredatalakestore.net/<path>")
Det här kodexemplet visar hur du läser in data från Azure Data Lake Storage Generation 2 (ADLS Gen 2) med autentiseringsuppgifterna för tjänstens huvudnamn:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<storage account name>.dfs.core.windows.net","OAuth")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<storage account name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<storage account name>.dfs.core.windows.net", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<storage account name>.dfs.core.windows.net", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<storage account name>.dfs.core.windows.net",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("abfss://<container name>@<storage account>.dfs.core.windows.net/<path>")
Läsa in data från registrerade datamängder
Du kan också placera en befintlig registrerad datamängd på din arbetsyta och utföra dataförberedelser på den om du konverterar den till en spark-dataram. Det här exemplet autentiserar till arbetsytan, hämtar en registrerad TabularDataset –blob_dset – som refererar till filer i bloblagring och konverterar den TabularDataset till en Spark-dataram. När du konverterar dina datauppsättningar till Spark-dataramar kan du använda pyspark bibliotek för datautforskning och förberedelse.
%%synapse
from azureml.core import Workspace, Dataset
subscription_id = "<enter your subscription ID>"
resource_group = "<enter your resource group>"
workspace_name = "<enter your workspace name>"
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
dset = Dataset.get_by_name(ws, "blob_dset")
spark_df = dset.to_spark_dataframe()
Utföra dataomvandlingsuppgifter
När du har hämtat och utforskat dina data kan du utföra dataomvandlingsuppgifter. Det här kodexemplet expanderar HDFS-exemplet i föregående avsnitt. Baserat på kolumnen Survivor filtrerar den data i spark-dataramen df och grupper som listas efter Ålder:
%%synapse
from pyspark.sql.functions import col, desc
df.filter(col('Survived') == 1).groupBy('Age').count().orderBy(desc('count')).show(10)
df.show()
Spara data till lagring och stoppa Spark-sessionen
När datautforskningen och förberedelsen är klar lagrar du dina förberedda data för senare användning i ditt lagringskonto i Azure. I det här kodexemplet skrivs förberedda data tillbaka till Azure Blob Storage och skriver över den ursprungliga Titanic.csv filen i training_data katalogen. Om du vill skriva tillbaka till lagringen behöver du behörigheter för Storage Blob Data-deltagare . Mer information finns i Tilldela en Azure-roll för åtkomst till blobdata.
%% synapse
df.write.format("csv").mode("overwrite").save("wasbs://demo@dprepdata.blob.core.windows.net/training_data/Titanic.csv")
När du har slutfört dataförberedelsen och sparat dina förberedda data till lagring avslutar du användningen av Apache Spark-poolen med det här kommandot:
%synapse stop
Skapa en datauppsättning för att representera förberedda data
När du är redo att använda dina förberedda data för modellträning ansluter du till lagringen med ett Azure-Mašinsko učenje datalager och anger den fil eller fil som du vill använda med en Azure-Mašinsko učenje datauppsättning.
Det här kodexemplet
- Förutsätter att du redan har skapat ett datalager som ansluter till lagringstjänsten där du sparade dina förberedda data
- Hämtar det befintliga dataarkivet –
mydatastore– från arbetsytanwsmed metoden get(). - Skapar en FileDataset,
train_ds, för att referera till de förberedda datafilernamydatastoretraining_datasom finns i katalogen - Skapar variabeln
input1. Vid ett senare tillfälle kan den här variabeln göra datafilerna för datamängdentrain_dstillgängliga för ett beräkningsmål för dina träningsaktiviteter.
from azureml.core import Datastore, Dataset
datastore = Datastore.get(ws, datastore_name='mydatastore')
datastore_paths = [(datastore, '/training_data/')]
train_ds = Dataset.File.from_files(path=datastore_paths, validate=True)
input1 = train_ds.as_mount()
Använda en ScriptRunConfig för att skicka en experimentkörning till en Synapse Spark-pool
Om du är redo att automatisera och produktionsanpassa dina dataomvandlingsuppgifter kan du skicka en experimentkörning till en bifogad Synapse Spark-pool med ScriptRunConfig-objektet . Om du har en Azure Mašinsko učenje pipeline på liknande sätt kan du använda SynapseSparkStep för att ange din Synapse Spark-pool som beräkningsmål för steget för förberedelse av data i pipelinen. Tillgängligheten för dina data till Synapse Spark-poolen beror på din datamängdstyp.
- För en FileDataset kan du använda
as_hdfs()-metoden. När körningen skickas görs datauppsättningen tillgänglig för Synapse Spark-poolen som ett Hadoop-distribuerat filsystem (HFDS) - För en TabularDataset kan du använda
as_named_input()metoden
Följande kodexempel
- Skapar variabeln
input2från FileDatasettrain_ds, som skapades i föregående kodexempel - Skapar variabel
outputmedHDFSOutputDatasetConfigurationklassen . När körningen är klar kan vi med den här klassen spara utdata från körningen som datauppsättningtesti datalagringenmydatastore. I Azure Mašinsko učenje-arbetsytan registreras datauppsättningentestunder namnetregistered_dataset - Konfigurerar inställningar som körningen ska använda för att utföra på Synapse Spark-poolen
- Definierar ScriptRunConfig-parametrarna till
- Använda skriptet
dataprep.pyför körningen - Ange vilka data som ska användas som indata och hur du gör dessa data tillgängliga för Synapse Spark-poolen
- Ange var utdata ska
outputlagras
- Använda skriptet
from azureml.core import Dataset, HDFSOutputDatasetConfig
from azureml.core.environment import CondaDependencies
from azureml.core import RunConfiguration
from azureml.core import ScriptRunConfig
from azureml.core import Experiment
input2 = train_ds.as_hdfs()
output = HDFSOutputDatasetConfig(destination=(datastore, "test").register_on_complete(name="registered_dataset")
run_config = RunConfiguration(framework="pyspark")
run_config.target = synapse_compute_name
run_config.spark.configuration["spark.driver.memory"] = "1g"
run_config.spark.configuration["spark.driver.cores"] = 2
run_config.spark.configuration["spark.executor.memory"] = "1g"
run_config.spark.configuration["spark.executor.cores"] = 1
run_config.spark.configuration["spark.executor.instances"] = 1
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-core==1.20.0")
run_config.environment.python.conda_dependencies = conda_dep
script_run_config = ScriptRunConfig(source_directory = './code',
script= 'dataprep.py',
arguments = ["--file_input", input2,
"--output_dir", output],
run_config = run_config)
Mer information om run_config.spark.configuration och allmän Spark-konfiguration finns i SparkConfiguration Class och Apache Sparks konfigurationsdokumentation.
När du har konfigurerat objektet ScriptRunConfig kan du skicka körningen.
from azureml.core import Experiment
exp = Experiment(workspace=ws, name="synapse-spark")
run = exp.submit(config=script_run_config)
run
Mer information, inklusive information om skriptet dataprep.py som används i det här exemplet, finns i exempelanteckningsboken.
När du har förberett dina data kan du använda dem som indata för dina träningsjobb. I kodexemplet ovan anger registered_dataset du som indata för träningsjobb.
Exempelnotebook-filer
I de här exempelanteckningsböckerna finns fler begrepp och demonstrationer av Azure Synapse Analytics och Azure Mašinsko učenje integreringsfunktioner:
- Kör en interaktiv Spark-session från en notebook-fil på din Azure Mašinsko učenje-arbetsyta.
- Skicka en Azure Mašinsko učenje-experimentkörning med en Synapse Spark-pool som beräkningsmål.