Konfigurera automatisk ML-träning utan kod för tabelldata med studiogränssnittet
I den här artikeln konfigurerar du automatiserade maskininlärningsträningsjobb med hjälp av Azure Machine Learning Automated ML i Azure Machine Learning-studio. Med den här metoden kan du konfigurera jobbet utan att skriva en enda kodrad. Automatiserad ML är en process där Azure Machine Learning väljer den bästa maskininlärningsalgoritmen för dina specifika data. Med processen kan du snabbt generera maskininlärningsmodeller. Mer information finns i Översikt över den automatiserade ML-processen.
Den här självstudien ger en översikt på hög nivå för att arbeta med automatiserad ML i studion. Följande artiklar innehåller detaljerade instruktioner för att arbeta med specifika maskininlärningsmodeller:
- Klassificering: Självstudie: Träna en klassificeringsmodell med automatiserad ML i studion
- Prognostisering av tidsserier: Självstudie: Prognostisera efterfrågan med automatiserad ML i studion
- Bearbetning av naturligt språk (NLP): Konfigurera automatiserad ML för att träna en NLP-modell (Azure CLI eller Python SDK)
- Visuellt innehåll: Konfigurera AutoML för att träna modeller för visuellt innehåll (Azure CLI eller Python SDK)
- Regression: Träna en regressionsmodell med automatiserad ML (Python SDK)
Förutsättningar
En Azure-prenumeration. Du kan skapa ett kostnadsfritt eller betalt konto för Azure Machine Learning.
En Azure Machine Learning-arbetsyta eller beräkningsinstans. Information om hur du förbereder dessa resurser finns i Snabbstart: Kom igång med Azure Machine Learning.
Den datatillgång som ska användas för det automatiserade ML-träningsjobbet. I den här självstudien beskrivs hur du väljer en befintlig datatillgång eller skapar en datatillgång från en datakälla, till exempel en lokal fil, en webb-URL eller ett datalager. Mer information finns i Skapa och hantera datatillgångar.
Viktigt!
Det finns två krav för träningsdata:
- Data måste vara i tabellform.
- Värdet som ska förutsägas (målkolumnen) måste finnas i data.
Skapa experiment
Skapa och kör ett experiment genom att följa dessa steg:
Logga in på Azure Machine Learning-studio och välj din prenumeration och arbetsyta.
På den vänstra menyn väljer du Automatiserad ML under avsnittet Redigering :
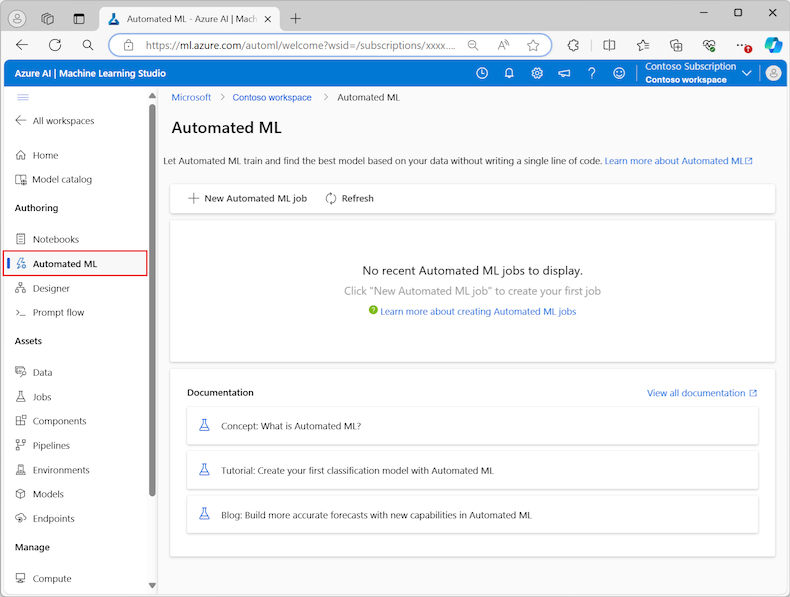
Första gången du arbetar med experiment i studion visas en tom lista och länkar till dokumentationen. Annars visas en lista över dina senaste automatiserade ML-experiment, inklusive objekt som skapats med Azure Machine Learning SDK.
Välj Nytt automatiserat ML-jobb för att starta processen Skicka ett automatiserat ML-jobb .
Som standard väljer processen alternativet Träna automatiskt på fliken Träningsmetod och fortsätter till konfigurationsinställningarna.
På fliken Grundläggande inställningar anger du värden för de inställningar som krävs, inklusive jobbnamnet och experimentnamnet. Du kan också ange värden för de valfria inställningarna efter behov.
Klicka på Nästa när du vill fortsätta.

Identifiera datatillgång
På fliken Aktivitetstyp och data anger du datatillgången för experimentet och maskininlärningsmodellen som ska användas för att träna data.
I den här självstudien kan du använda en befintlig datatillgång eller skapa en ny datatillgång från en fil på den lokala datorn. Studiogränssnittssidorna ändras baserat på ditt val för datakällan och typen av träningsmodell.
Om du väljer att använda en befintlig datatillgång kan du fortsätta till avsnittet Konfigurera träningsmodell .
Följ dessa steg för att skapa en ny datatillgång:
Om du vill skapa en ny datatillgång från en fil på den lokala datorn väljer du Skapa.
På sidan Datatyp :
- Ange ett datatillgångsnamn .
- Som Typ väljer du Tabell i listrutan.
- Välj Nästa.
På sidan Datakälla väljer du Från lokala filer.
Machine Learning Studio lägger till extra alternativ på den vänstra menyn så att du kan konfigurera datakällan.
Välj Nästa för att fortsätta till sidan Mållagringstyp , där du anger platsen för Azure Storage för att ladda upp datatillgången.
Du kan ange den standardlagringscontainer som skapas automatiskt med din arbetsyta eller välja en lagringscontainer som ska användas för experimentet.
- Som Datastore-typ väljer du Azure Blob Storage.
- I listan över datalager väljer du workspaceblobstore.
- Välj Nästa.
På sidan Fil- och mappval använder du listrutan Ladda upp filer eller mappar och väljer alternativet Ladda upp filer eller Ladda upp mapp .
- Bläddra till platsen för de data som ska laddas upp och välj Öppna.
- När filerna har laddats upp väljer du Nästa.
Machine Learning Studio validerar och laddar upp dina data.
Kommentar
Om dina data finns bakom ett virtuellt nätverk måste du aktivera funktionen Hoppa över verifieringen för att säkerställa att arbetsytan kan komma åt dina data. Mer information finns i Använda Azure Machine Learning-studio i ett virtuellt Azure-nätverk.
Kontrollera att dina uppladdade data är korrekta på sidan Inställningar . Fälten på sidan fylls i i förväg baserat på filtypen för dina data:
Fält beskrivning Filformat Definierar layouten och typen av data som lagras i en fil. Avgränsare Identifierar ett eller flera tecken för att ange gränsen mellan separata, oberoende regioner i oformaterad text eller andra dataströmmar. Kodning Identifierar vilken bit till teckenschematabell som ska användas för att läsa datauppsättningen. Kolumnrubriker Anger hur sidhuvudena i datauppsättningen, om några, behandlas. Hoppa över rader Anger hur många, om några, rader som hoppas över i datauppsättningen. Välj Nästa för att fortsätta till sidan Schema . Den här sidan är också ifyllt baserat på dina inställningar . Du kan konfigurera datatypen för varje kolumn, granska kolumnnamnen och hantera kolumner:
- Om du vill ändra datatypen för en kolumn använder du listrutan Typ för att välja ett alternativ.
- Om du vill exkludera en kolumn från datatillgången växlar du alternativet Inkludera för kolumnen.
Välj Nästa för att fortsätta till sidan Granska . Granska sammanfattningen av dina konfigurationsinställningar för jobbet och välj sedan Skapa.
Konfigurera träningsmodell
När datatillgången är klar återgår Machine Learning Studio till fliken Aktivitetstyp och data för processen Skicka ett automatiserat ML-jobb . Den nya datatillgången visas på sidan.
Följ de här stegen för att slutföra jobbkonfigurationen:
Expandera listrutan Välj aktivitetstyp och välj den träningsmodell som ska användas för experimentet. Alternativen omfattar klassificering, regression, prognostisering av tidsserier, bearbetning av naturligt språk (NLP) eller visuellt innehåll. Mer information om dessa alternativ finns i beskrivningarna av de aktivitetstyper som stöds.
När du har angett träningsmodellen väljer du din datauppsättning i listan.
Välj Nästa för att fortsätta till fliken Aktivitetsinställningar .
I listrutan Målkolumn väljer du den kolumn som ska användas för modellförutsägelserna.
Beroende på din träningsmodell konfigurerar du följande obligatoriska inställningar:
Klassificering: Välj om du vill aktivera djupinlärning.
Prognostisering av tidsserier: Välj om du vill aktivera djupinlärning och bekräfta dina inställningar för de inställningar som krävs:
Använd kolumnen Tid för att ange tidsdata som ska användas i modellen.
Välj om du vill aktivera ett eller flera alternativ för automatisk korrigering . När du avmarkerar alternativet Identifiera automatiskt , till exempel Prognoshorisont för automatiskdetektering, kan du ange ett specifikt värde. Värdet prognoshorisont anger hur många tidsenheter (minuter/timmar/dagar/veckor/månader/år) som modellen kan förutsäga för framtiden. Desto längre in i framtiden krävs modellen för att förutsäga, desto mindre exakt blir modellen.
Mer information om hur du konfigurerar de här inställningarna finns i Använda automatiserad ML för att träna en prognosmodell för tidsserier.
Bearbetning av naturligt språk: Bekräfta dina inställningar för de inställningar som krävs:
Använd alternativet Välj undertyp för att konfigurera underklassificeringstypen för NLP-modellen. Du kan välja mellan Klassificering av flera klasser, Klassificering av flera etiketter och Namngiven entitetsigenkänning (NER).
I avsnittet Svepinställningar anger du värden för Slack-faktorn och samplingsalgoritmen.
I avsnittet Sökutrymme konfigurerar du uppsättningen med modellalgoritmalternativ .
Mer information om hur du konfigurerar de här inställningarna finns i Konfigurera automatiserad ML för att träna en NLP-modell (Azure CLI eller Python SDK).
Visuellt innehåll: Välj om du vill aktivera manuell svepning och bekräfta dina inställningar för de inställningar som krävs:
- Använd alternativet Välj undertyp för att konfigurera underklassificeringstypen för modellen för visuellt innehåll. Du kan välja mellan Bildklassificering (Multi-class) eller (Multi-label), Objektidentifiering och Polygon (instanssegmentering).
Mer information om hur du konfigurerar de här inställningarna finns i Konfigurera AutoML för att träna modeller för visuellt innehåll (Azure CLI eller Python SDK).
Ange valfria inställningar
Machine Learning Studio innehåller valfria inställningar som du kan konfigurera baserat på valet av maskininlärningsmodell. I följande avsnitt beskrivs de extra inställningarna.
Konfigurera ytterligare inställningar
Du kan välja alternativet Visa ytterligare konfigurationsinställningar för att se åtgärder som ska utföras på data inför träningen.
På sidan Ytterligare konfiguration visas standardvärden baserat på val av experiment och data. Du kan använda standardvärdena eller konfigurera följande inställningar:
| Inställning | beskrivning |
|---|---|
| Primärt mått | Identifiera huvudmåttet för bedömning av din modell. Mer information finns i modellmått. |
| Aktivera ensemblestapling | Tillåt ensembleinlärning och förbättra maskininlärningsresultat och förutsägande prestanda genom att kombinera flera modeller i stället för att använda enkla modeller. Mer information finns i ensemblemodeller. |
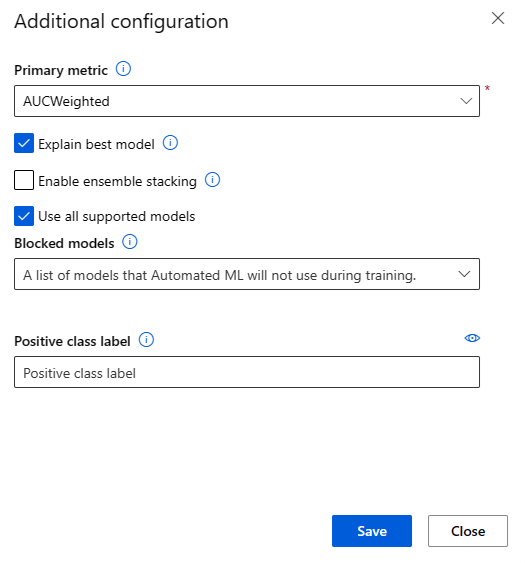
| Använda alla modeller som stöds | Använd det här alternativet för att instruera automatiserad ML om du vill använda alla modeller som stöds i experimentet. Mer information finns i de algoritmer som stöds för varje aktivitetstyp. – Välj det här alternativet för att konfigurera inställningen Blockerade modeller . – Avmarkera det här alternativet för att konfigurera inställningen Tillåtna modeller . |
| Blockerade modeller | (Tillgängligt när Använd alla modeller som stöds är markerat) Använd listrutan och välj de modeller som ska undantas från träningsjobbet. |
| Tillåtna modeller | (Tillgängligt när Använd alla modeller som stöds är inte markerat) Använd listrutan och välj de modeller som ska användas för träningsjobbet. Viktigt: Endast tillgängligt för SDK-experiment. |
| Förklara bästa modell | Välj det här alternativet för att automatiskt visa förklarande för den bästa modellen som skapats av automatiserad ML. |
| Positiv klassetikett | Ange etiketten för automatiserad ML som ska användas för att beräkna binära mått. |
Konfigurera inställningar för funktionalisering
Du kan välja alternativet Visa funktionaliseringsinställningar för att se åtgärder som ska utföras på data inför träningen.
På sidan Featurization visas standardtekniker för funktionalisering för dina datakolumner. Du kan aktivera/inaktivera automatisk funktionalisering och anpassa inställningarna för automatisk funktionalisering för experimentet.

Välj alternativet Aktivera funktionalisering för att tillåta konfiguration.
Viktigt!
När dina data innehåller icke-numeriska kolumner aktiveras alltid funktionalisering.
Konfigurera varje tillgänglig kolumn efter behov. I följande tabell sammanfattas de anpassningar som för närvarande är tillgängliga via studion.
Column Anpassning Funktionstyp Ändra värdetypen för den valda kolumnen. Impute med Välj vilket värde du vill imputera saknade värden med i dina data. 

Inställningarna för funktionalisering påverkar inte indata som behövs för slutsatsdragning. Om du exkluderar kolumner från träning krävs fortfarande de exkluderade kolumnerna som indata för slutsatsdragning av modellen.
Konfigurera begränsningar för jobbet
Avsnittet Gränser innehåller konfigurationsalternativ för följande inställningar:
| Inställning | beskrivning | Värde |
|---|---|---|
| Maximalt antal utvärderingsversioner | Ange det maximala antalet utvärderingsversioner som ska provas under det automatiserade ML-jobbet, där varje utvärderingsversion har en annan kombination av algoritmer och hyperparametrar. | Heltal mellan 1 och 1 000 |
| Maximalt antal samtidiga utvärderingar | Ange det maximala antalet utvärderingsjobb som kan köras parallellt. | Heltal mellan 1 och 1 000 |
| Maximalt antal noder | Ange det maximala antalet noder som det här jobbet kan använda från det valda beräkningsmålet. | 1 eller mer, beroende på beräkningskonfigurationen |
| Tröskelvärde för måttpoäng | Ange tröskelvärdet för iterationsmått. När iterationen når tröskelvärdet avslutas träningsjobbet. Tänk på att meningsfulla modeller har en korrelation som är större än noll. Annars är resultatet detsamma som att gissa. | Genomsnittligt tröskelvärde för mått, mellan gränser [0, 10] |
| Tidsgräns för experiment (minuter) | Ange den maximala tid som hela experimentet kan köras. När experimentet har nått gränsen avbryter systemet det automatiserade ML-jobbet, inklusive alla dess utvärderingsversioner (underordnade jobb). | Antal minuter |
| Timeout för iteration (minuter) | Ange den maximala tid som varje utvärderingsjobb kan köras. När utvärderingsjobbet når den här gränsen avbryter systemet utvärderingsversionen. | Antal minuter |
| Aktivera tidig avslutning | Använd det här alternativet för att avsluta jobbet när poängen inte förbättras på kort sikt. | Välj alternativet för att aktivera tidig slut på jobbet |
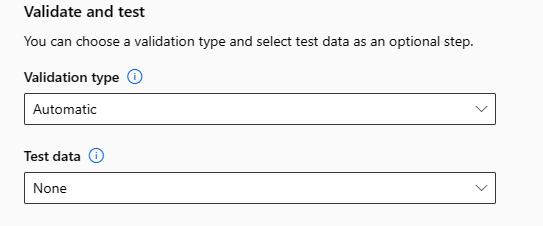
Validera och testa
Avsnittet Verifiera och testa innehåller följande konfigurationsalternativ:
Ange den valideringstyp som ska användas för ditt träningsjobb. Om du inte uttryckligen anger en
validation_dataellern_cross_validations-parameter tillämpar automatiserad ML standardtekniker beroende på antalet rader som anges i den enskilda datamängdentraining_data.Träningsdatastorlek Valideringsteknik Större än 20 000 rader Delning av tränings-/valideringsdata tillämpas. Standardvärdet är att ta 10 % av den inledande träningsdatauppsättningen som verifieringsuppsättning. Verifieringsuppsättningen används i sin tur för måttberäkning. Mindre än 20 000& rader Metoden för korsvalidering tillämpas. Standardantalet vikningar beror på antalet rader.
- Datauppsättning med mindre än 1 000 rader: 10 veck används
- Datauppsättning med 1 000 till 20 000 rader: Tre veck användsAnge testdata (förhandsversion) för att utvärdera den rekommenderade modell som automatiserad ML genererar i slutet av experimentet. När du anger testdatauppsättningen utlöses ett testjobb automatiskt i slutet av experimentet. Det här testjobbet är det enda jobbet på den bästa modellen som rekommenderas av automatiserad ML. Mer information finns i Visa resultat från fjärrtestjobb (förhandsversion).
Viktigt!
Att tillhandahålla en testdatauppsättning för att utvärdera genererade modeller är en förhandsversionsfunktion. Den här funktionen är en experimentell förhandsversionsfunktion och kan ändras när som helst.
Testdata anses vara åtskilda från träning och validering, och de bör inte ändra resultatet av testjobbet för den rekommenderade modellen. Mer information finns i Tränings-, validerings- och testdata.
Du kan antingen ange en egen testdatauppsättning eller välja att använda en procentandel av din träningsdatauppsättning. Testdata måste vara i form av en Azure Machine Learning-tabelldatauppsättning.
Schemat för testdatauppsättningen ska matcha träningsdatauppsättningen. Målkolumnen är valfri, men om ingen målkolumn anges beräknas inga testmått.
Testdatauppsättningen får inte vara samma som träningsdatauppsättningen eller valideringsdatauppsättningen.
Prognostiseringsjobb stöder inte tränings-/testdelning.
Konfigurera beräkningen
Följ dessa steg och konfigurera beräkningen:
Välj Nästa för att fortsätta till fliken Beräkning .
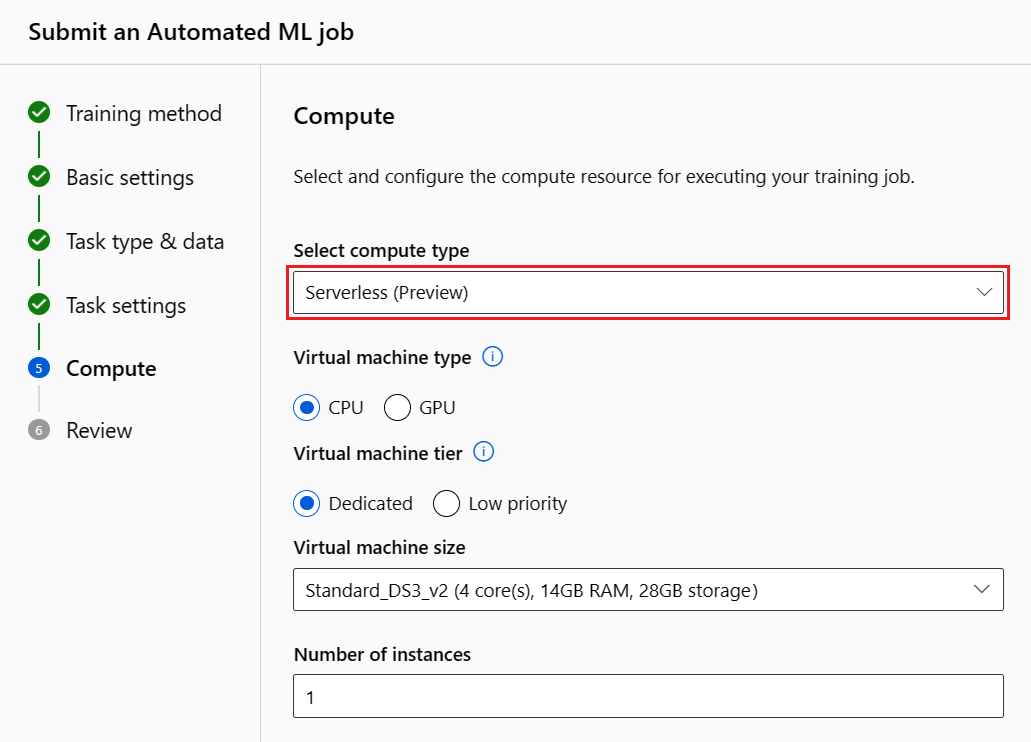
Använd listrutan Välj beräkningstyp för att välja ett alternativ för dataprofilering och träningsjobb. Alternativen är beräkningskluster, beräkningsinstanser eller serverlösa.
När du har valt beräkningstyp ändras det andra användargränssnittet på sidan baserat på ditt val:
Serverlös: Konfigurationsinställningarna visas på den aktuella sidan. Fortsätt till nästa steg för beskrivningar av de inställningar som ska konfigureras.
Beräkningskluster eller Beräkningsinstans: Välj bland följande alternativ:
Använd listrutan Välj automatiserad ML-beräkning för att välja en befintlig beräkning för din arbetsyta och välj sedan Nästa. Fortsätt till avsnittet Kör experiment och visa resultat .
Välj Ny för att skapa en ny beräkningsinstans eller ett nytt kluster. Det här alternativet öppnar sidan Skapa beräkning . Fortsätt till nästa steg för beskrivningar av de inställningar som ska konfigureras.
För en serverlös beräkning eller en ny beräkning konfigurerar du alla nödvändiga (*) inställningar:
Konfigurationsinställningarna varierar beroende på din beräkningstyp. I följande tabell sammanfattas de olika inställningar som du kan behöva konfigurera:
Fält beskrivning Beräkningsnamn Ange ett unikt namn som identifierar beräkningskontexten. Plats Ange datorns region. Prioritet för virtuell dator Virtuella datorer med låg prioritet är billigare men garanterar inte beräkningsnoderna. Typ av virtuell dator Välj CPU eller GPU för typ av virtuell dator. Nivå för virtuell dator Välj prioritet för experimentet. Storlek på virtuell dator Välj storleken på den virtuella datorn för din beräkning. Min/Max-noder Om du vill profilera data måste du ange en eller flera noder. Ange det maximala antalet noder för din beräkning. Standardvärdet är sex noder för en Azure Machine Learning Compute. Inaktiva sekunder innan nedskalning Ange inaktivitetstiden innan klustret skalas ned automatiskt till det minsta antalet noder. Avancerade inställningar Med de här inställningarna kan du konfigurera ett användarkonto och ett befintligt virtuellt nätverk för experimentet. När du har konfigurerat de nödvändiga inställningarna väljer du Nästa eller Skapa efter behov.
Det kan ta några minuter att skapa en ny beräkning. När skapandet är klart väljer du Nästa.
Köra experiment och visa resultat
Välj Slutför för att köra experimentet. Experimentförberedelserna kan ta upp till 10 minuter. För träningsjobb kan det ta ytterligare 2–3 minuter för varje pipeline att slutföra körningen. Om du har angett att generera RAI-instrumentpanelen för den bästa rekommenderade modellen kan det ta upp till 40 minuter.
Kommentar
Algoritmerna automatiserad ML använder har inbyggd slumpmässighet som kan orsaka liten variation i en rekommenderad modells slutliga måttpoäng, till exempel noggrannhet. Automatiserad ML utför också åtgärder på data, till exempel delning av träningstest, delning av tågvalidering eller korsvalidering efter behov. Om du kör ett experiment med samma konfigurationsinställningar och primärt mått flera gånger ser du förmodligen variation i varje experiments slutliga måttpoäng på grund av dessa faktorer.
Visa experimentinformation
Skärmen Jobbinformation öppnas på fliken Information . Den här skärmen visar en sammanfattning av experimentjobbet, inklusive ett statusfält högst upp bredvid jobbnumret.
Fliken Modeller innehåller en lista över de modeller som skapats ordnade efter måttpoängen. Som standard visas modellen med högst poäng utifrån det valda måttet överst i listan. När träningsjobbet provar fler modeller läggs de tränade modellerna till i listan. Använd den här metoden för att få en snabb jämförelse av måtten för de modeller som hittills har producerats.
Visa information om träningsjobb
Öka detaljnivån för någon av de slutförda modellerna för information om träningsjobbet. Du kan se prestandamåttdiagram för specifika modeller på fliken Mått . Mer information finns i Utvärdera automatiserade maskininlärningsexperimentresultat. På den här sidan kan du också hitta information om alla egenskaper för modellen tillsammans med associerad kod, underordnade jobb och bilder.
Visa resultat från fjärrtestjobb (förhandsversion)
Om du har angett en testdatauppsättning eller valt en tränings-/testdelning under experimentkonfigurationen i formuläret Verifiera och testa , testar automatiserad ML automatiskt den rekommenderade modellen som standard. Därför beräknar automatiserad ML testmått för att fastställa kvaliteten på den rekommenderade modellen och dess förutsägelser.
Viktigt!
Att testa dina modeller med en testdatauppsättning för att utvärdera genererade modeller är en förhandsversionsfunktion. Den här funktionen är en experimentell förhandsversionsfunktion och kan ändras när som helst.
Den här funktionen är inte tillgänglig för följande automatiserade ML-scenarier:
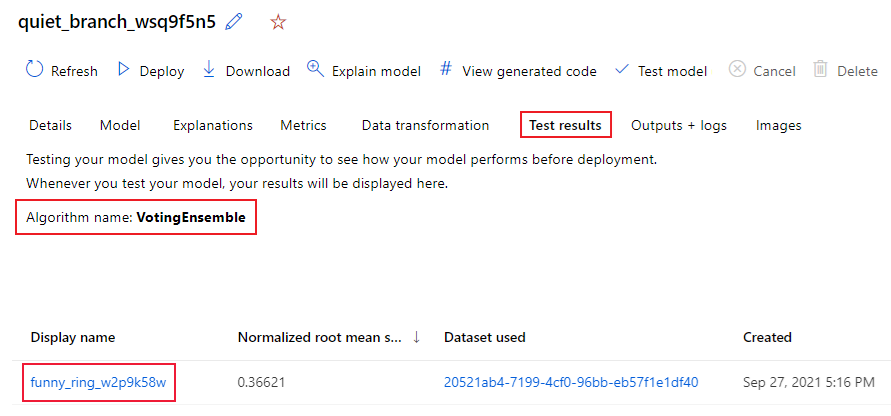
Följ de här stegen för att visa testjobbsmåtten för den rekommenderade modellen:
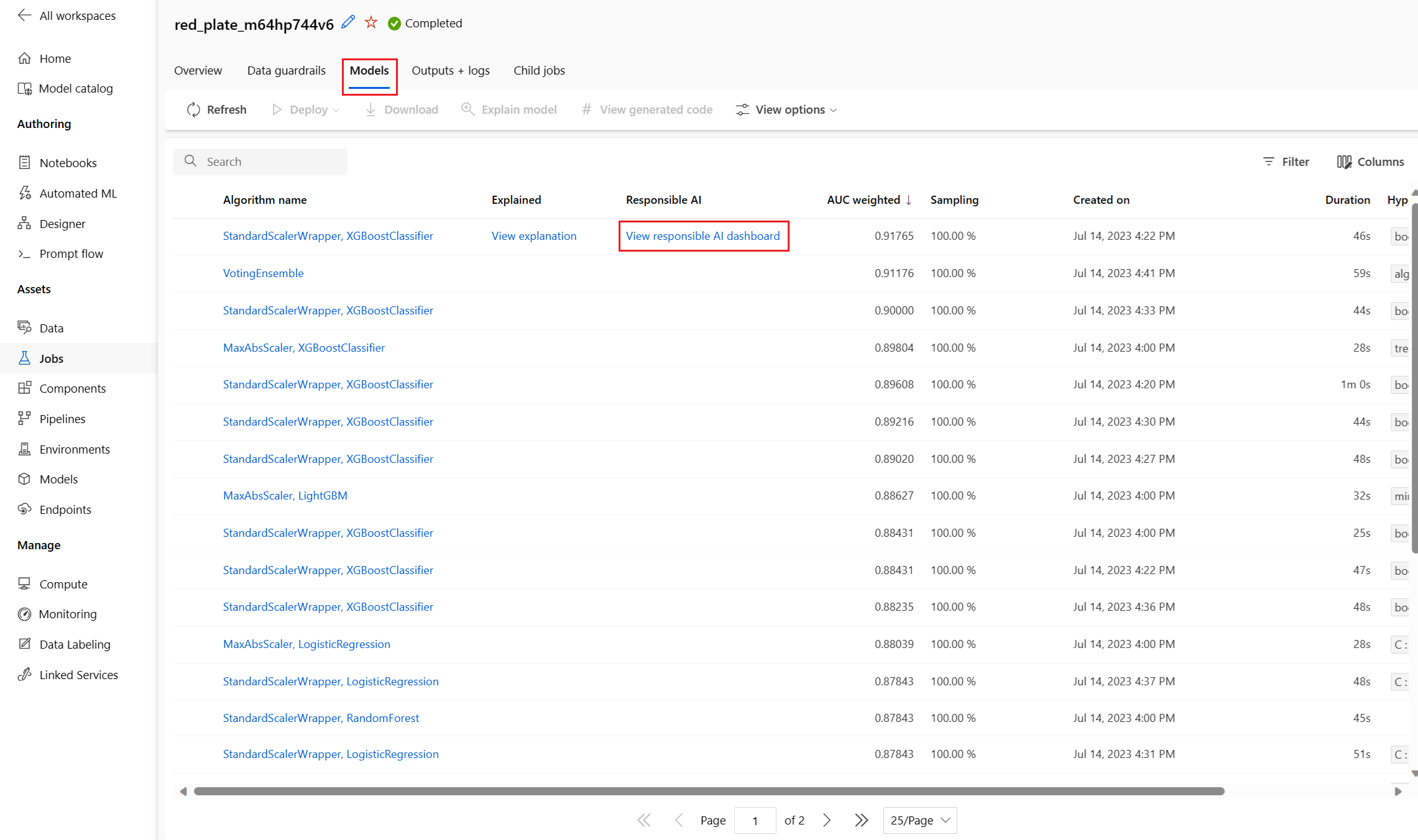
I studion bläddrar du till sidan Modeller och väljer den bästa modellen.
Välj fliken Testresultat (förhandsversion).
Välj önskat jobb och visa fliken Mått :
Visa testförutsägelserna som används för att beräkna testmåtten genom att följa dessa steg:
Längst ned på sidan väljer du länken under Datauppsättningen Utdata för att öppna datauppsättningen.
På sidan Datauppsättningar väljer du fliken Utforska för att visa förutsägelserna från testjobbet.
Förutsägelsefilen kan också visas och laddas ned från fliken Utdata + loggar . Expandera mappen Förutsägelser för att hitta filen prediction.csv .
Modelltestjobbet genererar den predictions.csv fil som lagras i standarddataarkivet som skapats med arbetsytan. Det här dataarkivet är synligt för alla användare med samma prenumeration. Testjobb rekommenderas inte för scenarier om någon av informationen som används för eller skapas av testjobbet måste förbli privat.
Testa befintlig automatiserad ML-modell (förhandsversion)
När experimentet är klart kan du testa de modeller som automatiserad ML genererar åt dig.
Viktigt!
Att testa dina modeller med en testdatauppsättning för att utvärdera genererade modeller är en förhandsversionsfunktion. Den här funktionen är en experimentell förhandsversionsfunktion och kan ändras när som helst.
Den här funktionen är inte tillgänglig för följande automatiserade ML-scenarier:
Om du vill testa en annan automatiserad ML-genererad modell och inte den rekommenderade modellen följer du dessa steg:
Välj ett befintligt automatiserat ML-experimentjobb.
Bläddra till fliken Modeller i jobbet och välj den färdiga modell som du vill testa.
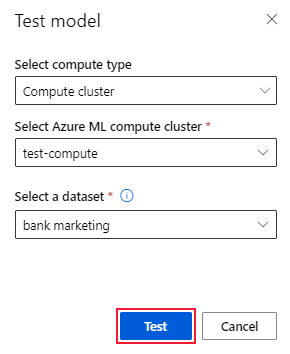
På sidan Modellinformation väljer du alternativet Testmodell (förhandsversion) för att öppna fönstret Testmodell.
I fönstret Testmodell väljer du beräkningsklustret och en testdatauppsättning som du vill använda för testjobbet.
Välj alternativet Testa. Schemat för testdatauppsättningen ska matcha träningsdatauppsättningen , men kolumnen Mål är valfri.
När modelltestjobbet har skapats visas ett meddelande på sidan Information . Välj fliken Testresultat för att se förloppet för jobbet.
Om du vill visa resultatet av testjobbet öppnar du sidan Information och följer stegen i avsnittet Visa resultat för fjärrtestjobb (förhandsversion).
Instrumentpanel för ansvarsfull AI (förhandsversion)
För att bättre förstå din modell kan du se olika insikter om din modell med hjälp av instrumentpanelen Ansvarsfull AI. Med det här användargränssnittet kan du utvärdera och felsöka din bästa automatiserade ML-modell. Instrumentpanelen ansvarsfull AI utvärderar modellfel och rättviseproblem, diagnostiserar varför felen inträffar genom att utvärdera dina tränings- och/eller testdata och observera modellförklaringar. Tillsammans kan dessa insikter hjälpa dig att skapa förtroende med din modell och klara granskningsprocesserna. Ansvarsfulla AI-instrumentpaneler kan inte genereras för en befintlig automatiserad ML-modell. Instrumentpanelen skapas endast för den bästa rekommenderade modellen när ett nytt automatiserat ML-jobb skapas. Användarna bör fortsätta att använda modellförklaringar (förhandsversion) tills stöd har tillhandahållits för befintliga modeller.
Generera en ansvarsfull AI-instrumentpanel för en viss modell genom att följa dessa steg:
När du skickar ett automatiserat ML-jobb fortsätter du till avsnittet Aktivitetsinställningar på den vänstra menyn och väljer alternativet Visa ytterligare konfigurationsinställningar .
På sidan Ytterligare konfiguration väljer du alternativet Förklara bästa modell :
Växla till fliken Beräkning och välj alternativet Serverlös för din beräkning:
När åtgärden är klar bläddrar du till sidan Modeller för ditt automatiserade ML-jobb, som innehåller en lista över dina tränade modeller. Välj länken Visa ansvarsfull AI-instrumentpanel:
Instrumentpanelen ansvarsfull AI visas för den valda modellen:
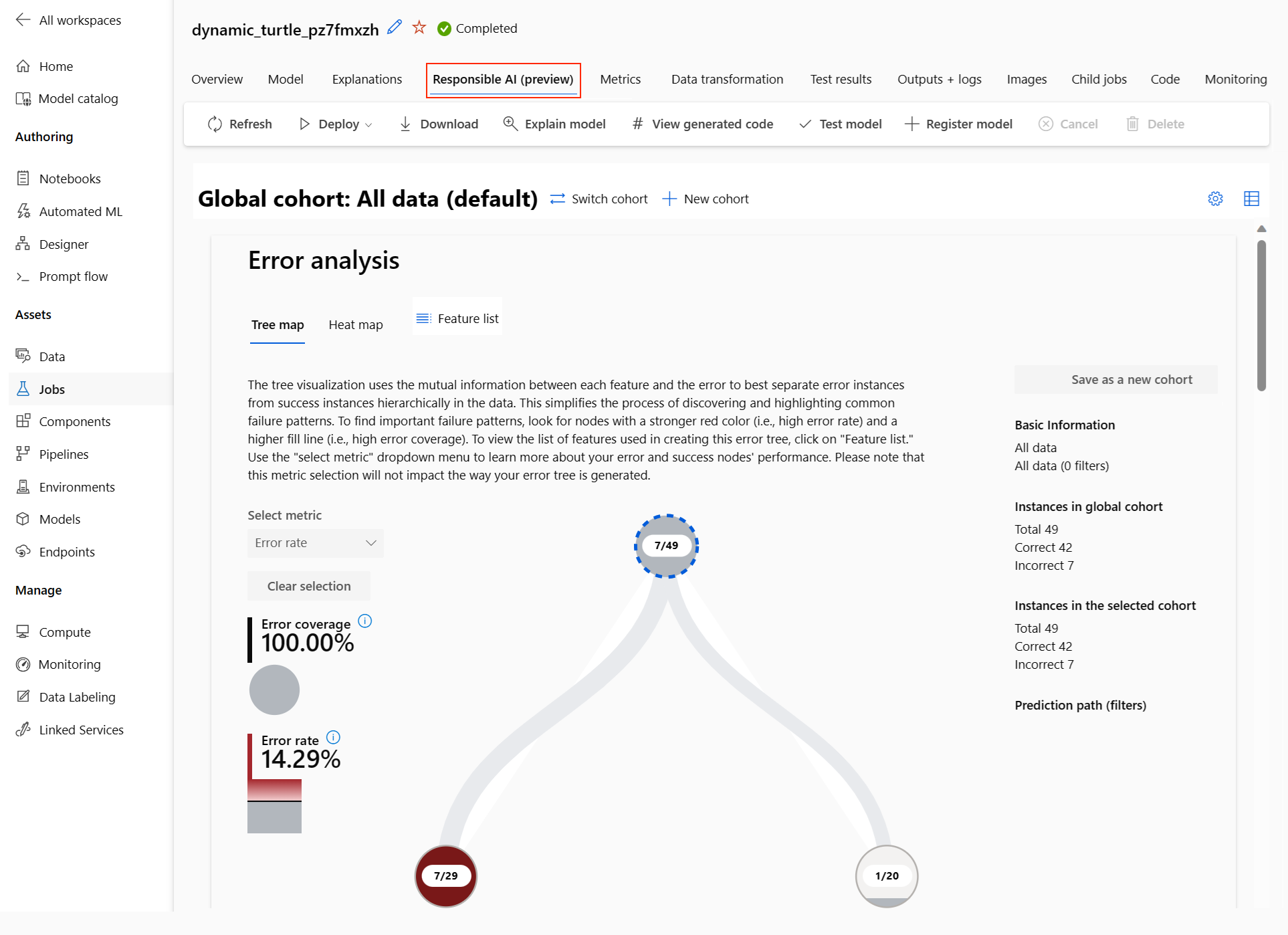
På instrumentpanelen ser du fyra komponenter som är aktiverade för din automatiserade ML-modell:
Komponent Vad visar komponenten? Hur läser jag diagrammet? Felanalys Använd felanalys när du behöver:
– Få en djup förståelse för hur modellfel fördelas över en datamängd och över flera indata- och funktionsdimensioner.
– Dela upp de aggregerade prestandamåtten för att automatiskt identifiera felaktiga kohorter för att informera dina riktade åtgärdssteg.Felanalysdiagram Modellöversikt och rättvisa Använd den här komponenten för att:
– Få en djup förståelse för modellens prestanda i olika kohorter av data.
– Förstå dina problem med modellens rättvisa genom att titta på olika mått. Dessa mått kan utvärdera och jämföra modellbeteende mellan undergrupper som identifieras i termer av känsliga (eller meningslösa) funktioner.Modellöversikt och rättvisediagram Modellförklaringar Använd modellförklaringskomponenten för att generera begripliga beskrivningar av förutsägelserna för en maskininlärningsmodell genom att titta på:
– Globala förklaringar: Vilka funktioner påverkar till exempel det övergripande beteendet för en låneallokeringsmodell?
– Lokala förklaringar: Varför godkändes eller avvisades en kunds låneansökan?Modellförklaringsdiagram Dataanalys Använd dataanalys när du behöver:
– Utforska datamängdsstatistiken genom att välja olika filter för att dela upp dina data i olika dimensioner (kallas även kohorter).
– Förstå fördelningen av din datamängd mellan olika kohorter och funktionsgrupper.
– Avgör om dina resultat som rör rättvisa, felanalys och orsakssamband (härledda från andra instrumentpanelskomponenter) är ett resultat av datamängdens distribution.
– Bestäm inom vilka områden du vill samla in mer data för att minimera fel som kommer från representationsproblem, etikettbrus, funktionsbrus, etikettfördomar och liknande faktorer.Datautforskaren-diagram Du kan ytterligare skapa kohorter (undergrupper med datapunkter som delar angivna egenskaper) för att fokusera din analys av varje komponent på olika kohorter. Namnet på den kohort som för närvarande tillämpas på instrumentpanelen visas alltid längst upp till vänster på instrumentpanelen. Standardvyn på instrumentpanelen är hela datauppsättningen med titeln Alla data som standard. Mer information finns i Globala kontroller för instrumentpanelen.


Redigera och skicka jobb (förhandsversion)
I scenarier där du vill skapa ett nytt experiment baserat på inställningarna för ett befintligt experiment tillhandahåller automatiserad ML alternativet Redigera och skicka i studiogränssnittet. Den här funktionen är begränsad till experiment som initierats från studiogränssnittet och kräver dataschemat för det nya experimentet för att matcha det ursprungliga experimentets.
Viktigt!
Möjligheten att kopiera, redigera och skicka ett nytt experiment baserat på ett befintligt experiment är en förhandsversionsfunktion. Den här funktionen är en experimentell förhandsversionsfunktion och kan ändras när som helst.
Alternativet Redigera och skicka öppnar guiden Skapa ett nytt automatiserat ML-jobb med de förifyllda inställningarna för data, beräkning och experiment. Du kan konfigurera alternativen på varje flik i guiden och redigera val efter behov för det nya experimentet.
Distribuera din modell
När du har den bästa modellen kan du distribuera modellen som en webbtjänst för att förutsäga nya data.
Kommentar
Om du vill distribuera en modell som genererats via automl paketet med Python SDK måste du registrera din modell) på arbetsytan.
När du har registrerat modellen kan du hitta modellen i studion genom att välja Modeller på den vänstra menyn. På sidan modellöversikt kan du välja alternativet Distribuera och fortsätta till steg 2 i det här avsnittet.
Automatiserad ML hjälper dig att distribuera modellen utan att skriva kod.
Initiera distributionen med någon av följande metoder:
Distribuera den bästa modellen med de måttkriterier som du definierade:
När experimentet är klart väljer du Jobb 1 och bläddrar till den överordnade jobbsidan.
Välj den modell som visas i avsnittet Bästa modellsammanfattning och välj sedan Distribuera.
Distribuera en specifik modell-iteration från det här experimentet:
- Välj önskad modell på fliken Modeller och välj sedan Distribuera.
Fyll i fönstret Distribuera modell:
Fält Värde Namn Ange ett unikt namn för distributionen. Beskrivning Ange en beskrivning för att bättre identifiera distributionssyftet. Beräkningstyp Välj den typ av slutpunkt som du vill distribuera: Azure Kubernetes Service (AKS) eller Azure Container Instance (ACI). Beräkningsnamn (Gäller endast för AKS) Välj namnet på det AKS-kluster som du vill distribuera till. Aktivera autentisering Välj för att tillåta tokenbaserad eller nyckelbaserad autentisering. Använda anpassade distributionstillgångar Aktivera anpassade tillgångar om du vill ladda upp ett eget bedömningsskript och en egen miljöfil. Annars tillhandahåller Automatiserad ML dessa tillgångar åt dig som standard. Mer information finns i Distribuera och poängsätta en maskininlärningsmodell med hjälp av en onlineslutpunkt. Viktigt!
Filnamnen måste vara mellan 1 och 32 tecken. Namnet måste börja och sluta med alfanumeriska värden och kan innehålla bindestreck, understreck, punkter och alfanumeriska mellan. Blanksteg tillåts inte.
Menyn Avancerat innehåller standarddistributionsfunktioner som datainsamling och inställningar för resursanvändning. Du kan använda alternativen i den här menyn för att åsidosätta dessa standardvärden. Mer information finns i Övervaka onlineslutpunkter.
Välj distribuera. Det kan ta ungefär 20 minuter att slutföra distributionen.
När distributionen har startat öppnas fliken Modellsammanfattning . Du kan övervaka distributionsförloppet under avsnittet Distribuera status .
Nu har du ett fungerande webbtjänst för att generera förutsägelser! Du kan testa förutsägelserna genom att fråga tjänsten från AI-exemplen från slutpunkt till slutpunkt i Microsoft Fabric.