Snabbstart: Vektorisera text och bilder med hjälp av Azure Portal
Den här snabbstarten hjälper dig att komma igång med integrerad vektorisering med hjälp av guiden Importera och vektorisera data i Azure Portal. Guiden segmenterar ditt innehåll och anropar en inbäddningsmodell för att vektorisera innehåll under indexering och för frågor.
Viktiga punkter om guiden:
Datakällor som stöds är Azure Blob Storage, Azure Data Lake Storage (ADLS) Gen2 eller OneLake-filer och genvägar.
Inbäddningsmodeller som stöds finns i Azure OpenAI, Azure AI Studio-modellkatalogen, Azure AI Vision multimodal.
Indexschemat innehåller vektor- och icke-vektorfält för segmenterade data.
Du kan lägga till fält, men du kan inte ta bort eller ändra genererade fält.
Dokumentparsningsläget skapar segment (ett sökdokument per segment).
Segmentering kan inte konfigureras. De effektiva inställningarna är:
"textSplitMode": "pages", "maximumPageLength": 2000, "pageOverlapLength": 500, "maximumPagesToTake": 0, #unlimited "unit": "characters",
Förutsättningar
En Azure-prenumeration. Skapa en kostnadsfritt.
Azure AI-tjänsten Search i samma region som Azure AI. Vi rekommenderar Basic-nivån eller högre.
Azure Blob Storage, Azure Data Lake Storage (ADLS) Gen2 (ett lagringskonto med ett hierarkiskt namnområde) eller ett OneLake Lakehouse.
Azure Storage måste vara ett standardkonto för prestanda (generell användning v2). Åtkomstnivåerna kan vara varma, lågfrekventa och kalla.
En inbäddningsmodell på en Azure AI-plattform i samma region som Azure AI Search. Distributionsinstruktioner finns i den här artikeln.
Provider Modeller som stöds Azure OpenAI-tjänsten text-embedding-ada-002, text-embedding-3-large eller text-embedding-3-small. Azure AI Studio-modellkatalog Inbäddningsmodeller för Azure, Cohere och Facebook. Azure AI-tjänsters multiservicekonto Azure AI Vision multimodal för bild- och textvektorisering. Azure AI Vision multimodal är tillgängligt i utvalda regioner. I dokumentationen finns en uppdaterad lista. Om du vill använda den här resursen måste kontot finnas i en tillgänglig region och i samma region som Azure AI Search.
Om du använder Azure OpenAI-tjänsten måste den ha en associerad anpassad underdomän. Om tjänsten skapades via Azure Portal genereras den här underdomänen automatiskt som en del av tjänstkonfigurationen. Se till att tjänsten innehåller en anpassad underdomän innan du använder den med Azure AI Search-integreringen.
Azure OpenAI-tjänstresurser (med åtkomst till inbäddningsmodeller) som skapades i AI Studio stöds inte. Endast De Azure OpenAI-tjänstresurser som skapats i Azure Portal är kompatibla med integreringen av Azure OpenAI-inbäddningsfärdighet.
Krav för offentlig slutpunkt
Alla föregående resurser måste ha offentlig åtkomst aktiverad så att portalnoderna kan komma åt dem. Annars misslyckas guiden. När guiden har körts kan du aktivera brandväggar och privata slutpunkter på integreringskomponenterna för säkerhet. Mer information finns i Säkra anslutningar i importguiderna.
Om privata slutpunkter redan finns och du inte kan inaktivera dem är det alternativa alternativet att köra respektive flöde från slutpunkt till slutpunkt från ett skript eller program på en virtuell dator. Den virtuella datorn måste finnas i samma virtuella nätverk som den privata slutpunkten. Här är ett Python-kodexempel för integrerad vektorisering. Samma GitHub-lagringsplats har exempel på andra programmeringsspråk.
Krav för rollbaserad åtkomstkontroll
Vi rekommenderar rolltilldelningar för söktjänstanslutningar till andra resurser.
Aktivera roller i Azure AI Search.
Konfigurera söktjänsten så att den använder en hanterad identitet.
Skapa rolltilldelningar som gör det möjligt för söktjänsten att komma åt data och modeller på datakällans plattform och inbäddningsmodellprovider. Förbered exempeldata innehåller instruktioner för hur du konfigurerar roller.
En kostnadsfri söktjänst stöder RBAC vid anslutningar till Azure AI Search, men den stöder inte hanterade identiteter vid utgående anslutningar till Azure Storage eller Azure AI Vision. Den här supportnivån innebär att du måste använda nyckelbaserad autentisering på anslutningar mellan en kostnadsfri söktjänst och andra Azure-tjänster.
För säkrare anslutningar:
- Använd basic-nivån eller högre.
- Konfigurera en hanterad identitet och använda roller för auktoriserad åtkomst.
Kommentar
Om du inte kan gå vidare med guiden eftersom alternativen inte är tillgängliga (du kan till exempel inte välja en datakälla eller en inbäddningsmodell) går du tillbaka till rolltilldelningarna. Felmeddelanden anger att modeller eller distributioner inte finns, när den verkliga orsaken i själva verket är att söktjänsten inte har behörighet att komma åt dem.
Kontrollera utrymmet
Om du börjar med den kostnadsfria tjänsten är du begränsad till tre index, datakällor, kompetensuppsättningar och indexerare. Grundläggande begränsar dig till 15. Kontrollera att du har plats för extra objekt innan du börjar. Den här snabbstarten skapar ett av varje objekt.
Sök efter semantisk ranker
Guiden stöder semantisk rangordning, men bara på basic-nivån och högre, och endast om semantisk ranker redan är aktiverat i söktjänsten. Om du använder en fakturerbar nivå kontrollerar du om semantisk rankning har aktiverats.
Förbereda exempeldata
Det här avsnittet pekar på data som fungerar för den här snabbstarten.
Logga in på Azure Portal med ditt Azure-konto och gå till ditt Azure Storage-konto.
I den vänstra rutan, under Datalagring, väljer du Containrar.
Skapa en ny container och ladda sedan upp de PDF-dokument för hälsoplan som används för den här snabbstarten.
I den vänstra rutan, under Åtkomstkontroll, tilldelar du rollen Storage Blob Data Reader till söktjänstens identitet. Du kan också hämta en anslutningssträng till lagringskontot från sidan Åtkomstnycklar.
Du kan också synkronisera borttagningarna i containern med borttagningar i sökindexet. Med följande steg kan du konfigurera indexeraren för borttagningsidentifiering:
Aktivera mjuk borttagning på ditt lagringskonto.
Om du använder inbyggd mjuk borttagning krävs inga ytterligare steg i Azure Storage.
Annars lägger du till anpassade metadata som en indexerare kan skanna för att avgöra vilka blobar som ska tas bort. Ge din anpassade egenskap ett beskrivande namn. Du kan till exempel ge egenskapen namnet "IsDeleted", inställt på false. Gör detta för varje blob i containern. När du senare vill ta bort bloben ändrar du egenskapen till true. Mer information finns i Ändra och ta bort identifiering vid indexering från Azure Storage
Konfigurera inbäddningsmodeller
Guiden kan använda inbäddningsmodeller som distribuerats från Azure OpenAI, Azure AI Vision eller från modellkatalogen i Azure AI Studio.
Guiden stöder text-embedding-ada-002, text-embedding-3-large och text-embedding-3-small. Internt anropar guiden AzureOpenAIEmbedding-färdigheten för att ansluta till Azure OpenAI.
Logga in på Azure Portal med ditt Azure-konto och gå till din Azure OpenAI-resurs.
Konfigurera behörigheter:
Välj Åtkomstkontroll på den vänstra menyn.
Välj Lägg till och sedan Lägg till rolltilldelning.
Under Jobbfunktionsroller väljer du Cognitive Services OpenAI-användare och sedan Nästa.
Under Medlemmar väljer du Hanterad identitet och sedan Medlemmar.
Filtrera efter prenumeration och resurstyp (söktjänster) och välj sedan söktjänstens hanterade identitet.
Välj Granska + tilldela.
På sidan Översikt väljer du Klicka här för att visa slutpunkter eller Klicka här för att hantera nycklar om du behöver kopiera en slutpunkt eller API-nyckel. Du kan klistra in dessa värden i guiden om du använder en Azure OpenAI-resurs med nyckelbaserad autentisering.
Under Resurshantering och modelldistributioner väljer du Hantera distributioner för att öppna Azure AI Studio.
Kopiera distributionsnamnet
text-embedding-ada-002för eller en annan inbäddningsmodell som stöds. Om du inte har någon inbäddningsmodell distribuerar du en nu.
Starta guiden
Logga in på Azure Portal med ditt Azure-konto och gå till azure AI-tjänsten Search.
På sidan Översikt väljer du Importera och vektorisera data.

Ansluta till data
Nästa steg är att ansluta till en datakälla som ska användas för sökindexet.
På sidan Konfigurera dataanslutning väljer du Azure Blob Storage.
Ange Azure-prenumerationen.
Välj det lagringskonto och den container som tillhandahåller data.
Ange om du vill ha stöd för borttagningsidentifiering . Vid efterföljande indexeringskörningar uppdateras sökindexet för att ta bort alla sökdokument baserat på mjukt borttagna blobar i Azure Storage.
- Blobar stöder antingen mjuk borttagning av inbyggda blobar eller mjuk borttagning med anpassade data.
- Du måste tidigare ha aktiverat mjuk borttagning i Azure Storage och eventuellt lagt till anpassade metadata som indexering kan identifiera som en borttagningsflagga. Mer information om de här stegen finns i Förbereda exempeldata.
- Om du har konfigurerat dina blobar för mjuk borttagning med anpassade data anger du metadataegenskapens namn/värde-par i det här steget. Vi rekommenderar "IsDeleted". Om "IsDeleted" är inställt på true på en blob släpper indexeraren motsvarande sökdokument vid nästa indexerarekörning.
Guiden kontrollerar inte om Azure Storage innehåller giltiga inställningar eller utlöser ett fel om kraven inte uppfylls. I stället fungerar inte borttagningsidentifieringen, och ditt sökindex kommer sannolikt att samla in överblivna dokument över tid.
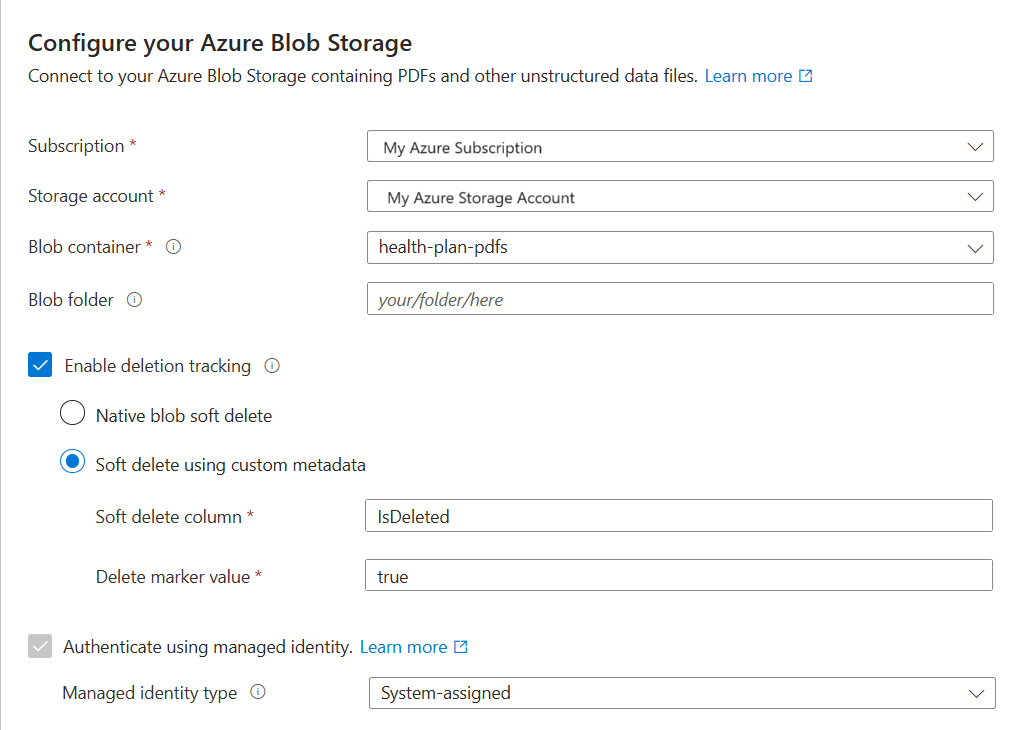
Ange om du vill att söktjänsten ska ansluta till Azure Storage med hjälp av dess hanterade identitet.
- Du uppmanas att välja antingen en systemhanterad eller användarhanterad identitet.
- Identiteten ska ha rollen Storage Blob Data Reader i Azure Storage.
- Hoppa inte över det här steget. Ett anslutningsfel uppstår under indexeringen om guiden inte kan ansluta till Azure Storage.
Välj Nästa.
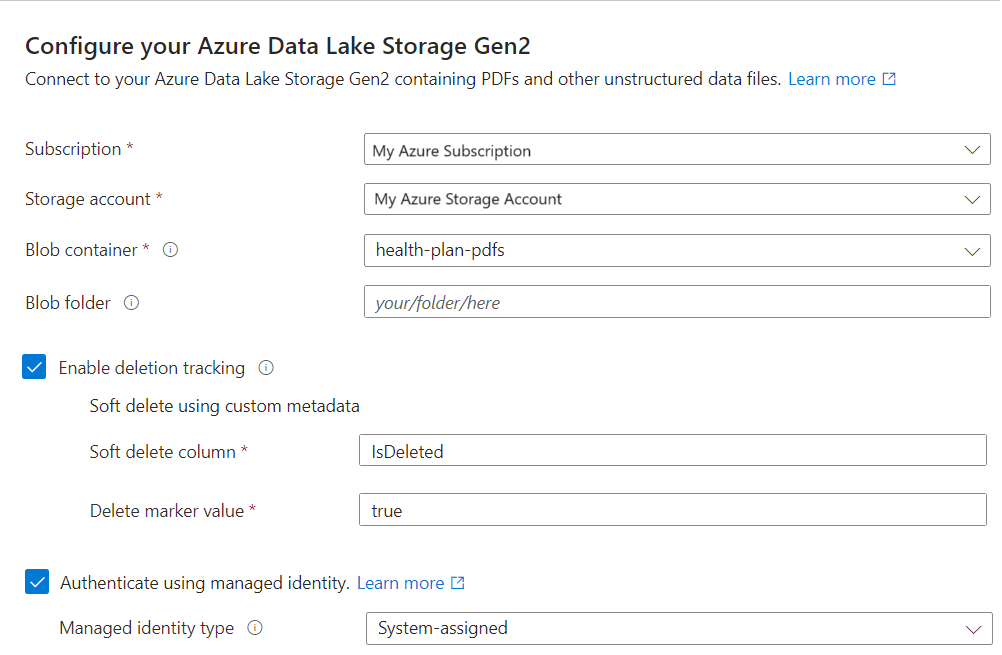
Vektorisera texten
I det här steget anger du inbäddningsmodellen för vektorisering av segmenterade data.
På sidan Vectorize your text (Vektorisera din text) väljer du källa för inbäddningsmodellen:
- Azure OpenAI
- Azure AI Studio-modellkatalog
- En befintlig multimodal Azure AI Vision-resurs i samma region som Azure AI Search. Om det inte finns något Azure AI Services-konto för flera tjänster i samma region är det här alternativet inte tillgängligt.
Välj Azure-prenumerationen.
Gör val enligt resursen:
För Azure OpenAI väljer du en befintlig distribution av text-embedding-ada-002, text-embedding-3-large eller text-embedding-3-small.
För AI Studio-katalog väljer du en befintlig distribution av en Inbäddningsmodell för Azure, Cohere och Facebook.
För AI Vision multimodala inbäddningar väljer du kontot.
Mer information finns i Konfigurera inbäddningsmodeller tidigare i den här artikeln.
Ange om du vill att söktjänsten ska autentisera med hjälp av en API-nyckel eller hanterad identitet.
- Identiteten ska ha en Cognitive Services OpenAI-användarroll på Azure AI-kontot för flera tjänster.
Markera kryssrutan som bekräftar faktureringspåverkan av att använda dessa resurser.
Välj Nästa.
Vektorisera och berika dina bilder
Om ditt innehåll innehåller bilder kan du använda AI på två sätt:
Använd en bildinbäddningsmodell som stöds från katalogen eller välj API:et för multimodala inbäddningar i Azure AI Vision för att vektorisera bilder.
Använd optisk teckenigenkänning (OCR) för att identifiera text i bilder. Det här alternativet anropar OCR-färdigheten för att läsa text från bilder.
Azure AI Search och din Azure AI-resurs måste finnas i samma region.
På sidan Vectorize your images (Vektorisera dina bilder) anger du vilken typ av anslutning guiden ska göra. För bildvektorisering kan guiden ansluta till inbäddningsmodeller i Azure AI Studio eller Azure AI Vision.
Ange prenumerationen.
För Azure AI Studio-modellkatalogen anger du projektet och distributionen. Mer information finns i Konfigurera inbäddningsmodeller tidigare i den här artikeln.
Du kan också knäcka binära bilder (till exempel skannade dokumentfiler) och använda OCR för att identifiera text.
Markera kryssrutan som bekräftar faktureringspåverkan av att använda dessa resurser.
Välj Nästa.
Lägg till semantisk rangordning
På sidan Avancerade inställningar kan du lägga till semantisk rangordning för att rangordna om resultaten i slutet av frågekörningen. Reranking höjer de mest semantiskt relevanta matcherna till toppen.
Mappa nya fält
På sidan Avancerade inställningar kan du lägga till nya fält. Som standard genererar guiden följande fält med följande attribut:
| Fält | Gäller för | beskrivning |
|---|---|---|
| chunk_id | Text- och bildvektorer | Genererat strängfält. Sökbar, hämtningsbar, sorterbar. Det här är dokumentnyckeln för indexet. |
| parent_id | Textvektorer | Genererat strängfält. Hämtningsbar, filterbar. Identifierar det överordnade dokument som segmentet kommer från. |
| segment | Text- och bildvektorer | Strängfält. Mänsklig läsbar version av datasegmentet. Sökbar och hämtningsbar, men inte filterbar, facetable eller sorterbar. |
| rubrik | Text- och bildvektorer | Strängfält. Mänsklig läsbar dokumentrubrik, sidrubrik eller sidnummer. Sökbar och hämtningsbar, men inte filterbar, facetable eller sorterbar. |
| text_vector | Textvektorer | Collection(Edm.single). Vektorrepresentation av segmentet. Sökbar och hämtningsbar, men inte filterbar, facetable eller sorterbar. |
Du kan inte ändra de genererade fälten eller deras attribut, men du kan lägga till nya fält om datakällan tillhandahåller dem. Azure Blob Storage innehåller till exempel en samling metadatafält.
Välj Lägg till.
Välj ett källfält i listan över tillgängliga fält, ange ett fältnamn för indexet och acceptera standarddatatypen eller åsidosättningen efter behov.
Metadatafält är sökbara, men går inte att hämta, filtrera, fasettbara eller sorterbara.
Välj Återställ om du vill återställa schemat till den ursprungliga versionen.
Schemalägg indexering
På sidan Avancerade inställningar kan du ange ett körningsschema för indexeraren.
- Välj Nästa när du är klar med sidan Avancerade inställningar .
Slutför guiden
På sidan Granska konfigurationen anger du ett prefix för de objekt som guiden skapar. Ett vanligt prefix hjälper dig att hålla ordning.
Välj Skapa.
När guiden har slutfört konfigurationen skapas följande objekt:
Anslutning till datakälla.
Index med vektorfält, vektoriserare, vektorprofiler och vektoralgoritmer. Du kan inte utforma eller ändra standardindexet under guidens arbetsflöde. Index överensstämmer med REST API för förhandsversionen av 2024-05-01.
Kompetensuppsättning med färdigheten Textdelning för segmentering och en inbäddningsfärdighet för vektorisering. Inbäddningsfärdigheten är antingen AzureOpenAIEmbeddingModel-färdigheten för Azure OpenAI eller AML-färdigheten för Azure AI Studio-modellkatalogen. Kompetensuppsättningen har också konfigurationen för indexprojektioner som gör att data kan mappas från ett dokument i datakällan till motsvarande segment i ett "underordnat" index.
Indexerare med fältmappningar och utdatafältmappningar (om tillämpligt).
Kontrollera resultat
Search Explorer accepterar textsträngar som indata och vektoriserar sedan texten för körning av vektorfrågor.
I Azure Portal går du till Sökhanteringsindex> och väljer sedan det index som du skapade.
Du kan också välja Frågealternativ och dölja vektorvärden i sökresultat. Det här steget gör sökresultaten enklare att läsa.
På menyn Visa väljer du JSON-vy så att du kan ange text för vektorfrågan i
textvektorfrågeparametern.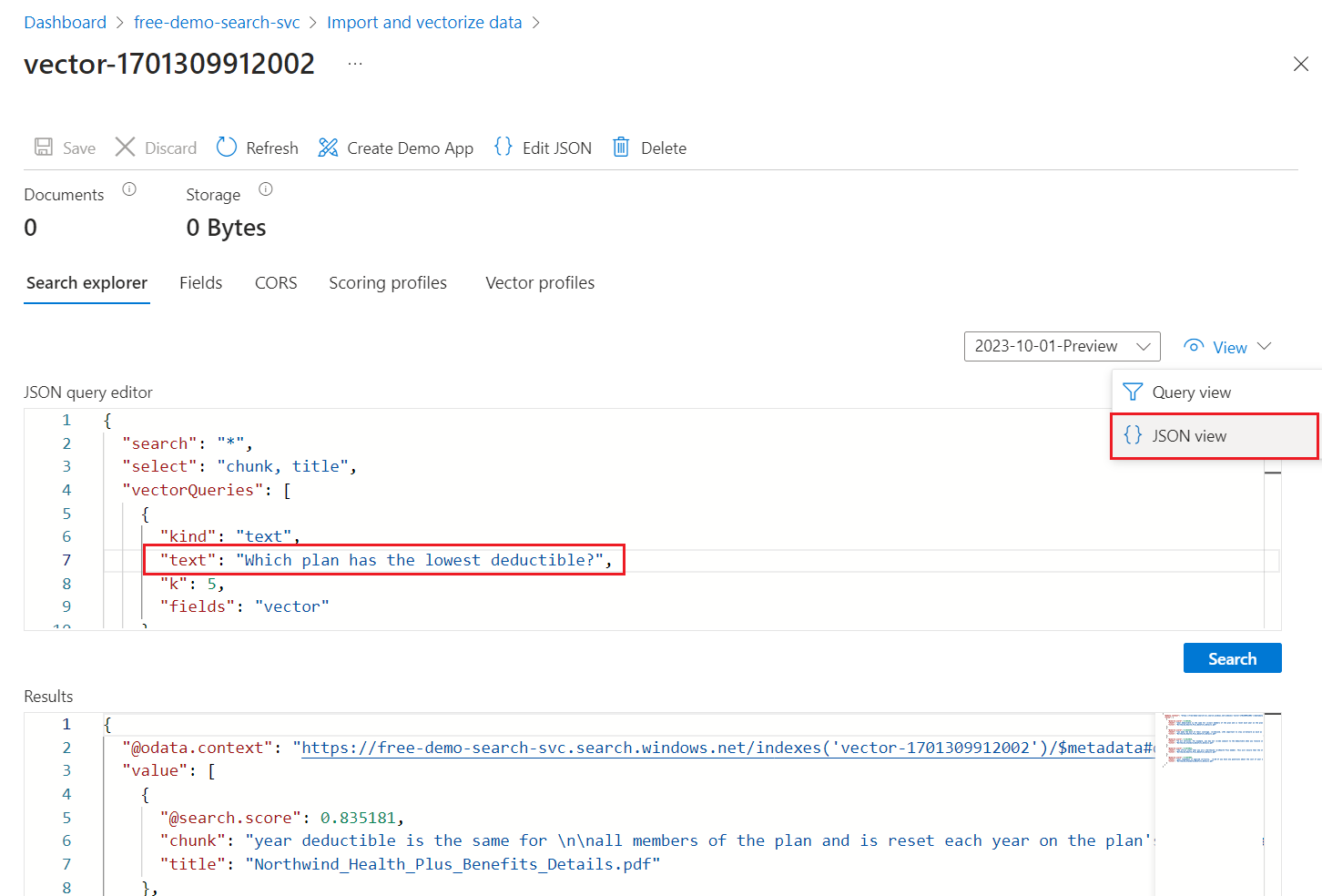
Guiden erbjuder en standardfråga som utfärdar en vektorfråga i
vectorfältet och returnerar de fem närmaste grannarna. Om du valde att dölja vektorvärden innehåller standardfrågan enselect-instruktion som exkluderarvectorfältet från sökresultat.{ "select": "chunk_id,parent_id,chunk,title", "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "vector" } ] }För värdet
textersätter du asterisken (*) med en fråga som rör hälsoplaner, till exempelWhich plan has the lowest deductible?.Välj Sök för att köra frågan.
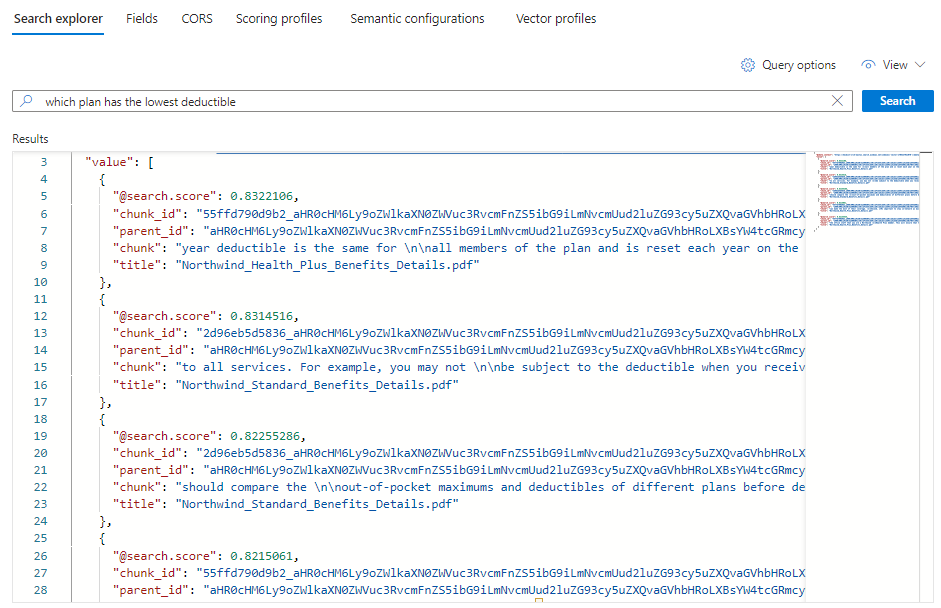
Fem matchningar ska visas. Varje dokument är en del av den ursprungliga PDF-filen. Fältet
titlevisar vilken PDF som segmentet kommer från.Om du vill se alla segment från ett visst dokument lägger du till ett filter för fältet
titleför en specifik PDF:{ "select": "chunk_id,parent_id,chunk,title", "filter": "title eq 'Benefit_Options.pdf'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "vector" } ] }
Rensa
Azure AI Search är en fakturerbar resurs. Om du inte längre behöver det tar du bort det från din prenumeration för att undvika avgifter.
Gå vidare
Den här snabbstarten introducerade dig i guiden Importera och vektorisera data som skapar alla nödvändiga objekt för integrerad vektorisering. Om du vill utforska varje steg i detalj kan du prova ett integrerat vektoriseringsexempel.