Semantisk rankning i Azure AI Search
I Azure AI Search är semantisk ranker en funktion som mätbart förbättrar sökrelevansen med hjälp av Microsofts språktolkningsmodeller för att rangordna sökresultaten igen. Den här artikeln är en introduktion på hög nivå som hjälper dig att förstå beteendet och fördelarna med semantisk ranker.
Semantisk ranker är en premiumfunktion som debiteras av användning. Vi rekommenderar den här artikeln för bakgrund, men om du hellre vill komma igång följer du de här stegen.
Kommentar
Semantisk ranker använder inte generativ AI eller vektorer. Om du letar efter vektorstöd och likhetssökning kan du läsa Vektorsökning i Azure AI Search för mer information.
Vad är semantisk rankning?
Semantisk rankning är en samling funktioner på frågesidan som förbättrar kvaliteten på ett första BM25-rankat eller RRF-rankat sökresultat för textbaserade frågor, vektorfrågor och hybridfrågor. När du aktiverar den i söktjänsten utökar semantisk rangordning frågekörningspipelinen på två sätt:
Först lägger den till sekundär rangordning över en första resultatuppsättning som poängsatts med BM25 eller Reciprocal Rank Fusion (RRF). Den här sekundära rankningen använder flerspråkiga djupinlärningsmodeller som är anpassade från Microsoft Bing för att främja de mest semantiskt relevanta resultaten.
För det andra extraherar och returnerar den bildtexter och svar i svaret, som du kan återge på en söksida för att förbättra användarens sökupplevelse.
Här är funktionerna i den semantiska rerankern.
| Kapacitet | beskrivning |
|---|---|
| L2-rangordning | Använder kontexten eller den semantiska innebörden av en fråga för att beräkna en ny relevanspoäng över förrankade resultat. |
| Semantiska bildtexter och markeringar | Extraherar ordagranna meningar och fraser från fält som bäst sammanfattar innehållet, med markeringar över viktiga passager för enkel genomsökning. Bildtexter som sammanfattar ett resultat är användbara när enskilda innehållsfält är för kompakta för sökresultatsidan. Markerad text höjer de mest relevanta termerna och fraserna så att användarna snabbt kan avgöra varför en matchning ansågs relevant. |
| Semantiska svar | En valfri och extra understruktur som returneras från en semantisk fråga. Det ger ett direkt svar på en fråga som ser ut som en fråga. Det kräver att ett dokument har text med egenskaperna för ett svar. |
Så här fungerar semantisk ranker
Semantisk ranker matar en fråga och resultat till modeller för språktolkning som hanteras av Microsoft och söker efter bättre matchningar.
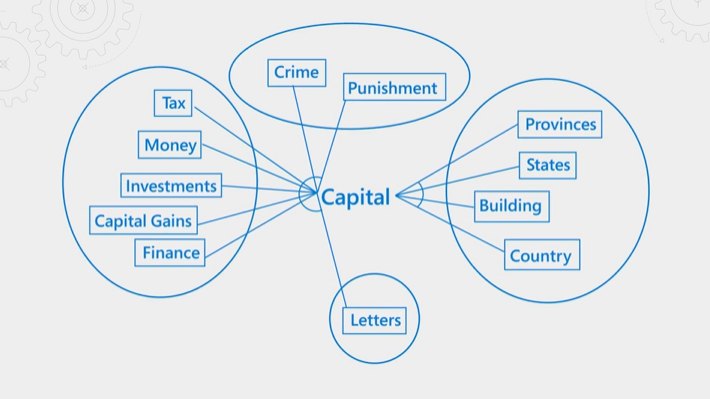
Följande bild förklarar begreppet. Överväg termen "kapital". Den har olika betydelser beroende på om kontexten är ekonomi, lag, geografi eller grammatik. Genom språktolkning kan den semantiska rankaren identifiera kontext och höja upp resultat som passar fråge avsikter.
Semantisk rangordning är både resurs- och tidsintensiv. För att slutföra bearbetningen inom den förväntade svarstiden för en frågeåtgärd konsolideras indata till den semantiska rankern och minskas så att omrankningssteget kan slutföras så snabbt som möjligt.
Det finns tre steg för semantisk rangordning:
- Samla in och sammanfatta indata
- Poängsätta resultat med hjälp av semantisk ranker
- Utdata ominspelade resultat, undertexter och svar
Hur indata samlas in och sammanfattas
I semantisk rangordning skickar frågeundersystemet sökresultat som indata till sammanfattnings- och rangordningsmodeller. Eftersom rangordningsmodellerna har begränsningar för indatastorlek och bearbetar intensivt måste sökresultaten vara storleksanpassade och strukturerade (sammanfattade) för effektiv hantering.
Semantisk rankning börjar med ett BM25-rankat resultat från en textfråga eller ett RRF-rankat resultat från en vektor- eller hybridfråga. Endast textfält används i omrankningsövningen och endast de 50 främsta resultaten går vidare till semantisk rangordning, även om resultaten innehåller fler än 50. Fält som används i semantisk rangordning är vanligtvis informations- och beskrivande.
För varje dokument i sökresultatet accepterar sammanfattningsmodellen upp till 2 000 token, där en token är cirka 10 tecken. Indata sammanställs från fälten "title", "keyword" och "content" som anges i den semantiska konfigurationen.
Alltför långa strängar trimmas för att säkerställa att den totala längden uppfyller indatakraven i sammanfattningssteget. Den här trimningsövningen är därför det är viktigt att lägga till fält i din semantiska konfiguration i prioritetsordning. Om du har mycket stora dokument med textintensiva fält ignoreras allt efter maxgränsen.
Semantiskt fält Tokengräns "title" 128 tokens "nyckelord 128 tokens "innehåll" återstående token Sammanfattningsutdata är en sammanfattningssträng för varje dokument som består av den mest relevanta informationen från varje fält. Sammanfattningssträngar skickas till rankaren för bedömning och till maskinläsningsförståelsemodeller för bildtexter och svar.
Den maximala längden för varje genererad sammanfattningssträng som skickas till den semantiska rankern är 256 token.
Så här poängsätts rangordningen
Bedömning görs över undertexten och allt annat innehåll från sammanfattningssträngen som fyller i 256 tokenlängden.
Undertexter utvärderas för konceptuell och semantisk relevans i förhållande till den angivna frågan.
En @search.rerankerScore tilldelas varje dokument baserat på dokumentets semantiska relevans för den angivna frågan. Poängen varierar från 4 till 0 (hög till låg), där en högre poäng indikerar högre relevans.
Poäng Innebörd 4.0 Dokumentet är mycket relevant och besvarar frågan helt, även om passagen kan innehålla extra text som inte är relaterad till frågan. 3,0 Dokumentet är relevant men saknar information som skulle göra det komplett. 2.0 Dokumentet är något relevant. den besvarar frågan antingen delvis eller bara tar upp vissa aspekter av frågan. 1.0 Dokumentet är relaterat till frågan och besvarar en liten del av den. 0,0 Dokumentet är irrelevant. Matchningar visas i fallande ordning efter poäng och ingår i nyttolasten för frågesvar. Nyttolasten innehåller svar, oformaterad text och markerade bildtexter samt eventuella fält som du har markerat som hämtningsbara eller angivna i en select-sats.
Kommentar
För en viss fråga kan distributionerna av @search.rerankerScore uppvisa små variationer på grund av förhållanden på infrastrukturnivå. Uppdateringar av rangordningsmodeller har också varit kända för att påverka fördelningen. Om du skriver anpassad kod för minimitrösklar eller anger tröskelvärdesegenskapen för vektor- och hybridfrågor ska du därför inte göra gränserna för detaljerade.
Utdata från semantisk ranker
Från varje sammanfattningssträng hittar maskinläsningsförståelsemodellerna de passager som är mest representativa.
Utdata är:
En semantisk bildtext för dokumentet. Varje bildtext är tillgänglig i en oformaterad textversion och en markeringsversion och är ofta färre än 200 ord per dokument.
Ett valfritt semantiskt svar, förutsatt att du angav parametern
answers, frågan ställdes som en fråga och en passage hittas i den långa strängen som ger ett troligt svar på frågan.
Undertexter och svar är alltid ordagrant text från ditt index. Det finns ingen generativ AI-modell i det här arbetsflödet som skapar eller skapar nytt innehåll.
Semantiska funktioner och begränsningar
Semantisk ranker är en nyare teknik så det är viktigt att sätta förväntningar på vad den kan och inte kan göra. Vad den kan göra:
Flytta upp matchningar som är semantiskt närmare avsikten med den ursprungliga frågan.
Hitta strängar som ska användas som undertexter och svar. Bildtexter och svar returneras i svaret och kan återges på en sökresultatsida.
Vad semantisk ranker inte kan göra är att köra frågan igen över hela corpus för att hitta semantiskt relevanta resultat. Semantisk rangordning rangordnar om den befintliga resultatuppsättningen, som består av de 50 bästa resultaten enligt standardrankningsalgoritmen. Dessutom kan semantisk ranker inte skapa ny information eller strängar. Bildtexter och svar extraheras ordagrant från ditt innehåll, så om resultaten inte innehåller svarsliknande text kommer språkmodellerna inte att producera någon.
Även om semantisk rangordning inte är fördelaktig i varje scenario kan visst innehåll dra stor nytta av dess funktioner. Språkmodellerna i semantisk ranker fungerar bäst på sökbart innehåll som är informationsrikt och strukturerat som prosa. En kunskapsbas, onlinedokumentation eller dokument som innehåller beskrivande innehåll ser de största vinsterna från semantiska rankningsfunktioner.
Den underliggande tekniken kommer från Bing och Microsoft Research och är integrerad i Azure AI Search-infrastrukturen som en tilläggsfunktion. Mer information om forsknings- och AI-investeringar som stöder semantisk rankning finns i How AI from Bing is powering Azure AI Search (Microsoft Research Blog).
Följande video ger en översikt över funktionerna.
Tillgänglighet och priser
Semantisk rankning är tillgängligt på söktjänster på nivåerna Basic och högre, beroende på regional tillgänglighet.
När du aktiverar semantisk rankning väljer du en prisplan för funktionen:
- Vid lägre frågevolymer (under 1 000 per månad) är semantisk rangordning kostnadsfri.
- Vid högre frågevolymer väljer du standardprisplanen.
På prissättningssidan för Azure AI Search visas faktureringsfrekvensen för olika valutor och intervall.
Avgifter för semantisk rankning debiteras när frågebegäranden inkluderar queryType=semantic och söksträngen inte är tom (till exempel search=pet friendly hotels in New York). Om söksträngen är tom (search=*) debiteras du inte, även om queryType är inställd på semantisk.
Så här kommer du igång med semantisk ranker
Logga in på Azure Portal för att kontrollera att söktjänsten är Basic eller högre.
Konfigurera frågor för att returnera semantiska bildtexter och markeringar.