Relevans i nyckelordssökning (BM25-bedömning)
Den här artikeln förklarar algoritmen för relevansbedömning i BM25 som används för att beräkna sökpoäng för fulltextsökning. BM25-relevans är exklusiv för fulltextsökning. Filterfrågor, komplettera automatiskt och föreslagna frågor, jokerteckensökning eller fuzzy-sökfrågor poängsätts inte eller rangordnas inte för relevans.
Bedömningsalgoritmer som används i fulltextsökning
Azure AI Search innehåller följande bedömningsalgoritmer för fulltextsökning:
| Algoritm | Användning | Intervall |
|---|---|---|
BM25Similarity |
Algoritmen har åtgärdats för alla söktjänster som skapats efter juli 2020. Du kan konfigurera den här algoritmen, men du kan inte växla till en äldre (klassisk). | Obegränsad. |
ClassicSimilarity |
Finns på äldre söktjänster. Du kan välja BM25 och välja en algoritm per index. | 0 < 1.00 |
Både BM25 och Classic är TF-IDF-liknande hämtningsfunktioner som använder termfrekvensen (TF) och den omvända dokumentfrekvensen (IDF) som variabler för att beräkna relevanspoäng för varje dokumentfrågepar, som sedan används för rangordningsresultat. Även om BM25 konceptuellt liknar klassiskt är det rotat i probabilistisk informationshämtning som ger mer intuitiva matchningar, mätt i användarforskning.
BM25 erbjuder avancerade anpassningsalternativ, till exempel att låta användaren bestämma hur relevanspoängen skalar med termfrekvensen för matchade termer. Mer information finns i Konfigurera bedömningsalgoritmen.
Kommentar
Om du använder en söktjänst som skapades före juli 2020 är bedömningsalgoritmen troligen den tidigare standardinställningen, ClassicSimilarity, som du kan uppgradera per index. Mer information finns i Aktivera BM25-poängsättning för äldre tjänster .
Följande videosegment snabbsnabbas till en förklaring av de allmänt tillgängliga rankningsalgoritmerna som används i Azure AI Search. Du kan titta på hela videon för mer bakgrund.
Så här fungerar BM25-rankning
Relevansbedömning refererar till beräkningen av en sökpoäng (@search.score) som fungerar som en indikator på ett objekts relevans i kontexten för den aktuella frågan. Intervallet är obundet. Men ju högre poäng, desto mer relevant är objektet.
Sökpoängen beräknas baserat på statistiska egenskaper för strängindata och själva frågan. Azure AI Search hittar dokument som matchar söktermer (vissa eller alla, beroende på searchMode), vilket gynnar dokument som innehåller många instanser av söktermen. Sökpoängen ökar ännu högre om termen är sällsynt i dataindexet, men vanlig i dokumentet. Grunden för den här metoden för databehandlingsrelevans kallas TF-IDF eller termfrekvens-inverterad dokumentfrekvens.
Sökresultat kan upprepas i en resultatuppsättning. När flera träffar har samma sökpoäng är ordningen på samma poängsatta objekt odefinierad och inte stabil. Kör frågan igen och du kan se objekt flytta position, särskilt om du använder den kostnadsfria tjänsten eller en fakturerbar tjänst med flera repliker. Med tanke på två objekt med en identisk poäng finns det ingen garanti för att en visas först.
Om du vill bryta oavgjort mellan upprepade poäng kan du lägga till en $orderby-sats i första ordningen efter poäng och sedan sortera efter ett annat sorterbart fält (till exempel $orderby=search.score() desc,Rating desc). Mer information finns i $orderby.
Endast fält som är markerade som searchable i indexet eller searchFields i frågan används för bedömning. Endast fält som har markerats som retrievable, eller fält som anges i select frågan, returneras i sökresultaten, tillsammans med deras sökpoäng.
Kommentar
A @search.score = 1 anger en resultatuppsättning som inte är poängsatt eller orankad. Poängen är enhetlig för alla resultat. Resultat som inte är poängsatta uppstår när frågeformuläret är fuzzy-sökning, jokertecken- eller regex-frågor eller en tom sökning (search=*ibland parat med filter, där filtret är det primära sättet att returnera en matchning).
Poäng i ett textresultat
När resultaten rangordnas @search.score innehåller egenskapen det värde som används för att sortera resultaten.
I följande tabell identifieras den bedömningsegenskap som returneras för varje matchning, algoritm och intervall.
| Sökmetod | Parameter | Bedömningsalgoritm | Intervall |
|---|---|---|---|
| fulltextsökning | @search.score |
BM25-algoritm med hjälp av de parametrar som anges i indexet. | Obegränsad. |
Poängvariant
Sökpoäng förmedlar en allmän relevanskänsla som återspeglar matchningens styrka i förhållande till andra dokument i samma resultatuppsättning. Men poängen är inte alltid konsekventa från en fråga till en annan, så när du arbetar med frågor kanske du ser små skillnader i hur sökdokument sorteras. Det finns flera förklaringar till varför detta kan inträffa.
| Orsak | beskrivning |
|---|---|
| Identiska poäng | Om flera dokument har samma poäng kan någon av dem visas först. |
| Datavolatilitet | Indexinnehållet varierar när du lägger till, ändrar eller tar bort dokument. Termfrekvenser ändras när indexuppdateringar bearbetas över tid, vilket påverkar sökpoängen för matchande dokument. |
| Flera repliker | För tjänster som använder flera repliker utfärdas frågor mot varje replik parallellt. Indexstatistiken som används för att beräkna en sökpoäng beräknas per replik, med resultat sammanfogade och ordnade i frågesvaret. Repliker är mestadels speglingar av varandra, men statistiken kan skilja sig åt på grund av små skillnader i tillstånd. En replik kan till exempel ha tagit bort dokument som bidrar till deras statistik, som har sammanfogats från andra repliker. Vanligtvis är skillnaderna i statistik per replik mer märkbara i mindre index. Följande avsnitt innehåller mer information om det här villkoret. |
Horisontell partitioneringseffekter på frågeresultat
En shard är ett segment av ett index. Azure AI Search delar upp ett index i shards för att göra processen med att lägga till partitioner snabbare (genom att flytta shards till nya sökenheter). I en söktjänst är shardhantering en implementeringsinformation och kan inte konfigureras, men att veta att ett index är fragmenterat hjälper till att förstå tillfälliga avvikelser i rangordnings- och automatisk kompletteringsbeteenden:
Rankningsavvikelser: Sökpoäng beräknas först på shardnivå och aggregeras sedan till en enda resultatuppsättning. Beroende på egenskaperna för shardinnehåll kan matchningar från en shard rangordnas högre än matchningar i en annan. Om du ser intuitiva räknare i sökresultat beror det troligtvis på effekterna av horisontell partitionering, särskilt om indexen är små. Du kan undvika dessa rankningsavvikelser genom att välja att beräkna poäng globalt i hela indexet, men detta medför en prestandastraff.
Autokomplettera avvikelser: Komplettera automatiskt frågor, där matchningar görs på de första flera tecknen i en delvis angiven term, accepterar en fuzzy-parameter som förlåter små avvikelser i stavning. För automatisk komplettering begränsas fuzzy-matchning till termer inom den aktuella sharden. Om en shard till exempel innehåller "Microsoft" och en partiell term för "mikro" anges matchar sökmotorn "Microsoft" i fragmentet, men inte i andra shards som innehåller de återstående delarna av indexet.
Följande diagram visar relationen mellan repliker, partitioner, fragment och sökenheter. Den visar ett exempel på hur ett enda index sträcker sig över fyra sökenheter i en tjänst med två repliker och två partitioner. Var och en av de fyra sökenheterna lagrar bara hälften av indexets fragment. Sökenheterna i den vänstra kolumnen lagrar den första halvan av fragmenten, som består av den första partitionen, medan de i den högra kolumnen lagrar den andra halvan av fragmenten, som består av den andra partitionen. Eftersom det finns två repliker finns det två kopior av varje indexshard. Sökenheterna på den översta raden lagrar en kopia, bestående av den första repliken, medan de på den nedre raden lagrar en annan kopia, som består av den andra repliken.
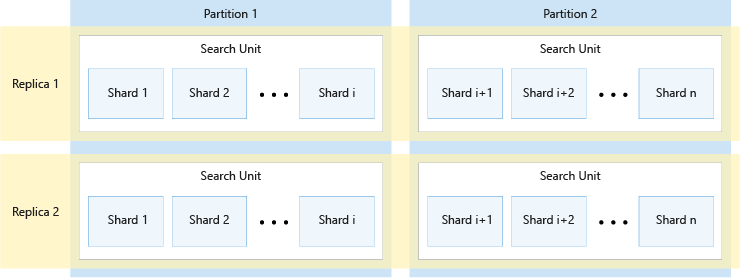
Diagrammet ovan är bara ett exempel. Många kombinationer av partitioner och repliker är möjliga, upp till högst 36 totala sökenheter.
Kommentar
Antalet repliker och partitioner delas upp jämnt i 12 (specifikt 1, 2, 3, 4, 6, 12). Azure AI Search delar upp varje index i 12 shards så att det kan spridas i lika delar över alla partitioner. Om din tjänst till exempel har tre partitioner och du skapar ett index, innehåller varje partition fyra shards av indexet. Hur Azure AI Search fragmentar ett index är en implementeringsinformation som kan komma att ändras i framtida versioner. Även om antalet är 12 i dag bör du inte förvänta dig att det talet alltid ska vara 12 i framtiden.
Poängstatistik och klibbiga sessioner
För skalbarhet distribuerar Azure AI Search varje index horisontellt genom en horisontell partitioneringsprocess, vilket innebär att delar av ett index är fysiskt åtskilda.
Som standard beräknas poängen för ett dokument baserat på statistiska egenskaper för data i ett fragment. Den här metoden är vanligtvis inte ett problem för en stor mängd data och ger bättre prestanda än att behöva beräkna poängen baserat på information över alla shards. Med den här prestandaoptimeringen kan det dock leda till att två mycket liknande dokument (eller till och med identiska dokument) får olika relevanspoäng om de hamnar i olika fragment.
Om du föredrar att beräkna poängen baserat på de statistiska egenskaperna för alla shards kan du göra det genom att lägga till scoringStatistics=global som en frågeparameter (eller lägga till "scoringStatistics": "global" som en brödtextparameter för frågebegäran).
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
Om du använder scoringStatistics ser du till att alla shards i samma replik ger samma resultat. Med det sagt kan olika repliker skilja sig något från varandra eftersom de alltid uppdateras med de senaste ändringarna i ditt index. I vissa scenarier kanske du vill att användarna ska få mer konsekventa resultat under en "frågesession". I sådana scenarier kan du ange en som en sessionId del av dina frågor. sessionId är en unik sträng som du skapar för att referera till en unik användarsession.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
Så länge samma sessionId sak används görs ett bästa försök att rikta in sig på samma replik, vilket ökar konsekvensen för de resultat som användarna ser.
Kommentar
Återanvändning av samma sessionId värden upprepade gånger kan störa belastningsutjämningen av begäranden mellan repliker och påverka söktjänstens prestanda negativt. Värdet som används som sessionId kan inte börja med ett _-tecken.
Relevansjustering
I Azure AI Search kan du konfigurera BM25-algoritmparametrar och justera sökrelevans och öka sökpoängen genom följande mekanismer:
| Metod | Implementering | beskrivning |
|---|---|---|
| Bedömningsalgoritmkonfiguration | Sökindex | |
| Poängprofiler | Sökindex | Ange kriterier för att öka sökpoängen för en matchning baserat på innehållsegenskaper. Du kanske till exempel vill öka matchningar baserat på deras intäktspotential, höja upp nyare objekt eller kanske öka objekt som har varit i lager för länge. En bedömningsprofil är en del av indexdefinitionen, som består av viktade fält, funktioner och parametrar. Du kan uppdatera ett befintligt index med bedömningsprofiländringar utan att behöva återskapa ett index. |
| Semantisk rankning | Frågebegäran | Använder maskinläsningsförståelse för sökresultat och främjar mer semantiskt relevanta resultat överst. |
| featuresMode-parameter | Frågebegäran | Den här parametern används främst för att packa upp en poäng, men den kan användas för i kod som tillhandahåller en anpassad bedömningslösning. |
featuresMode-parameter (förhandsversion)
Begäranden om sökdokument stöder en featuresMode-parameter som ger mer information om en relevanspoäng på fältnivå. @searchScore Medan är beräknat för dokumentets all-up (hur relevant är det här dokumentet i samband med den här frågan), visar featuresMode information om enskilda fält, som uttrycks i en @search.features struktur. Strukturen innehåller alla fält som används i frågan (antingen specifika fält via sökfält i en fråga eller alla fält som tillskrivs som sökbara i ett index).
För varje fält @search.features ger du följande värden:
- Antal unika token som finns i fältet
- Likhetspoäng, eller ett mått på hur likt innehållet i fältet är, i förhållande till frågetermen
- Termfrekvens eller antalet gånger som frågetermen hittades i fältet
För en fråga som riktar sig mot fälten "description" och "title" kan ett svar som innehåller @search.features se ut så här:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
Du kan använda dessa datapunkter i anpassade bedömningslösningar eller använda informationen för att felsöka problem med sökrelevans.
Parametern featuresMode finns inte dokumenterad i REST-API:erna, men du kan använda den vid ett REST API-förhandsgranskningsanrop till Sök dokument.
Antal rankade resultat i ett frågesvar i fulltext
Om du inte använder sidnumrering returnerar sökmotorn som standard de 50 högst rankade matchningarna för fulltextsökning. Du kan använda parametern top för att returnera ett mindre eller större antal objekt (upp till 1 000 i ett enda svar). Fulltextsökning omfattas av en maximal gräns på 1 000 matchningar (se API-svarsgränser). När 1 000 matchningar har hittats letar sökmotorn inte längre efter fler.
Om du vill returnera mer eller mindre resultat använder du växlingsparametrarna top, skipoch next. Växling är hur du fastställer antalet resultat på varje logisk sida och navigerar genom den fullständiga nyttolasten. Mer information finns i Så här arbetar du med sökresultat.