Förstå och justera Stream Analytics-strömningsenheter
Förstå strömningsenhet och direktuppspelningsnod
Strömningsenheter (SUs) representerar de beräkningsresurser som allokeras för att köra ett Stream Analytics-jobb. Ju fler SU:er, desto fler processor- och minnesresurser allokeras för jobbet. Med den här kapaciteten kan du fokusera på frågelogik och sammanfatta behovet av att hantera maskinvaran för att köra Stream Analytics-jobbet i rätt tid.
Azure Stream Analytics stöder två strömningsenhetsstrukturer: SU V1 (som ska vara inaktuell) och SU V2(rekommenderas).
SU V1-modellen är Azure Stream Analytics(ASA):s ursprungliga erbjudande där var 6:e SUS motsvarar en enda direktuppspelningsnod för ett jobb. Jobb kan också köras med 1 och 3 SUs och de motsvarar noder med bråkuppspelning. Skalning sker i steg om 6 fler än 6 SU-jobb, till 12, 18, 24 och senare genom att lägga till fler direktuppspelningsnoder som tillhandahåller distribuerade databehandlingsresurser.
SU V2-modellen (rekommenderas) är en förenklad struktur med bra priser för samma beräkningsresurser. I SU V2-modellen motsvarar 1 SU V2 en direktuppspelningsnod för jobbet. 2 SU V2s motsvarar 2, 3 till 3 och så vidare. Jobb med 1/3 och 2/3 SU V2s är också tillgängliga med en direktuppspelningsnod men en bråkdel av databehandlingsresurserna. 1/3- och 2/3 SU V2-jobben är ett kostnadseffektivt alternativ för arbetsbelastningar som kräver mindre skala.
Den underliggande beräkningskraften för V1- och V2-strömningsenheter är följande:
Information om SU-priser finns på sidan med priser för Azure Stream Analytics.
Förstå konverteringar av strömningsenheter och var de gäller
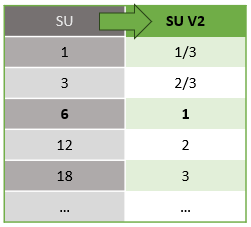
Det finns en automatisk konvertering av strömningsenheter som sker från REST API-lagret till användargränssnittet (Azure Portal och Visual Studio Code). Du ser den här konverteringen i aktivitetsloggen och där SU-värden ser annorlunda ut än värdena i användargränssnittet. Det här beteendet är avsiktligt och orsaken till det är att REST API-fält är begränsade till heltalsvärden och ASA-jobb stöder bråknoder (1/3 och 2/3 streamingenheter). ASA:s användargränssnitt visar nodvärdena 1/3, 2/3, 1, 2, 3, ... etc., medan serverdelen (aktivitetsloggar, REST API-lager) visar samma värden multiplicerat med 10 som 3, 7, 10, 20 respektive 30.
| Standard | Standard V2 (UI) | Standard V2 (serverdel, till exempel loggar, Rest API osv.) |
|---|---|---|
| 1 | 1/3 | 3 |
| 3 | 2/3 | 7 |
| 6 | 1 | 10 |
| 12 | 2 | 20 |
| 18 | 3 | 30 |
| ... | ... | ... |
Det gör att vi kan förmedla samma kornighet och eliminera decimaltecknet i API-lagret för V2-SKU:er. Den här konverteringen är automatisk och påverkar inte jobbets prestanda.
Förstå förbrukning och minnesanvändning
För att minimera svarstiderna vid bearbetningen av dataströmmar utför Azure Stream Analytics-jobb all bearbetning i minnet. När minnet börjar ta slut misslyckas strömningsjobbet. För ett produktionsjobb är det därför viktigt att övervaka resursanvändningen för ett direktuppspelningsjobb och se till att det finns tillräckligt med resurser allokerade för att hålla jobben igång dygnet innan.
Användningsmåttet SU % som sträcker sig från 0 % till 100 %, beskriver minnesförbrukningen för din arbetsbelastning. För ett direktuppspelningsjobb med minimalt fotavtryck är det här måttet vanligtvis mellan 10 % och 20 %. Om SU%-användningen är hög (över 80 %), eller om indatahändelser blir eftersläppta (även med en låg SU%-användning eftersom den inte visar CPU-användning), kräver din arbetsbelastning sannolikt fler beräkningsresurser, vilket kräver att du ökar antalet strömningsenheter. Det är bäst att hålla SU-måttet under 80 % för att ta hänsyn till tillfälliga toppar. Om du vill reagera på ökade arbetsbelastningar och öka strömningsenheterna bör du överväga att ange en avisering på 80 % för måttet SU-användning. Du kan också använda mått för vattenstämpelfördröjning och eftersläppta händelser för att se om det finns en påverkan.
Konfigurera Stream Analytics-strömningsenheter (SUS)
Logga in på Azure-portalen.
I listan över resurser hittar du det Stream Analytics-jobb som du vill skala och öppnar det sedan.
På jobbsidan går du till rubriken Konfigurera och väljer Skala. Standardantalet SUS:er är 1 när du skapar ett jobb.

Välj alternativet SU i listrutan för att ange SUs för jobbet. Observera att du är begränsad till ett specifikt SU-intervall.
Du kan ändra antalet SUs som tilldelats till jobbet medan det körs. Du kan vara begränsad till att välja från en uppsättning SU-värden när jobbet körs om jobbet använder icke-partitionerade utdata. Eller har en fråga i flera steg med olika PARTITION BY-värden.
Övervaka jobbprestanda
Med hjälp av Azure Portal kan du spåra prestandarelaterade mått för ett jobb. Mer information om måttdefinitionen finns i Jobbmått för Azure Stream Analytics. Mer information om måttövervakning i portalen finns i Övervaka Stream Analytics-jobb med Azure Portal.
Beräkna det förväntade dataflödet för arbetsbelastningen. Om dataflödet är mindre än förväntat justerar du indatapartitionen, finjusterar frågan och lägger till SUs i jobbet.
Hur många SU:er behövs för ett jobb?
Om du väljer antalet nödvändiga SUS:er för ett visst jobb beror på partitionskonfigurationen för indata och frågan som definieras i jobbet. På sidan Skala kan du ange rätt antal SUS:er. Det är en bra idé att allokera fler SUS:er än vad som behövs. Stream Analytics-bearbetningsmotorn optimerar för svarstid och dataflöde på bekostnad av allokering av ytterligare minne.
I allmänhet är bästa praxis att börja med 1 SU V2 för frågor som inte använder PARTITION BY. Bestäm sedan den söta platsen med hjälp av en utvärderings- och felmetod där du ändrar antalet SUs efter att du har passerat representativa mängder data och undersökt måttet SU% Utilization. Det maximala antalet strömningsenheter som kan användas av ett Stream Analytics-jobb beror på antalet steg i frågan som definierats för jobbet och antalet partitioner i varje steg. Du kan läsa mer om gränserna här.
Mer information om hur du väljer rätt antal SUs finns på den här sidan: Skala Azure Stream Analytics-jobb för att öka dataflödet.
Kommentar
Hur många SUS som krävs för ett visst jobb beror på partitionskonfigurationen för indata och på frågan som definierats för jobbet. Du kan välja upp till din kvot i SUs för ett jobb. Information om Prenumerationskvoten för Azure Stream Analytics finns i Stream Analytics-gränser. Kontakta Microsoft Support om du vill öka antalet SU:er för dina prenumerationer utöver den här kvoten. Giltiga värden för SUs per jobb är 1/3, 2/3, 1, 2, 3 och så vidare.
Faktorer som ökar den procentuella användningen av SU:er
Temporala (tidsorienterade) frågeelement är den grundläggande uppsättningen tillståndskänsliga operatorer som tillhandahålls av Stream Analytics. Stream Analytics hanterar tillståndet för dessa åtgärder internt för användarens räkning genom att hantera minnesförbrukning, kontrollpunkter för återhämtning och tillståndsåterställning under tjänstuppgraderingar. Även om Stream Analytics hanterar tillstånden fullt ut finns det många rekommendationer för bästa praxis som användarna bör överväga.
Ett jobb med komplex frågelogik kan ha hög SU%-användning även om det inte kontinuerligt tar emot indatahändelser. Det kan inträffa efter en plötslig ökning av in- och utdatahändelser. Jobbet kan fortsätta att behålla tillståndet i minnet om frågan är komplex.
SU%-användningen kan plötsligt sjunka till 0 under en kort period innan den återgår till förväntade nivåer. Det inträffar på grund av tillfälliga fel eller systeminitierade uppgraderingar. Att öka antalet strömningsenheter för ett jobb kanske inte minskar SU%-användningen om frågan inte är helt parallell.
När du jämför användningen under en viss tidsperiod använder du mått för händelsefrekvens. Måtten InputEvents och OutputEvents visar hur många händelser som har lästs och bearbetats. Det finns mått som också anger antalet felhändelser, till exempel deserialiseringsfel. När antalet händelser per tidsenhet ökar ökar SU% i de flesta fall.
Tillståndskänslig frågelogik i temporala element
En av de unika funktionerna i Azure Stream Analytics-jobbet är att utföra tillståndskänslig bearbetning, till exempel fönsterade aggregeringar, temporala kopplingar och temporala analysfunktioner. Var och en av dessa operatorer behåller tillståndsinformation. Den maximala fönsterstorleken för dessa frågeelement är sju dagar.
Begreppet temporalfönster visas i flera Stream Analytics-frågeelement:
Fönsteraggregeringar: GRUPPERA EFTER av rullande, hoppande och glidande fönster
Temporalkopplingar: Join with DATEDIFF function (Tidsmässiga kopplingar: ANSLUT med funktionen DATEDIFF)
Temporala analysfunktioner: ISFIRST, LAST och LAG med LIMIT DURATION
Följande faktorer påverkar det minne som används (en del av måttet för strömningsenheter) av Stream Analytics-jobb:
Fönsterade aggregeringar
Det förbrukade minnet (tillståndsstorleken) för ett fönsteraggregat är inte alltid direkt proportionellt mot fönsterstorleken. I stället är det förbrukade minnet proportionellt mot datans kardinalitet eller antalet grupper i varje tidsfönster.
I följande fråga är till exempel det tal som är associerat med clusterid frågans kardinalitet.
SELECT count(*)
FROM input
GROUP BY clusterid, tumblingwindow (minutes, 5)
För att minimera eventuella problem som orsakas av hög kardinalitet i föregående fråga kan du skicka händelser till Event Hubs som partitionerats av clusteridoch skala ut frågan genom att tillåta systemet att bearbeta varje indatapartition separat med PARTITION BY enligt följande exempel:
SELECT count(*)
FROM input PARTITION BY PartitionId
GROUP BY PartitionId, clusterid, tumblingwindow (minutes, 5)
När frågan har partitionerats ut sprids den ut över flera noder. Därför minskas antalet clusterid värden som kommer in i varje nod, vilket minskar kardinaliteten för gruppen efter operator.
Event Hubs-partitioner ska partitioneras av grupperingsnyckeln för att undvika behovet av ett reduce-steg. Mer information finns i Översikt över Event Hubs.
Tidsmässiga kopplingar
Det förbrukade minnet (tillståndsstorleken) för en tidsmässig koppling är proportionellt mot antalet händelser i anslutningens tidsmässiga svängrum, vilket är händelseinmatningshastigheten multiplicerad med den virriga rumsstorleken. Med andra ord är det minne som förbrukas av kopplingar proportionellt mot DateDiff-tidsintervallet multiplicerat med genomsnittlig händelsefrekvens.
Antalet omatchade händelser i kopplingen påverkar minnesanvändningen för frågan. Följande fråga söker efter reklamannonser som genererar klick:
SELECT clicks.id
FROM clicks
INNER JOIN impressions ON impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10.
I det här exemplet är det möjligt att många annonser visas och att få personer klickar på det och att det krävs för att hålla alla händelser i tidsfönstret. Förbrukat minne beror på tidsperiodens längd och händelsens frekvens.
För att åtgärda det här beteendet skickar du händelser till Event Hubs som partitionerats av kopplingsnycklarna (ID i det här fallet) och skalar ut frågan genom att låta systemet bearbeta varje indatapartition separat med PARTITION BY enligt följande:
SELECT clicks.id
FROM clicks PARTITION BY PartitionId
INNER JOIN impressions PARTITION BY PartitionId
ON impression.PartitionId = clicks.PartitionId AND impressions.id = clicks.id AND DATEDIFF(hour, impressions, clicks) between 0 AND 10
När frågan har partitionerats ut sprids den ut över flera noder. Därför minskas antalet händelser som kommer till varje nod, vilket minskar storleken på tillståndet som sparas i kopplingsfönstret.
Temporala analysfunktioner
Det förbrukade minnet (tillståndsstorleken) för en tidsanalysfunktion är proportionellt mot händelsehastigheten multiplicerat med varaktigheten. Minnet som förbrukas av analysfunktioner är inte proportionellt mot fönsterstorleken, utan snarare partitionsantalet i varje tidsfönster.
Reparationen liknar temporal koppling. Du kan skala ut frågan med PARTITION BY.
Slut på ordningsbuffert
Användaren kan konfigurera buffertstorleken ur ordning i konfigurationsfönstret Händelseordning. Bufferten används för att lagra indata under hela fönstret och ordna om dem. Buffertens storlek är proportionell mot händelseindatahastigheten multipliceras med storleken på out-of-order-fönstret. Standardfönstrets storlek är 0.
Om du vill åtgärda överflödet av out-of-order-bufferten skalar du ut frågan med PARTITION BY. När frågan har partitionerats ut sprids den ut över flera noder. Därför minskas antalet händelser som kommer in i varje nod, vilket minskar antalet händelser i varje omordningsbuffert.
Antal indatapartitioner
Varje indatapartition för ett jobbindata har en buffert. Ju större antal indatapartitioner, desto mer resurs förbrukar jobbet. För varje strömningsenhet kan Azure Stream Analytics bearbeta ungefär 7 MB/s indata. Därför kan du optimera genom att matcha antalet Stream Analytics-strömningsenheter med antalet partitioner i händelsehubben.
Normalt räcker det med ett jobb som konfigurerats med en strömningsenhet för 1/3 för en händelsehubb med två partitioner (vilket är det minsta för händelsehubben). Om händelsehubben har fler partitioner förbrukar Stream Analytics-jobbet fler resurser, men använder inte nödvändigtvis det extra dataflöde som tillhandahålls av Event Hubs.
För ett jobb med 1 V2-strömningsenhet kan du behöva 4 eller 8 partitioner från händelsehubben. Undvik dock för många onödiga partitioner eftersom det orsakar överdriven resursanvändning. Till exempel en händelsehubb med 16 partitioner eller större i ett Stream Analytics-jobb som har en strömningsenhet.
Referensdata
Referensdata i ASA läses in i minnet för snabb sökning. Med den aktuella implementeringen behåller varje kopplingsåtgärd med referensdata en kopia av referensdata i minnet, även om du ansluter med samma referensdata flera gånger. För frågor med PARTITION BY har varje partition en kopia av referensdata, så partitionerna är helt frikopplade. Med multiplikationseffekten kan minnesanvändningen snabbt bli mycket hög om du ansluter med referensdata flera gånger med flera partitioner.
Användning av UDF-funktioner
När du lägger till en UDF-funktion läser Azure Stream Analytics in JavaScript-körningen i minnet, vilket påverkar SU%.
Nästa steg
- Skapa parallelliserbara frågor i Azure Stream Analytics
- Skala Azure Stream Analytics-jobb för att öka dataflödet
- Azure Stream Analytics-jobbmått
- Måttmått för Azure Stream Analytics-jobb
- Övervaka Stream Analytics-jobb med Azure Portal
- Analysera Stream Analytics-jobbprestanda med måttdimensioner
- Förstå och justera direktuppspelningsenheter