Introduktion till Microsoft Spark Utilities
Microsoft Spark Utilities (MSSparkUtils) är ett inbyggt paket som hjälper dig att enkelt utföra vanliga uppgifter. Du kan använda MSSparkUtils för att arbeta med filsystem, hämta miljövariabler, länka ihop notebook-filer och arbeta med hemligheter. MSSparkUtils finns i PySpark (Python), Scala, .NET Spark (C#)och R (Preview) notebook-filer och Synapse-pipelines.
Förutsättningar
Konfigurera åtkomst till Azure Data Lake Storage Gen2
Synapse-notebook-filer använder Microsoft Entra-direkt för att få åtkomst till ADLS Gen2-kontona. Du måste vara en Storage Blob Data-deltagare för att få åtkomst till ADLS Gen2-kontot (eller mappen).
Synapse-pipelines använder arbetsytans hanterade tjänstidentitet (MSI) för att komma åt lagringskontona. Om du vill använda MSSparkUtils i dina pipelineaktiviteter måste din arbetsyteidentitet vara Storage Blob Data-deltagare för att få åtkomst till ADLS Gen2-kontot (eller mappen).
Följ de här stegen för att se till att ditt Microsoft Entra-ID och din arbetsytas MSI har åtkomst till ADLS Gen2-kontot:
Öppna Azure Portal och det lagringskonto som du vill komma åt. Du kan navigera till den specifika container som du vill komma åt.
Välj Åtkomstkontroll (IAM) på den vänstra panelen.
Klicka på Lägg till>Lägg till rolltilldelning för att öppna sidan Lägg till rolltilldelning.
Tilldela följande roll. Läs mer om att tilldela roller i Tilldela Azure-roller via Azure Portal.
Inställning Värde Roll Storage blobb data-deltagare Tilldela åtkomst till USER och MANAGEDIDENTITY Medlemmar ditt Microsoft Entra-konto och din arbetsyteidentitet Kommentar
Namnet på den hanterade identiteten är också arbetsytans namn.

Välj Spara.
Du kan komma åt data på ADLS Gen2 med Synapse Spark via följande URL:
abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<path>
Konfigurera åtkomst till Azure Blob Storage
Synapse använder signatur för delad åtkomst (SAS) för åtkomst till Azure Blob Storage. För att undvika att exponera SAS-nycklar i koden rekommenderar vi att du skapar en ny länkad tjänst i Synapse-arbetsytan till det Azure Blob Storage-konto som du vill komma åt.
Följ dessa steg för att lägga till en ny länkad tjänst för ett Azure Blob Storage-konto:
- Öppna Azure Synapse Studio.
- Välj Hantera i den vänstra panelen och välj Länkade tjänster under Externa anslutningar.
- Sök i Azure Blob Storage i panelen Ny länkad tjänst till höger.
- Välj Fortsätt.
- Välj Azure Blob Storage-kontot för att komma åt och konfigurera det länkade tjänstnamnet. Föreslå att du använder kontonyckeln för autentiseringsmetoden.
- Välj Testa anslutning för att verifiera att inställningarna är korrekta.
- Välj Skapa först och klicka på Publicera alla för att spara ändringarna.
Du kan komma åt data i Azure Blob Storage med Synapse Spark via följande URL:
wasb[s]://<container_name>@<storage_account_name>.blob.core.windows.net/<path>
Här är ett kodexempel:
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
val blob_account_name = "" // replace with your blob name
val blob_container_name = "" //replace with your container name
val blob_relative_path = "/" //replace with your relative folder path
val linked_service_name = "" //replace with your linked service name
val blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
val wasbs_path = f"wasbs://$blob_container_name@$blob_account_name.blob.core.windows.net/$blob_relative_path"
spark.conf.set(f"fs.azure.sas.$blob_container_name.$blob_account_name.blob.core.windows.net",blob_sas_token)
var blob_account_name = ""; // replace with your blob name
var blob_container_name = ""; // replace with your container name
var blob_relative_path = ""; // replace with your relative folder path
var linked_service_name = ""; // replace with your linked service name
var blob_sas_token = Credentials.GetConnectionStringOrCreds(linked_service_name);
spark.Conf().Set($"fs.azure.sas.{blob_container_name}.{blob_account_name}.blob.core.windows.net", blob_sas_token);
var wasbs_path = $"wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}";
Console.WriteLine(wasbs_path);
# Azure storage access info
blob_account_name <- 'Your account name' # replace with your blob name
blob_container_name <- 'Your container name' # replace with your container name
blob_relative_path <- 'Your path' # replace with your relative folder path
linked_service_name <- 'Your linked service name' # replace with your linked service name
blob_sas_token <- mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
sparkR.session()
wasb_path <- sprintf('wasbs://%s@%s.blob.core.windows.net/%s',blob_container_name, blob_account_name, blob_relative_path)
sparkR.session(sprintf('fs.azure.sas.%s.%s.blob.core.windows.net',blob_container_name, blob_account_name), blob_sas_token)
print( paste('Remote blob path: ',wasb_path))
Konfigurera åtkomst till Azure Key Vault
Du kan lägga till ett Azure Key Vault som en länkad tjänst för att hantera dina autentiseringsuppgifter i Synapse. Följ de här stegen för att lägga till ett Azure Key Vault som en länkad Synapse-tjänst:
Välj Hantera i den vänstra panelen och välj Länkade tjänster under Externa anslutningar.
Sök i Azure Key Vault i panelen Ny länkad tjänst till höger.
Välj Azure Key Vault-kontot för att komma åt och konfigurera det länkade tjänstnamnet.
Välj Testa anslutning för att verifiera att inställningarna är korrekta.
Välj Skapa först och klicka på Publicera alla för att spara ändringen.
Synapse-notebook-filer använder Microsoft Entra-direkt för att få åtkomst till Azure Key Vault. Synapse-pipelines använder arbetsyteidentitet (MSI) för att få åtkomst till Azure Key Vault. För att se till att koden fungerar både i notebook-filen och i Synapse-pipelinen rekommenderar vi att du beviljar behörighet till hemlig åtkomst för både ditt Microsoft Entra-konto och din arbetsyteidentitet.
Följ dessa steg för att ge hemlig åtkomst till din arbetsyteidentitet:
- Öppna Azure Portal och det Azure Key Vault som du vill komma åt.
- Välj Åtkomstprinciper i den vänstra panelen.
- Välj Lägg till åtkomstprincip:
- Välj Nyckel, Hemlighet och Certifikathantering som konfigurationsmall.
- Välj ditt Microsoft Entra-konto och din arbetsyteidentitet (samma som namnet på arbetsytan) i det valda huvudkontot eller kontrollera att det redan har tilldelats.
- Välj Välj och lägg till.
- Välj knappen Spara för att checka in ändringar.
Filsystemverktyg
mssparkutils.fs tillhandahåller verktyg för att arbeta med olika filsystem, inklusive Azure Data Lake Storage Gen2 (ADLS Gen2) och Azure Blob Storage. Se till att du konfigurerar åtkomsten till Azure Data Lake Storage Gen2 och Azure Blob Storage på rätt sätt.
Kör följande kommandon för en översikt över tillgängliga metoder:
from notebookutils import mssparkutils
mssparkutils.fs.help()
mssparkutils.fs.help()
using Microsoft.Spark.Extensions.Azure.Synapse.Analytics.Notebook.MSSparkUtils;
FS.Help()
library(notebookutils)
mssparkutils.fs.help()
Resulterar i:
mssparkutils.fs provides utilities for working with various FileSystems.
Below is overview about the available methods:
cp(from: String, to: String, recurse: Boolean = false): Boolean -> Copies a file or directory, possibly across FileSystems
mv(src: String, dest: String, create_path: Boolean = False, overwrite: Boolean = False): Boolean -> Moves a file or directory, possibly across FileSystems
ls(dir: String): Array -> Lists the contents of a directory
mkdirs(dir: String): Boolean -> Creates the given directory if it does not exist, also creating any necessary parent directories
put(file: String, contents: String, overwrite: Boolean = false): Boolean -> Writes the given String out to a file, encoded in UTF-8
head(file: String, maxBytes: int = 1024 * 100): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8
append(file: String, content: String, createFileIfNotExists: Boolean): Boolean -> Append the content to a file
rm(dir: String, recurse: Boolean = false): Boolean -> Removes a file or directory
Use mssparkutils.fs.help("methodName") for more info about a method.
Lista filer
Visa en lista över innehållet i en katalog.
mssparkutils.fs.ls('Your directory path')
mssparkutils.fs.ls("Your directory path")
FS.Ls("Your directory path")
mssparkutils.fs.ls("Your directory path")
Visa filegenskaper
Returnerar filegenskaper som filnamn, filsökväg, filstorlek, filändringstid och om det är en katalog och en fil.
files = mssparkutils.fs.ls('Your directory path')
for file in files:
print(file.name, file.isDir, file.isFile, file.path, file.size, file.modifyTime)
val files = mssparkutils.fs.ls("/")
files.foreach{
file => println(file.name,file.isDir,file.isFile,file.size,file.modifyTime)
}
var Files = FS.Ls("/");
foreach(var File in Files) {
Console.WriteLine(File.Name+" "+File.IsDir+" "+File.IsFile+" "+File.Size);
}
files <- mssparkutils.fs.ls("/")
for (file in files) {
writeLines(paste(file$name, file$isDir, file$isFile, file$size, file$modifyTime))
}
Skapa ny katalog
Skapar den angivna katalogen om den inte finns och eventuella nödvändiga överordnade kataloger.
mssparkutils.fs.mkdirs('new directory name')
mssparkutils.fs.mkdirs("new directory name")
FS.Mkdirs("new directory name")
mssparkutils.fs.mkdirs("new directory name")
Kopiera fil
Kopierar en fil eller katalog. Stöder kopiering mellan filsystem.
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)# Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
FS.Cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)
Performant copy-fil
Den här metoden ger ett snabbare sätt att kopiera eller flytta filer, särskilt stora mängder data.
mssparkutils.fs.fastcp('source file or directory', 'destination file or directory', True) # Set the third parameter as True to copy all files and directories recursively
Kommentar
Metoden stöder endast i Azure Synapse Runtime för Apache Spark 3.3 och Azure Synapse Runtime för Apache Spark 3.4.
Förhandsgranska filinnehåll
Returnerar upp till de första "maxBytes"-byteen för den angivna filen som en strängkodad i UTF-8.
mssparkutils.fs.head('file path', maxBytes to read)
mssparkutils.fs.head("file path", maxBytes to read)
FS.Head("file path", maxBytes to read)
mssparkutils.fs.head('file path', maxBytes to read)
Flytta fil
Flyttar en fil eller katalog. Stöder flytt mellan filsystem.
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
mssparkutils.fs.mv("source file or directory", "destination directory", true) // Set the last parameter as True to firstly create the parent directory if it does not exist
FS.Mv("source file or directory", "destination directory", true)
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
Skrivfil
Skriver ut den angivna strängen till en fil, kodad i UTF-8.
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
FS.Put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
Lägga till innehåll i en fil
Lägger till den angivna strängen i en fil, kodad i UTF-8.
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path","content to append",true) // Set the last parameter as True to create the file if it does not exist
FS.Append("file path", "content to append", true) // Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
Kommentar
mssparkutils.fs.append()ochmssparkutils.fs.put()stöder inte samtidig skrivning till samma fil på grund av brist på atomicitetsgarantier.- När du använder API:et
mssparkutils.fs.appendi enforloop för att skriva till samma fil rekommenderar vi att du lägger till ensleepinstruktion runt 0,5s~1s mellan de återkommande skrivningarna. Detta beror på attmssparkutils.fs.appendAPI:ets internaflushåtgärd är asynkron, så en kort fördröjning bidrar till att säkerställa dataintegriteten.
Ta bort fil eller katalog
Tar bort en fil eller en katalog.
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
FS.Rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
Verktyg för notebook-filer
Stöds ej.
Du kan använda MSSparkUtils Notebook Utilities för att köra en notebook-fil eller avsluta en notebook-fil med ett värde. Kör följande kommando för att få en översikt över tillgängliga metoder:
mssparkutils.notebook.help()
Hämta resultat:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Kommentar
Notebook-verktyg gäller inte för Apache Spark-jobbdefinitioner (SJD).
Referera till en notebook-fil
Referera till en notebook-fil och returnerar dess slutvärde. Du kan köra kapslingsfunktionsanrop i en notebook-fil interaktivt eller i en pipeline. Den notebook-fil som refereras körs i Spark-poolen där notebook-filen anropar den här funktionen.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Till exempel:
mssparkutils.notebook.run("folder/Sample1", 90, {"input": 20 })
När körningen är klar visas en ögonblicksbildslänk med namnet "Visa notebook-körning: Notebook-namn" som visas i cellutdata. Du kan klicka på länken för att se ögonblicksbilden för den här specifika körningen.

Referenskörning av flera notebook-filer parallellt
Med metoden mssparkutils.notebook.runMultiple() kan du köra flera notebook-filer parallellt eller med en fördefinierad topologisk struktur. API:et använder en mekanism för implementering av flera trådar i en Spark-session, vilket innebär att beräkningsresurserna delas av referensanteckningsbokens körningar.
Med mssparkutils.notebook.runMultiple()kan du:
Kör flera notebook-filer samtidigt, utan att vänta på att var och en ska slutföras.
Ange beroenden och körningsordning för dina notebook-filer med hjälp av ett enkelt JSON-format.
Optimera användningen av Spark-beräkningsresurser och minska kostnaden för dina Synapse-projekt.
Visa ögonblicksbilder av varje notebook-körningspost i utdata och felsöka/övervaka dina notebook-uppgifter på ett bekvämt sätt.
Hämta slutvärdet för varje verkställande aktivitet och använd dem i underordnade uppgifter.
Du kan också försöka köra mssparkutils.notebook.help("runMultiple") för att hitta exemplet och den detaljerade användningen.
Här är ett enkelt exempel på hur du kör en lista över notebook-filer parallellt med den här metoden:
mssparkutils.notebook.runMultiple(["NotebookSimple", "NotebookSimple2"])
Körningsresultatet från rotanteckningsboken är följande:

Följande är ett exempel på hur du kör notebook-filer med topologisk struktur med hjälp av mssparkutils.notebook.runMultiple(). Använd den här metoden för att enkelt orkestrera notebook-filer via en kodupplevelse.
# run multiple notebooks with parameters
DAG = {
"activities": [
{
"name": "NotebookSimple", # activity name, must be unique
"path": "NotebookSimple", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"p1": "changed value", "p2": 100}, # notebook parameters
},
{
"name": "NotebookSimple2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 2", "p2": 200}
},
{
"name": "NotebookSimple2.2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 3", "p2": 300},
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["NotebookSimple"] # list of activity names that this activity depends on
}
]
}
mssparkutils.notebook.runMultiple(DAG)
Kommentar
- Metoden stöder endast i Azure Synapse Runtime för Apache Spark 3.3 och Azure Synapse Runtime för Apache Spark 3.4.
- Parallellitetsgraden för flera notebook-körningar är begränsad till den totala tillgängliga beräkningsresursen för en Spark-session.
Avsluta en notebook-fil
Avslutar en notebook-fil med ett värde. Du kan köra kapslingsfunktionsanrop i en notebook-fil interaktivt eller i en pipeline.
När du anropar en exit() -funktion från en notebook-fil interaktivt utlöser Azure Synapse ett undantag, hoppar över att köra underfrågor och håller Spark-sessionen vid liv.
När du dirigerar en notebook-fil som anropar en
exit()funktion i en Synapse-pipeline returnerar Azure Synapse ett slutvärde, slutför pipelinekörningen och stoppar Spark-sessionen.När du anropar en
exit()funktion i en notebook-fil som refereras kommer Azure Synapse att stoppa den ytterligare körningen i notebook-filen som refereras och fortsätta att köra nästa celler i anteckningsboken som anroparrun()funktionen. Till exempel: Notebook1 har tre celler och anropar enexit()funktion i den andra cellen. Notebook2 har fem celler och anroprun(notebook1)i den tredje cellen. När du kör Notebook2 stoppas Notebook1 i den andra cellen när du trycker påexit()funktionen. Notebook2 fortsätter att köra sin fjärde cell och femte cell.
mssparkutils.notebook.exit("value string")
Till exempel:
Sample1 Notebook finns under mapp/ med följande två celler:
- cell 1 definierar en indataparameter med standardvärdet inställt på 10.
- cell 2 avslutar notebook-filen med indata som utgångsvärde.
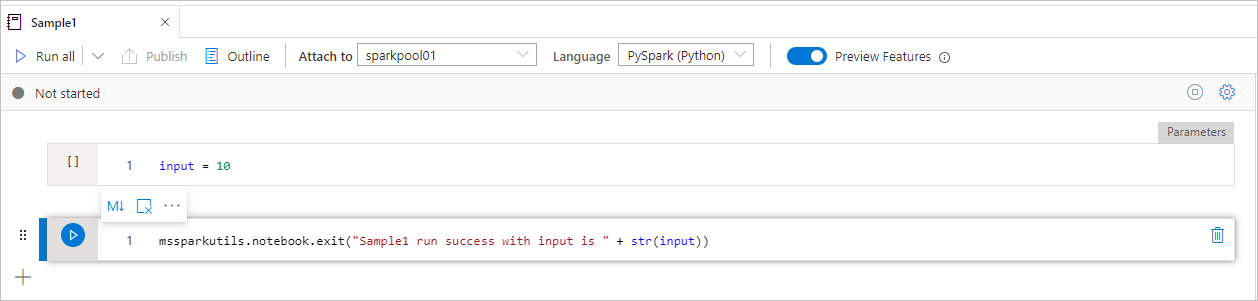
Du kan köra Sample1 i en annan notebook-fil med standardvärden:
exitVal = mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Resulterar i:
Sample1 run success with input is 10
Du kan köra Sample1 i en annan notebook-fil och ange indatavärdet som 20:
exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print (exitVal)
Resulterar i:
Sample1 run success with input is 20
Du kan använda MSSparkUtils Notebook Utilities för att köra en notebook-fil eller avsluta en notebook-fil med ett värde. Kör följande kommando för att få en översikt över tillgängliga metoder:
mssparkutils.notebook.help()
Hämta resultat:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Referera till en notebook-fil
Referera till en notebook-fil och returnerar dess slutvärde. Du kan köra kapslingsfunktionsanrop i en notebook-fil interaktivt eller i en pipeline. Den notebook-fil som refereras körs i Spark-poolen där notebook-filen anropar den här funktionen.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Till exempel:
mssparkutils.notebook.run("folder/Sample1", 90, Map("input" -> 20))
När körningen är klar visas en ögonblicksbildslänk med namnet "Visa notebook-körning: Notebook-namn" som visas i cellutdata. Du kan klicka på länken för att se ögonblicksbilden för den här specifika körningen.
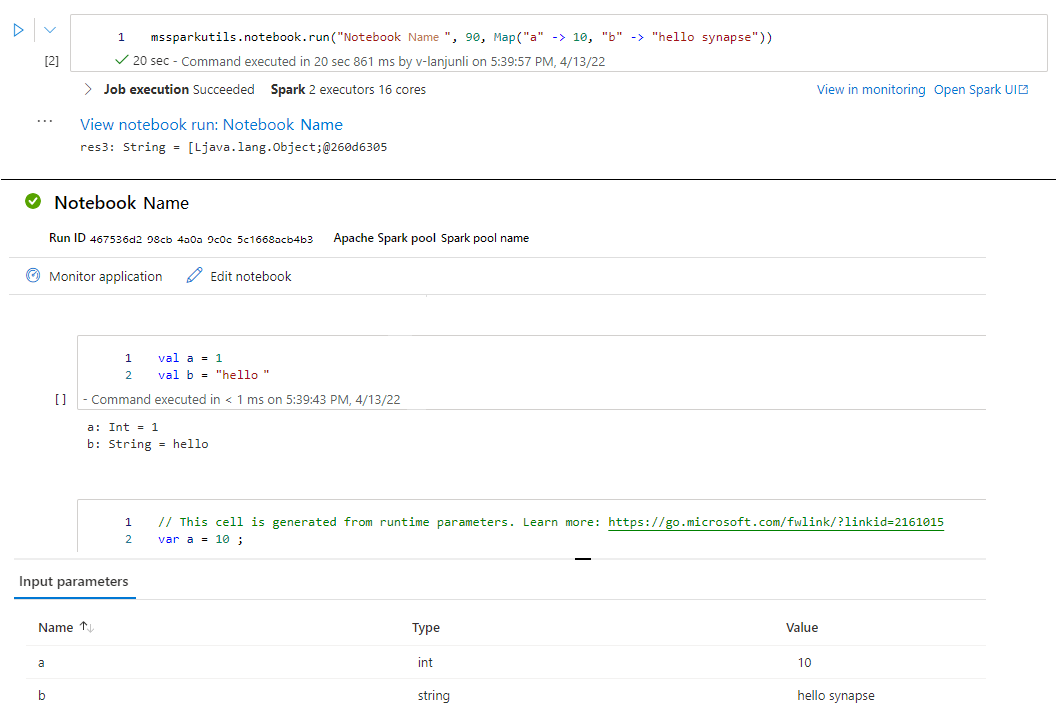
Avsluta en notebook-fil
Avslutar en notebook-fil med ett värde. Du kan köra kapslingsfunktionsanrop i en notebook-fil interaktivt eller i en pipeline.
När du anropar en
exit()funktion som en notebook-fil interaktivt utlöser Azure Synapse ett undantag, hoppar över att köra underordnade celler och håller Spark-sessionen vid liv.När du dirigerar en notebook-fil som anropar en
exit()funktion i en Synapse-pipeline returnerar Azure Synapse ett slutvärde, slutför pipelinekörningen och stoppar Spark-sessionen.När du anropar en
exit()funktion i en notebook-fil som refereras kommer Azure Synapse att stoppa den ytterligare körningen i notebook-filen som refereras och fortsätta att köra nästa celler i anteckningsboken som anroparrun()funktionen. Till exempel: Notebook1 har tre celler och anropar enexit()funktion i den andra cellen. Notebook2 har fem celler och anroprun(notebook1)i den tredje cellen. När du kör Notebook2 stoppas Notebook1 i den andra cellen när du trycker påexit()funktionen. Notebook2 fortsätter att köra sin fjärde cell och femte cell.
mssparkutils.notebook.exit("value string")
Till exempel:
Sample1 Notebook finns under mssparkutils/folder/ med följande två celler:
- cell 1 definierar en indataparameter med standardvärdet inställt på 10.
- cell 2 avslutar notebook-filen med indata som utgångsvärde.
Du kan köra Sample1 i en annan notebook-fil med standardvärden:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1")
print(exitVal)
Resulterar i:
exitVal: String = Sample1 run success with input is 10
Sample1 run success with input is 10
Du kan köra Sample1 i en annan notebook-fil och ange indatavärdet som 20:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print(exitVal)
Resulterar i:
exitVal: String = Sample1 run success with input is 20
Sample1 run success with input is 20
Du kan använda MSSparkUtils Notebook Utilities för att köra en notebook-fil eller avsluta en notebook-fil med ett värde. Kör följande kommando för att få en översikt över tillgängliga metoder:
mssparkutils.notebook.help()
Hämta resultat:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Referera till en notebook-fil
Referera till en notebook-fil och returnerar dess slutvärde. Du kan köra kapslingsfunktionsanrop i en notebook-fil interaktivt eller i en pipeline. Den notebook-fil som refereras körs i Spark-poolen där notebook-filen anropar den här funktionen.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Till exempel:
mssparkutils.notebook.run("folder/Sample1", 90, list("input": 20))
När körningen är klar visas en ögonblicksbildslänk med namnet "Visa notebook-körning: Notebook-namn" som visas i cellutdata. Du kan klicka på länken för att se ögonblicksbilden för den här specifika körningen.
Avsluta en notebook-fil
Avslutar en notebook-fil med ett värde. Du kan köra kapslingsfunktionsanrop i en notebook-fil interaktivt eller i en pipeline.
När du anropar en
exit()funktion som en notebook-fil interaktivt utlöser Azure Synapse ett undantag, hoppar över att köra underordnade celler och håller Spark-sessionen vid liv.När du dirigerar en notebook-fil som anropar en
exit()funktion i en Synapse-pipeline returnerar Azure Synapse ett slutvärde, slutför pipelinekörningen och stoppar Spark-sessionen.När du anropar en
exit()funktion i en notebook-fil som refereras kommer Azure Synapse att stoppa den ytterligare körningen i notebook-filen som refereras och fortsätta att köra nästa celler i anteckningsboken som anroparrun()funktionen. Till exempel: Notebook1 har tre celler och anropar enexit()funktion i den andra cellen. Notebook2 har fem celler och anroprun(notebook1)i den tredje cellen. När du kör Notebook2 stoppas Notebook1 i den andra cellen när du trycker påexit()funktionen. Notebook2 fortsätter att köra sin fjärde cell och femte cell.
mssparkutils.notebook.exit("value string")
Till exempel:
Sample1 Notebook finns under mapp/ med följande två celler:
- cell 1 definierar en indataparameter med standardvärdet inställt på 10.
- cell 2 avslutar notebook-filen med indata som utgångsvärde.
Du kan köra Sample1 i en annan notebook-fil med standardvärden:
exitVal <- mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Resulterar i:
Sample1 run success with input is 10
Du kan köra Sample1 i en annan notebook-fil och ange indatavärdet som 20:
exitVal <- mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, list("input": 20))
print (exitVal)
Resulterar i:
Sample1 run success with input is 20
Verktyg för autentiseringsuppgifter
Du kan använda verktygen för MSSparkUtils-autentiseringsuppgifter för att hämta åtkomsttoken för länkade tjänster och hantera hemligheter i Azure Key Vault.
Kör följande kommando för att få en översikt över tillgängliga metoder:
mssparkutils.credentials.help()
mssparkutils.credentials.help()
Not supported.
mssparkutils.credentials.help()
Hämta resultat:
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Kommentar
För närvarande stöds inte getSecretWithLS(linkedService, hemlighet) i C#.
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Hämta token
Returnerar Microsoft Entra-token för en viss målgrupp, namn (valfritt). Tabellen nedan visar alla tillgängliga målgruppstyper:
| Målgruppstyp | Strängliteral som ska användas i API-anrop |
|---|---|
| Azure Storage | Storage |
| Azure Key Vault | Vault |
| Azure-hantering | AzureManagement |
| Azure SQL Data Warehouse (dedikerad och serverlös) | DW |
| Azure Synapse | Synapse |
| Azure Data Lake Store | DataLakeStore |
| Azure Data Factory | ADF |
| Öppna Azure-datautforskaren | AzureDataExplorer |
| Azure Database for MySQL | AzureOSSDB |
| Azure-databas för MariaDB | AzureOSSDB |
| Azure Database for PostgreSQL | AzureOSSDB |
mssparkutils.credentials.getToken('audience Key')
mssparkutils.credentials.getToken("audience Key")
Credentials.GetToken("audience Key")
mssparkutils.credentials.getToken('audience Key')
Verifiera token
Returnerar true om token inte har upphört att gälla.
mssparkutils.credentials.isValidToken('your token')
mssparkutils.credentials.isValidToken("your token")
Credentials.IsValidToken("your token")
mssparkutils.credentials.isValidToken('your token')
Hämta anslutningssträng eller autentiseringsuppgifter för länkad tjänst
Returnerar anslutningssträng eller autentiseringsuppgifter för länkad tjänst.
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
mssparkutils.credentials.getConnectionStringOrCreds("linked service name")
Credentials.GetConnectionStringOrCreds("linked service name")
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
Hämta hemlighet med hjälp av arbetsyteidentitet
Returnerar Azure Key Vault-hemlighet för ett angivet Azure Key Vault-namn, hemligt namn och länkat tjänstnamn med hjälp av arbetsyteidentitet. Se till att du konfigurerar åtkomsten till Azure Key Vault på rätt sätt.
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
mssparkutils.credentials.getSecret("azure key vault name","secret name","linked service name")
Credentials.GetSecret("azure key vault name","secret name","linked service name")
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
Hämta hemlighet med användarautentiseringsuppgifter
Returnerar Azure Key Vault-hemlighet för ett angivet Azure Key Vault-namn, hemligt namn och länkat tjänstnamn med hjälp av autentiseringsuppgifter.
mssparkutils.credentials.getSecret('azure key vault name','secret name')
mssparkutils.credentials.getSecret("azure key vault name","secret name")
Credentials.GetSecret("azure key vault name","secret name")
mssparkutils.credentials.getSecret('azure key vault name','secret name')
Placera hemlighet med hjälp av arbetsyteidentitet
Placerar Azure Key Vault-hemlighet för ett visst Azure Key Vault-namn, hemligt namn och länkat tjänstnamn med hjälp av arbetsyteidentitet. Se till att du konfigurerar åtkomsten till Azure Key Vault på rätt sätt.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Placera hemlighet med hjälp av arbetsyteidentitet
Placerar Azure Key Vault-hemlighet för ett visst Azure Key Vault-namn, hemligt namn och länkat tjänstnamn med hjälp av arbetsyteidentitet. Se till att du konfigurerar åtkomsten till Azure Key Vault på rätt sätt.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value","linked service name")
Placera hemlighet med hjälp av arbetsyteidentitet
Placerar Azure Key Vault-hemlighet för ett visst Azure Key Vault-namn, hemligt namn och länkat tjänstnamn med hjälp av arbetsyteidentitet. Se till att du konfigurerar åtkomsten till Azure Key Vault på rätt sätt.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Placera hemlighet med användarautentiseringsuppgifter
Placerar Azure Key Vault-hemlighet för ett angivet Azure Key Vault-namn, hemligt namn och länkat tjänstnamn med hjälp av autentiseringsuppgifter.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Placera hemlighet med användarautentiseringsuppgifter
Placerar Azure Key Vault-hemlighet för ett angivet Azure Key Vault-namn, hemligt namn och länkat tjänstnamn med hjälp av autentiseringsuppgifter.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Placera hemlighet med användarautentiseringsuppgifter
Placerar Azure Key Vault-hemlighet för ett angivet Azure Key Vault-namn, hemligt namn och länkat tjänstnamn med hjälp av autentiseringsuppgifter.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value")
Miljöverktyg
Kör följande kommandon för att få en översikt över tillgängliga metoder:
mssparkutils.env.help()
mssparkutils.env.help()
mssparkutils.env.help()
Env.Help()
Hämta resultat:
getUserName(): returns user name
getUserId(): returns unique user id
getJobId(): returns job id
getWorkspaceName(): returns workspace name
getPoolName(): returns Spark pool name
getClusterId(): returns cluster id
Hämta användarnamn
Returnerar aktuellt användarnamn.
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
Env.GetUserName()
Hämta användar-ID
Returnerar aktuellt användar-ID.
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
Env.GetUserId()
Hämta jobb-ID
Returnerar jobb-ID.
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
Env.GetJobId()
Hämta arbetsytans namn
Returnerar arbetsytans namn.
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
Env.GetWorkspaceName()
Hämta poolnamn
Returnerar Namnet på Spark-poolen.
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
Env.GetPoolName()
Hämta kluster-ID
Returnerar aktuellt kluster-ID.
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
Env.GetClusterId()
Körningskontext
Mssparkutils runtime utils exponerade 3 körningsegenskaper, du kan använda mssparkutils-körningskontexten för att hämta egenskaperna enligt nedan:
- Notebookname – Namnet på den aktuella notebook-filen returnerar alltid värde för både interaktivt läge och pipelineläge.
- Pipelinejobid – Pipelinekörnings-ID :t returnerar värdet i pipelineläge och returnerar en tom sträng i interaktivt läge.
- Activityrunid – Körnings-ID för notebook-aktivitet, returnerar värdet i pipelineläge och returnerar en tom sträng i interaktivt läge.
För närvarande stöder körningskontext både Python och Scala.
mssparkutils.runtime.context
ctx <- mssparkutils.runtime.context()
for (key in ls(ctx)) {
writeLines(paste(key, ctx[[key]], sep = "\t"))
}
%%spark
mssparkutils.runtime.context
Sessionshantering
Stoppa en interaktiv session
I stället för att klicka på stoppknappen manuellt är det ibland enklare att stoppa en interaktiv session genom att anropa ett API i koden. I sådana fall tillhandahåller vi ett API mssparkutils.session.stop() som stöder stopp av den interaktiva sessionen via kod, det är tillgängligt för Scala och Python.
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop() API:et stoppar den aktuella interaktiva sessionen asynkront i bakgrunden, stoppar Spark-sessionen och frigör resurser som används av sessionen så att de är tillgängliga för andra sessioner i samma pool.
Kommentar
Vi rekommenderar inte att du anropar inbyggda API:er för språk, till exempel sys.exit i Scala eller sys.exit() Python i din kod, eftersom sådana API:er bara dödar tolkprocessen och lämnar Spark-sessionen vid liv och resurser inte släpps.
Paketberoenden
Om du vill utveckla notebook-filer eller jobb lokalt och behöver referera till relevanta paket för kompilering/IDE-tips kan du använda följande paket.