Vad är lagringsstrukturen för analytiska dataflöden?
Analytiska dataflöden lagrar både data och metadata i Azure Data Lake Storage. Dataflöden använder en standardstruktur för att lagra och beskriva data som skapats i sjön, som kallas Common Data Model-mappar. I den här artikeln får du lära dig mer om lagringsstandarden som dataflöden använder i bakgrunden.
Lagringen behöver en struktur för ett analytiskt dataflöde
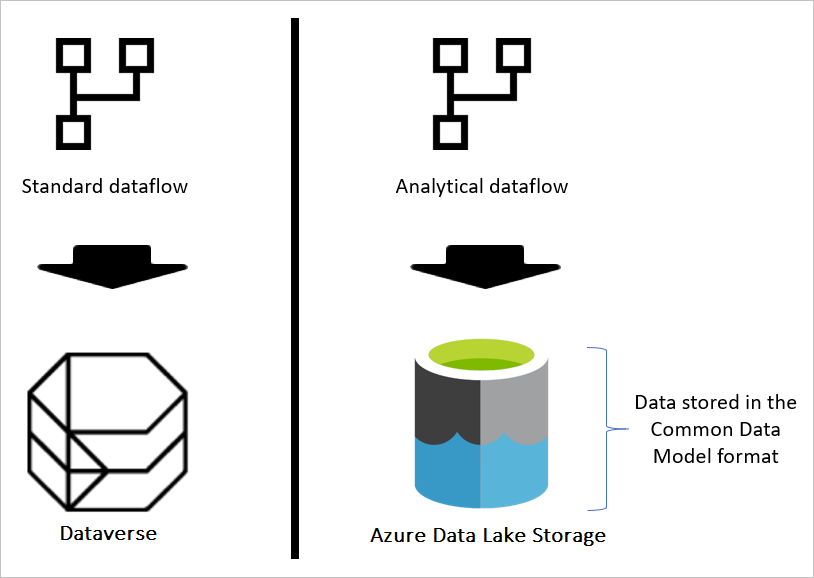
Om dataflödet är standard lagras data i Dataverse. Dataversum är som ett databassystem. den har begreppet tabeller, vyer och så vidare. Dataverse är ett strukturerat datalagringsalternativ som används av standarddataflöden.
Men när dataflödet är analytiskt lagras data i Azure Data Lake Storage. Ett dataflödes data och metadata lagras i en Common Data Model-mapp. Eftersom ett lagringskonto kan ha flera dataflöden lagrade i det, har en hierarki med mappar och undermappar introducerats för att organisera data. Beroende på vilken produkt dataflödet skapades i kan mapparna och undermapparna representera arbetsytor (eller miljöer) och sedan dataflödets Common Data Model-mapp. I mappen Common Data Model lagras både schema och data för dataflödestabellerna. Den här strukturen följer de standarder som definierats för Common Data Model.
Vad är lagringsstrukturen för Common Data Model?
Common Data Model är en metadatastruktur som definierats för att ge överensstämmelse och konsekvens för användning av data på flera plattformar. Common Data Model är inte datalagring, det är sättet som data lagras och definieras på.
Common Data Model-mappar definierar hur en tabells schema och dess data ska lagras. I Azure Data Lake Storage ordnas data i mappar. Mappar kan representera en arbetsyta eller miljö. Under dessa mappar skapas undermappar för varje dataflöde.
Vad finns i en dataflödesmapp?
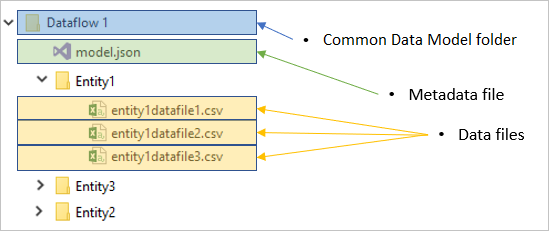
Varje dataflödesmapp innehåller en undermapp för varje tabell och en metadatafil med namnet model.json.
Metadatafilen: model.json
Filen model.json är metadatadefinitionen för dataflödet. Det här är den enda fil som innehåller alla dataflödesmetadata. Den innehåller en lista över tabeller, kolumner och deras datatyper i varje tabell, relationen mellan tabeller och så vidare. Du kan enkelt exportera den här filen från ett dataflöde, även om du inte har åtkomst till mappstrukturen Common Data Model.
Du kan använda den här JSON-filen för att migrera (eller importera) ditt dataflöde till en annan arbetsyta eller miljö.
Om du vill veta exakt vad den model.json metadatafilen innehåller går du till Metadatafilen (model.json) för Common Data Model.
Datafiler
Förutom metadatafilen innehåller dataflödesmappen andra undermappar. Ett dataflöde lagrar data för varje tabell i en undermapp med tabellens namn. Data för en tabell kan delas upp i flera datapartitioner som lagras i CSV-format.
Så här ser eller får du åtkomst till Common Data Model-mappar
Om du använder dataflöden som använder lagring som tillhandahålls av den produkt som de skapades i, har du inte åtkomst till dessa mappar direkt. I sådana fall kräver hämtar data från dataflöden med hjälp av Microsoft Power Platform-dataflödesanslutningsappen som är tillgänglig i Hämta dataupplevelse i produkterna Power BI-tjänst, Power Apps och Dynamics 35 Customer Insights, eller i Power BI Desktop.
Om du vill veta hur dataflöden och den interna Data Lake Storage-integreringen fungerar går du till Dataflöden och Azure Data Lake-integrering (förhandsversion).
Om din organisation har aktiverat dataflöden för att dra nytta av sitt Data Lake Storage-konto och har valts som inläsningsmål för dataflöden, kan du fortfarande hämta data från dataflödet med hjälp av Anslutningsappen för Power Platform-dataflöde enligt ovan. Men du kan också komma åt dataflödets Common Data Model-mapp direkt via sjön, även utanför Power Platform-verktyg och -tjänster. Åtkomst till sjön är möjlig via Azure-portalen, Microsoft Azure Storage Explorer eller någon annan tjänst eller upplevelse som stöder Azure Data Lake Storage. Mer information: Anslut Azure Data Lake Storage Gen2 för lagring av dataflöden