Öğretici: Azure İzleyici'de KQL makine öğrenmesi özelliklerini kullanarak anomalileri algılama ve analiz etme
Kusto Sorgu Dili (KQL), zaman serisi analizi, anomali algılama, tahmin ve kök neden analizi için makine öğrenmesi işleçlerini, işlevlerini ve eklentilerini içerir. Verileri dış makine öğrenmesi araçlarına aktarma yükü olmadan Azure İzleyici'de gelişmiş veri analizi gerçekleştirmek için bu KQL özelliklerini kullanın.
Bu öğreticide aşağıdakilerin nasıl yapılacağını öğreneceksiniz:
- Zaman serisi oluşturma
- Zaman serisindeki anomalileri tanımlama
- Sonuçları daraltmak için anomali algılama ayarlarını ayarlama
- Anomalilerin kök nedenini analiz etme
Not
Bu öğreticide, KQL sorgu örneklerini çalıştırabileceğiniz bir Log Analytics tanıtım ortamına bağlantılar sağlanır. Tanıtım ortamındaki veriler dinamik olduğundan, sorgu sonuçları bu makalede gösterilen sorgu sonuçlarıyla aynı değildir. Ancak, kendi ortamınızda ve KQL kullanan tüm Azure İzleyici araçlarında aynı KQL sorgularını ve sorumlularını uygulayabilirsiniz.
Önkoşullar
- Etkin aboneliği olan bir Azure hesabı. Ücretsiz hesap oluşturun.
- Günlük verilerini içeren bir çalışma alanı.
Gerekli izinler
Örneğin Log Analytics Okuyucusu yerleşik rolü tarafından sağlandığı gibi sorguladığınız Log Analytics çalışma alanları için izinlere sahip Microsoft.OperationalInsights/workspaces/query/*/read olmanız gerekir.
Zaman serisi oluşturma
Zaman serisi oluşturmak için KQL make-series işlecini kullanın.
Şimdi Kullanım tablosundaki günlükleri temel alan ve çalışma alanında her bir tablonun saatte bir ne kadar veri aldığına ilişkin bilgileri (faturalanabilir ve faturalanamayan veriler dahil) tutan bir zaman serisi oluşturalım.
Bu sorgu, son 21 gün içinde çalışma alanında her gün her tablo tarafından alınan toplam faturalanabilir veri miktarını grafik olarak kullanır make-series :
Sorguyu çalıştırmak için tıklayın
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
Sonuçta elde edilen grafikte, ve veri türlerinde AzureDiagnostics SecurityEvent bazı anomalileri açıkça görebilirsiniz:
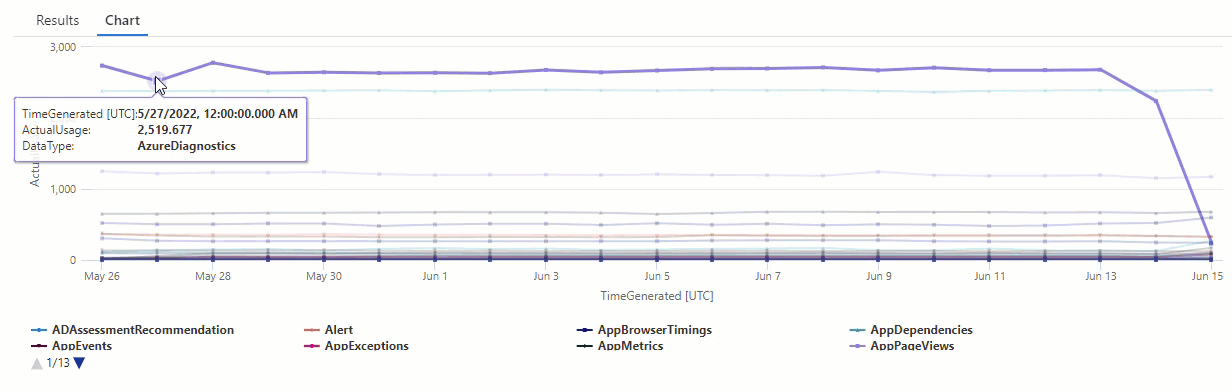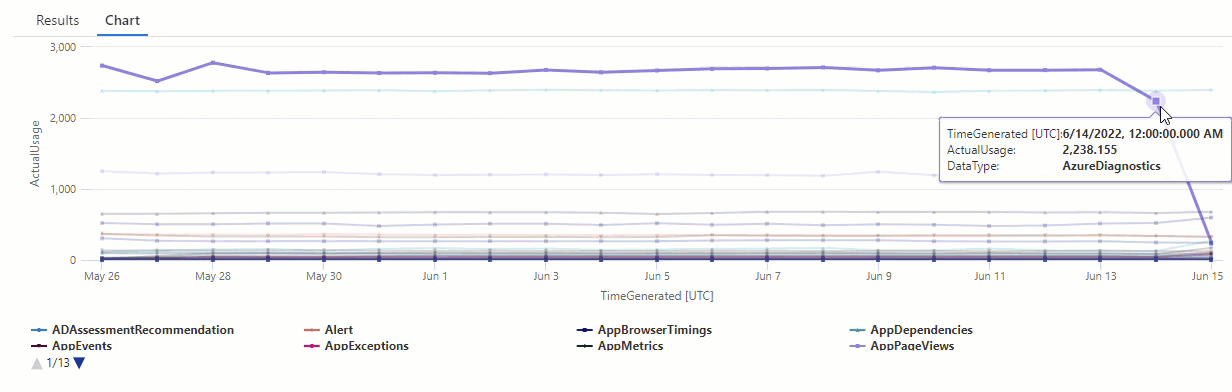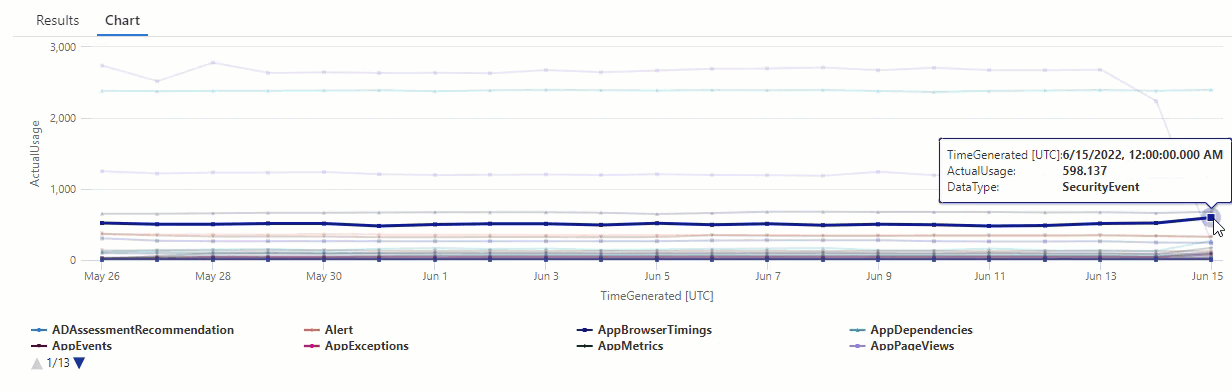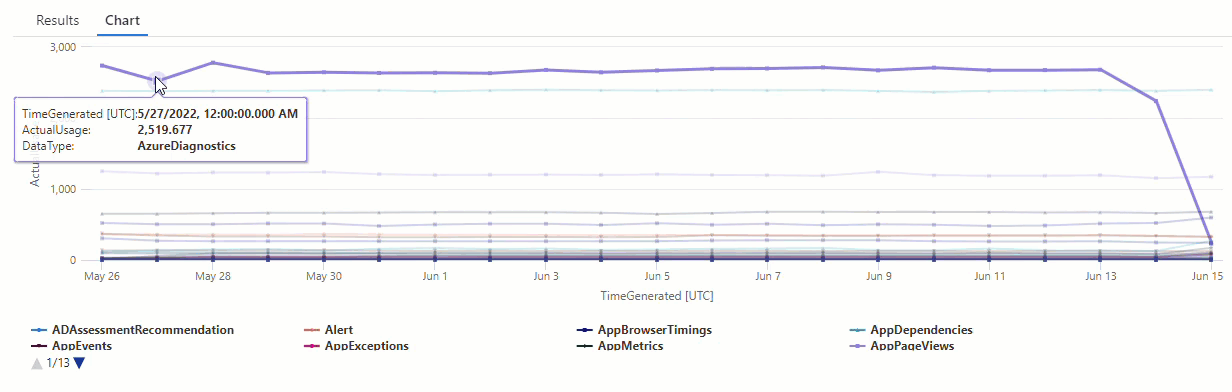
Şimdi, bir zaman serisindeki tüm anomalileri listelemek için bir KQL işlevi kullanacağız.
Not
Söz dizimi ve kullanımı hakkında make-series daha fazla bilgi için bkz . make-series işleci.
Zaman serisindeki anomalileri bulma
işlevi giriş series_decompose_anomalies() olarak bir dizi değer alır ve anomalileri ayıklar.
Zaman serisi sorgumuzun sonuç kümesini işleve series_decompose_anomalies() giriş olarak verelim:
Sorguyu çalıştırmak için tıklayın
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Bu sorgu, son üç haftadaki tüm tablolar için tüm kullanım anomalilerini döndürür:

Sorgu sonuçlarına baktığınızda işlevinin şu şekilde olduğunu görebilirsiniz:
- Her tablo için beklenen günlük kullanımı hesaplar.
- Gerçek günlük kullanımı beklenen kullanımla karşılaştırır.
- Her veri noktasına, gerçek kullanımın beklenen kullanımdan sapma kapsamını gösteren bir anomali puanı atar.
- Her tablodaki pozitif (
1) ve negatif (-1) anomalileri tanımlar.
Not
Söz dizimi ve kullanımı hakkında series_decompose_anomalies() daha fazla bilgi için bkz . series_decompose_anomalies().
Sonuçları daraltmak için anomali algılama ayarlarını ayarlama
İlk sorgu sonuçlarını gözden geçirmek ve gerekirse sorguda ayarlamalar yapmak iyi bir uygulamadır. Giriş verilerindeki aykırı değerler işlevin öğrenmesini etkileyebilir ve daha doğru sonuçlar elde etmek için işlevin anomali algılama ayarlarını ayarlamanız gerekebilir.
Veri türündeki series_decompose_anomalies() anomaliler AzureDiagnostics için sorgunun sonuçlarını filtreleyin:

Sonuçlar, 14 Haziran ve 15 Haziran'da iki anomali olduğunu göstermektedir. Bu sonuçları, 27 ve 28 Mayıs'ta diğer anomalileri görebileceğiniz ilk make-series sorgumuzdaki grafikle karşılaştırın:

Sonuçlardaki fark, işlevin series_decompose_anomalies() beklenen kullanım değerine göre anomalileri puanlamasıdır ve bu değer giriş serisindeki değerlerin tamamına göre hesaplanır.
İşlevden daha iyi sonuçlar elde etmek için, serideki diğer değerlerle karşılaştırıldığında aykırı değer olan 15 Haziran'daki kullanımı işlevin öğrenme sürecinden hariç tutun.
İşlevin series_decompose_anomalies() söz dizimi şöyledir:
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points öğrenme (regresyon) işleminin dışında tutulacak serinin sonundaki nokta sayısını belirtir.
Son veri noktasını dışlamak için olarak 1ayarlayınTest_points:
Sorguyu çalıştırmak için tıklayın
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Veri türü için sonuçları filtreleyin AzureDiagnostics :

İlk make-series sorgumuzdaki grafikteki anomalilerin tümü artık sonuç kümesinde görünür.
Anomalilerin kök nedenini analiz etme
Beklenen değerleri anormal değerlerle karşılaştırmak, iki küme arasındaki farkların nedenini anlamanıza yardımcı olur.
KQL diffpatterns() eklentisi aynı yapıdaki iki veri kümesini karşılaştırır ve iki veri kümesi arasındaki farkları karakterize eden desenler bulur.
Bu sorgu, örneğimizdeki aşırı aykırı değerler olan 15 Haziran'daki kullanımı diğer günlerdeki tablo kullanımıyla karşılaştırır AzureDiagnostics :
Sorguyu çalıştırmak için tıklayın
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
Sorgu, tablodaki her girişin AnomalyDate (15 Haziran) veya OtherDates'te gerçekleştiğini tanımlar. Eklenti diffpatterns() daha sonra A (Örneğimizdeki OtherDates) ve B (Örneğimizdeki AnomaliTarihi) adlı bu veri kümelerini böler ve iki kümedeki farklara katkıda bulunan birkaç desen döndürür:

Sorgu sonuçlarına baktığınızda aşağıdaki farkları görebilirsiniz:
- Sorgu zaman aralığındaki diğer tüm günlerde CH1-GEARAMAAKS kaynağından 24.892.147 veri alımı örneği vardır ve 15 Haziran'da bu kaynaktan veri alınmaz. CH1-GEARAMAAKS kaynağından alınan veriler, sorgu zaman aralığındaki diğer günlerde toplam alımın %73,36'sını ve 15 Haziran'da toplam alımın %0'ını oluşturur.
- Sorgu zaman aralığındaki diğer tüm günlerde NSG-TESTSQLMI519 kaynağından 2.168.448 veri alımı örneği ve 15 Haziran'da bu kaynaktan 110.544 veri alımı örneği vardır. NSG-TESTSQLMI519 kaynağından alınan veriler, sorgu zaman aralığındaki diğer günlerde toplam alımın %6,39'unu ve 15 Haziran'da alımın %25,61'ini oluşturur.
Diğer gün dönemini oluşturan 20 gün boyunca NSG-TESTSQLMI519 kaynağından ortalama olarak 108.422 alım örneği olduğuna dikkat edin (2.168.448'i 20'ye bölün). Bu nedenle, 15 Haziran'da NSG-TESTSQLMI519 kaynağından alınan alım, diğer günlerde bu kaynaktan alınan alımdan önemli ölçüde farklı değildir. Ancak 15 Haziran'da CH1-GEARAMAAKS'tan veri alımı olmadığından NSG-TESTSQLMI519 alımı, anomali tarihindeki toplam alımın diğer günlere kıyasla önemli ölçüde daha fazla yüzdesini oluşturur.
PercentDiffAB sütunu, A ile B arasındaki mutlak yüzde noktası farkını gösterir (|YüzdeA - YüzdeB|), iki küme arasındaki farkın ana ölçüsüdür. Varsayılan olarak, diffpatterns() eklenti iki veri kümesi arasında %5'in üzerinde bir fark döndürür, ancak bu eşiği değiştirebilirsiniz. Örneğin, iki veri kümesi arasında yalnızca %20 veya daha fazla fark döndürmek için yukarıdaki sorguda ayarlayabilirsiniz | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) . Sorgu artık yalnızca bir sonuç döndürür:

Not
Söz dizimi ve kullanımı hakkında diffpatterns() daha fazla bilgi için bkz . fark desenleri eklentisi.
Sonraki adımlar
Aşağıdakiler hakkında daha fazla bilgi edinin:
- Azure İzleyici'de günlük sorguları.
- Kusto sorgularını kullanma.
- KQL ile Azure İzleyici'de günlükleri analiz etme