Azure Data Factory veya Synapse Analytics kullanarak PostgreSQL için Azure Veritabanı verileri kopyalama ve dönüştürme
UYGULANANLAR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
İpucu
Kuruluşlar için hepsi bir arada analiz çözümü olan Microsoft Fabric'te Data Factory'yi deneyin. Microsoft Fabric , veri taşımadan veri bilimine, gerçek zamanlı analize, iş zekasına ve raporlamaya kadar her şeyi kapsar. Yeni bir deneme sürümünü ücretsiz olarak başlatmayı öğrenin!
Bu makalede, Azure Data Factory ve Synapse Analytics işlem hatlarında Kopyalama Etkinliğini kullanarak verileri PostgreSQL için Azure Veritabanı ve Veri Akışı kullanarak PostgreSQL için Azure Veritabanı'daki verileri dönüştürme adımları açıklanmaktadır. Daha fazla bilgi edinmek için Azure Data Factory ve Synapse Analytics'e yönelik giriş makalelerini okuyun.
Bu bağlayıcı PostgreSQL için Azure Veritabanı hizmeti için özeldir. Şirket içinde veya bulutta bulunan genel bir PostgreSQL veritabanından veri kopyalamak için PostgreSQL bağlayıcısını kullanın.
Desteklenen özellikler
Bu PostgreSQL için Azure Veritabanı bağlayıcısı aşağıdaki özellikler için desteklenir:
| Desteklenen özellikler | IR | Yönetilen özel uç nokta |
|---|---|---|
| Kopyalama etkinliği (kaynak/havuz) | (1) (2) | ✓ |
| Eşleme veri akışı (kaynak/havuz) | (1) | ✓ |
| Arama etkinliği | (1) (2) | ✓ |
(1) Azure tümleştirme çalışma zamanı (2) Şirket içinde barındırılan tümleştirme çalışma zamanı
Üç etkinlik tüm PostgreSQL için Azure Veritabanı dağıtım seçeneklerinde çalışır:
Başlarken
İşlem hattıyla Kopyalama etkinliği gerçekleştirmek için aşağıdaki araçlardan veya SDK'lardan birini kullanabilirsiniz:
- Veri Kopyalama aracı
- Azure portal
- .NET SDK'sı
- Python SDK'sı
- Azure PowerShell
- The REST API
- Azure Resource Manager şablonu
Kullanıcı arabirimini kullanarak PostgreSQL için Azure Veritabanı bağlı hizmet oluşturma
Azure portalı kullanıcı arabiriminde PostgreSQL için Azure veritabanına bağlı bir hizmet oluşturmak için aşağıdaki adımları kullanın.
Azure Data Factory veya Synapse çalışma alanınızda Yönet sekmesine göz atın ve Bağlı Hizmetler'i seçin, ardından Yeni'ye tıklayın:
PostgreSQL'i arayın ve PostgreSQL için Azure veritabanı bağlayıcısını seçin.
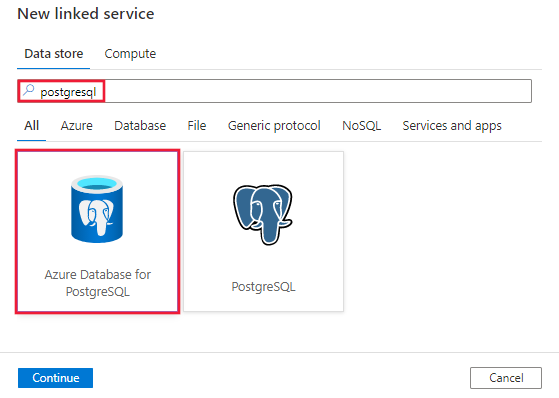
Hizmet ayrıntılarını yapılandırın, bağlantıyı test edin ve yeni bağlı hizmeti oluşturun.
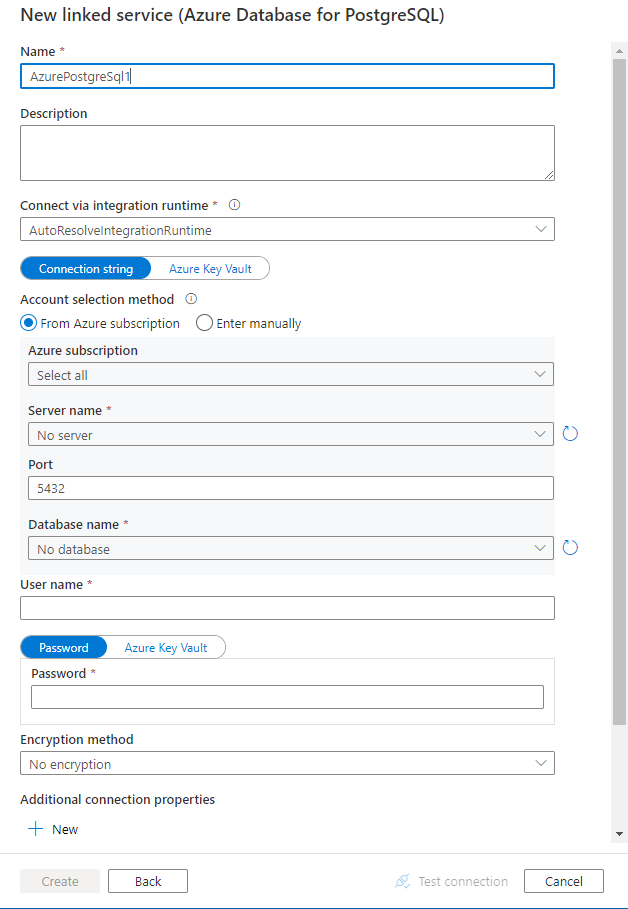
Bağlayıcı yapılandırma ayrıntıları
Aşağıdaki bölümlerde, PostgreSQL için Azure Veritabanı bağlayıcısına özgü Data Factory varlıklarını tanımlamak için kullanılan özellikler hakkında ayrıntılar sunulmaktadır.
Bağlı hizmet özellikleri
PostgreSQL için Azure Veritabanı bağlı hizmeti için aşağıdaki özellikler desteklenir:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | tür özelliği şu şekilde ayarlanmalıdır: AzurePostgreSql. | Yes |
| connectionString | PostgreSQL için Azure Veritabanı bağlanmak için bir ODBC bağlantı dizesi. Ayrıca Azure Key Vault'a parola ekleyebilir ve yapılandırmayı password bağlantı dizesi çıkarabilirsiniz. Daha fazla ayrıntı için aşağıdaki örneklere ve Azure Key Vault'ta kimlik bilgilerini depolama bölümüne bakın. |
Yes |
| connectVia | Bu özellik, veri deposuna bağlanmak için kullanılacak tümleştirme çalışma zamanını temsil eder. Azure Integration Runtime veya Şirket İçinde Barındırılan Tümleştirme Çalışma Zamanı'nı (veri deponuz özel ağda bulunuyorsa) kullanabilirsiniz. Belirtilmezse, varsayılan Azure Integration Runtime'ı kullanır. | Hayır |
Tipik bir bağlantı dizesi.Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password> Aşağıda, servis talebinize göre ayarlayabileceğiniz daha fazla özellik vardır:
| Özellik | Açıklama | Seçenekler | Zorunlu |
|---|---|---|---|
| EncryptionMethod (EM) | Sürücü ile veritabanı sunucusu arasında gönderilen verileri şifrelemek için sürücünün kullandığı yöntem. Örneğin EncryptionMethod=<0/1/6>; |
0 (Şifreleme yok) (Varsayılan) / 1 (SSL) / 6 (RequestSSL) | Hayır |
| ValidateServerCertificate (VSC) | SSL şifrelemesi etkinleştirildiğinde sürücünün veritabanı sunucusu tarafından gönderilen sertifikayı doğrulayıp doğrulamadığını belirler (Şifreleme Yöntemi=1). Örneğin ValidateServerCertificate=<0/1>; |
0 (Devre Dışı) (Varsayılan) / 1 (Etkin) | Hayır |
Örnek:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>"
}
}
}
Örnek:
Parolayı Azure Key Vault'ta depolama
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Veri kümesi özellikleri
Veri kümelerini tanımlamak için kullanılabilen bölümlerin ve özelliklerin tam listesi için bkz . Veri kümeleri. Bu bölüm, PostgreSQL için Azure Veritabanı veri kümelerinde desteklediği özelliklerin listesini sağlar.
PostgreSQL için Azure Veritabanı'dan veri kopyalamak için veri kümesinin type özelliğini AzurePostgreSqlTable olarak ayarlayın. Aşağıdaki özellikler desteklenir:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | Veri kümesinin tür özelliği AzurePostgreSqlTable olarak ayarlanmalıdır | Yes |
| tableName | Tablonun adı | Hayır (etkinlik kaynağında "sorgu" belirtilirse) |
Örnek:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Kopyalama etkinliğinin özellikleri
Etkinlikleri tanımlamak için kullanılabilen bölümlerin ve özelliklerin tam listesi için bkz . İşlem hatları ve etkinlikler. Bu bölümde, PostgreSQL için Azure Veritabanı kaynağı tarafından desteklenen özelliklerin listesi sağlanır.
Kaynak olarak PostgreSql için Azure Veritabanı
PostgreSQL için Azure Veritabanı'dan veri kopyalamak için kopyalama etkinliğindeki kaynak türünü AzurePostgreSqlSource olarak ayarlayın. Kopyalama etkinliği kaynağı bölümünde aşağıdaki özellikler desteklenir:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | Kopyalama etkinliği kaynağının type özelliği AzurePostgreSqlSource olarak ayarlanmalıdır | Yes |
| query | Verileri okumak için özel SQL sorgusunu kullanın. Örneğin: SELECT * FROM mytable veya SELECT * FROM "MyTable". PostgreSQL'de varlık adı, tırnak içinde belirtilmemişse büyük/küçük harfe duyarsız olarak değerlendirilir. |
Hayır (veri kümesindeki tableName özelliği belirtilmişse) |
| partitionOptions | Azure SQL Veritabanı'dan veri yüklemek için kullanılan veri bölümleme seçeneklerini belirtir. İzin verilen değerler şunlardır: Hiçbiri (varsayılan), PhysicalPartitionsOfTable ve DynamicRange. Bir bölüm seçeneği etkinleştirildiğinde (başka bir ifadeyle değil None), bir Azure SQL Veritabanı verileri eşzamanlı olarak yüklemek için paralellik derecesi kopyalama etkinliğindeki parallelCopies ayar tarafından denetlenmektedir. |
Hayır |
| partitionSettings | Veri bölümleme ayarlarının grubunu belirtin. Bölüm seçeneği olmadığında Noneuygulayın. |
Hayır |
altında partitionSettings: |
||
| partitionNames | Kopyalanması gereken fiziksel bölümlerin listesi. Bölüm seçeneği olduğunda PhysicalPartitionsOfTableuygulayın. Kaynak verileri almak için bir sorgu kullanırsanız WHERE yan tümcesine bağlanın ?AdfTabularPartitionName . Bir örnek için PostgreSQL için Azure Veritabanı paralel kopya bölümüne bakın. |
Hayır |
| partitionColumnName | Paralel kopyalama için aralık bölümleme tarafından kullanılacak tamsayı veya tarih/tarih saat türünde (, , bigint, date, veya timestamp with time zone time without time zonetimestamp without time zone) kaynak sütunun adını belirtin. smallintint Belirtilmezse, tablonun birincil anahtarı otomatik olarak algılanır ve bölüm sütunu olarak kullanılır.Bölüm seçeneği olduğunda DynamicRangeuygulayın. Kaynak verileri almak için bir sorgu kullanırsanız WHERE yan tümcesine bağlanın ?AdfRangePartitionColumnName . Bir örnek için PostgreSQL için Azure Veritabanı paralel kopya bölümüne bakın. |
Hayır |
| partitionUpperBound | Verileri kopyalamak için bölüm sütununun en yüksek değeri. Bölüm seçeneği olduğunda DynamicRangeuygulayın. Kaynak verileri almak için bir sorgu kullanırsanız WHERE yan tümcesine bağlanın ?AdfRangePartitionUpbound . Bir örnek için PostgreSQL için Azure Veritabanı paralel kopya bölümüne bakın. |
Hayır |
| partitionLowerBound | Verileri kopyalamak için bölüm sütununun en düşük değeri. Bölüm seçeneği olduğunda DynamicRangeuygulayın. Kaynak verileri almak için bir sorgu kullanırsanız WHERE yan tümcesine bağlanın ?AdfRangePartitionLowbound . Bir örnek için PostgreSQL için Azure Veritabanı paralel kopya bölümüne bakın. |
Hayır |
Örnek:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Havuz olarak PostgreSQL için Azure Veritabanı
Verileri PostgreSQL için Azure Veritabanı kopyalamak için kopyalama etkinliği havuzu bölümünde aşağıdaki özellikler desteklenir:
| Özellik | Açıklama | Gerekli |
|---|---|---|
| Tür | Kopyalama etkinliği havuzu type özelliği AzurePostgreSQLSink olarak ayarlanmalıdır. | Yes |
| preCopyScript | Her çalıştırmada PostgreSQL için Azure Veritabanı veri yazmadan önce yürütülecek kopyalama etkinliği için bir SQL sorgusu belirtin. Önceden yüklenmiş verileri temizlemek için bu özelliği kullanabilirsiniz. | Hayır |
| writeMethod | PostgreSQL için Azure Veritabanı içine veri yazmak için kullanılan yöntem. İzin verilen değerler şunlardır: CopyCommand (varsayılan, daha yüksek performanslıdır), BulkInsert. |
Hayır |
| writeBatchSize | Toplu iş başına PostgreSQL için Azure Veritabanı yüklenen satır sayısı. İzin verilen değer, satır sayısını temsil eden bir tamsayıdır. |
Hayır (varsayılan değer 1.000.000'dir) |
| writeBatchTimeout | Zaman aşımına uğramadan önce toplu ekleme işleminin tamamlanması için bekleme süresi. İzin verilen değerler Zaman aralığı dizeleridir. Örnek olarak 00:30:00 (30 dakika) gösteriliyor. |
Hayır (varsayılan değer 00:30:00'dır) |
Örnek:
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
PostgreSQL için Azure Veritabanı paralel kopyalama
Kopyalama etkinliğindeki PostgreSQL için Azure Veritabanı bağlayıcısı, verileri paralel olarak kopyalamak için yerleşik veri bölümleme sağlar. Veri bölümleme seçeneklerini kopyalama etkinliğinin Kaynak sekmesinde bulabilirsiniz.
Bölümlenmiş kopyalamayı etkinleştirdiğinizde, kopyalama etkinliği bölümlere göre veri yüklemek için PostgreSQL için Azure Veritabanı kaynağınızda paralel sorgular çalıştırır. Paralel derece, kopyalama etkinliğindeki parallelCopies ayar tarafından denetlenilir. Örneğin, dört olarak ayarlarsanızparallelCopies, hizmet aynı anda belirtilen bölüm seçeneğinize ve ayarlarınıza göre dört sorgu oluşturur ve çalıştırır ve her sorgu PostgreSQL için Azure Veritabanı verinin bir bölümünü alır.
Özellikle PostgreSQL için Azure Veritabanı büyük miktarda veri yüklediğinizde veri bölümleme ile paralel kopyalamayı etkinleştirmeniz önerilir. Farklı senaryolar için önerilen yapılandırmalar aşağıdadır. Verileri dosya tabanlı veri deposuna kopyalarken, bir klasöre birden çok dosya olarak yazmanız önerilir (yalnızca klasör adını belirtin), bu durumda performans tek bir dosyaya yazmaktan daha iyidir.
| Senaryo | Önerilen ayarlar |
|---|---|
| Fiziksel bölümleri olan büyük tablodan tam yük. | Bölüm seçeneği: Tablonun fiziksel bölümleri. Yürütme sırasında, hizmet fiziksel bölümleri otomatik olarak algılar ve bölümlere göre verileri kopyalar. |
| Veri bölümleme için bir tamsayı sütunuyla birlikte fiziksel bölümler olmadan büyük tablodan tam yük. | Bölüm seçenekleri: Dinamik aralık bölümü. Bölüm sütunu: Verileri bölümleme için kullanılan sütunu belirtin. Belirtilmezse birincil anahtar sütunu kullanılır. |
| Fiziksel bölümler içeren özel bir sorgu kullanarak büyük miktarda veri yükleyin. | Bölüm seçeneği: Tablonun fiziksel bölümleri. Sorgu: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Bölüm adı: Veri kopyalanacak bölüm adlarını belirtin. Belirtilmezse, hizmet PostgreSQL veri kümesinde belirttiğiniz tablodaki fiziksel bölümleri otomatik olarak algılar. Yürütme sırasında hizmet ?AdfTabularPartitionName yerine gerçek bölüm adını alır ve PostgreSQL için Azure Veritabanı gönderir. |
| Veri bölümleme için bir tamsayı sütunuylayken fiziksel bölümler olmadan özel bir sorgu kullanarak büyük miktarda veri yükleyin. | Bölüm seçenekleri: Dinamik aralık bölümü. Sorgu: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Bölüm sütunu: Verileri bölümleme için kullanılan sütunu belirtin. Tamsayı veya tarih/tarih saat veri türüne sahip sütuna göre bölümleyebilirsiniz. Bölüm üst sınırı ve bölüm alt sınırı: Yalnızca alt ve üst aralık arasındaki verileri almak için bölüm sütununa göre filtrelemek isteyip istemediğinizi belirtin. Yürütme sırasında, hizmet , ?AdfRangePartitionUpboundve ?AdfRangePartitionLowbound yerine ?AdfRangePartitionColumnNameher bölüm için gerçek sütun adı ve değer aralıklarını ekler ve PostgreSQL için Azure Veritabanı gönderir. Örneğin, "ID" bölüm sütununuz alt sınır 1 ve üst sınır 80 olarak ayarlanırsa, paralel kopya 4 olarak ayarlanırsa, hizmet verileri 4 bölüme göre alır. Kimlikleri sırasıyla [1,20], [21, 40], [41, 60] ve [61, 80] arasındadır. |
Bölüm seçeneğiyle veri yüklemek için en iyi yöntemler:
- Veri dengesizliği önlemek için bölüm sütunu (birincil anahtar veya benzersiz anahtar gibi) olarak ayırt edici sütunu seçin.
- Tabloda yerleşik bölüm varsa, daha iyi performans elde etmek için "Tablonun fiziksel bölümleri" bölüm seçeneğini kullanın.
- Verileri kopyalamak için Azure Integration Runtime kullanıyorsanız, daha fazla bilgi işlem kaynağı kullanmak için daha büyük "Veri Entegrasyonu Birimleri (DIU)" (>4) ayarlayabilirsiniz. İlgili senaryoları burada kontrol edin.
- "Kopyalama paralelliği derecesi" bölüm numaralarını denetler, bu sayıyı bazen çok büyük ayarlamak performansı düşürür, bu sayıyı (ŞIRKET içinde barındırılan IR düğümlerinin DIU veya sayısı) * (2 - 4) olarak ayarlamanızı öneririz.
Örnek: Fiziksel bölümleri olan büyük tablodan tam yük
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Örnek: dinamik aralık bölümü olan sorgu
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Eşleme veri akışı özellikleri
Eşleme veri akışındaki verileri dönüştürürken, PostgreSQL için Azure Veritabanı tablolarını okuyabilir ve tablolara yazabilirsiniz. Daha fazla bilgi için bkz . Eşleme veri akışlarında kaynak dönüştürme ve havuz dönüşümü . Kaynak ve havuz türü olarak bir PostgreSQL için Azure Veritabanı veri kümesini veya satır içi veri kümesini kullanmayı seçebilirsiniz.
Kaynak dönüştürme
Aşağıdaki tabloda, PostgreSQL için Azure Veritabanı kaynağı tarafından desteklenen özellikler listelenmektedir. Bu özellikleri Kaynak seçenekleri sekmesinde düzenleyebilirsiniz.
| Veri Akışı Adı | Açıklama | Gerekli | İzin verilen değerler | Veri akışı betiği özelliği |
|---|---|---|---|---|
| Tablo | Giriş olarak Tablo'yı seçerseniz, veri akışı veri kümesinde belirtilen tablodan tüm verileri getirir. | Hayır | - | (yalnızca satır içi veri kümesi için) tableName |
| Sorgu | Giriş olarak Sorgu'yu seçerseniz, kaynaktan veri getirmek için bir SQL sorgusu belirtin. Bu sorgu, veri kümesinde belirttiğiniz tüm tabloları geçersiz kılar. Sorguları kullanmak, test veya arama için satırları azaltmanın harika bir yoludur. Order By yan tümcesi desteklenmez, ancak tam bir SELECT FROM deyimi ayarlayabilirsiniz. Kullanıcı tanımlı tablo işlevlerini de kullanabilirsiniz. select * from udfGetData() , SQL'de veri akışında kullanabileceğiniz bir tablo döndüren bir UDF'dir. Sorgu örneği: select * from mytable where customerId > 1000 and customerId < 2000 veya select * from "MyTable". PostgreSQL'de varlık adı, tırnak içinde belirtilmemişse büyük/küçük harfe duyarsız olarak değerlendirilir. |
Hayır | String | query |
| Şema adı | Giriş olarak Saklı yordam'ı seçerseniz saklı yordamın şema adını belirtin veya hizmetlerden şema adlarını bulmasını istemek için Yenile'yi seçin. | Hayır | String | schemaName |
| Saklı yordam | Giriş olarak Saklı yordam'ı seçerseniz, kaynak tablodaki verileri okumak için saklı yordamın adını belirtin veya hizmetten yordam adlarını bulmasını istemek için Yenile'yi seçin. | Evet (Giriş olarak Saklı yordam'ı seçerseniz) | String | procedureName |
| Yordam parametreleri | Giriş olarak Saklı yordam'ı seçerseniz, saklı yordam için herhangi bir giriş parametresini yordamda ayarlanan sırayla belirtin veya formu @paraNamekullanarak tüm yordam parametrelerini içeri aktarmak için İçeri Aktar'ı seçin. |
Hayır | Dizi | Giriş |
| Toplu iş boyutu | Büyük verileri toplu işlere ayırmak için bir toplu iş boyutu belirtin. | Hayır | Tamsayı | batchSize |
| Yalıtım Düzeyi | Aşağıdaki yalıtım düzeylerinden birini seçin: - Okundu - Okunmamış (varsayılan) - Yinelenebilir Okuma -Serileştirilebilir - Yok (yalıtım düzeyini yoksay) |
Hayır | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERİLEŞTİRİLEBİLİR HİÇBİRİ |
isolationLevel |
PostgreSQL için Azure Veritabanı kaynak betik örneği
Kaynak türü olarak PostgreSQL için Azure Veritabanı kullandığınızda, ilişkili veri akışı betiği şöyledir:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
Havuz dönüşümü
Aşağıdaki tabloda PostgreSQL için Azure Veritabanı havuzu tarafından desteklenen özellikler listelenmektedir. Bu özellikleri Havuz seçenekleri sekmesinde düzenleyebilirsiniz.
| Veri Akışı Adı | Açıklama | Gerekli | İzin verilen değerler | Veri akışı betiği özelliği |
|---|---|---|---|---|
| Güncelleştirme yöntemi | Veritabanı hedefinizde hangi işlemlere izin verileceğini belirtin. Varsayılan değer yalnızca eklemelere izin vermektir. Satırları güncelleştirmek, eklemek veya silmek için, bu eylemlerin satırlarını etiketlemek için bir Değişiklik satırı dönüştürmesi gerekir. |
Yes | true veya false |
deletable eklenebilir güncelleştirilebilir upsertable |
| Anahtar sütunlar | Güncelleştirmeler, upsert'ler ve silmeler için, hangi satırın değiştirileceğini belirlemek için anahtar sütunlarının ayarlanması gerekir. Anahtar olarak seçtiğiniz sütun adı, sonraki upsert, delete güncelleştirmesinin bir parçası olarak kullanılır. Bu nedenle, Havuz eşlemesinde var olan bir sütun seçmelisiniz. |
Hayır | Dizi | keys |
| Anahtar sütunları yazmayı atlama | Değeri anahtar sütununa yazmak istemiyorsanız "Anahtar sütunlarını yazmayı atla" seçeneğini belirleyin. | Hayır | true veya false |
skipKeyWrites |
| Tablo eylemi | Yazmadan önce hedef tablodan tüm satırların yeniden oluşturulmasını veya kaldırılıp kaldırılmayacağını belirler. - Yok: Tabloda hiçbir eylem yapılmaz. - Yeniden oluştur: Tablo bırakılır ve yeniden oluşturulur. Dinamik olarak yeni bir tablo oluşturuyorsanız gereklidir. - Kesme: Hedef tablodaki tüm satırlar kaldırılır. |
Hayır | true veya false |
Yeni -den oluşturun truncate |
| Toplu iş boyutu | Her toplu işlemde kaç satır yazıldığını belirtin. Daha büyük toplu iş boyutları sıkıştırmayı ve bellek iyileştirmeyi geliştirir, ancak verileri önbelleğe alırken bellek özel durumlarının dışına çıkma riskiyle karşı karşıyadır. | Hayır | Tamsayı | batchSize |
| Kullanıcı veritabanı şemasını seçin | Varsayılan olarak, havuz şeması altında hazırlama olarak geçici bir tablo oluşturulur. Alternatif olarak Havuz şeması kullan seçeneğinin işaretini kaldırabilir ve bunun yerine Data Factory'nin yukarı akış verilerini yüklemek ve tamamlandıktan sonra bunları otomatik olarak temizlemek için bir hazırlama tablosu oluşturacağı bir şema adı belirtebilirsiniz. Veritabanında tablo oluşturma iznine sahip olduğunuzdan ve şemada değişiklik iznine sahip olduğunuzdan emin olun. | Hayır | String | stagingSchemaName |
| SQL Betikleri Öncesi ve Sonrası | Havuz veritabanınıza veri yazıldıktan önce (ön işleme) ve sonra (işleme sonrası) yürütülecek çok satırlı SQL betiklerini belirtin. | Hayır | String | preSQL'ler postSQL'ler |
İpucu
- Birden çok komut içeren tek toplu iş betiklerini birden çok toplu iş olarak bölmeniz önerilir.
- Yalnızca basit bir güncelleştirme sayısı döndüren Veri Tanımlama Dili (DDL) ve Veri İşleme Dili (DML) deyimleri toplu iş kapsamında çalıştırılabilir. Toplu işlem gerçekleştirme'den daha fazla bilgi edinin
Artımlı ayıklamayı etkinleştir: ADF'ye yalnızca işlem hattının son yürütülmesinden bu yana değişen satırları işlemesini bildirmek için bu seçeneği kullanın.
Artımlı sütun: Artımlı ayıklama özelliğini kullanırken, kaynak tablonuzda filigran olarak kullanmak istediğiniz tarih/saat veya sayısal sütunu seçmeniz gerekir.
Okumaya baştan başlayın: Artımlı ayıklama ile bu seçeneğin ayarlanması, ADF'ye artımlı ayıklamanın açık olduğu bir işlem hattının ilk yürütülmesinde tüm satırları okumasını bildirecektir.
PostgreSQL için Azure Veritabanı havuz betiği örneği
havuz türü olarak PostgreSQL için Azure Veritabanı kullandığınızda, ilişkili veri akışı betiği şöyledir:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSQLSink
Arama etkinliği özellikleri
Özellikler hakkında daha fazla bilgi için bkz . Arama etkinliği.
İlgili içerik
Kopyalama etkinliği tarafından kaynak ve havuz olarak desteklenen veri depolarının listesi için bkz . Desteklenen veri depoları.