HDInsight'ta Apache Hadoop ile Apache Ambari Hive Görünümünü Kullanma
Apache Ambari Hive Görünümünü kullanarak Hive sorgularını çalıştırmayı öğrenin. Hive Görünümü, web tarayıcınızdan Hive sorguları yazmanızı, iyileştirmenizi ve çalıştırmanızı sağlar.
Önkoşullar
HDInsight üzerinde hadoop kümesi. Bkz . Linux'ta HDInsight'ı kullanmaya başlama.
Hive sorgusu çalıştırma
Azure portalda kümenizi seçin. Yönergeler için bkz . Kümeleri listeleme ve gösterme. Küme yeni bir portal görünümünde açılır.
Küme panolarından Ambari görünümleri'ne tıklayın. Kimlik doğrulaması yapmanız istendiğinde, kümeyi oluştururken sağladığınız küme oturum açma (varsayılan
admin) hesap adını ve parolasını kullanın. Ayrıca, tarayıcınızda kümenizin adı olan konumunaCLUSTERNAMEda gidebilirsinizhttps://CLUSTERNAME.azurehdinsight.net/#/main/views.Görünüm listesinden Hive Görünümü'nü seçin.
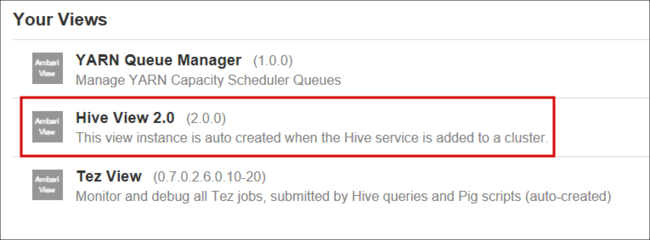
Hive görünüm sayfası aşağıdaki görüntüye benzer:
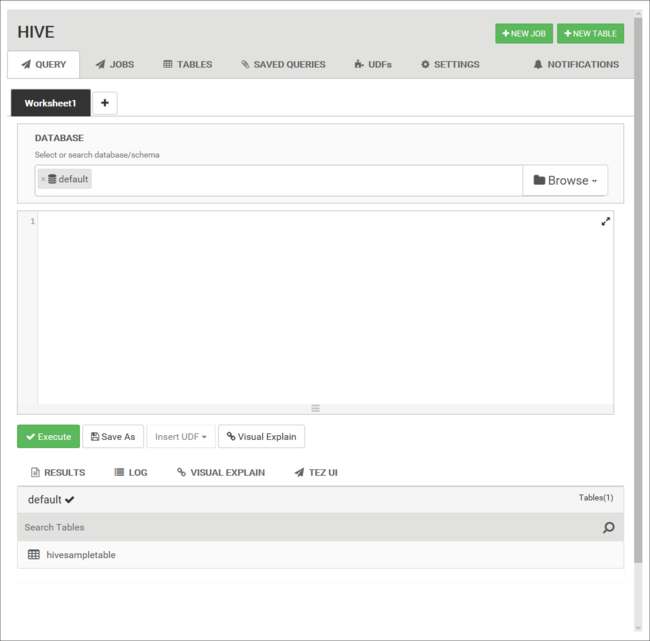
Sorgu sekmesinden aşağıdaki HiveQL deyimlerini çalışma sayfasına yapıştırın:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;Bu deyimler aşağıdaki eylemleri gerçekleştirir:
Deyim Açıklama DROP TABLE Tablonun zaten mevcut olması durumunda tabloyu ve veri dosyasını siler. DıŞ TABLO OLUŞTURMA Hive'da yeni bir "dış" tablo oluşturur. Dış tablolar yalnızca Hive'da tablo tanımını depolar. Veriler özgün konumda bırakılır. SATıR BIÇIMI Verilerin nasıl biçimlendirildiğini gösterir. Bu durumda, her günlükteki alanlar bir boşlukla ayrılır. TEXTFILE KONUMU OLARAK DEPOLANıR Verilerin nerede depolandığını ve metin olarak depolandığını gösterir. SELECT t4 sütununun [ERROR] değerini içerdiği tüm satırların sayısını seçer. Önemli
Veritabanı seçimini varsayılan olarak bırakın. Bu belgedeki örneklerde HDInsight'ta bulunan varsayılan veritabanı kullanılır.
Sorguyu başlatmak için çalışma sayfasının altındaki Yürüt'e tıklayın. Düğme turuncuya dönüşür ve metin Durdur olarak değişir.
Sorgu tamamlandıktan sonra Sonuçlar sekmesi işlemin sonuçlarını görüntüler. Aşağıdaki metin sorgunun sonucudur:
loglevel count [ERROR] 3İşin oluşturduğu günlük bilgilerini görüntülemek için LOG sekmesini kullanabilirsiniz.
İpucu
Sonuçlar sekmesinin altındaki Eylemler açılan iletişim kutusundan sonuçları indirin veya kaydedin.
Görselde açıklanmaktadır
Sorgu planının görselleştirmesini görüntülemek için çalışma sayfasının altındaki Görsel Açıklar sekmesini seçin.
Sorgunun Görsel Açıklar görünümü, karmaşık sorguların akışını anlamanıza yardımcı olabilir.
Tez Kullanıcı Arabirimi
Sorgunun Tez kullanıcı arabirimini görüntülemek için çalışma sayfasının altındaki Tez ui sekmesini seçin.
Önemli
Tez, tüm sorguları çözümlemek için kullanılmaz. Tez kullanmadan birçok sorgu çözümleyebilirsiniz.
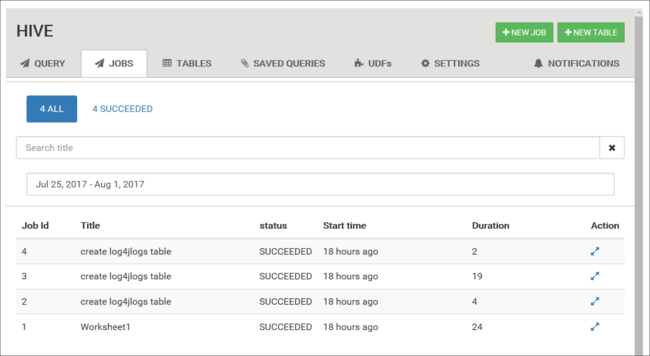
İş geçmişini görüntüleme
İşler sekmesinde Hive sorgularının geçmişi görüntülenir.
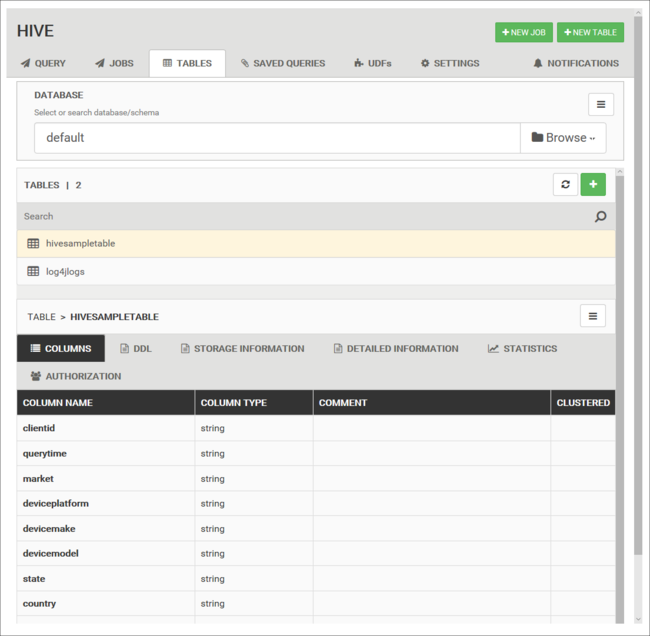
Veritabanı tabloları
Hive veritabanındaki tablolarla çalışmak için Tablolar sekmesini kullanabilirsiniz.
Kaydedilen sorgular
Sorgu sekmesinden isteğe bağlı olarak sorguları kaydedebilirsiniz. Bir sorguyu kaydettikten sonra, Kaydedilen Sorgular sekmesinden yeniden kullanabilirsiniz.

İpucu
Kaydedilen sorgular varsayılan küme depolama alanında depolanır. Kaydedilen sorguları yolunun /user/<username>/hive/scriptsaltında bulabilirsiniz. Bunlar düz metin .hql dosyaları olarak depolanır.
Kümeyi siler ancak depolama alanını tutarsanız sorguları almak için Azure Depolama Gezgini veya Data Lake Depolama Gezgini (Azure Portal'dan) gibi bir yardımcı program kullanabilirsiniz.
Kullanıcı tanımlı işlevler
Hive'ı kullanıcı tanımlı işlevler (UDF) aracılığıyla genişletebilirsiniz. HiveQL'de kolayca modellenmeyecek işlevleri veya mantığı uygulamak için UDF kullanın.
Hive Görünümünün en üstündeki UDF sekmesini kullanarak bir UDF kümesi bildirin ve kaydedin. Bu UDF'ler Sorgu Düzenleyicisi ile kullanılabilir.
Sorgu Düzenleyicisi en altında udfs ekle düğmesi görüntülenir. Bu girdi, Hive Görünümünde tanımlanan UDF'lerin açılan listesini görüntüler. UDF seçildiğinde, UDF'yi etkinleştirmek için sorgunuza HiveQL deyimleri eklenir.
Örneğin, aşağıdaki özelliklere sahip bir UDF tanımladıysanız:
Kaynak adı: myudfs
Kaynak yolu: /myudfs.jar
UDF adı: myawesomeudf
UDF sınıf adı: com.myudfs.Awesome
udfs Ekle düğmesi kullanıldığında myudfs adlı bir girdi görüntülenir ve bu kaynak için tanımlanan her UDF için başka bir açılan liste görüntülenir. Bu durumda, myawesomeudf. Bu girişin seçilmesi sorgunun başına aşağıdakileri ekler:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
Ardından sorgunuzda UDF'yi kullanabilirsiniz. Örneğin, SELECT myawesomeudf(name) FROM people;.
HDInsight üzerinde Hive ile UDF'leri kullanma hakkında daha fazla bilgi için aşağıdaki makalelere bakın:
- HDInsight'ta Apache Hive ve Apache Pig ile Python kullanma
- HDInsight'ta Apache Hive ile Java UDF kullanma
Hive ayarları
Tez (varsayılan) olan Hive yürütme altyapısını MapReduce olarak değiştirme gibi çeşitli Hive ayarlarını değiştirebilirsiniz.
Sonraki adımlar
HDInsight üzerinde Hive hakkında genel bilgi için: