Öğretici: HDInsight üzerinde Apache Spark Yapılandırılmış Akışını Apache Kafka ile kullanma
Bu öğreticide, Azure HDInsight üzerinde Apache Kafka ile veri okumak ve yazmak için Apache Spark Yapılandırılmış Akışı'nın nasıl kullanılacağı gösterilmektedir.
Spark Yapılandırılmış Akış, Spark SQL üzerinde oluşturulmuş bir akış işleme altyapısıdır. Bu altyapıyı kullanarak, statik veriler üzerinde toplu hesaplamayla aynı şekilde akış hesaplamalarını ifade edebilirsiniz.
Bu öğreticide aşağıdakilerin nasıl yapılacağını öğreneceksiniz:
- Küme oluşturmak için Azure Resource Manager şablonu kullanma
- Kafka ile Spark Yapılandırılmış Akışı Kullanma
Bu belgedeki adımları tamamladığınızda fazla ücretlerden kaçınmak için kümeleri silmeyi unutmayın.
Önkoşullar
jq, bir komut satırı JSON işlemcisi. Bkz. https://stedolan.github.io/jq/.
HDInsight üzerinde Spark ile Jupyter Notebook kullanma hakkında bilgi. Daha fazla bilgi için HDInsight üzerinde Apache Spark ile veri yükleme ve sorguları çalıştırma belgesine bakın.
Scala programlama dilini bilme. Bu öğreticide kullanılan kod, Scala dilinde yazılmıştır.
Kafka konuları oluşturmayı bilme. Daha fazla bilgi için HDInsight üzerinde Apache Kafka hızlı başlangıç belgesine bakın.
Önemli
Bu belgede yer alan adımlar hem HDInsight üzerinde Spark hem de HDInsight kümesi üzerinde Kafka içeren bir Azure kaynak grubu gerektirir. Bu kümelerin her ikisi de Spark kümesinin Kafka kümesiyle doğrudan iletişim kurmasına olanak tanıyan bir Azure Sanal Ağı içinde bulunur.
Size kolaylık sağlamak için bu belgede, tüm gerekli Azure kaynaklarını oluşturabilecek bir şablonun bağlantıları sağlanır.
Sanal ağda HDInsight kullanma hakkında daha fazla bilgi için HDInsight için sanal ağ planlama belgesine bakın.
Apache Kafka ile Yapılandırılmış Akış
Spark Yapılandırılmış Akışı, Spark SQL altyapısı üzerinde derlenen bir akış işleme altyapısıdır. Yapılandırılmış Akış'ı kullanırken, akış sorgularını toplu sorgu yazdığınız gibi yazabilirsiniz.
Aşağıdaki kod parçacıkları, Kafka’dan okuma ve dosyaya depolama işlemlerini gösterir. Birincisi bir toplu iş işlemi, ikincisiyse bir akış işlemidir:
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
Her iki kod parçacığında Kafka’dan veriler okunur ve dosyaya yazılır. Örnekler arasındaki farklar şunlardır:
| Batch | Akışlar |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
Akış işlemi, 30.000 ms'den sonra akışı durduran öğesini de kullanır awaitTermination(30000).
Kafka ile Yapılandırılmış Akışı kullanmak için projenizin org.apache.spark : spark-sql-kafka-0-10_2.11 paketinde bir bağımlılığı olmalıdır. Bu paketin sürümü, HDInsight üzerinde Spark sürümüyle eşleşmelidir. Spark 2.4 için (HDInsight 4.0'da kullanılabilir), farklı proje türlerine yönelik bağımlılık bilgilerini adresinde https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjarbulabilirsiniz.
Bu öğreticide kullanılan Jupyter Notebook için aşağıdaki hücre bu paket bağımlılığını yükler:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
Kümeleri oluşturma
HDInsight üzerinde Apache Kafka, Genel İnternet üzerinden Kafka aracılarına erişim sağlamaz. Kafka kullanan her özellik aynı Azure sanal ağı içinde olmalıdır. Bu öğreticide hem Kafka hem de Spark kümeleri aynı Azure sanal ağı içinde yer alır.
Aşağıdaki diyagramda Spark ile Kafka arasındaki iletişimin nasıl aktığı gösterilmektedir:
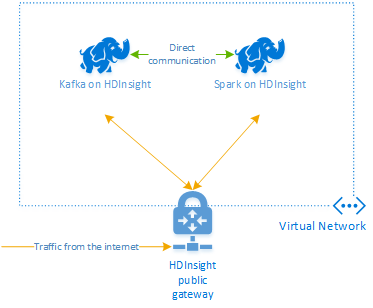
Not
Kafka hizmeti, sanal ağ içindeki iletişimle sınırlıdır. SSH ve Ambari gibi küme üzerindeki diğer hizmetlere internet üzerinden erişilebilir. HDInsight üzerinde kullanılabilir olan genel bağlantı noktaları hakkında daha fazla bilgi için bkz. HDInsight Tarafından Kullanılan Bağlantı Noktaları ve URI’ler.
Bir Azure Sanal Ağı oluşturmak ve sonra bunun içinde Kafka ve Spark kümeleri oluşturmak için aşağıdaki adımları kullanın:
Aşağıdaki düğmeyi kullanarak Azure'da oturum açın ve şablonu Azure portalında açın.

Azure Resource Manager şablonu https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json sayfasında bulunur.
Bu şablon aşağıdaki kaynakları oluşturur:
HDInsight 4.0 veya 5.0 kümesinde kafka.
HDInsight 4.0 veya 5.0 kümesinde Spark 2.4 veya 3.1.
HDInsight kümeleri içeren bir Azure Sanal Ağı.
Önemli
Bu öğreticide kullanılan yapılandırılmış akış not defteri, HDInsight 4.0 veya 5.0 üzerinde Spark 2.4 veya 3.1 gerektirir. HDInsight üzerinde Spark’ın daha önceki bir sürümünü kullanıyorsanız, not defterini kullanırken hatalarla karşılaşırsınız.
Özelleştirilmiş şablon bölümündeki girişleri doldurmak için aşağıdaki bilgileri kullanın:
Ayar Value Abonelik Azure aboneliğiniz Kaynak grubu Kaynakları içeren kaynak grubu. Konum İçinde kaynakların oluşturulduğu Azure bölgesi. Spark Kümesi Adı Spark kümesinin adı. İlk altı karakter Kafka küme adından farklı olmalıdır. Kafka Kümesi Adı Kafka kümesinin adı. İlk altı karakter Spark küme adından farklı olmalıdır. Küme Oturum Açma Kullanıcı Adı Kümeler için yönetici kullanıcı adı. Küme Oturum Açma Parolası Kümeler için yönetici kullanıcı parolası. SSH Kullanıcı Adı Kümeler için oluşturulacak SSH kullanıcısı. SSH Parolası SSH kullanıcısı için parola. 
Hüküm ve Koşullar'ı okuyun, ardından Yukarıda belirtilen hüküm ve koşulları kabul ediyorum'ı seçin.
Satın al'ı seçin.
Not
Kümelerin oluşturulması 20 dakikaya kadar sürebilir.
Spark Yapılandırılmış Akışı Kullanma
Bu örnek, HDInsight üzerinde Kafka ile Spark Yapılandırılmış Akışı'nın nasıl kullanılacağını gösterir. New York City tarafından sağlanan taksi yolculukları ile ilgili verileri kullanır. Bu not defteri tarafından kullanılan veri kümesi 2016 Yeşil Taksi Yolculuğu Verileri'ne ait.
Konak bilgilerini toplayın. Kafka ZooKeeper ve aracı konak bilgilerini almak için aşağıdaki curl ve jq komutlarını kullanın. Komutlar bir Windows komut istemi için tasarlanmıştır, diğer ortamlar için küçük çeşitlemeler gerekir. değerini Kafka kümenizin adıyla ve
KafkaPasswordküme oturum açma parolası ile değiştirinKafkaCluster. Ayrıca değerini jq yüklemenizin gerçek yoluyla değiştirinC:\HDI\jq-win64.exe. Windows komut istemine komutları girin ve çıkışı sonraki adımlarda kullanmak üzere kaydedin.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"Bir web tarayıcısından adresine gidin
https://CLUSTERNAME.azurehdinsight.net/jupyter; buradaCLUSTERNAMEkümenizin adıdır. Sorulduğunda, kümeyi oluştururken kullanılan küme kullanıcı adı (yönetici) ve parolasını girin.Not defteri oluşturmak için Yeni > Spark'ı seçin.
Spark akışında mikrobatching vardır; bu da verilerin toplu olarak geldiği ve yürütücülerin veri toplu işlemlerinde çalıştırıldığı anlamına gelir. Yürütücü, toplu işlemi işlemek için gereken süreden daha az boşta zaman aşımına sahipse yürütücüler sürekli eklenir ve kaldırılır. Yürütücülerin boşta kalma zaman aşımı toplu işlem süresinden uzunsa yürütücü hiçbir zaman kaldırılmaz. Bu nedenle akış uygulamalarını çalıştırırken spark.dynamicAllocation.enabled ayarını false olarak ayarlayarak dinamik ayırmayı devre dışı bırakmanızı öneririz.
Not Defteri hücresine aşağıdaki bilgileri girerek Not Defteri tarafından kullanılan paketleri yükleyin. CTRL + ENTER tuşlarını kullanarak komutunu çalıştırın.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Kafka konusunu oluşturun. öğesini ilk adımda ayıklanan Zookeeper konak bilgileriyle değiştirerek
YOUR_ZOOKEEPER_HOSTSaşağıdaki komutu düzenleyin. Konuyu oluşturmaktripdataiçin Jupyter Not Defterinize düzenlenen komutu girin.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersTaksi yolculukları ile ilgili verileri alma. New York City'deki taksi yolculuklarına veri yüklemek için sonraki hücreye komutunu girin. Veriler bir veri çerçevesine yüklenir ve ardından veri çerçevesi hücre çıkışı olarak görüntülenir.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Kafka aracısı konak bilgilerini ayarlayın. değerini, 1. adımda ayıkladığınız aracı konak bilgileriyle değiştirin
YOUR_KAFKA_BROKER_HOSTS. Düzenlenen komutu sonraki Jupyter Notebook hücresine girin.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")Verileri Kafka'ya gönderin. Aşağıdaki komutta
vendorid, alan Kafka iletisinin anahtar değeri olarak kullanılır. Anahtar, Kafka tarafından verileri bölümlerken kullanılır. Tüm alanlar Kafka iletisinde JSON dize değeri olarak depolanır. Verileri toplu iş sorgusu kullanarak Kafka'ya kaydetmek için Jupyter'a aşağıdaki komutu girin.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")Şema bildirme. Aşağıdaki komut, kafka'dan JSON verilerini okurken şemanın nasıl kullanılacağını gösterir. Sonraki Jupyter hücrenize komutunu girin.
// Import bits useed for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")Verileri seçin ve akışı başlatın. Aşağıdaki komut, bir toplu iş sorgusu kullanarak Kafka'dan veri almayı gösterir. Ardından sonuçları Spark kümesindeki HDFS'ye yazın. Bu örnekte,
selectİletiyi (değer alanı) Kafka'dan alır ve şemayı buna uygular. Veriler daha sonra HDFS'ye (WASB veya ADL) parquet biçiminde yazılır. Sonraki Jupyter hücrenize komutunu girin.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")Sonraki Jupyter hücrenize komutunu girerek dosyaların oluşturulduğunu doğrulayabilirsiniz. Dizindeki
/example/batchtripdatadosyaları listeler.%%bash hdfs dfs -ls /example/batchtripdataÖnceki örnekte bir toplu iş sorgusu kullanılırken, aşağıdaki komut akış sorgusu kullanarak aynı şeyin nasıl yapılacağını gösterir. Sonraki Jupyter hücrenize komutunu girin.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")Dosyaların akış sorgusu tarafından yazıldığını doğrulamak için aşağıdaki hücreyi çalıştırın.
%%bash hdfs dfs -ls /example/streamingtripdata
Kaynakları temizleme
Bu öğretici ile oluşturulan kaynakları temizlemek için kaynak grubunu silebilirsiniz. Kaynak grubu silindiğinde ilişkili HDInsight kümesi de silinir. Kaynak grubuyla ilişkili diğer tüm kaynakları da.
Azure portalını kullanarak kaynak grubunu kaldırmak için:
- Azure portalında sol taraftaki menüyü genişleterek hizmet menüsünü açın ve kaynak gruplarınızın listesini görüntülemek için Kaynak Grupları'nı seçin.
- Silinecek kaynak grubunu bulun ve sonra listenin sağ tarafındaki Daha fazla düğmesine (...) sağ tıklayın.
- Kaynak grubunu sil'i seçip onaylayın.
Uyarı
HDInsight kümesi faturalandırması küme oluşturulduğunda başlar ve küme silindiğinde sona erer. Fatura dakikalara eşit olarak dağıtıldığından, kullanılmayan kümelerinizi mutlaka silmelisiniz.
HDInsight üzerinde Kafka kümesinin silinmesi Kafka’da depolanmış tüm verileri siler.