Hızlı Başlangıç: ARM şablonunu kullanarak Azure HDInsight'ta Apache Spark kümesi oluşturma
Bu hızlı başlangıçta, Azure HDInsight'ta Apache Spark kümesi oluşturmak için bir Azure Resource Manager şablonu (ARM şablonu) kullanacaksınız. Ardından bir Jupyter Notebook dosyası oluşturur ve Apache Hive tablolarında Spark SQL sorguları çalıştırmak için bu dosyayı kullanırsınız. Azure HDInsight kuruluşlara yönelik, yönetilen, tam spektrumlu ve açık kaynaklı bir analiz hizmetidir. HDInsight için Apache Spark çerçevesi, bellek içi işlemeyi kullanarak hızlı veri analizi ve küme bilişimi sağlar. Jupyter Notebook verilerinizle etkileşim kurmanıza, kodu markdown metniyle birleştirmenize ve basit görselleştirmeler yapmanıza olanak tanır.
Birlikte birden çok küme kullanıyorsanız, bir sanal ağ oluşturmak istersiniz ve Spark kümesi kullanıyorsanız Hive Ambarı Bağlayıcısı'nı da kullanmak istersiniz. Daha fazla bilgi için bkz . Azure HDInsight için sanal ağ planlama ve Apache Spark ile Apache Hive'ı Hive Ambar Bağlayıcısı ile tümleştirme.
Azure Resource Manager şablonu, projenizin altyapısını ve yapılandırmasını tanımlayan bir JavaScript Nesne Gösterimi (JSON) dosyasıdır. Bu şablonda, bildirim temelli sözdizimi kullanılır. Dağıtımı oluşturmak için programlama komutlarının sırasını yazmadan hedeflenen dağıtımınızı açıklarsınız.
Ortamınız önkoşulları karşılıyorsa ve ARM şablonlarını kullanma hakkında bilginiz varsa, Azure’a dağıtma düğmesini seçin. Şablon Azure portalda açılır.

Önkoşullar
Azure aboneliğiniz yoksa başlamadan önce ücretsiz bir hesap oluşturun.
Şablonu gözden geçirme
Bu hızlı başlangıçta kullanılan şablon Azure Hızlı Başlangıç Şablonlarından alınmıştır.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.5.6.12127",
"templateHash": "4742950082151195489"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the HDInsight cluster to create."
}
},
"clusterLoginUserName": {
"type": "string",
"maxLength": 20,
"minLength": 2,
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards. The username must consist of digits, upper or lowercase letters, and/or the following special characters: (!#$%&'()-^_`{}~)."
}
},
"clusterLoginPassword": {
"type": "secureString",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"minLength": 2,
"metadata": {
"description": "These credentials can be used to remotely access the cluster. The sshUserName can only consit of digits, upper or lowercase letters, and/or the following special characters (%&'^_`{}~). Also, it cannot be the same as the cluster login username or a reserved word"
}
},
"sshPassword": {
"type": "secureString",
"maxLength": 72,
"minLength": 6,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"headNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"workerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the workernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2021-08-01",
"name": "[format('storage{0}', uniqueString(resourceGroup().id))]",
"location": "[parameters('location')]",
"sku": {
"name": "Standard_LRS"
},
"kind": "StorageV2"
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"tier": "Standard",
"clusterDefinition": {
"kind": "spark",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))).primaryEndpoints.blob, 'https://', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('headNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('workerNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))]"
]
}
],
"outputs": {
"storage": {
"type": "object",
"value": "[reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')))]"
}
}
}
Şablonda iki Azure kaynağı tanımlanır:
- Microsoft.Storage/storageAccounts: Bir Azure Depolama Hesabı oluşturun.
- Microsoft.HDInsight/cluster: HDInsight kümesi oluşturun.
Şablonu dağıtma
Azure’da oturum açmak ve ARM şablonunu açmak için aşağıdan Azure’da Dağıt düğmesini seçin.
Aşağıdaki değerleri yazın veya seçin:
Özellik Açıklama Abonelik Açılan listeden küme için kullanılan Azure aboneliğini seçin. Kaynak grubu Açılan listeden mevcut kaynak grubunuzu seçin veya Yeni oluştur'u seçin. Konum Değer, kaynak grubu için kullanılan konumla otomatik olarak doldurulur. Küme Adı Genel olarak benzersiz bir ad girin. Bu şablon için yalnızca küçük harfleri ve sayıları kullanın. Küme Oturum Açma Kullanıcı Adı Varsayılan olarak kullanıcı adını admingirin.Küme Oturum Açma Parolası Bir parola girin. Parola en az 10 karakter uzunluğunda olmalı ve en az bir basamak, bir büyük harf ve bir küçük harf, bir alfasayısal olmayan karakter (karakterler ' ` "hariç) içermelidir.SSH Kullanıcı Adı Varsayılan olarak kullanıcı adını sshusergirin.SSH Parolası Parolayı belirtin. 
HÜKÜM VE KOŞULLAR'ı gözden geçirin. Ardından yukarıda belirtilen hüküm ve koşulları kabul ediyorum'a ve ardından Satın Al'a tıklayın. Dağıtımınızın devam ettiğini belirten bir bildirim alırsınız. Bir küme oluşturmak yaklaşık 20 dakika sürer.
HDInsight kümeleri oluştururken bir sorunla karşılaşırsanız, bunu yapmak için doğru izinlere sahip olmayabilirsiniz. Daha fazla bilgi için bkz. Erişim denetimi gereksinimleri.
Dağıtılan kaynakları gözden geçirme
Küme oluşturulduktan sonra Kaynağa git bağlantısıyla bir Dağıtım başarılı bildirimi alırsınız. Kaynak grubu sayfanız yeni HDInsight kümenizi ve kümeyle ilişkili varsayılan depolama alanını listeler. Her kümenin bir Azure Depolaması veya Azure Data Lake Storage Gen2 bağımlılığı vardır. Varsayılan depolama hesabı olarak adlandırılır. HDInsight kümesi ve varsayılan depolama hesabı aynı Azure bölgesinde birlikte bulunmalıdır. Kümelerin silinmesi depolama hesabı bağımlılığını silmez. Varsayılan depolama hesabı olarak adlandırılır. HDInsight kümesi ve varsayılan depolama hesabı aynı Azure bölgesinde birlikte bulunmalıdır. Kümelerin silinmesi depolama hesabını silmez.
Jupyter Notebook dosyası oluşturma
Jupyter Notebook , çeşitli programlama dillerini destekleyen etkileşimli bir not defteri ortamıdır. Verilerinizle etkileşime geçmek, kodu markdown metniyle birleştirmek ve basit görselleştirmeler gerçekleştirmek için Jupyter Notebook dosyası kullanabilirsiniz.
Azure portalını açın.
HDInsight kümeleri’ni ve sonra oluşturduğunuz kümeyi seçin.
Portaldaki Küme panoları bölümünde Jupyter Notebook'u seçin. İstendiğinde, küme için küme oturum açma kimlik bilgilerini girin.
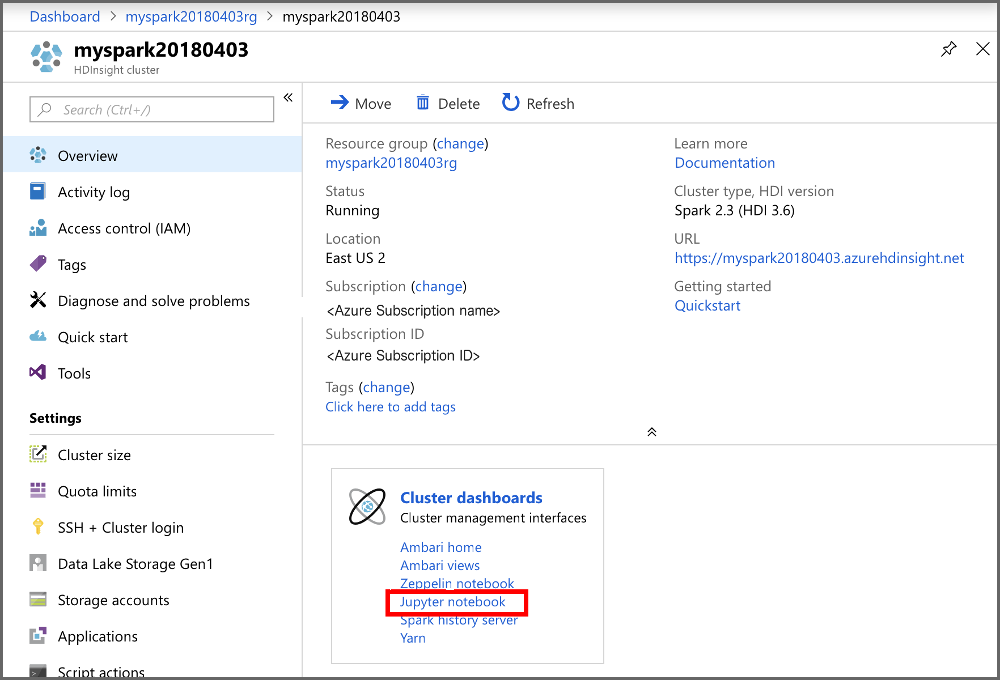
Yeni>PySpark seçeneklerini belirleyerek bir not defteri oluşturun.
Untitled(Untitled.pynb) adıyla yeni bir not defteri oluşturulur ve açılır.
Apache Spark SQL deyimlerini çalıştırma
SQL (Yapılandırılmış Sorgu Dili), veri sorgulama ve dönüştürme için en yaygın kullanılan dildir. Bilinen SQL söz dizimini kullanan Spark SQL, yapısal verileri işleyen bir Apache Spark uzantısı olarak çalışır.
Çekirdeğin hazır olduğunu doğrulayın. Not defterinde çekirdek adının yanında boş bir daire görmeniz, çekirdeğin hazır olduğu anlamına gelir. Dolu daire, çekirdeğin meşgul olduğunu belirtir.
 alt-text="Çekirdek durumu." border="true":::
alt-text="Çekirdek durumu." border="true":::Not defterini ilk kez başlattığınızda, çekirdek arka planda birkaç görev gerçekleştirir. Çekirdeğin hazır olmasını bekleyin.
Aşağıdaki kodu boş bir hücreye yapıştırın ve kodu çalıştırmak için SHIFT + ENTER tuşlarına basın. Komut, kümedeki Hive tablolarını listeler:
%%sql SHOW TABLESHDInsight kümenizle bir Jupyter Notebook dosyası kullandığınızda, Spark SQL kullanarak Hive sorguları çalıştırmak için kullanabileceğiniz önceden ayarlanmış
sparkbir oturum elde edersiniz.%%sql, Hive sorgusunu çalıştırmak için Jupyter Not Defteri’nesparkoturumu ön ayarını kullanmasını söyler. Sorgu, varsayılan olarak tüm HDInsight kümelerinde sağlanan Hive tablosundaki (hivesampletable) ilk 10 satırı getirir. Sorguyu ilk kez gönderdiğinizde Jupyter not defteri için bir Spark uygulaması oluşturur. Tamamlanması yaklaşık 30 saniye sürer. Spark uygulaması hazır olduktan sonra sorgu yaklaşık bir saniye içinde yürütülür ve sonuçları üretir. Çıktı şuna benzer: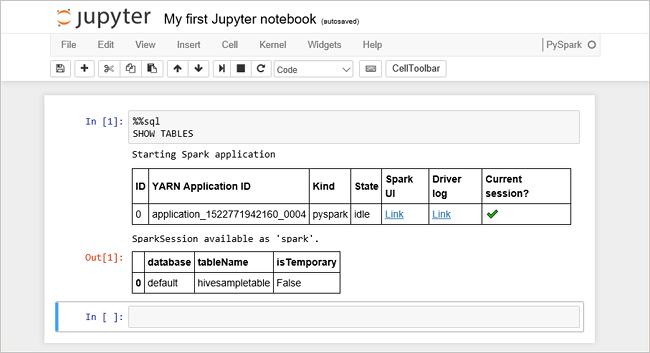 HDInsight'ta y" border="true":::
HDInsight'ta y" border="true":::Jupyter’de bir sorguyu her çalıştırdığınızda web tarayıcınızın pencere başlığında not defteri başlığı ile birlikte (Meşgul) durumu gösterilir. Ayrıca sağ üst köşedeki PySpark metninin yanında içi dolu bir daire görürsünüz.
hivesampletablekomutundaki verileri görmek için başka bir sorgu çalıştırın.%%sql SELECT * FROM hivesampletable LIMIT 10Sorgu çıkışının görüntülenmesi için ekranın yenilenmesi gerekir.
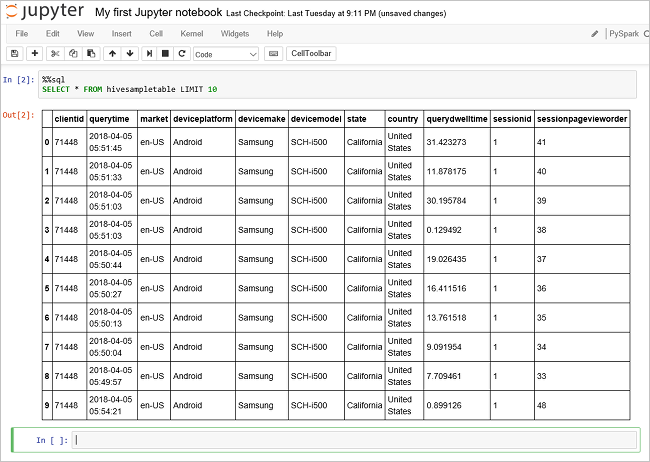 Insight" border="true":::
Insight" border="true":::Not defterindeki Dosya menüsünden Kapat ve Durdur’u seçin. Not defterinin kapatılması, Spark uygulaması da dahil olmak üzere küme kaynaklarını serbest bırakır.
Kaynakları temizleme
Hızlı başlangıcı tamamladıktan sonra kümeyi silmek isteyebilirsiniz. HDInsight ile verileriniz Azure Depolama'da depolanır, böylece kullanımda olmayan bir kümeyi güvenle silebilirsiniz. Kullanımda olmasa bile HDInsight kümesi için de ücretlendirilirsiniz. Küme ücretleri depolama ücretlerinden çok daha fazla olduğundan, kullanımda olmayan kümeleri silmek ekonomik bir anlam ifade eder.
Azure portalından kümenize gidin ve Sil'i seçin.
 sight cluster" border="true":::
sight cluster" border="true":::
Kaynak grubu adını seçerek de kaynak grubu sayfasını açabilir ve sonra Kaynak grubunu sil’i seçebilirsiniz. Kaynak grubunu silerek hem HDInsight kümesini hem de varsayılan depolama hesabını silersiniz.
Sonraki adımlar
Bu hızlı başlangıçta HDInsight'ta Apache Spark kümesi oluşturmayı ve temel bir Spark SQL sorgusu çalıştırmayı öğrendiniz. Örnek veriler üzerinde etkileşimli sorgular çalıştırmak için HDInsight kümesi kullanmayı öğrenmek için sonraki öğreticiye ilerleyin.