Varyantları kullanarak istemleri ayarlama
İyi bir istem oluşturmak, çok fazla yaratıcılık, netlik ve ilgi gerektiren zorlu bir görevdir. İyi bir istem, önceden eğitilmiş bir dil modelinden istenen çıkışı elde edebilirken, hatalı bir istem yanlış, ilgisiz veya önemsiz çıkışlara yol açabilir. Bu nedenle, farklı görevler ve etki alanları için performanslarını ve sağlamlıklarını iyileştirmek için istemleri ayarlamak gerekir.
Bu nedenle, modelin davranışını farklı sözcükler, biçimlendirme, bağlam, sıcaklık veya üst k gibi farklı koşullar altında test edebilmenize yardımcı olabilecek çeşitlemeler kavramını tanıtıyoruz. Modelin doğruluğunu, çeşitliliğini veya tutarlılığını en üst düzeye çıkaran en iyi istem ve yapılandırmayı karşılaştırıp buluyoruz.
Bu makalede, istemleri ayarlamak ve farklı varyantların performansını değerlendirmek için varyantları nasıl kullanacağınızı göstereceğiz.
Önkoşullar
Bu makaleyi okumadan önce şunları yapmak daha iyidir:
Çeşitlemeler kullanarak istemleri ayarlama
Bu makalede, örnek olarak Web Sınıflandırması örnek akışını kullanacağız.
Örnek akışı açın ve başlangıç olarak prepare_examples düğümünü kaldırın.

classify_with_llm düğümünde temel istem olarak aşağıdaki istemi kullanın.

Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
The output shoule be in this format: {"category": "App", "evidence": "Both"}
OUTPUT:
Bu akışı iyileştirmek için birden çok yol olabilir ve iki yön aşağıdadır:
classify_with_llm düğüm için: Topluluktan ve makalelerden daha düşük bir sıcaklığın daha yüksek hassasiyet ama daha az yaratıcılık ve sürpriz verdiğini öğrendim, bu nedenle düşük sıcaklık sınıflandırma görevleri için uygundur ve ayrıca az çekim istem LLM performansını artırabilir. Bu nedenle, sıcaklık 1'den 0'a değiştiğinde ve istem birkaç deneme örneğiyle olduğunda akışımın nasıl davrandığını test etmek istiyorum.
summarize_text_content düğüm için: Ayrıca, daha fazla metin içeriğinin performansı iyileştirmeye yardımcı olup olmadığını görmek için özeti 100 sözcükten 300'e değiştirdiğimde akışımın davranışını test etmek istiyorum.
Çeşitlemeler oluşturma
- LLM düğümünün sağ üst kısmındaki Varyantları göster düğmesini seçin. Mevcut LLM düğümü variant_0 ve varsayılan değişkendir.
- variant_1 oluşturmak için variant_0'da Kopyala düğmesini seçin, ardından parametreleri farklı değerlere yapılandırabilir veya variant_1'da istemi güncelleştirebilirsiniz.
- Daha fazla değişken oluşturmak için adımı yineleyin.
- Daha fazla değişken eklemeyi durdurmak için Varyantları gizle'yi seçin. Tüm çeşitler katlanır. Düğüm için varsayılan değişken gösterilir.
variant_0 temelinde classify_with_llm düğüm için:
- Sıcaklığın 1'den 0'a değiştirildiği variant_1 oluşturun.
- Sıcaklığın 0 olduğu variant_2 oluşturun ve birkaç çekim örneği de dahil olmak üzere aşağıdaki istemi kullanabilirsiniz.
Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
Here are a few examples:
URL: https://play.google.com/store/apps/details?id=com.spotify.music
Text content: Spotify is a free music and podcast streaming app with millions of songs, albums, and original podcasts. It also offers audiobooks, so users can enjoy thousands of stories. It has a variety of features such as creating and sharing music playlists, discovering new music, and listening to popular and exclusive podcasts. It also has a Premium subscription option which allows users to download and listen offline, and access ad-free music. It is available on all devices and has a variety of genres and artists to choose from.
OUTPUT: {"category": "App", "evidence": "Both"}
URL: https://www.youtube.com/channel/UC_x5XG1OV2P6uZZ5FSM9Ttw
Text content: NFL Sunday Ticket is a service offered by Google LLC that allows users to watch NFL games on YouTube. It is available in 2023 and is subject to the terms and privacy policy of Google LLC. It is also subject to YouTube's terms of use and any applicable laws.
OUTPUT: {"category": "Channel", "evidence": "URL"}
URL: https://arxiv.org/abs/2303.04671
Text content: Visual ChatGPT is a system that enables users to interact with ChatGPT by sending and receiving not only languages but also images, providing complex visual questions or visual editing instructions, and providing feedback and asking for corrected results. It incorporates different Visual Foundation Models and is publicly available. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models.
OUTPUT: {"category": "Academic", "evidence": "Text content"}
URL: https://ab.politiaromana.ro/
Text content: There is no content available for this text.
OUTPUT: {"category": "None", "evidence": "None"}
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
OUTPUT:
summarize_text_content düğümde, variant_0 temelinde, variant_1 oluşturabilirsiniz; burada 100 words komut isteminde sözcüklere 300 değiştirilir.
Şimdi akış aşağıdaki gibi görünüyor: summarize_text_content düğüm için 2 değişken ve classify_with_llm düğüm için 3.

Tek bir veri satırıyla tüm varyantları çalıştırma ve çıkışları denetleme
Tüm değişkenlerin başarıyla çalıştırıldığından ve beklendiği gibi çalıştığından emin olmak için akışı test etmek üzere tek bir veri satırıyla çalıştırabilirsiniz.
Not
Her seferinde çalıştırılacak varyantları olan yalnızca bir LLM düğümü seçebilirsiniz, diğer LLM düğümleri ise varsayılan değişkeni kullanır.
Bu örnekte, hem summarize_text_content düğüm hem de classify_with_llm düğüm için varyantları yapılandıracağız, bu nedenle tüm varyantları test etmek için iki kez çalıştırmanız gerekir.
- Sağ üstteki Çalıştır düğmesini seçin.
- Varyantları olan bir LLM düğümü seçin. Diğer LLM düğümleri varsayılan değişkenini kullanır.
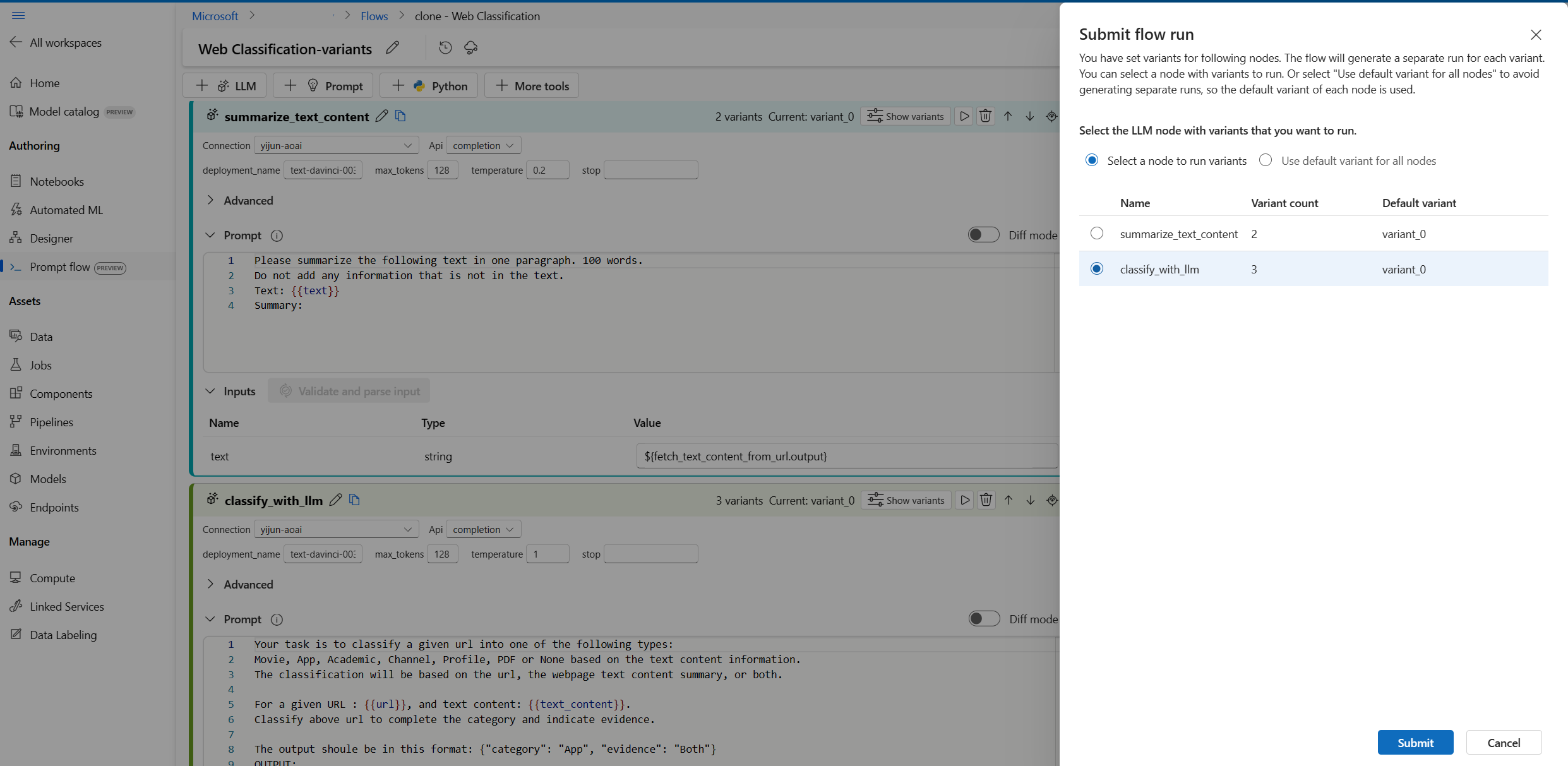
- Akış çalıştırmasını gönderin.
- Akış çalıştırması tamamlandıktan sonra, her değişken için karşılık gelen sonucu de kontrol edebilirsiniz.
- Değişkenli diğer LLM düğümüyle başka bir akış çalıştırması gönderin ve çıkışları denetleyin.
- Başka bir giriş verilerini değiştirebilir (örneğin, Wikipedia sayfası URL'sini kullanabilir) ve farklı verilerin değişkenlerini test etmek için yukarıdaki adımları yineleyebilirsiniz.

Varyantları değerlendirme
Değişkenleri birkaç tek veri parçasıyla çalıştırdığınızda ve sonuçları çıplak gözle kontrol ettiğinizde, gerçek dünya verilerinin karmaşıklığını ve çeşitliliğini yansıtamaz; bu arada çıkış ölçülebilir değildir, bu nedenle farklı varyantların etkinliğini karşılaştırmak zordur, ardından en iyiyi seçin.
En uygun olanı bulmanıza yardımcı olmak için değişkenlerini büyük miktarda veriyle test etmenizi ve ölçümlerle değerlendirmenizi sağlayan bir toplu iş çalıştırması gönderebilirsiniz.
İlk olarak, istem akışıyla çözmek istediğiniz gerçek dünya sorununu yeterince temsil eden bir veri kümesi hazırlamanız gerekir. Bu örnekte URL'lerin ve bunların sınıflandırma temeli gerçeğinin listesi verilmiştir. Varyantların performansını değerlendirmek için doğruluğu kullanacağız.
Sayfanın sağ üst kısmındaki Değerlendir'i seçin.
Batch çalıştırması ve Değerlendirmesi için bir sihirbaz oluşur. İlk adım, tüm değişkenlerini çalıştırmak için bir düğüm seçmektir.
Bir akıştaki her düğümde farklı değişkenlerin ne kadar iyi çalıştığını test etmek için, her düğüm için farklı değişkenlere sahip bir toplu iş çalıştırması çalıştırmanız gerekir. Bu, diğer düğümlerin değişkenlerinin etkisini önlemenize ve bu düğümün varyantlarının sonuçlarına odaklanmanıza yardımcı olur. Bu, denetimli denemenin kuralına uyar. Bu, bir kerede yalnızca bir şeyi değiştirdiğiniz ve diğer her şeyi aynı tuttuğunuz anlamına gelir.
Örneğin, tüm varyantları çalıştırmak için classify_with_llm düğüm seçebilirsiniz, summarize_text_content düğümü bu toplu çalıştırma için varsayılan değişkenini kullanır.
Batch çalıştırma ayarları bölümünde toplu çalıştırma adını ayarlayabilir, bir çalışma zamanı seçebilir ve hazırlanan verileri karşıya yükleyebilirsiniz.
Ardından Değerlendirme ayarları'nda bir değerlendirme yöntemi seçin.
Bu akış sınıflandırma için olduğundan, doğruluğu değerlendirmek için Sınıflandırma Doğruluğu Değerlendirme yöntemini seçebilirsiniz.
Doğruluk, akış (tahmin) tarafından atanan tahmin edilen etiketleri gerçek veri etiketleriyle (temel gerçek) karşılaştırarak ve bunların kaç tanesinin eşleşeceğini sayarak hesaplanır.
Değerlendirme giriş eşlemesi bölümünde, temel gerçeğin giriş veri kümesinin kategori sütunundan geldiğini ve tahminin akış çıkışlarından birinden geldiğini belirtmeniz gerekir: kategori.
Tüm ayarları gözden geçirdikten sonra toplu çalıştırmayı gönderebilirsiniz.
Çalıştırma gönderildikten sonra bağlantıyı seçin ve çalıştırma ayrıntıları sayfasına gidin.
Not
Çalıştırmanın tamamlanması birkaç dakika sürebilir.
Çıktıları görselleştirme
- Toplu çalıştırma ve değerlendirme çalıştırması tamamlandıktan sonra, çalıştırma ayrıntıları sayfasında, her değişken için toplu iş çalıştırmalarını çoklu seçin ve ardından Çıktıları görselleştir'i seçin. classify_with_llm düğümü için 3 varyasyonun ölçümlerini ve her veri kaydı için LLM tarafından tahmin edilen çıkışları görürsünüz.
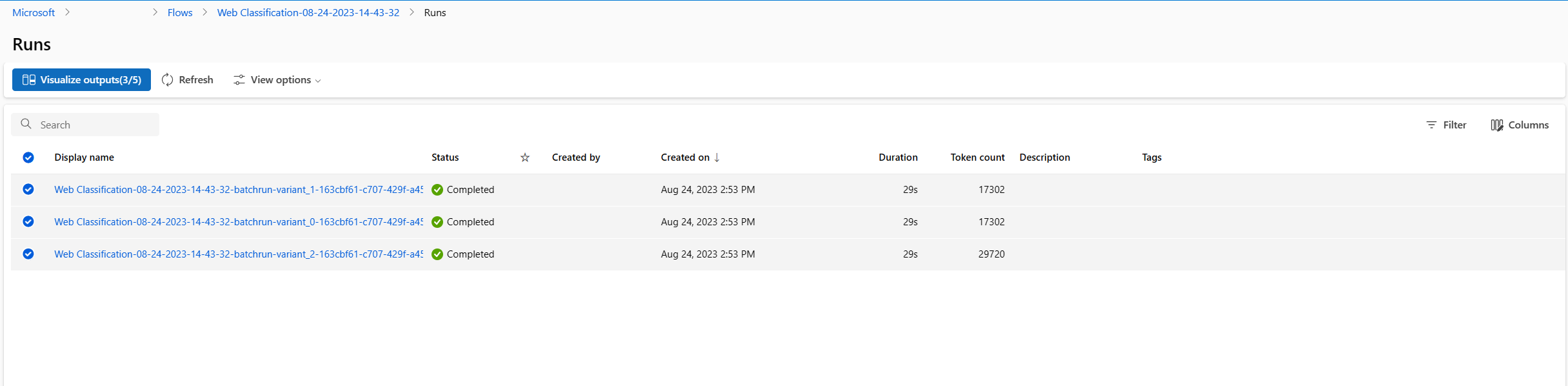
- Hangi değişkenin en iyi olduğunu belirledikten sonra akış yazma sayfasına geri dönebilir ve bu değişkeni düğümün varsayılan değişkeni olarak ayarlayabilirsiniz
- Summarize_text_content düğümünün değişkenlerini değerlendirmek için yukarıdaki adımları yineleyebilirsiniz.
Şimdi, değişkenleri kullanarak istemleri ayarlama işlemini tamamladınız. LLM düğümü için en iyi değişkeni bulmak için bu tekniği kendi istem akışınıza uygulayabilirsiniz.