Azure Data Lake Storage 2. Nesil kullanmak için en iyi yöntemler
Bu makalede performansı iyileştirmenize, maliyetleri azaltmanıza ve Data Lake Storage 2. Nesil etkin Azure Depolama hesabınızın güvenliğini sağlamanıza yardımcı olan en iyi uygulama yönergeleri sağlanır.
Veri gölü yapılandırmayla ilgili genel öneriler için şu makalelere bakın:
- Veri yönetimi ve analiz senaryosu için Azure Data Lake Depolama genel bakış
- Her veri giriş bölgesi için üç Azure Data Lake Storage 2. Nesil hesabı sağlama
Belgeleri arayın
Azure Data Lake Storage 2. Nesil ayrılmış bir hizmet veya hesap türü değildir. Yüksek aktarım hızı analiz iş yüklerini destekleyen bir özellik kümesidir. Data Lake Storage 2. Nesil belgeleri, bu özellikleri kullanmaya yönelik en iyi yöntemleri ve yönergeleri sağlar. Hesap yönetiminin ağ güvenliğini ayarlama, yüksek kullanılabilirlik için tasarlama ve olağanüstü durum kurtarma gibi diğer tüm yönleri için Blob depolama belge içeriğine bakın.
Özellik desteğini ve bilinen sorunları değerlendirme
Hesabınızı Blob depolama özelliklerini kullanacak şekilde yapılandırırken aşağıdaki deseni kullanın.
Bir özelliğin hesabınızda tam olarak desteklenip desteklenmediğini belirlemek için Azure Depolama hesaplarında Blob Depolama özellik desteği makalesini gözden geçirin. Bazı özellikler henüz desteklenmediğinden veya etkinleştirilmiş Data Lake Storage 2. Nesil hesaplarda kısmi desteğe sahiptir. Özellik desteği her zaman genişlediğinden güncelleştirmeler için bu makaleyi düzenli aralıklarla gözden geçirmeyi unutmayın.
Kullanmak istediğiniz özellikle ilgili sınırlamalar veya özel yönergeler olup olmadığını görmek için Azure Data Lake Storage 2. Nesil ile ilgili bilinen sorunlar makalesini gözden geçirin.
Data Lake Storage 2. Nesil etkin hesaplara özgü yönergeler için özellik makalelerini tarayın.
Belgelerde kullanılan terimleri anlama
İçerik kümeleri arasında hareket ettikçe bazı küçük terminoloji farklılıkları fark edeceksiniz. Örneğin, Blob depolama belgelerinde yer alan içerik, dosya yerine blob terimini kullanır. Teknik olarak, depolama hesabınıza alınan dosyalar hesabınızda blob haline gelir. Bu nedenle, terim doğrudur. Ancak blob terimi, dosya terimine alışkınsanız karışıklığa neden olabilir. Ayrıca bir dosya sistemine başvurmak için kullanılan kapsayıcı terimini de görürsünüz. Bu terimleri eş anlamlı olarak düşünün.
Premium'a göz önünde bulundurun
İş yükleriniz düşük tutarlı bir gecikme süresi gerektiriyorsa ve/veya saniyede yüksek sayıda giriş çıkış işlemi (IOP) gerektiriyorsa premium blok blob depolama hesabı kullanmayı göz önünde bulundurun. Bu tür bir hesap, verileri yüksek performanslı donanım aracılığıyla kullanılabilir hale getirir. Veriler, düşük gecikme süresi için iyileştirilmiş katı hal sürücülerinde (SSD) depolanır. SSD'ler geleneksel sabit sürücülere kıyasla daha yüksek aktarım hızı sağlar. Premium performansın depolama maliyetleri daha yüksektir, ancak işlem maliyetleri daha düşüktür. Bu nedenle, iş yükleriniz çok sayıda işlem yürütürse premium performans blok blobu hesabı ekonomik olabilir.
Depolama hesabınız analiz için kullanılacaksa, premium blok blob depolama hesabıyla birlikte Azure Data Lake Storage 2. Nesil kullanmanızı kesinlikle öneririz. Data Lake Depolama etkin bir hesapla birlikte premium blok blob depolama hesaplarını kullanmanın bu birleşimi, Azure Data Lake Depolama için premium katman olarak adlandırılır.
Veri alımı için iyileştirme
Bir kaynak sistemden veri alırken, kaynak donanım, kaynak ağ donanımı veya depolama hesabınıza ağ bağlantısı bir performans sorunu olabilir.
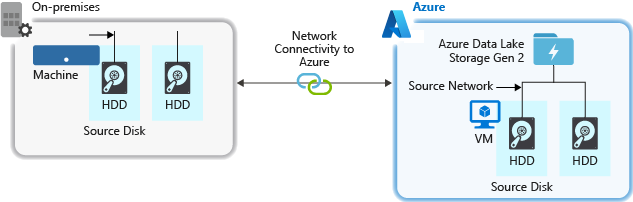
Kaynak donanım
İster şirket içi makineleri ister Azure'da Sanal Makineler (VM) kullanıyor olun, uygun donanımı dikkatle seçtiğinizden emin olun. Disk donanımı için Katı Hal Sürücüleri (SSD) kullanmayı ve daha hızlı iş milleri olan disk donanımlarını seçmeyi göz önünde bulundurun. Ağ donanımı için mümkün olan en hızlı Ağ Arabirimi Denetleyicileri'ni (NIC) kullanın. Azure'da, uygun güçlü disk ve ağ donanımına sahip Azure D14 VM'lerini öneririz.
Depolama hesabına ağ bağlantısı
Kaynak verilerinizle depolama hesabınız arasındaki ağ bağlantısı bazen bir performans sorununa neden olabilir. Kaynak verileriniz şirket içindeyken Azure ExpressRoute ile ayrılmış bir bağlantı kullanmayı göz önünde bulundurun. Kaynak verileriniz Azure'daysa, veriler Data Lake Storage 2. Nesil etkin hesabınızla aynı Azure bölgesinde olduğunda performans en iyisidir.
Maksimum paralelleştirme için veri alımı araçlarını yapılandırma
En iyi performansı elde etmek için mümkün olduğunca çok okuma ve yazma işlemini paralel olarak gerçekleştirerek kullanılabilir tüm aktarım hızını kullanın.
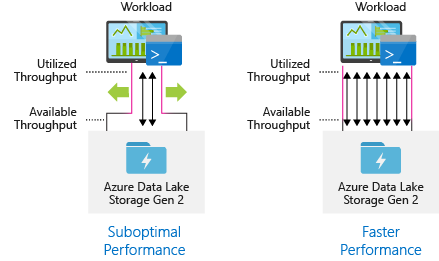
Aşağıdaki tabloda, çeşitli popüler alım araçlarının temel ayarları özetlemektedir.
| Araç | Ayarlar |
|---|---|
| DistCp | -m (eşleştirici) |
| Azure Data Factory | parallelCopies |
| Sqoop | fs.azure.block.size, -m (eşleyici) |
Not
Alma işlemlerinizin genel performansı, verileri almak için kullandığınız ara çubuğuna özgü diğer faktörlere bağlıdır. En iyi güncel yönergeler için kullanmayı düşündüğünüz her aracın belgelerine bakın.
Hesabınız tüm analiz senaryoları için gerekli aktarım hızını sağlayacak şekilde ölçeklendirilebilir. Varsayılan olarak, Data Lake Storage 2. Nesil etkin bir hesap, geniş bir kullanım örneği kategorisinin gereksinimlerini karşılamak için varsayılan yapılandırmasında yeterli aktarım hızı sağlar. Varsayılan sınırla karşılaşırsanız hesap, Azure Desteği'ne başvurarak daha fazla aktarım hızı sağlayacak şekilde yapılandırılabilir.
Veri kümelerini yapılandırma
Verilerinizin yapısını önceden planlamayı göz önünde bulundurun. Dosya biçimi, dosya boyutu ve dizin yapısı performansı ve maliyeti etkileyebilir.
Dosya biçimleri
Veriler çeşitli biçimlerde alınabiliyor. Veriler JSON, CSV veya XML gibi okunabilir biçimlerde veya gibi .tar.gzsıkıştırılmış ikili biçimlerde görünebilir. Veriler çeşitli boyutlarda da gelebilir. Veriler, sql tablosunun şirket içi sistemlerinizden dışarı aktarılmış verileri gibi büyük dosyalardan (birkaç terabayt) oluşabilir. Veriler, nesnelerin İnterneti (IoT) çözümünden gerçek zamanlı olaylardaki veriler gibi çok sayıda küçük dosya (birkaç kilobayt) biçiminde de gelebilir. Uygun bir dosya biçimi ve dosya boyutu seçerek verimliliği ve maliyetleri iyileştirebilirsiniz.
Hadoop, yapılandırılmış verileri depolamak ve işlemek için iyileştirilmiş bir dosya biçimleri kümesini destekler. Bazı yaygın biçimler Avro, Parquet ve İyileştirilmiş Satır Sütunlu (ORC) biçimidir. Bu biçimlerin tümü makine tarafından okunabilir ikili dosya biçimleridir. Dosya boyutunu yönetmenize yardımcı olmak için sıkıştırılırlar. Her dosyaya eklenmiş bir şemaları vardır ve bu da kendilerini açıklayıcı hale getirir. Bu biçimler arasındaki fark, verilerin nasıl depolandığıdır. Avro verileri satır tabanlı biçimde, Parquet ve ORC biçimleri ise verileri sütunlu biçimde depolar.
G/Ç desenlerinizin daha fazla yazma ağır olduğu veya sorgu desenlerinin tamamen birden çok kayıt satırını almayı tercih ettiği durumlarda Avro dosya biçimini kullanmayı göz önünde bulundurun. Örneğin Avro biçimi, ardı ardına birden çok olay/ileti yazan Event Hubs veya Kafka gibi bir ileti veri yolu ile düzgün çalışır.
G/Ç desenleri daha yoğun okunduğunda veya sorgu desenleri kayıtlardaki sütunların bir alt kümesine odaklandığında Parquet ve ORC dosya biçimlerini göz önünde bulundurun. Okuma işlemleri, kaydın tamamını okumak yerine belirli sütunları alacak şekilde iyileştirilebilir.
Apache Parquet, okuma ağır analiz işlem hatları için iyileştirilmiş bir açık kaynak dosya biçimidir. Parquet'in sütunlu depolama yapısı, ilgili olmayan verileri atlamanızı sağlar. Sorgularınız, depolamadan analiz altyapısına gönderilecek verilerin kapsamını daraltabildiğinden çok daha verimlidir. Ayrıca, benzer veri türleri (sütun için) birlikte depolandığından Parquet, veri depolama maliyetlerini düşürebilen verimli veri sıkıştırma ve kodlama düzenlerini destekler. Azure Synapse Analytics, Azure Databricks ve Azure Data Factory gibi hizmetler Parquet dosya biçimlerinden yararlanan yerel işlevlere sahiptir.
Dosya boyutu
Daha büyük dosyalar daha iyi performansa ve düşük maliyetlere yol açar.
HDInsight gibi analiz altyapıları genellikle listeleme, erişimi denetleme ve çeşitli meta veri işlemlerini gerçekleştirme gibi görevleri içeren dosya başına ek yüke sahiptir. Verilerinizi çok sayıda küçük dosya olarak depolarsanız, bu durum performansı olumsuz etkileyebilir. Genel olarak, daha iyi performans için verilerinizi daha büyük boyutlu dosyalar halinde düzenleyin (boyutu 256 MB ile 100 GB arası). Bazı altyapılar ve uygulamalar, boyutu 100 GB'tan büyük dosyaları verimli bir şekilde işlerken sorun yaşayabilir.
Dosya boyutunun artırılması işlem maliyetlerini de azaltabilir. Okuma ve yazma işlemleri 4 megabaytlık artışlarla faturalandırılır, bu nedenle dosyada 4 megabayt veya yalnızca birkaç kilobayt bulunup bulunmadığına bakılmaksızın işlem için ücretlendirilirsiniz. Fiyatlandırma bilgileri için bkz. Azure Data Lake Depolama fiyatlandırması.
Bazen veri işlem hatlarının ham veriler üzerinde denetimi sınırlıdır ve bu da çok sayıda küçük dosyaya sahiptir. Genel olarak, sisteminizin aşağı akış uygulamaları tarafından kullanılmak üzere küçük dosyaları daha büyük dosyalar halinde toplamaya yönelik bir tür işlemi olmasını öneririz. Verileri gerçek zamanlı olarak işliyorsanız, verilerinizi daha büyük dosyalar olarak depolamak için bir ileti aracısı (Event Hubs veya Apache Kafka gibi) ile birlikte gerçek zamanlı bir akış altyapısı (Azure Stream Analytics veya Spark Streaming gibi) kullanabilirsiniz. Küçük dosyaları daha büyük dosyalar halinde toplarken, aşağı akış işleme için Apache Parquet gibi okuma için iyileştirilmiş bir biçimde kaydetmeyi göz önünde bulundurun.
Dizin yapısı
Her iş yükünün verilerin nasıl tüketilmesiyle ilgili farklı gereksinimleri vardır, ancak bunlar Nesnelerin İnterneti (IoT), toplu iş senaryoları veya zaman serisi verileri için iyileştirme yaparken dikkate alınması gereken bazı yaygın düzenlerdir.
IoT yapısı
IoT iş yüklerinde çok sayıda ürün, cihaz, kuruluş ve müşteriye yayılan çok sayıda veri alınabilir. Aşağı akış tüketicileri için verilerin kuruluş, güvenlik ve verimli bir şekilde işlenmesi için dizin düzenini önceden planlamak önemlidir. Dikkate alınması gereken genel bir şablon aşağıdaki düzende olabilir:
- {Region}/{SubjectMatter(s)}/{yyyy}/{mm}/{dd}/{hh}/
Örneğin, İngiltere'de bir uçak motoru için iniş telemetrisi aşağıdaki yapı gibi görünebilir:
- UK/Planes/BA1293/Engine1/2017/08/11/12/
Bu örnekte, tarihi dizin yapısının sonuna koyarak ACL'leri kullanarak bölgeleri daha kolay güvenli hale getirmek ve belirli kullanıcı ve grupların konularını daha kolay güvenli hale getirmek için kullanabilirsiniz. Tarih yapısını en başa koyarsanız, bu bölgelerin ve konu konularının güvenliğini sağlamak çok daha zor olacaktır. Örneğin, yalnızca Birleşik Krallık verilerine veya belirli düzlemlere erişim sağlamak istiyorsanız, her saat dizini altında çok sayıda dizin için ayrı bir izin uygulamanız gerekir. Bu yapı, zaman geçtikçe dizin sayısını da katlanarak artıracaktır.
Toplu iş yapısı
Toplu işlemede yaygın olarak kullanılan bir yaklaşım, verileri "in" dizinine yerleştirmektir. Ardından veriler işlendikten sonra, aşağı akış işlemlerinin tüketmesi için yeni verileri bir "out" dizinine yerleştirin. Bu dizin yapısı bazen tek tek dosyalar üzerinde işleme gerektiren işler için kullanılır ve büyük veri kümeleri üzerinde büyük ölçüde paralel işleme gerektirmeyebilir. Yukarıda önerilen IoT yapısı gibi iyi bir dizin yapısı, bölge ve konu konuları (örneğin kuruluş, ürün veya üretici) gibi konular için üst düzey dizinlere sahiptir. İşlemede daha iyi düzenleme, filtrelenmiş aramalar, güvenlik ve otomasyon sağlamak için yapıdaki tarih ve saati göz önünde bulundurun. Tarih yapısının ayrıntı düzeyi, verilerin karşıya yüklendiği veya işlendiği zaman aralığına (saatlik, günlük, hatta aylık gibi) göre belirlenir.
Bazen veri bozulması veya beklenmeyen biçimler nedeniyle dosya işleme başarısız olur. Bu gibi durumlarda, dizin yapısı dosyaları daha fazla inceleme için taşımak üzere /bad klasöründen yararlanabilir. Toplu iş, el ile müdahale için bu hatalı dosyaların raporlamasını veya bildirimini de işleyebilir. Aşağıdaki şablon yapısını göz önünde bulundurun:
- {Region}/{SubjectMatter(s)}/In/{yy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Out/{yy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Bad/{yy}/{mm}/{dd}/{hh}/
Örneğin, bir pazarlama firması Kuzey Amerika'da müşterilerinden müşteri güncelleştirmelerinin günlük veri ayıklamalarını alır. İşlenmeden önce ve işlendikten sonra aşağıdaki kod parçacığı gibi görünebilir:
- NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
Toplu verilerin doğrudan Hive veya geleneksel SQL veritabanları gibi veritabanlarına işlenmesi durumunda, çıkış Hive tablosu veya dış veritabanı için ayrı bir klasöre zaten gittiği için /in veya /out dizinine gerek yoktur. Örneğin, müşterilerden günlük ayıklamalar ilgili dizinlerine iner. Ardından Azure Data Factory, Apache Oozie veya Apache Airflow gibi bir hizmet, verileri işlemek ve bir Hive tablosuna yazmak için günlük bir Hive veya Spark işini tetikler.
Zaman serisi veri yapısı
Hive iş yükleri için, zaman serisi verilerinin bölüm ayıklaması bazı sorguların verilerin yalnızca bir alt kümesini okumalarına yardımcı olabilir ve bu da performansı artırır.
Zaman serisi verilerini alınan bu işlem hatları genellikle dosyalarını dosyalar ve klasörler için yapılandırılmış bir adlandırma ile yerleştirir. Tarihe göre yapılandırılmış veriler için gördüğümüz yaygın bir örnek aşağıda verilmiştir:
/DataSet/YYYY/AA/GG/datafile_YYYY_MM_DD.tsv
Tarih saat bilgilerinin hem klasör olarak hem de dosya adında göründüğüne dikkat edin.
Tarih ve saat için aşağıdakiler ortak bir desendir
/DataSet/YYYY/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
Yine, klasör ve dosya düzenlemesi ile yaptığınız seçim, daha büyük dosya boyutları ve her klasördeki makul sayıda dosya için iyileştirilmelidir.
Güvenliği ayarlama
Blob depolama için güvenlik önerileri makalesindeki önerileri gözden geçirerek başlayın. Verilerinizi yanlışlıkla veya kötü amaçlı silmeye karşı koruma, güvenlik duvarının arkasındaki verilerin güvenliğini sağlama ve kimlik yönetiminin temeli olarak Microsoft Entra Id kullanma hakkında en iyi uygulama kılavuzunu bulacaksınız.
Ardından, etkinleştirilmiş Data Lake Storage 2. Nesil hesaplara özgü yönergeler için Azure Data Lake Storage 2. Nesil makaledeki Erişim denetimi modelini gözden geçirin. Bu makale, hiyerarşik dosya sisteminizdeki dizinler ve dosyalar üzerinde güvenlik izinlerini zorlamak için Azure rol tabanlı erişim denetimi (Azure RBAC) rollerini erişim denetim listeleri (ACL' ler) ile birlikte kullanmayı anlamanıza yardımcı olur.
Alma, işleme ve analiz etme
Birçok farklı veri kaynağı ve bu verilerin Data Lake Storage 2. Nesil etkin bir hesaba alınabilmesinin farklı yolları vardır.
Örneğin, HDInsight ve Hadoop kümelerinden büyük veri kümeleri veya uygulama prototipi için daha küçük geçici veri kümeleri alabilirsiniz. Uygulamalar, cihazlar ve algılayıcılar gibi çeşitli kaynaklar tarafından oluşturulan akışlı verileri alabilirsiniz. Bu tür veriler için araçları kullanarak verileri gerçek zamanlı olarak olay temelinde yakalayıp işleyebilir ve ardından olayları toplu olarak hesabınıza yazabilirsiniz. Sayfa isteklerinin geçmişi gibi bilgiler içeren web sunucusu günlüklerini de alabilirsiniz. Günlük verileri için, büyük büyük veri uygulamanızın parçası olarak veri yükleme bileşeninizi dahil etme esnekliğine sahip olmak için bunları karşıya yüklemek üzere özel betikler veya uygulamalar yazmayı göz önünde bulundurun.
Veriler hesabınızda kullanılabilir duruma gelince bu veriler üzerinde analiz çalıştırabilir, görselleştirmeler oluşturabilir ve hatta verileri yerel makinenize veya Azure SQL veritabanı veya SQL Server örneği gibi diğer depolara indirebilirsiniz.
Aşağıdaki tabloda verileri almak, çözümlemek, görselleştirmek ve indirmek için kullanabileceğiniz araçlar önerilir. Her aracı yapılandırma ve kullanma yönergelerini bulmak için bu tablodaki bağlantıları kullanın.
| Purpose | Araçlar ve Araç kılavuzu |
|---|---|
| Geçici verileri alma | Azure portalı, Azure PowerShell, Azure CLI, REST, Azure Depolama Gezgini, Apache DistCp, AzCopy |
| İlişkisel verileri alma | Azure Data Factory |
| Web sunucusu günlüklerini alma | Azure PowerShell, Azure CLI, REST, Azure SDK'ları (.NET, Java, Python ve Node.js), Azure Data Factory |
| HDInsight kümelerinden alma | Azure Data Factory, Apache DistCp, AzCopy |
| Hadoop kümelerinden alma | Azure Data Factory, Apache DistCp, WANdisco LiveData Migrator for Azure, Azure Data Box |
| Büyük veri kümelerini alma (birkaç terabayt) | Azure ExpressRoute |
| Verileri işleme ve analiz etme | Azure Synapse Analytics, Azure HDInsight, Databricks |
| Verileri görselleştirme | Power BI, Azure Data Lake Depolama sorgu hızlandırma |
| Verileri indirme | Azure portalı, PowerShell, Azure CLI, REST, Azure SDK'ları (.NET, Java, Python ve Node.js), Azure Depolama Gezgini, AzCopy, Azure Data Factory, Apache DistCp |
Not
Bu tablo, Data Lake Storage 2. Nesil destekleyen Azure hizmetlerinin tam listesini yansıtmaz. Desteklenen Azure hizmetlerinin listesini ve destek düzeylerini görmek için bkz. Azure Data Lake Storage 2. Nesil destekleyen Azure hizmetleri.
Telemetriyi izleme
Kullanımı ve performansı izlemek, hizmetinizi kullanıma hazır hale getirmenin önemli bir parçasıdır. Örnekler arasında sık yapılan işlemler, yüksek gecikme süresine sahip işlemler veya hizmet tarafı azaltmaya neden olan işlemler verilebilir.
Depolama hesabınızın tüm telemetri verilerini Azure İzleyici'deki Azure Depolama günlükleri aracılığıyla kullanabilirsiniz. Bu özellik, depolama hesabınızı Log Analytics ve Event Hubs ile tümleştirir ve günlükleri başka bir depolama hesabına arşivlemenizi sağlar. Ölçümlerin ve kaynak günlüklerinin ve ilişkili şemalarının tam listesini görmek için bkz. Azure Depolama izleme verileri başvurusu.
Günlüklerinizi nerede depolamayı seçtiğiniz, bunlara nasıl erişmeyi planladığınıza bağlıdır. Örneğin, günlüklerinize gerçek zamanlıya yakın bir şekilde erişmek ve günlüklerdeki olayları Azure İzleyici'deki diğer ölçümlerle ilişkilendirmek istiyorsanız günlüklerinizi bir Log Analytics çalışma alanında depolayabilirsiniz. Ardından, çalışma alanınızdaki tabloyu numaralandıran StorageBlobLogs KQL ve yazar sorguları kullanarak günlüklerinizi sorgulayın.
Günlüklerinizi hem gerçek zamanlıya yakın sorgu hem de uzun süreli saklama için depolamak istiyorsanız, tanılama ayarlarınızı günlükleri hem Log Analytics çalışma alanına hem de depolama hesabına gönderecek şekilde yapılandırabilirsiniz.
Günlüklerinize Splunk gibi başka bir sorgu altyapısı üzerinden erişmek istiyorsanız, tanılama ayarlarınızı günlükleri bir olay hub'ına gönderecek ve günlükleri olay hub'ından seçtiğiniz hedefe gönderecek şekilde yapılandırabilirsiniz.
Azure İzleyici'deki Azure Depolama günlükleri Azure portalı, PowerShell, Azure CLI ve Azure Resource Manager şablonları aracılığıyla etkinleştirilebilir. Ölçekli dağıtımlar için Azure İlkesi düzeltme görevleri için tam destekle birlikte kullanılabilir. Daha fazla bilgi için bkz. ciphertxt/Azure Depolama Policy.