Azure Synapse Analytics'de sunucusuz SQL havuzu sorunlarını giderme
Bu makale, Azure Synapse Analytics'te sunucusuz SQL havuzuyla ilgili en sık karşılaşılan sorunları giderme hakkında bilgi içerir.
Azure Synapse Analytics hakkında daha fazla bilgi edinmek için Genel Bakış'taki konulara bakın.
Synapse Studio
Synapse Studio , veritabanı erişim araçlarını yüklemeye gerek kalmadan tarayıcı kullanarak verilerinize erişmek için kullanabileceğiniz kullanımı kolay bir araçtır. Synapse Studio, büyük bir veri kümesini veya SQL nesnelerinin tam yönetimini okuyacak şekilde tasarlanmamıştır.
Sunucusuz SQL havuzu Synapse Studio'da gri gösteriliyor
Synapse Studio sunucusuz SQL havuzuna bağlantı kuramıyorsa sunucusuz SQL havuzunun gri olduğunu veya Çevrimdışı durumunu gösterdiğini fark edersiniz.
Bu sorun genellikle iki nedenden biri nedeniyle oluşur:
- Ağınız Azure Synapse Analytics arka ucuyla iletişimi engeller. En sık karşılaşılan durum, 1443 numaralı TCP bağlantı noktasının engellenmesidir. Sunucusuz SQL havuzunun çalışmasını sağlamak için bu bağlantı noktasının engelini kaldırın. Diğer sorunlar sunucusuz SQL havuzunun da çalışmasını engelleyebilir. Daha fazla bilgi için Sorun giderme kılavuzuna bakın.
- Sunucusuz SQL havuzunda oturum açma izniniz yok. Erişim kazanmak için Azure Synapse çalışma alanı yöneticisinin sizi çalışma alanı yöneticisi rolüne veya SQL yöneticisi rolüne eklemesi gerekir. Daha fazla bilgi için bkz . Azure Synapse erişim denetimi.
Websocket bağlantısı beklenmedik bir şekilde kapatıldı
Sorgunuz hata iletisiyle Websocket connection was closed unexpectedly. başarısız olabilir Bu ileti, örneğin bir ağ sorunu nedeniyle Synapse Studio'ya olan tarayıcı bağlantınızın kesildiği anlamına gelir.
- Bu sorunu çözmek için sorgunuzu yeniden çalıştırın.
- Daha fazla araştırma için Synapse Studio yerine aynı sorgular için Azure Data Studio veya SQL Server Management Studio'yu deneyin.
- Bu ileti ortamınızda sık sık oluşuyorsa ağ yöneticinizden yardım alın. Ayrıca güvenlik duvarı ayarlarını ve Sorun giderme kılavuzunu da denetleyebilirsiniz.
- Sorun devam ederse Azure portalı üzerinden bir destek bileti oluşturun.
Sunucusuz veritabanları Synapse Studio'da gösterilmiyor
Sunucusuz SQL havuzunda oluşturulan veritabanlarını görmüyorsanız sunucusuz SQL havuzunuzun başlatılıp başlatılmadığını denetleyin. Sunucusuz SQL havuzu devre dışı bırakılırsa veritabanları gösterilmez. Etkinleştirmek ve veritabanlarının görünmesini sağlamak için sunucusuz SQL havuzunda gibi SELECT 1herhangi bir sorguyu yürütebilirsiniz.
Synapse Sunucusuz SQL havuzu kullanılamıyor olarak görünüyor
Bu davranışın nedeni genellikle yanlış ağ yapılandırmasıdır. Bağlantı noktalarının düzgün yapılandırıldığından emin olun. Güvenlik duvarı veya özel uç noktalar kullanıyorsanız bu ayarları da denetleyin.
Son olarak, uygun rollerin verildiğinden ve iptal edilmemiş olduğundan emin olun.
İstek eski/süresi dolmuş anahtarı kullanacağı için yeni veritabanı oluşturulamıyor
Bu hata, şifreleme için kullanılan çalışma alanı müşteri tarafından yönetilen anahtarın değiştirilmesi nedeniyle oluşur. Çalışma alanında bulunan tüm verileri etkin anahtarın en son sürümüyle yeniden şifrelemeyi seçebilirsiniz. Yeniden şifrelemek için Azure portalındaki anahtarı geçici bir anahtarla değiştirin ve ardından şifreleme için kullanmak istediğiniz anahtara geri dönün. Burada çalışma alanı anahtarlarını yönetmeyi öğrenin.
Synapse sunucusuz SQL havuzu, aboneliği farklı bir Microsoft Entra kiracısına aktardıktan sonra kullanılamaz
Aboneliği başka bir Microsoft Entra kiracısına taşıdıysanız sunucusuz SQL havuzuyla ilgili bazı sorunlarla karşılaşabilirsiniz. Bir destek bileti oluşturun ve Azure desteği sorunu çözmek için sizinle iletişime geçin.
Depolama erişimi
Azure depolamadaki dosyalara erişmeye çalışırken hata alırsanız verilere erişme izniniz olduğundan emin olun. Genel kullanıma açık dosyalara erişebilmelisiniz. Verilere kimlik bilgileri olmadan erişmeye çalışırsanız, Microsoft Entra kimliğinizin dosyalara doğrudan erişebildiğinden emin olun.
Dosyalara erişmek için kullanmanız gereken bir paylaşılan erişim imzası anahtarınız varsa, bu kimlik bilgilerini içeren sunucu düzeyinde veya veritabanı kapsamlı bir kimlik bilgisi oluşturduğunuzdan emin olun. Çalışma alanı yönetilen kimliğini ve özel hizmet asıl adını (SPN) kullanarak verilere erişmeniz gerekiyorsa kimlik bilgileri gereklidir.
Azure Data Lake Storage'da dosyalar okunamıyor, listelenemez veya erişilemiyor
Microsoft Entra oturum açma bilgilerini açık kimlik bilgileri olmadan kullanıyorsanız, Microsoft Entra kimliğinizin depolamadaki dosyalara erişebildiğinden emin olun. Dosyalara erişmek için Microsoft Entra kimliğinizin Blob Veri Okuyucusu iznine veya ADLS'de Listele ve Oku erişim denetim listelerine (ACL) izinlerine sahip olması gerekir. Daha fazla bilgi için bkz . Dosya açılamadığı için sorgu başarısız oluyor.
Depolamaya kimlik bilgilerini kullanarak erişiyorsa, yönetilen kimliğinizin veya SPN'nizin Veri Okuyucusu veya Katkıda Bulunan rolüne veya belirli ACL izinlerine sahip olduğundan emin olun. Paylaşılan erişim imzası belirteci kullandıysanız, izni olduğundan rl ve süresinin dolmadığından emin olun.
SQL oturum açma bilgilerini ve OPENROWSET işlevi veri kaynağı olmadan kullanıyorsanız, depolama URI'sine uyan ve depolamaya erişim izni olan sunucu düzeyinde bir kimlik bilgileriniz olduğundan emin olun.
Dosya açılamadığı için sorgu başarısız oluyor
Sorgunuz hatayla File cannot be opened because it does not exist or it is used by another process başarısız olursa ve her iki dosyanın da var olduğundan ve başka bir işlem tarafından kullanılmadığınızdan eminseniz sunucusuz SQL havuzu dosyaya erişemez. Bu sorun genellikle Microsoft Entra kimliğinizin dosyaya erişme hakları olmaması veya bir güvenlik duvarının dosyaya erişimi engellemesi nedeniyle oluşur.
Sunucusuz SQL havuzu varsayılan olarak Microsoft Entra kimliğinizi kullanarak dosyaya erişmeye çalışır. Bu sorunu çözmek için dosyaya erişmek için uygun haklara sahip olmanız gerekir. En kolay yol, sorgulamaya çalıştığınız depolama hesabında kendinize bir Depolama Blobu Veri Katkıda Bulunanı rolü vermektir.
Daha fazla bilgi için bkz.
- Depolama için Microsoft Entra Id erişim denetimi
- Synapse Analytics'te sunucusuz SQL havuzu için depolama hesabı erişimini denetleme
Depolama Blobu Veri Katkıda Bulunanı rolüne alternatif
Kendinize Bir Depolama Blobu Veri Katkıda Bulunanı rolü vermek yerine, dosyaların bir alt kümesi üzerinde daha ayrıntılı izinler de vekleyebilirsiniz.
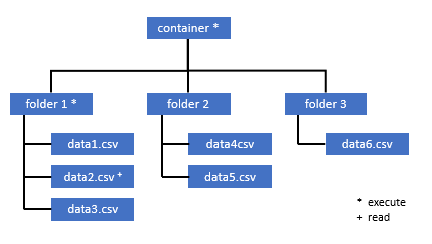
Bu kapsayıcıdaki bazı verilere erişmesi gereken tüm kullanıcıların da köke (kapsayıcı) kadar olan tüm üst klasörlerde EXECUTE iznine sahip olması gerekir.
Azure Data Lake Storage 2. Nesil'da ACL'leri ayarlama hakkında daha fazla bilgi edinin.
Not
Kapsayıcı düzeyinde yürütme izni Azure Data Lake Storage 2. Nesil içinde ayarlanmalıdır. Klasördeki izinler Azure Synapse içinde ayarlanabilir.
Bu örnekteki data2.csv sorgulamak istiyorsanız aşağıdaki izinler gereklidir:
- Kapsayıcıda yürütme izni
- Klasör1 üzerinde yürütme izni
- data2.csv okuma izni
Erişmek istediğiniz veriler üzerinde tam izinlere sahip bir yönetici kullanıcıyla Azure Synapse'te oturum açın.
Veri bölmesinde dosyaya sağ tıklayın ve Erişimi yönet'i seçin.
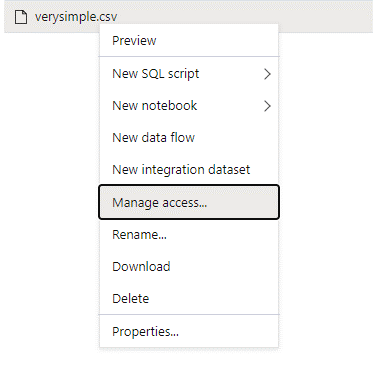
En azından Okuma izni'ne tıklayın. Kullanıcının UPN'sini veya nesne kimliğini girin; örneğin,
user@contoso.com. Ekle'yi seçin.Bu kullanıcı için okuma izni verin.

Not
Konuk kullanıcılar için bu adımın doğrudan Azure Synapse üzerinden yapılamadığı için Azure Data Lake ile yapılması gerekir.
Yoldaki dizinin içeriği listelenemiyor
Bu hata, Azure Data Lake'i sorgulayan kullanıcının depolamadaki dosyaları listeleyediğini gösterir. Bu hatanın gerçekleşebileceği çeşitli senaryolar vardır:
- Microsoft Entra doğrudan kimlik doğrulamasını kullanan Microsoft Entra kullanıcısının Data Lake Storage'daki dosyaları listeleme izni yoktur.
- Paylaşılan erişim imzası anahtarı veya çalışma alanı yönetilen kimliği kullanarak verileri okuyan Microsoft Entra Kimliği veya SQL kullanıcısı ve bu anahtar veya kimliğin depolamadaki dosyaları listeleme izni yoktur.
- Dataverse verilerine erişen ve Dataverse'deki verileri sorgulama izni olmayan kullanıcı. SQL kullanıcıları kullanıyorsanız bu senaryo gerçekleşebilir.
- Delta Lake'e erişen kullanıcının Delta Lake işlem günlüğünü okuma izni olmayabilir.
Bu sorunu çözmenin en kolay yolu, sorgulamaya çalıştığınız depolama hesabında kendinize Depolama Blobu Veri Katkıda Bulunanı rolü vermektir.
Daha fazla bilgi için bkz.
- Depolama için Microsoft Entra Id erişim denetimi
- Synapse Analytics'te sunucusuz SQL havuzu için depolama hesabı erişimini denetleme
Dataverse tablosunun içeriği listelenemiyor
Bağlantılı DataVerse tablolarını okumak için Dataverse için Azure Synapse Link kullanıyorsanız sunucusuz SQL havuzunu kullanarak bağlantılı verilere erişmek için Microsoft Entra hesabını kullanmanız gerekir. Daha fazla bilgi için bkz . Azure Data Lake ile Dataverse için Azure Synapse Link.
DataVerse tablosuna başvuran bir dış tabloyu okumak için SQL oturum açma bilgilerini kullanmayı denerseniz aşağıdaki hatayı alırsınız: External table '???' is not accessible because content of directory cannot be listed.
Dataverse dış tabloları her zaman Microsoft Entra geçiş kimlik doğrulamasını kullanır. Bunları paylaşılan erişim imzası anahtarı veya çalışma alanı yönetilen kimliği kullanacak şekilde yapılandıramazsınız.
Delta Lake işlem günlüğünün içeriği listelenemiyor
Sunucusuz SQL havuzu Delta Lake işlem günlüğü klasörünü okuyamıyorsa aşağıdaki hata döndürülür:
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
Klasörün var olduğundan emin _delta_log olun. Delta Lake biçimine dönüştürülmeyen düz Parquet dosyalarını sorgulıyorsunuz olabilir. _delta_log Klasör varsa, temel delta lake klasörleri üzerinde hem Okuma hem de Liste iznine sahip olduğunuzdan emin olun. kullanarak FORMAT='csv'json dosyalarını doğrudan okumayı deneyin. URI'nizi BULK parametresine yerleştirin:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
Bu sorgu başarısız olursa, çağıranın temel depolama dosyalarını okuma izni yoktur.
Sorgu yürütme
Aşağıdaki durumlarda sorgu yürütme sırasında hata alabilirsiniz:
- Çağıran bazı nesnelere erişemiyor.
- Sorgu dış verilere erişemiyor.
- Sorgu, sunucusuz SQL havuzlarında desteklenmeyen bazı işlevler içeriyor.
Geçerli kaynak kısıtlamaları nedeniyle yürütülemediği için sorgu başarısız oluyor
Sorgunuz şu hata iletisiyle This query cannot be executed due to current resource constraints. başarısız olabilir: Bu ileti sunucusuz SQL havuzunun şu anda yürütülememesi anlamına gelir. Bazı sorun giderme seçenekleri şunlardır:
- Makul boyutlarda veri türlerinin kullanıldığından emin olun.
- Sorgunuz Parquet dosyalarını hedefliyorsa, dize sütunları varsayılan olarak VARCHAR(8000) olacağından bu sütunlara açık türler tanımlamayı göz önünde bulundurun. Çıkarsanan veri türlerini denetleme.
- Sorgunuz CSV dosyalarını hedefliyorsa istatistik oluşturmanız faydalı olabilir.
- Sorgunuzu iyileştirmek için bkz. Sunucusuz SQL havuzu performansı için en iyi yöntemler.
Sorgu süresi doldu
Sorgu sunucusuz SQL havuzunda 30 dakikadan fazla yürütürse hata Query timeout expired döndürülür. Sunucusuz SQL havuzu için bu sınır değiştirilemez.
- En iyi yöntemleri uygulayarak sorgunuzu iyileştirmeyi deneyin.
- Select (CETAS) olarak dış tablo oluştur'u kullanarak sorgularınızın bölümlerini gerçekleştirmeye çalışın.
- Diğer sorgular kaynakları alabileceğinden sunucusuz SQL havuzunda eş zamanlı bir iş yükü çalışıp çalışmadığını denetleyin. Bu durumda, iş yükünü birden çok çalışma alanına bölebilirsiniz.
Geçersiz nesne adı
Hata Invalid object name 'table name' , sunucusuz SQL havuzu veritabanında mevcut olmayan bir tablo veya görünüm gibi bir nesne kullandığınızı gösterir. Şu seçenekleri deneyin:
Tabloları veya görünümleri listeleyin ve nesnenin var olup olmadığını denetleyin. Synapse Studio sunucusuz SQL havuzunda bulunmayan bazı tabloları gösterebileceğinden SQL Server Management Studio veya Azure Data Studio kullanın.
nesnesini görürseniz büyük/küçük harfe duyarlı/ikili veritabanı harmanlaması kullanıp kullanmadığınızı denetleyin. Nesne adı, sorguda kullandığınız adla eşleşmemiş olabilir. İkili veritabanı harmanlaması
Employeeile veemployeeiki farklı nesnedir.Nesneyi görmüyorsanız, bir gölden veya Spark veritabanından tablo sorgulamaya çalışıyor olabilirsiniz. Tablo sunucusuz SQL havuzunda kullanılamayabilir çünkü:
- Tabloda sunucusuz SQL havuzunda temsil edilmeyecek bazı sütun türleri vardır.
- Tablo sunucusuz SQL havuzunda desteklenmeyen bir biçime sahiptir. Örnek olarak Avro veya ORC verilebilir.
Dize veya ikili veriler kesilebilir
Dizenizin veya ikili sütun türünüzün uzunluğu (örneğin VARCHAR, , VARBINARYveya NVARCHAR) okuduğunuz verilerin gerçek boyutundan kısaysa bu hata oluşur. Sütun türünün uzunluğunu artırarak bu hatayı düzeltebilirsiniz:
- Dize sütununuz tür olarak
VARCHAR(32)tanımlanmışsa ve metin 60 karakter ise, sütun şemanızda türü (veya daha uzun) kullanınVARCHAR(60). - Şema çıkarımı kullanıyorsanız (şema olmadan
WITH), tüm dize sütunları otomatik olarak tür olarakVARCHAR(8000)tanımlanır. Bu hatayı alıyorsanız, bu hatayı çözmek için şemayı daha büyükVARCHAR(MAX)sütun türüne sahip birWITHyan tümcesinde açıkça tanımlayın. - Tablonuz Lake veritabanındaysa Spark havuzundaki dize sütununun boyutunu artırmayı deneyin.
SET ANSI_WARNINGS OFFİşlevlerinizi etkilemeyecekse sunucusuz SQL havuzunun VARCHAR değerlerini otomatik olarak kesmesini etkinleştirmeyi deneyin.
Karakter dizesinden sonra kapatılmamış tırnak işareti
Like işlecini bir dize sütununda veya dize değişmez değerleriyle bir karşılaştırmada kullandığınız nadir durumlarda aşağıdaki hatayı alabilirsiniz:
Unclosed quotation mark after the character string
Sütunda Latin1_General_100_BIN2_UTF8 harmanlamayı kullanırsanız bu hata oluşabilir. Sorunu çözmek için harmanlama yerine Latin1_General_100_BIN2_UTF8 sütunda harmanlamayı ayarlamayı Latin1_General_100_CI_AS_SC_UTF8 deneyin. Hata yine de döndürülürse Azure portalı üzerinden bir destek isteği oluşturun.
Bir dağıtımdan diğerine veri aktarılırken tempdb alanı ayrılamadı
Sorgu yürütme altyapısı verileri işleyemiyorsa ve sorguyu yürüten düğümler arasında aktaramayınca hata Could not allocate tempdb space while transferring data from one distribution to another döndürülür. Geçerli kaynak kısıtlamaları hatası nedeniyle yürütülemediğinden genel sorgunun başarısız olması özel bir durum. Veritabanına ayrılan kaynaklar sorguyu çalıştırmak için tempdb yetersiz olduğunda bu hata döndürülür.
Destek bileti oluşturmadan önce en iyi yöntemleri uygulayın.
Sorgu bir dış dosyayı işlerken hatayla başarısız oluyor (maksimum hata sayısına ulaşıldı)
Sorgunuz hata iletisiyle error handling external file: Max errors count reachedbaşarısız olursa, belirtilen sütun türünde ve yüklenmesi gereken verilerde uyuşmazlık olduğu anlamına gelir.
Hata ve hangi satır ve sütunlara bakıldığı hakkında daha fazla bilgi edinmek için, ayrıştırıcı sürümünü olarak 2.0 1.0değiştirin.
Örnek
Bu Sorgu 1 ile dosyayı names.csv sorgulamak istiyorsanız, Azure Synapse sunucusuz SQL havuzu şu hatayla döndürür: Örneğin: Error handling external file: 'Max error count reached'. File/External table name: [filepath].
names.csv dosyası aşağıdakileri içerir:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
Sorgu 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Neden
Ayrıştırıcı sürümü 2.0 sürümünden 1.0 sürümüne değiştirildiğinde, hata iletileri sorunu tanımlamaya yardımcı olur. Yeni hata iletisi şu anda Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
Kesme, sütun türünüzün verilerinize sığamayacak kadar küçük olduğunu bildirir. Bu names.csv dosyadaki en uzun ad yedi karakterden oluşur. Kullanılacak uygun veri türü en az VARCHAR(7) olmalıdır. Hatanın nedeni şu kod satırıdır:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
Sorgunun uygun şekilde değiştirilmesi hatayı çözer. Hata ayıklamadan sonra, maksimum performans elde etmek için ayrıştırıcı sürümünü yeniden 2.0 olarak değiştirin.
Hangi ayrıştırıcı sürümünün ne zaman kullanılacağı hakkında daha fazla bilgi için bkz . Synapse Analytics'te sunucusuz SQL havuzu kullanarak OPENROWSET kullanma.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
Dosya açılamadığından toplu yükleme yapılamıyor
Sorgu yürütme sırasında bir dosya değiştirilirse hata Cannot bulk load because the file could not be opened döndürülür. Genellikle şunun gibi bir hata alabilirsiniz: Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
Sunucusuz SQL havuzları, sorgu çalışırken değiştirilen dosyaları okuyamaz. Sorgu dosyalara kilitlenemez. Değişiklik işleminin ekleme olduğunu biliyorsanız, şu seçeneği ayarlamayı deneyebilirsiniz: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}.
Daha fazla bilgi için bkz. Yalnızca ekleme dosyalarını sorgulama veya yalnızca ekleme dosyalarında tablo oluşturma.
Sorgu veri dönüştürme hatasıyla başarısız oluyor
Sorgunuz hata iletisiyle Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. başarısız olabilir Bu ileti, veri türlerinizin n ve m sütunu için gerçek verilerle eşleşmediğini gösterir.
Örneğin, verilerinizde yalnızca tamsayılar bekliyorsanız, ancak n. satırda bir dize varsa, bu hata iletisini alırsınız.
Bu sorunu çözmek için dosyayı ve seçtiğiniz veri türlerini inceleyin. Ayrıca satır sınırlayıcınızın ve alan sonlandırıcı ayarlarınızın doğru olup olmadığını denetleyin. Aşağıdaki örnekte, sütun türü olarak VARCHAR kullanılarak incelemenin nasıl yapılabilmesi gösterilmektedir.
Alan sonlandırıcıları, satır sınırlayıcıları ve kaçış alıntısı karakterleri hakkında daha fazla bilgi için bkz . CSV dosyalarını sorgulama.
Örnek
dosyasını names.csvsorgulamak istiyorsanız:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
Aşağıdaki sorguyla:
Sorgu 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Azure Synapse sunucusuz SQL havuzu hata döndürüyor Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
Verilere göz atmak ve bu sorunu çözmek için bilinçli bir karar vermek gerekir. Bu soruna neden olan verilere bakmak için önce veri türünün değiştirilmesi gerekir. SMALLINT veri türüyle ID sütununu sorgulamak yerine, bu sorunu çözümlemek için VARCHAR(100) kullanılır.
Bu biraz değiştirilen Sorgu 2 ile veriler artık ad listesini döndürmek için işlenebilir.
Sorgu 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Verilerin beşinci satırda kimlik için beklenmeyen değerlere sahip olduğunu gözlemleyebilirsiniz. Bu gibi durumlarda, bu örnekteki gibi bozuk verilerin nasıl önlenebileceği konusunda anlaşmaya varmak için verilerin işletme sahibiyle uyumlu hale getirmek önemlidir. Uygulama düzeyinde önleme mümkün değilse, burada tek seçenek makul boyutlu VARCHAR olabilir.
İpucu
VARCHAR() öğesini mümkün olduğunca kısa yapmaya çalışın. Performansı bozabileceğinden mümkünse VARCHAR(MAX) kullanmaktan kaçının.
Sorgu sonucu beklendiği gibi görünmüyor
Sorgunuz başarısız olmayabilir, ancak sonuç kümenizin beklendiği gibi olmadığını görebilirsiniz. Sonuçta elde edilen sütunlar boş olabilir veya beklenmeyen veriler döndürülebilir. Bu senaryoda, büyük olasılıkla bir satır sınırlayıcısı veya alan sonlandırıcısı yanlış seçilmiştir.
Bu sorunu çözmek için verilere bir kez daha göz atın ve bu ayarları değiştirin. Aşağıdaki örnekte gösterildiği gibi bu sorguda hata ayıklamak kolaydır.
Örnek
Sorgu 1'de sorguyla dosyayı names.csv sorgulamak istiyorsanız, Azure Synapse sunucusuz SQL havuzu garip görünen bir sonuç verir:
names.csv içinde:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
sütununda Firstnamedeğer yok gibi görünüyor. Bunun yerine, tüm değerler sütunda yer aldı ID . Bu değerler virgülle ayrılır. Alan sonlandırıcısı olarak noktalı virgül simgesi yerine virgülün seçilmesi gerektiğinden soruna bu kod satırı neden oldu:
FIELDTERMINATOR =';',
Bu tek karakterin değiştirilmesi sorunu çözer:
FIELDTERMINATOR =',',
Sorgu 2 tarafından oluşturulan sonuç kümesi artık beklendiği gibi görünür:
Sorgu 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Döndürür:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
Tür sütunu dış veri türüyle uyumlu değil
Sorgunuz hata iletisiyle Column [column-name] of type [type-name] is not compatible with external data type […], başarısız olursa, büyük olasılıkla bir PARQUET veri türü yanlış bir SQL veri türüne eşlenmiş olabilir.
Örneğin, Parquet dosyanızın kayan sayılarla (12,89 gibi) bir sütun fiyatı varsa ve bunu INT ile eşlemeye çalıştıysanız, bu hata iletisini alırsınız.
Bu sorunu çözmek için dosyayı ve seçtiğiniz veri türlerini inceleyin. Bu eşleme tablosu doğru bir SQL veri türü seçmenize yardımcı olur. En iyi yöntem olarak, yalnızca VARCHAR veri türüne çözümlenebilen sütunlar için eşlemeyi belirtin. Mümkün olduğunda VARCHAR'ın engellenmesi sorgularda daha iyi performansa yol açar.
Örnek
Bu Sorgu 1 ile dosyayı taxi-data.parquet sorgulamak istiyorsanız, Azure Synapse sunucusuz SQL havuzu aşağıdaki hatayı döndürür:
Dosya taxi-data.parquet aşağıdakileri içerir:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
Sorgu 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
Bu hata iletisi, veri türlerinin uyumlu olmadığını bildirir ve INT yerine FLOAT kullanma önerisiyle birlikte gelir. Hatanın nedeni şu kod satırıdır:
SumTripDistance INT,
Bu biraz değiştirilen Sorgu 2 ile veriler artık işlenebilir ve üç sütunun tümünü gösterir:
Sorgu 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
Sorgu, dağıtılmış işleme modunda desteklenmeyen bir nesneye başvuruyor
Hata The query references an object that is not supported in distributed processing mode , Azure Depolama veya Azure Cosmos DB analiz depolama alanında veri sorgularken kullanılamayabilecek bir nesne veya işlev kullandığınızı gösterir.
Sistem görünümleri ve işlevler gibi bazı nesneler, Azure Data Lake veya Azure Cosmos DB analiz depolama alanında depolanan verileri sorgularken kullanılamaz. Dış verileri sistem görünümleriyle birleştiren sorguları kullanmaktan kaçının, geçici tabloya dış verileri yükleyin veya dış verileri filtrelemek için bazı güvenlik veya meta veri işlevlerini kullanın.
WaitIOCompletion çağrısı başarısız oldu
Hata iletisi WaitIOCompletion call failed , uzak depolama alanından (Azure Data Lake) veri okuyan G/Ç işleminin tamamlanmasını beklerken sorgunun başarısız olduğunu gösterir.
Hata iletisi aşağıdaki desene sahiptir: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Depolama alanınızın sunucusuz SQL havuzuyla aynı bölgeye yerleştirildiğinden emin olun. Depolama ölçümlerini denetleyin ve depolama katmanında G/Ç isteklerini karşılayabilen yeni dosyaları karşıya yükleme gibi başka iş yükü olmadığını doğrulayın.
HRESULT alanı sonuç kodunu içerir. Aşağıdaki hata kodları, olası çözümleriyle birlikte en yaygın olanıdır.
Bu hata kodu, kaynak dosyanın depolama alanında olmadığı anlamına gelir.
Bu hata kodunun gerçekleşmesinin nedenleri vardır:
- Dosya başka bir uygulama tarafından silinmiş.
- Bu yaygın senaryoda sorgu yürütme başlatılır, dosyaları numaralandırır ve dosyalar bulunur. Daha sonra sorgu yürütme sırasında bir dosya silinir. Örneğin Databricks, Spark veya Azure Data Factory tarafından silinebilir. Dosya bulunamadığından sorgu başarısız oluyor.
- Bu sorun Delta biçiminde de oluşabilir. Tablonun yeni bir sürümü olduğundan ve silinen dosya yeniden sorgulanmadığından sorgu yeniden denemede başarılı olabilir.
- Geçersiz bir yürütme planı önbelleğe alınmış.
- Geçici bir çözüm olarak
DBCC FREEPROCCACHEkomutunu çalıştırın. Sorun devam ederse bir destek bileti oluşturun.
- Geçici bir çözüm olarak
DEĞİl yakınında yanlış söz dizimi
Hata Incorrect syntax near 'NOT' , sütun tanımında NOT NULL kısıtlamasını içeren sütunları olan bazı dış tablolar olduğunu gösterir.
- Sütun tanımından NOT NULL değerini kaldırmak için tabloyu güncelleştirin.
- Bu hata bazen BIR CETAS deyiminden oluşturulan tablolarda geçici olarak da oluşabilir. Sorun çözülmezse dış tabloyu bırakıp yeniden oluşturmayı deneyebilirsiniz.
Bölüm sütunu NULL değerleri döndürür
Sorgunuz sütunları bölümleme yerine NULL değerler döndürüyorsa veya bölüm sütunlarını bulamıyorsa, birkaç olası sorun giderme adımınız vardır:
- Bölümlenmiş bir veri kümesini sorgulamak için tabloları kullanırsanız, tablolar bölümleme özelliğini desteklemez. Tabloyu bölümlenmiş görünümlerle değiştirin.
- Bölümlenmiş görünümleri FILEPATH() işlevini kullanarak bölümlenmiş dosyaları sorgulayan OPENROWSET ile kullanıyorsanız, konumda joker karakter desenini doğru belirttiğinizden ve joker karaktere başvurmak için uygun dizini kullandığınızdan emin olun.
- Dosyaları doğrudan bölümlenmiş klasörde sorgularsanız, bölümleme sütunları dosya sütunlarının bölümleri değildir. Bölümleme değerleri dosyalara değil klasör yollarına yerleştirilir. Bu nedenle dosyalar bölümleme değerlerini içermez.
Sütun türü için batch'e değer ekleme DATETIME2 başarısız oldu
Hata Inserting value to batch for column type DATETIME2 failed , sunucusuz havuzun temel alınan dosyalardan tarih değerlerini okuyamazsınız. Parquet veya Delta Lake dosyasında depolanan datetime değeri sütun DATETIME2 olarak temsil edilemez.
Spark kullanarak dosyadaki en düşük değeri inceleyin ve bazı tarihlerin 0001-01-03'ten küçük olup olmadığını denetleyin. Dosyaları Spark 2.4 (desteklenmeyen çalışma zamanı sürümü) sürümünü veya hala eski tarih saat depolama biçimini kullanan daha yüksek Spark sürümüyle depoladıysanız, önceki tarih saat değerleri sunucusuz SQL havuzlarında kullanılan proleptik Gregoryen takvimle uyumlu olmayan Jülyen takvimi kullanılarak yazılır.
Parquet'deki değerleri yazmak için kullanılan Jülyen takvimi (bazı Spark sürümlerinde) ile sunucusuz SQL havuzunda kullanılan proleptik Gregoryen takvim arasında iki günlük bir fark olabilir. Bu fark, negatif bir tarih değerine dönüştürmeye neden olabilir ve bu değer geçersizdir.
Spark'ı kullanarak bu değerleri güncelleştirmeye çalışın çünkü BUNLAR SQL'de geçersiz tarih değerleri olarak değerlendirilir. Aşağıdaki örnek, Delta Lake'te SQL tarih aralıklarının dışında olan değerlerin NULL olarak nasıl güncelleştirildiğini gösterir:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
Bu değişiklik, temsil edilmeyecek değerleri kaldırır. Jülyen ve proleptik Gregoryen takvimler arasında hala bir fark olduğundan, diğer tarih değerleri düzgün bir şekilde yüklenmiş ancak yanlış gösterilmiş olabilir. Spark 3.0 veya daha eski sürümleri kullanıyorsanız, önceki 1900-01-01 tarihlerde bile beklenmeyen tarih kaydırmaları görebilirsiniz.
Spark 3.1 veya sonraki bir sürüme geçmeyi ve proleptik Gregoryen takvime geçmeyi göz önünde bulundurun. En son Spark sürümleri, sunucusuz SQL havuzundaki takvimle hizalanmış proleptik Gregoryen takvimi varsayılan olarak kullanır. Eski verilerinizi Spark'ın daha yüksek sürümüyle yeniden yükleyin ve tarihleri düzeltmek için aşağıdaki ayarı kullanın:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
Topoloji değişikliği veya işlem kapsayıcısı hatası nedeniyle sorgu başarısız oldu
Bu hata, sunucusuz SQL havuzunda bazı iç işlem sorunlarının oluştuğuna işaret edebilir. Azure desteği ekibinin sorunu incelemesine yardımcı olabilecek tüm gerekli ayrıntıları içeren bir destek bileti oluşturun.
Normal iş yüküyle karşılaştırıldığında olağan dışı olabilecek her şeyi açıklayın. Örneğin, bu hata oluşmadan önce çok sayıda eşzamanlı istek veya özel bir iş yükü veya sorgu yürütüldü.
Joker karakter genişletme zaman aşımına uğradı
Sorgu klasörleri ve birden çok dosya bölümünde açıklandığı gibi Sunucusuz SQL havuzu joker karakterler kullanarak birden çok dosya/klasör okumayı destekler. Sorgu başına en fazla 10 joker karakter sınırı vardır. Bu işlevin bir maliyeti olduğunu bilmeniz gerekir. Sunucusuz havuzun joker karakterle eşleşebilecek tüm dosyaları listelemesi zaman alır. Bu, gecikme süresine neden olur ve sorgulamaya çalıştığınız dosya sayısı yüksekse bu gecikme süresi artabilir. Bu durumda aşağıdaki hatayla karşılaşabilirsiniz:
"Wildcard expansion timed out after X seconds."
Bunu önlemek için yapabileceğiniz birkaç azaltma adımı vardır:
- En İyi Yöntemler Sunucusuz SQL Havuzu'nda açıklanan en iyi yöntemleri uygulayın.
- Dosyaları daha büyük dosyalara sıkıştırarak sorgulamaya çalıştığınız dosya sayısını azaltmayı deneyin. Dosya boyutlarınızı 100 MB'ın üzerinde tutmaya çalışın.
- Mümkün olan her yerde bölümleme sütunları üzerindeki filtrelerin kullanıldığından emin olun.
- Delta dosya biçimi kullanıyorsanız Spark'ta yazma iyileştirme özelliğini kullanın. Bu, okunması ve işlenmesi gereken veri miktarını azaltarak sorguların performansını artırabilir. Yazma iyileştirme özelliğinin nasıl kullanılacağı Apache Spark'ta en iyi duruma getirme yazma özelliğini kullanma başlığında açıklanmıştır.
- Bölümleme sütunları üzerinde örtük filtreleri etkili bir şekilde sabit kodlama yoluyla bazı üst düzey joker karakterlerden kaçınmak için dinamik SQL kullanın.
Otomatik şema çıkarımı kullanılırken eksik sütun
WITH yan tümcesini atlayarak şemayı bilmeden veya belirtmeden dosyaları kolayca sorgulayabilirsiniz. Bu durumda, sütun adları ve veri türleri dosyalardan çıkarılır. Aynı anda dosya sayısını okuyorsanız, şemanın depolama alanından alınan ilk dosya hizmetinden çıkarılacağını unutmayın. Bu, beklenen bazı sütunların atlanacağı anlamına gelebilir, çünkü şemayı tanımlamak için hizmet tarafından kullanılan dosya bu sütunları içermiyor. Şemayı açıkça belirtmek için OPENROWSET WITH yan tümcesini kullanın. Şema belirtirseniz (dış tablo veya OPENROWSET WITH yan tümcesi kullanılarak) varsayılan lax yol modu kullanılır. Bu, bazı dosyalarda var olmayan sütunların NULL olarak döndürüleceği anlamına gelir (bu dosyalardaki satırlar için). Yol modunun nasıl kullanıldığını anlamak için aşağıdaki belgelere ve örneğe bakın.
Yapılandırma
Sunucusuz SQL havuzları, veritabanı nesnelerini yapılandırmak için T-SQL kullanmanızı sağlar. Bazı kısıtlamalar vardır:
- ve
lakehouseveya Spark veritabanlarındamasternesne oluşturamazsınız. - Kimlik bilgileri oluşturmak için bir ana anahtarınız olmalıdır.
- Nesnelerde kullanılan verilere başvurma izniniz olmalıdır.
Veritabanı oluşturulamıyor
hatasını CREATE DATABASE failed. User database limit has been already reached.alırsanız, tek bir çalışma alanında desteklenen en fazla veritabanı sayısını oluşturmuş olursunuz. Daha fazla bilgi için bkz . Kısıtlamalar.
- Nesneleri ayırmanız gerekiyorsa veritabanlarındaki şemaları kullanın.
- Azure Data Lake storage'a başvurmanız gerekiyorsa sunucusuz SQL havuzunda eşitlenecek lakehouse veritabanları veya Spark veritabanları oluşturun.
En düşük satır boyutu izin verilen en büyük tablo satırı boyutu olan 8060 bayt'ı aştığından tablo oluşturulamadı veya değiştirilemiyor
Herhangi bir tablonun satır başına boyutu 8 KB'a kadar olabilir (satır dışı VARCHAR(MAX)/VARBINARY(MAX) verileri dahil değildir). Satırdaki hücrelerin toplam boyutunun 8060 bayt'ı aştığı bir tablo oluşturursanız aşağıdaki hatayı alırsınız:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
Bu hata, 8060 bayt'ı aşan sütun boyutlarına sahip bir Spark tablosu oluşturursanız ve sunucusuz SQL havuzu Spark tablosu verilerine başvuran bir tablo oluşturamazsa Lake veritabanında da oluşabilir.
Bir azaltma olarak, gibi CHAR(N) sabit boyut türlerini kullanmaktan kaçının ve bunları değişken boyut VARCHAR(N) türleriyle değiştirin veya içindeki CHAR(N)boyutu azaltın. Bkz . SQL Server'da 8 KB satır grubu sınırlaması.
Bu işlemi gerçekleştirmeden önce veritabanında bir ana anahtar oluşturun veya oturumda ana anahtarı açın
Sorgunuz hata iletisiyle Please create a master key in the database or open the master key in the session before performing this operation.başarısız olursa, kullanıcı veritabanınızın şu anda bir ana anahtara erişimi olmadığı anlamına gelir.
Büyük olasılıkla yeni bir kullanıcı veritabanı oluşturdunuz ve henüz ana anahtar oluşturmadınız.
Bu sorunu çözmek için aşağıdaki sorguyla bir ana anahtar oluşturun:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Not
değerini burada farklı bir gizli diziyle değiştirin 'strongpasswordhere' .
CREATE deyimi ana veritabanında desteklenmiyor
Sorgunuz hata iletisiyle Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database.başarısız olursa, sunucusuz SQL havuzundaki master veritabanı aşağıdakilerin oluşturulmasını desteklemez:
- Dış tablolar.
- Dış veri kaynakları.
- Veritabanı kapsamlı kimlik bilgileri.
- Dış dosya biçimleri.
Çözüm şu şekildedir:
Kullanıcı veritabanı oluşturma:
CREATE DATABASE <DATABASE_NAME>daha önce veritabanı için başarısız olan DATABASE_NAME> bağlamında <create deyimi yürütür
master.Dış dosya biçimi oluşturma örneği aşağıda verilmiştir:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Microsoft Entra oturum açma bilgisi veya kullanıcı oluşturulamıyor
Veritabanında yeni bir Microsoft Entra oturum açma bilgisi veya kullanıcı oluşturmaya çalışırken hata alırsanız veritabanınıza bağlanmak için kullandığınız oturum açma bilgilerini denetleyin. Yeni bir Microsoft Entra kullanıcısı oluşturmaya çalışan oturum açma bilgilerinin Microsoft Entra etki alanına erişme ve kullanıcının var olup olmadığını denetleme izni olmalıdır. Aşağıdakilere dikkat edin:
- SQL oturum açma işlemleri bu izne sahip olmadığından, SQL kimlik doğrulaması kullanıyorsanız her zaman bu hatayı alırsınız.
- Yeni oturum açma bilgileri oluşturmak için Microsoft Entra oturum açma bilgileri kullanıyorsanız Microsoft Entra etki alanına erişim izniniz olup olmadığını denetleyin.
Azure Cosmos DB
Sunucusuz SQL havuzları, işlevini kullanarak Azure Cosmos DB analiz depolamasını OPENROWSET sorgulamanıza olanak tanır. Azure Cosmos DB kapsayıcınızda analitik depolama olduğundan emin olun. Hesap, veritabanı ve kapsayıcı adını doğru belirttiğinizden emin olun. Ayrıca Azure Cosmos DB hesap anahtarınızın geçerli olduğundan emin olun. Daha fazla bilgi için bkz. Önkoşullar.
OPENROWSET işlevi kullanılarak Azure Cosmos DB sorgulanabilir
Azure Cosmos DB hesabınıza bağlanamıyorsanız önkoşullara bakın. Olası hatalar ve sorun giderme eylemleri aşağıdaki tabloda listelenmiştir.
| Hata | Kök neden |
|---|---|
| Söz dizimi hataları: - yakınında OPENROWSETyanlış söz dizimi.- ... tanınan BULK OPENROWSET bir sağlayıcı seçeneği değildir.- yakınında ...yanlış söz dizimi. |
Olası kök nedenler: - Azure Cosmos DB'yi ilk parametre olarak kullanmama. - Üçüncü parametrede tanımlayıcı yerine dize değişmez değeri kullanma. - Üçüncü parametre belirtilmiyor (kapsayıcı adı). |
| Azure Cosmos DB bağlantı dizesi bir hata oluştu. | - Hesap, veritabanı veya anahtar belirtilmemiş. - bağlantı dizesi bir seçenek tanınmaz. - Bağlantı dizesi sonuna noktalı virgül ( ;) yerleştirilir. |
| Azure Cosmos DB yolunu çözümleme işlemi "Yanlış hesap adı" veya "Yanlış veritabanı adı" hatasıyla başarısız oldu. | Belirtilen hesap adı, veritabanı adı veya kapsayıcı bulunamıyor veya analitik depolama belirtilen koleksiyonda etkinleştirilmemiş. |
| Azure Cosmos DB yolunu çözümleme işlemi "Yanlış gizli dizi değeri" veya "Gizli dizi null veya boş" hatasıyla başarısız oldu. | Hesap anahtarı geçerli değil veya eksik. |
Azure Cosmos DB dize türleri okunurken UTF-8 harmanlama uyarısı döndürülür
Sunucusuz SQL havuzu, sütun harmanlaması UTF-8 kodlaması içermiyorsa OPENROWSET derleme zamanı uyarısı döndürür. T-SQL deyimini kullanarak geçerli veritabanında çalışan tüm OPENROWSET işlevler için varsayılan harmanlamayı kolayca değiştirebilirsiniz:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
Latin1_General_100_BIN2_UTF8 harmanlama, dize koşullarını kullanarak verilerinizi filtrelediğinizde en iyi performansı sağlar.
Azure Cosmos DB analiz deposunda eksik satırlar
Azure Cosmos DB'den bazı öğeler işlev tarafından OPENROWSET döndürülmeyebilir. Aşağıdakilere dikkat edin:
- İşlem deposu ile analiz deposu arasında eşitleme gecikmesi vardır. Azure Cosmos DB işlem deposuna girdiğiniz belge iki-üç dakika sonra analiz deposunda görünebilir.
- Belge bazı şema kısıtlamalarını ihlal edebilir.
Sorgu bazı Azure Cosmos DB öğelerinde NULL değerleri döndürür
Azure Synapse SQL, aşağıdaki durumlarda işlem deposunda gördüğünüz değerler yerine NULL döndürür:
- İşlem deposu ile analiz deposu arasında eşitleme gecikmesi vardır. Azure Cosmos DB işlem deposuna girdiğiniz değer, analiz deposunda iki-üç dakika sonra görünebilir.
- WITH yan tümcesinde yanlış sütun adı veya yol ifadesi olabilir. WITH yan tümcesindeki sütun adı (veya sütun türünden sonraki yol ifadesi) Azure Cosmos DB koleksiyonundaki özellik adlarıyla eşleşmelidir. Karşılaştırma büyük/küçük harfe duyarlıdır. Örneğin ve
productCodeProductCodefarklı özelliklerdir. Sütun adlarınızın Azure Cosmos DB özellik adlarıyla tam olarak eşleştiğinden emin olun. - Özellik, 1.000'den fazla özellik veya 127'den fazla iç içe yerleştirme düzeyi gibi bazı şema kısıtlamalarını ihlal ettiğinden analiz depolama alanına taşınamayabilir.
- İyi tanımlanmış şema gösterimi kullanıyorsanız işlem deposundaki değer yanlış türde olabilir. İyi tanımlanmış şema, belgeleri örnekleme yoluyla her özelliğin türlerini kilitler. İşlem deposuna eklenen ve türle eşleşmeyen tüm değerler yanlış değer olarak değerlendirilir ve analiz deposuna geçirilmez.
- Tam uygunluk şeması gösterimi kullanıyorsanız, gibi
$.price.int64özellik adından sonra tür soneki eklediğinizden emin olun. Başvurulan yol için bir değer görmüyorsanız, farklı bir tür yolu altında depolanmış olabilir; örneğin,$.price.float64. Daha fazla bilgi için bkz . Tam uygunluk şemasında Azure Cosmos DB koleksiyonlarını sorgulama.
Sütun dış veri türüyle uyumlu değil
WITH yan tümcesindeki belirtilen sütun türü Azure Cosmos DB kapsayıcısı içindeki türle eşleşmiyorsa hata Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. döndürülür. Azure Cosmos DB bölümünde açıklandığı gibi sütun türünü SQL türü eşlemeleri olarak değiştirmeyi deneyin veya VARCHAR türünü kullanın.
Çözüm: Azure Cosmos DB yolu hatayla başarısız oldu
Hata Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'. alırsanız Azure Cosmos DB'de özel uç noktaları kullanıp kullanmadığınıza bakın. Sunucusuz SQL havuzunun özel uç noktaları olan bir analiz deposuna erişmesine izin vermek için Azure Cosmos DB analiz deposu için özel uç noktaları yapılandırmanız gerekir.
Azure Cosmos DB performans sorunları
Beklenmeyen performans sorunlarıyla karşılaşırsanız aşağıdakiler gibi en iyi yöntemleri uyguladığınıza emin olun:
- İstemci uygulamasını, sunucusuz havuzu ve Azure Cosmos DB analiz depolama alanını aynı bölgeye yerleştirdiğinizden emin olun.
- WITH yan tümcesini en uygun veri türleriyle kullandığınızdan emin olun.
- Dize koşullarını kullanarak verilerinizi filtrelerken Latin1_General_100_BIN2_UTF8 harmanlama kullandığınızdan emin olun.
- Önbelleğe alınabilecek yinelenen sorgularınız varsa, sorgu sonuçlarını Azure Data Lake Storage'da depolamak için CETAS'ı kullanmayı deneyin.
Delta Lake
Sunucusuz SQL havuzlarında Delta Lake desteğinde görebileceğiniz bazı sınırlamalar vardır:
- OPENROWSET işlevinde veya dış tablo konumunda kök Delta Lake klasörüne başvurduğunuza emin olun.
- Kök klasörde adlı
_delta_logbir alt klasör olmalıdır. Klasör yoksa_delta_logsorgu başarısız olur. Bu klasörü görmüyorsanız, Apache Spark havuzları kullanılarak Delta Lake'e dönüştürülmesi gereken düz Parquet dosyalarına başvurursunuz. - Bölüm şemasını açıklamak için joker karakterler belirtmeyin. Delta Lake sorgusu Delta Lake bölümlerini otomatik olarak tanımlar.
- Kök klasörde adlı
- Apache Spark havuzlarında oluşturulan Delta Lake tabloları sunucusuz SQL havuzunda otomatik olarak kullanılabilir, ancak şema güncelleştirilmez (genel önizleme sınırlaması). Spark havuzu kullanarak Delta tablosuna sütun eklerseniz, değişiklikler sunucusuz SQL havuzu veritabanında gösterilmez.
- Dış tablolar bölümlendirmeyi desteklemez. Bölüm eleme özelliğini kullanmak için Delta Lake klasöründe bölümlenmiş görünümleri kullanın. Makalenin devamında bilinen sorunlar ve geçici çözümler bölümüne bakın.
- Sunucusuz SQL havuzları zaman yolculuğu sorgularını desteklemez. Geçmiş verileri okumak için Synapse Analytics'te Apache Spark havuzlarını kullanın.
- Sunucusuz SQL havuzları Delta Lake dosyalarının güncelleştirilmesini desteklemez. Delta Lake'in en son sürümünü sorgulamak için sunucusuz SQL havuzunu kullanabilirsiniz. Delta Lake'i güncelleştirmek için Synapse Analytics'te Apache Spark havuzlarını kullanın.
- CETAS komutunu kullanarak sorgu sonuçlarını Delta Lake biçiminde depolamaya depolayamazsınız. CETAS komutu, çıkış biçimleri olarak yalnızca Parquet ve CSV'yi destekler.
- Synapse Analytics'teki sunucusuz SQL havuzları Delta okuyucu sürüm 1 ile uyumludur.
- Synapse Analytics'teki sunucusuz SQL havuzları BLOOM filtresine sahip veri kümelerini desteklemez. Sunucusuz SQL havuzu BLOOM filtrelerini yoksayar.
- Delta Lake desteği ayrılmış SQL havuzlarında kullanılamaz. Delta Lake dosyalarını sorgulamak için sunucusuz SQL havuzları kullandığınızdan emin olun.
- Sunucusuz SQL havuzlarıyla ilgili bilinen sorunlar hakkında daha fazla bilgi için bkz . Azure Synapse Analytics bilinen sorunlar.
Sunucusuz destek Delta 1.0 sürümü
Sunucusuz SQL havuzları yalnızca Delta Lake 1.0 sürümünü okuyor. Sunucusuz SQL havuzları 1. düzeye sahip bir Delta okuyucudur ve aşağıdaki özellikleri desteklemez:
- Sütun eşlemeleri yoksayılır- sunucusuz SQL havuzları özgün sütun adlarını döndürür.
- Silme vektörleri yoksayılır ve silinen/güncelleştirilmiş satırların eski sürümü döndürülür (büyük olasılıkla yanlış sonuçlar).
- Aşağıdaki Delta Lake özellikleri desteklenmez: V2 denetim noktaları, saat dilimi olmadan zaman damgası, VACUUM protokol denetimi
Silme vektörleri yoksayılır
Delta lake tablonuz Delta yazıcı sürüm 7'yi kullanacak şekilde yapılandırılmışsa silinen satırları ve güncelleştirilmiş satırların eski sürümlerini Sil Vektörleri'nde (DV) depolar. Sunucusuz SQL havuzları Delta okuyucu 1 düzeyine sahip olduğundan silme vektörlerini yoksayar ve desteklenmeyen Delta Lake sürümünü okurken büyük olasılıkla yanlış sonuçlar üretir.
Delta tablosunda sütun yeniden adlandırma desteklenmiyor
Sunucusuz SQL havuzu, delta lake tablolarını yeniden adlandırılmış sütunlarla sorgulamayı desteklemez. Sunucusuz SQL havuzu, yeniden adlandırılan sütundaki verileri okuyamaz.
Delta tablosundaki bir sütunun değeri NULL'dir
Delta okuyucu sürüm 2 veya üzerini gerektiren Delta veri kümesi kullanıyorsanız ve sürüm 1'de desteklenmeyen özellikleri (örneğin, sütunları yeniden adlandırma, sütunları bırakma veya sütun eşleme) kullanıyorsanız, başvuruda bulunılan sütunlardaki değerler gösterilmeyebilir.
JSON metni düzgün biçimlendirilmemiş
Bu hata sunucusuz SQL havuzunun Delta Lake işlem günlüğünü okuyamazsınız. Büyük olasılıkla aşağıdaki hatayı görürsünüz:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Delta Lake veri kümenizin bozuk olmadığından emin olun. Azure Synapse'te Apache Spark havuzunu kullanarak Delta Lake klasörünün içeriğini okuyabildiğinizi doğrulayın. Bu şekilde dosyanın bozulmadığından emin _delta_log olursunuz.
Geçici çözüm
Apache Spark havuzunu kullanarak Delta Lake veri kümesinde bir denetim noktası oluşturmayı deneyin ve sorguyu yeniden çalıştırın. Denetim noktası işlem JSON günlük dosyalarını toplar ve sorunu çözebilir.
Veri kümesi geçerliyse bir destek bileti oluşturun ve daha fazla bilgi sağlayın:
- Bu işlem Delta Lake işlem günlüğü dosyalarının durumunu değiştirebileceğinden sütunları ekleme veya kaldırma ya da tabloyu iyileştirme gibi herhangi bir değişiklik yapmayın.
- Klasörün içeriğini
_delta_logyeni bir boş klasöre kopyalayın. Dosyaları kopyalamayın.parquet data. - Yeni klasöre kopyaladığınız içeriği okumaya çalışın ve aynı hatayı gördüğünüzden emin olun.
- Kopyalanan
_delta_logdosyanın içeriğini Azure desteği gönderin.
Artık Spark havuzuyla Delta Lake klasörünü kullanmaya devam edebilirsiniz. Bu bilgileri paylaşma izniniz varsa kopyalanan verileri Microsoft desteğine sağlayacaksınız. Azure ekibi dosyanın içeriğini delta_log inceler ve olası hatalar ve geçici çözümler hakkında daha fazla bilgi sağlar.
Delta günlüklerini çözümleme başarısız oldu
Aşağıdaki hata sunucusuz SQL havuzunun Delta günlüklerini çözümleyemediğini gösterir: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. En yaygın neden last_checkpoint_file , Spark 3.3'e _delta_log eklenen alan nedeniyle checkpointSchema klasörde 200 bayttan büyük olmasıdır.
Bu hatayı aşmak için iki seçenek vardır:
- Spark not defterinde uygun yapılandırmayı değiştirin ve yeniden oluşturulacak
last_checkpoint_fileyeni bir denetim noktası oluşturun. Azure Databricks kullanıyorsanız yapılandırma değişikliği aşağıdaki gibidir:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Spark 3.2.1'e düşürme.
Mühendislik ekibimiz şu anda Spark 3.3 için tam destek üzerinde çalışmaktadır.
Spark'ta oluşturulan Delta tablosu sunucusuz havuzda gösterilmiyor
Not
Spark'ta oluşturulan Delta tablolarının çoğaltması hala genel önizleme aşamasındadır.
Spark'ta bir Delta tablosu oluşturduysanız ve bu tablo sunucusuz SQL havuzunda gösterilmiyorsa aşağıdakileri denetleyin:
- Spark tabloları gecikmeyle eşitlenmiş olduğundan biraz bekleyin (genellikle 30 saniye).
- Tablo bir süre sonra sunucusuz SQL havuzunda görünmediyse Spark Delta tablosunun şemasını denetleyin. Karmaşık türleri olan Spark tabloları veya sunucusuz olarak desteklenmeyen türler kullanılamaz. Bir göl veritabanında aynı şemaya sahip bir Spark Parquet tablosu oluşturmayı deneyin ve bu tablonun sunucusuz SQL havuzunda görünüp görünmediğini denetleyin.
- Tablo tarafından başvuruda bulunan çalışma alanı Yönetilen Kimlik erişimi Delta Lake klasörünü denetleyin. Sunucusuz SQL havuzu, tabloyu oluşturmak üzere depolama alanından tablo sütunu bilgilerini almak için çalışma alanı Yönetilen Kimliği'ni kullanır.
Göl veritabanı
Spark veya Synapse tasarımcısı kullanılarak oluşturulan Lake veritabanı tabloları, sorgulama için sunucusuz SQL havuzunda otomatik olarak kullanılabilir. Spark havuzu kullanılarak oluşturulan Parquet, CSV ve Delta Lake tablolarını sorgulamak ve Lake veritabanınıza roldeki db_datareader diğer şemaları, görünümleri, yordamları, tablo değeri işlevlerini ve Microsoft Entra kullanıcılarını eklemek için sunucusuz SQL havuzunu kullanabilirsiniz. Olası sorunlar bu bölümde listelenmiştir.
Spark'ta oluşturulan tablo sunucusuz havuzda kullanılamaz
Oluşturulan tablolar sunucusuz SQL havuzunda hemen kullanılamayabilir.
- Tablolar sunucusuz havuzlarda biraz gecikmeli olarak kullanılabilir. Spark'ta tablo oluşturulduktan sonra sunucusuz SQL havuzunda görmek için 5-10 dakika beklemeniz gerekebilir.
- Yalnızca Parquet, CSV ve Delta biçimlerine başvuran tablolar sunucusuz SQL havuzunda kullanılabilir. Diğer tablo türleri kullanılamaz.
- Desteklenmeyen sütun türleri içeren bir tablo sunucusuz SQL havuzunda kullanılamaz.
- Lake veritabanlarında Delta Lake tablolarına erişim genel önizleme aşamasındadır. Bu bölümde veya Delta Lake bölümünde listelenen diğer sorunları denetleyin.
Spark'ta oluşturulan bir dış tablo sunucusuz havuzda beklenmeyen sonuçlar gösteriyor
Kaynak Spark dış tablosu ile sunucusuz havuzdaki çoğaltılmış dış tablo arasında uyuşmazlık olabilir. Spark dış tabloları oluştururken kullanılan dosyalar uzantısızsa bu durum oluşabilir. Uygun sonuçları almak için tüm dosyaların .parquet gibi uzantılarla birlikte olduğundan emin olun.
Çoğaltılmış veritabanı için işleme izin verilmiyor
Bir Lake veritabanını değiştirmeye, dış tablolar, dış veri kaynakları, veritabanı kapsamlı kimlik bilgileri veya Lake veritabanınızdaki diğer nesneler oluşturmaya çalışıyorsanız bu hata döndürülür. Bu nesneler yalnızca SQL veritabanlarında oluşturulabilir.
Lake veritabanları Apache Spark havuzundan çoğaltılır ve Apache Spark tarafından yönetilir. Bu nedenle, T-SQL dilini kullanarak SQL Veritabanı'lerde gibi nesneler oluşturamazsınız.
Lake veritabanlarında yalnızca aşağıdaki işlemlere izin verilir:
- dışındaki
dboşemalarda görünümleri, yordamları ve satır içi tablo değeri işlevlerini (iTVF) oluşturma, bırakma veya değiştirme. - Microsoft Entra Id'den veritabanı kullanıcılarını oluşturma ve bırakma.
- Veritabanı kullanıcılarını şemaya ekleme veya şemadan
db_datareaderkaldırma.
Lake veritabanlarında diğer işlemlere izin verilmez.
Not
Şemada dbo bir görünüm, yordam veya işlev oluşturuyorsanız (veya şemayı atlayıp genellikle dbovarsayılan olanı kullanıyorsanız) hata iletisini alırsınız.
Lake veritabanlarındaki Delta tabloları sunucusuz SQL havuzunda kullanılamaz
Çalışma alanı yönetilen kimliğinizin Delta klasörünü içeren ADLS depolama alanında okuma erişimine sahip olduğundan emin olun. Sunucusuz SQL havuzu, ADLS'ye yerleştirilen Delta günlüklerinden Delta Lake tablo şemasını okur ve Delta işlem günlüklerine erişmek için çalışma alanı Yönetilen Kimliği'ni kullanır.
Bazı SQL Veritabanı Yönetilen Kimlik kimlik bilgilerini kullanarak Azure Data Lake depolamanıza başvuran bir veri kaynağı ayarlamayı deneyin ve Yönetilen Kimlik ile bir tablonun depolama alanınıza erişebildiğini onaylamak için Yönetilen Kimlik ile veri kaynağının üzerinde dış tablo oluşturmayı deneyin.
Lake veritabanlarındaki Delta tablolarının Spark ve sunucusuz havuzlarda aynı şemaya sahip olmaması
Sunucusuz SQL havuzları, Spark veya Synapse tasarımcısı kullanılarak Lake veritabanında oluşturulan Parquet, CSV ve Delta tablolarına erişmenizi sağlar. Delta tablolarına erişim hala genel önizleme aşamasındadır ve şu anda sunucusuz bir Delta tablosunu oluşturma sırasında Spark ile eşitler, ancak sütunlar daha sonra Spark'taki deyimi kullanılarak eklenirse şemayı ALTER TABLE güncelleştirmez.
Bu, genel önizleme sınırlamasıdır. Bu sorunu çözmek için tabloları değiştirmek yerine Spark'ta Delta tablosunu bırakın ve yeniden oluşturun (mümkünse).
Performans
Sunucusuz SQL havuzu, kaynakları veri kümesinin boyutuna ve sorgu karmaşıklığını temel alarak sorgulara atar. Sorgulara sağlanan kaynakları değiştiremez veya sınırlayamazsınız. Beklenmeyen sorgu performansı düşüşleriyle karşılaşabileceğiniz ve kök nedenleri belirlemeniz gerekebilecek bazı durumlar vardır.
Sorgu süresi çok uzun
Sorgu süresi 30 dakikadan uzun olan sorgularınız varsa, sorgunun sonuçları istemciye yavaş döndürmesi yavaştır. Sunucusuz SQL havuzu yürütme için 30 dakikalık bir sınıra sahiptir. Sonuç akışı için daha fazla zaman harcanıyor. Aşağıdaki geçici çözümleri deneyin:
- Synapse Studio kullanıyorsanız SQL Server Management Studio veya Azure Data Studio gibi başka bir uygulamayla ilgili sorunları yeniden oluşturmayı deneyin.
- SORGUnuz SQL Server Management Studio, Azure Data Studio, Power BI veya başka bir uygulama kullanılarak yürütülürken yavaşsa ağ sorunlarını ve en iyi yöntemleri denetleyin.
- Sorguyu CETAS komutuna yerleştirin ve sorgu süresini ölçün. CETAS komutu sonuçları Azure Data Lake Storage'da depolar ve istemci bağlantısına bağımlı değildir. CETAS komutu özgün sorgudan daha hızlı tamamlanırsa, istemci ile sunucusuz SQL havuzu arasındaki ağ bant genişliğini denetleyin.
Synapse Studio kullanılarak yürütülürken sorgu yavaş çalışıyor
Synapse Studio kullanıyorsanız SQL Server Management Studio veya Azure Data Studio gibi bir masaüstü istemcisi kullanmayı deneyin. Synapse Studio, SQL Server Management Studio veya Azure Data Studio'da kullanılan yerel SQL bağlantılarından genellikle daha yavaş olan HTTP protokollerini kullanarak sunucusuz SQL havuzuna bağlanan bir web istemcisidir.
Sorgu, uygulama kullanılarak yürütülürken yavaş çalışıyor
Yavaş sorgu yürütmeyle karşılaşırsanız aşağıdaki sorunları denetleyin:
- İstemci uygulamalarının sunucusuz SQL havuzu uç noktasıyla birlikte bulunduğundan emin olun. Bölge genelinde bir sorgunun yürütülmesi ek gecikme süresine ve sonuç kümesinin yavaş akışına neden olabilir.
- Sonuç kümesinin yavaş akışına neden olabilecek ağ sorunları olmadığından emin olun
- İstemci uygulamasında yeterli kaynak olduğundan emin olun (örneğin, %100 CPU kullanmaz).
- Depolama hesabının veya Azure Cosmos DB analiz depolama alanının sunucusuz SQL uç noktanızla aynı bölgeye yerleştirildiğinden emin olun.
Kaynakları birlikte konumlandırmaya yönelik en iyi yöntemlere bakın.
Sorgu sürelerinde yüksek varyasyonlar
Aynı sorguyu yürütüyor ve sorgu sürelerindeki varyasyonları gözlemliyorsanız, bu davranışa çeşitli nedenler neden olabilir:
- Bunun sorgunun ilk yürütmesi olup olmadığını denetleyin. Sorgunun ilk yürütülmesi, plan oluşturmak için gereken istatistikleri toplar. İstatistikler, temel alınan dosyalar taranarak toplanır ve sorgu süresini artırabilir. Synapse Studio'da, sorgunuzdan önce yürütülen SQL istek listesinde "genel istatistik oluşturma" sorgularını görürsünüz.
- İstatistiklerin süresi bir süre sonra dolabilir. Sunucusuz havuzun istatistikleri taraması ve yeniden oluşturması gerektiğinden düzenli aralıklarla performans üzerinde bir etki gözlemleyebilirsiniz. SQL istek listesinde sorgunuzdan önce yürütülen başka bir "genel istatistik oluşturma" sorgusu fark edebilirsiniz.
- Sorguyu daha uzun süre yürütürken aynı uç noktada çalışan bir iş yükü olup olmadığını denetleyin. Sunucusuz SQL uç noktası kaynakları paralel olarak yürütülen tüm sorgulara eşit olarak ayırır ve sorgu gecikebilir.
Bağlantılar
Sunucusuz SQL havuzu, TDS protokolunu kullanarak ve verileri sorgulamak için T-SQL dilini kullanarak bağlanmanızı sağlar. SQL Server'a veya Azure SQL Veritabanı bağlanabilen araçların çoğu sunucusuz SQL havuzuna da bağlanabilir.
SQL havuzu ısınıyor
Daha uzun bir süre etkinlik yapılmadığında sunucusuz SQL havuzu devre dışı bırakılır. Etkinleştirme, ilk bağlantı girişimi gibi sonraki ilk etkinlikte otomatik olarak gerçekleşir. Etkinleştirme işlemi tek bir bağlantı denemesi zaman aralığından daha uzun sürebilir ve bu nedenle hata iletisi görüntülenir. Bağlantı girişiminin yeniden denenmesi yeterli olmalıdır.
En iyi yöntem olarak, onu destekleyen istemciler için yeniden bağlanma davranışını denetlemek için ConnectionRetryCount ve ConnectRetryInterval bağlantı dizesi anahtar sözcükleri kullanın.
Hata iletisi devam ederse Azure portalı üzerinden bir destek bileti oluşturun.
Synapse Studio'dan bağlanılamıyor
Synapse Studio bölümüne bakın.
Bir araçtan Azure Synapse havuzuna bağlanılamıyor
Bazı araçlarda Azure Synapse sunucusuz SQL havuzuna bağlanmak için kullanabileceğiniz açık bir seçenek olmayabilir. SQL Server'a veya SQL Veritabanı bağlanmak için kullanabileceğiniz bir seçeneği kullanın. Sunucusuz SQL havuzu SQL Server veya SQL Veritabanı ile aynı protokolü kullandığından bağlantı iletişim kutusunun "Synapse" olarak markalanması gerekmez.
Bir araç yalnızca mantıksal sunucu adı girmenize olanak tanıyıp etki alanını önceden tanımlasa database.windows.net bile, Azure Synapse çalışma alanı adını ve ardından -ondemand son eki ve database.windows.net etki alanını ekleyin.
Güvenlik
Kullanıcının veritabanlarına erişim izinlerine, komutları yürütme izinlerine ve Azure Data Lake veya Azure Cosmos DB depolama alanına erişme izinlerine sahip olduğundan emin olun.
Azure Cosmos DB hesabına erişemiyorum
Analiz depolama alanınıza erişmek için salt okunur bir Azure Cosmos DB anahtarı kullanmanız gerekir, bu nedenle süresinin dolmadığından veya yeniden üretilemediğinden emin olun.
"Azure Cosmos DB yolu çözümlenemedi hatasıyla başarısız oldu" hatasını alırsanız bir güvenlik duvarı yapılandırdığınızdan emin olun.
Lakehouse veya Spark veritabanına erişemiyorum
Bir kullanıcı lakehouse veya Spark veritabanına erişemiyorsa, kullanıcının veritabanına erişme ve veritabanına okuma izni olmayabilir. CONTROL SERVER izni olan bir kullanıcının tüm veritabanlarına tam erişimi olmalıdır. Kısıtlanmış bir izin olarak, HERHANGİ Bİr VERİSAYICIYA BAĞLANIN ve TÜM KULLANICI GÜVENİLENİP SEÇİn'i kullanmayı deneyebilirsiniz.
SQL kullanıcısı Dataverse tablolarına erişemiyor
Dataverse tabloları, çağıranın Microsoft Entra kimliğini kullanarak depolamaya erişir. Yüksek izinlere sahip bir SQL kullanıcısı bir tablodan veri seçmeye çalışabilir, ancak tablo Dataverse verilerine erişemez. Bu senaryo desteklenmez.
SPI bir rol ataması oluşturduğunda Microsoft Entra hizmet sorumlusu oturum açma hataları
Başka bir SPI kullanarak bir hizmet sorumlusu tanımlayıcısı (SPI) veya Microsoft Entra uygulaması için rol ataması oluşturmak istiyorsanız veya zaten bir tane oluşturduysanız ve oturum açamıyorsanız, büyük olasılıkla aşağıdaki hatayı alırsınız: Login error: Login failed for user '<token-identified principal>'.
Hizmet sorumluları için oturum açma bilgileri oluşturulurken bir nesne kimliği değil uygulama kimliği (güvenlik kimliği (SID) olarak) kullanılmalıdır. Hizmet sorumlularıyla ilgili bilinen bir sınırlama vardır. Bu sınırlama Azure Synapse'in başka bir SPI veya uygulama için rol ataması oluştururken Microsoft Graph'dan uygulama kimliğini getirmesini engeller.
Çözüm 1
Azure portalı>Synapse Studio>Erişimi Yönet>denetimine gidin ve istenen hizmet sorumlusu için Synapse Yöneticisi'ni veya Synapse SQL Yöneticisi'ni el ile ekleyin.
Çözüm 2
SQL koduyla el ile düzgün bir oturum açma oluşturmanız gerekir:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
Çözüm 3
PowerShell kullanarak hizmet sorumlusu Azure Synapse yöneticisi de ayarlayabilirsiniz. Az.Synapse modülünü yüklemiş olmanız gerekir.
Çözüm, cmdlet'ini New-AzSynapseRoleAssignment ile -ObjectId "parameter"kullanmaktır. Bu parametre alanında, çalışma alanı yöneticisi Azure hizmet sorumlusu kimlik bilgilerini kullanarak nesne kimliği yerine uygulama kimliğini sağlayın.
PowerShell betiği:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Doğrulama
Sunucusuz SQL uç noktasına bağlanın ve SID ile dış oturum açmanın (app_id_to_add_as_admin önceki örnekte) oluşturulduğunu doğrulayın:
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
Alternatif olarak, ayarlanan yönetici uygulamasını kullanarak sunucusuz SQL uç noktasında oturum açmayı da deneyebilirsiniz.
Sınırlamalar
Bazı genel sistem kısıtlamaları iş yükünüzü etkileyebilir:
| Özellik | Sınırlama |
|---|---|
| Abonelik başına en fazla Azure Synapse çalışma alanı sayısı | Bkz. sınırlar. |
| Sunucusuz havuz başına en fazla veritabanı sayısı | 100 (Apache Spark havuzundan eşitlenen veritabanları dahil değildir). |
| Apache Spark havuzundan eşitlenen en fazla veritabanı sayısı | Sınırlı değil. |
| Veritabanı başına en fazla veritabanı nesnesi sayısı | Veritabanındaki tüm nesnelerin sayısı 2.147.483.647'yi aşamaz. Bkz . SQL Server veritabanı altyapısındaki sınırlamalar. |
| Karakter cinsinden tanımlayıcı uzunluğu üst sınırı | 128. Bkz . SQL Server veritabanı altyapısındaki sınırlamalar. |
| En fazla sorgu süresi | 30 dakika. |
| Sonuç kümesinin en büyük boyutu | Eşzamanlı sorgular arasında en fazla 400 GB paylaşıldı. |
| En fazla eşzamanlılık | Sınırlı değildir ve sorgu karmaşıklığı ve taranan veri miktarına bağlıdır. Sunucusuz bir SQL havuzu, basit sorgular yürüten 1.000 etkin oturumu eş zamanlı olarak idare edebilir. Sorgular daha karmaşıksa veya daha fazla miktarda veri taranacaksa bu sayı daha düşük olacaktır. Bu nedenle bu durumda eş zamanlı kullanımı azaltmayı ve mümkünse sorguları daha uzun bir süre boyunca yürütmeyi göz önünde bulundurun. |
| Dış Tablo adının en büyük boyutu | 100 karakter. |
Sunucusuz SQL havuzunda veritabanı oluşturulamıyor
Sunucusuz SQL havuzlarının sınırlamaları vardır ve çalışma alanı başına 100'den fazla veritabanı oluşturamazsınız. Nesneleri ayırmanız ve yalıtmanız gerekiyorsa şemaları kullanın.
Bir çalışma alanında desteklenen en fazla veritabanı sayısını oluşturduğunuz hatasını CREATE DATABASE failed. User database limit has been already reached alırsanız.
Farklı kiracıların verilerini yalıtmak için ayrı veritabanları kullanmanız gerekmez. Tüm veriler harici olarak bir veri gölünde ve Azure Cosmos DB'de depolanır. Tablo, görünümler ve işlev tanımları gibi meta veriler şemalar kullanılarak başarıyla yalıtılabilir. Şema tabanlı yalıtım, veritabanlarının ve şemaların aynı kavramlar olduğu Spark'ta da kullanılır.