Ana etmen görselleştirmeleri oluşturma
ŞUNLAR IÇIN GEÇERLIDIR:![]() Power BI Desktop
Power BI Desktop ![]() Power BI hizmeti
Power BI hizmeti
Ana etmenler görseli, ilgilendiğiniz bir ölçümü yönlendiren faktörleri anlamanıza yardımcı olur. Verilerinizi analiz eder, önemli faktörleri sıralar ve bunları ana etmenler olarak görüntüler. Örneğin, değişim sıklığı olarak da bilinen çalışan cirosunu neyin etkilediğini öğrenmek istediğinizi varsayalım. Bir faktör iş sözleşmesi uzunluğu, bir diğer faktör ise işe giriş süresi olabilir.
Ana etmenler ne zaman kullanılır?
Aşağıdakiler için ana etmenler görseli harika bir seçimdir:
- Analiz edilen ölçümü hangi faktörlerin etkilediğine bakın.
- Bu faktörlerin göreli önemini karşıtlık. Örneğin, kısa vadeli sözleşmeler uzun vadeli sözleşmelerden daha fazla değişim sıklığı etkiler mi?
Ana etmenler görselinin özellikleri
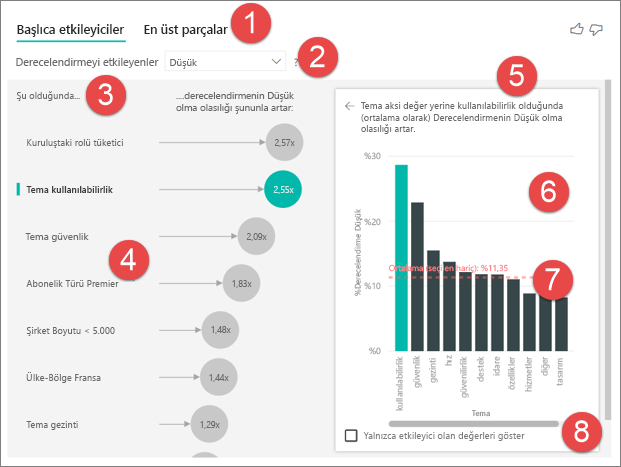
Sekmeler: Görünümler arasında geçiş yapmak için bir sekme seçin. Ana etmenler , seçili ölçüm değerine en çok katkıda bulunanları gösterir. En üst segmentler , seçili ölçüm değerine katkıda bulunan en üst segmentleri gösterir. Segment, değerlerin birleşiminden oluşur. Örneğin, bir segment en az 20 yıldır müşteri olan ve batı bölgesinde yaşayan tüketiciler olabilir.
Açılan kutu: Araştırma altındaki ölçümün değeri. Bu örnekte Derecelendirme ölçümüne bakın. Seçilen değer Düşük.
Yeniden ifade: Sol bölmedeki görseli yorumlamanıza yardımcı olur.
Sol bölme: Sol bölmede bir görsel bulunur. Bu durumda, sol bölmede en önemli etmenlerin listesi gösterilir.
Yeniden ifade: Sağ bölmedeki görseli yorumlamanıza yardımcı olur.
Sağ bölme: Sağ bölmede bir görsel bulunur. Bu durumda sütun grafiği, sol bölmede seçilen ana etmen Temasının tüm değerlerini görüntüler. Sol bölmeden belirli kullanılabilirlik değeri yeşil olarak gösterilir. Tema için diğer tüm değerler siyah olarak gösterilir.
Ortalama çizgi: Kullanılabilirlik (seçilen etmen) dışında Tema için tüm olası değerler için ortalama hesaplanır. Bu nedenle hesaplama, siyahtaki tüm değerler için geçerlidir. Diğer Temaların yüzde kaçının düşük derecelendirmeye sahip olduğunu belirtir. Bu durumda %11,35'in düşük derecelendirmesi vardı (noktalı çizgiyle gösterilmiştir).
Onay kutusu: Sağ bölmedeki görseli yalnızca ilgili alan için etmen olan değerleri gösterecek şekilde filtreler. Bu örnekte görsel kullanılabilirlik, güvenlik ve gezintiyi gösterecek şekilde filtrelenmiştir.
Kategorik bir ölçümü analiz etme
Kategorik ölçümle ana etmenler görseli oluşturmayı öğrenmek için bu videoyu izleyin. Ardından, bir tane oluşturmak için adımları izleyin.
Not
Bu videoda Power BI Desktop'ın önceki sürümleri veya Power BI hizmeti kullanılabilir.
- Product Manager'ınız, müşterilerin bulut hizmetiniz hakkında olumsuz incelemeler bırakmasına neden olan faktörleri öğrenmenizi istiyor. Power BI Desktop'ta takip etmek için Müşteri Geri Bildirimi PBIX dosyasını açın.
Not
Müşteri Geri Bildirimi veri kümesi [Moro et al., 2014] S. Moro, P. Cortez ve P. Rita'yı temel alır. "Banka Telemarketing'in Başarısını Tahmin Etmek için Veri Odaklı Bir Yaklaşım." Karar Destek Sistemleri, Elsevier, 62:22-31, Haziran 2014.
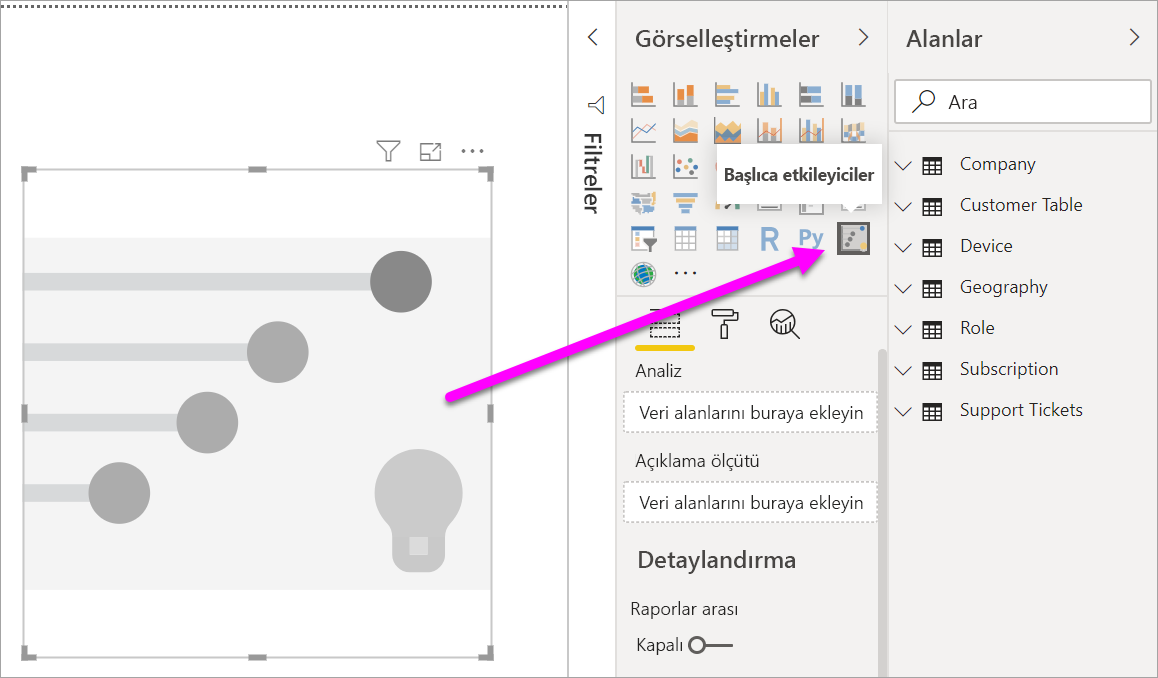
Görsel Öğeler bölmesindeki Görsel oluştur'un altında Ana etmenler simgesini seçin.
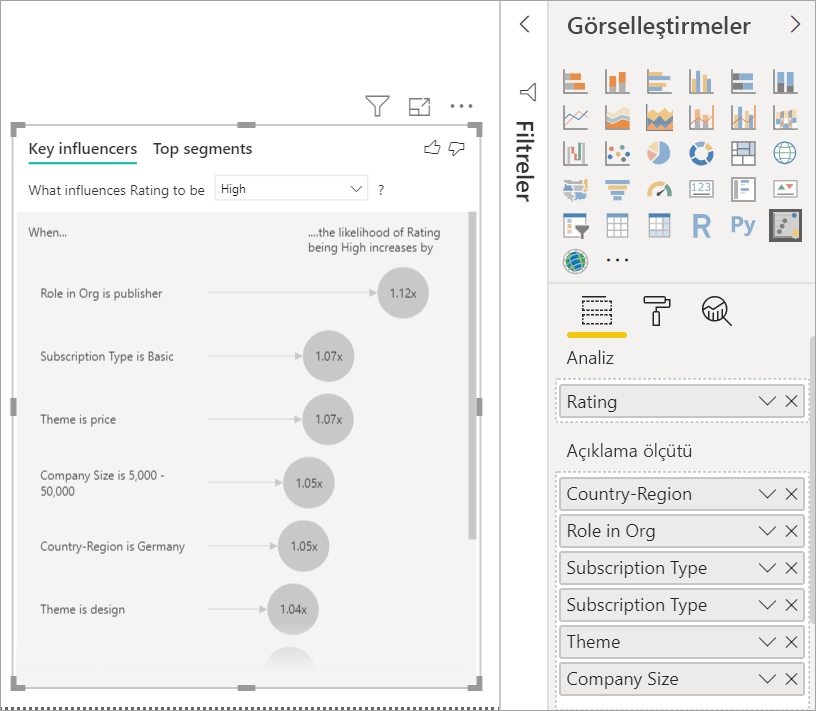
Araştırmak istediğiniz ölçümü Çözümle alanına taşıyın. Hizmetin müşteri derecelendirmesinin düşük olmasına neyin neden olduğunu görmek için Müşteri Tablosu>Derecelendirmesi'ni seçin.
Derecelendirmeyi etkileyebileceğini düşündüğünüz alanları Açıklama ölçütü alanına taşıyın. İstediğiniz kadar alan taşıyabilirsiniz. Bu durumda, şununla başlayın:
- Ülke-Bölge
- Kuruluştaki Rol
- Abonelik Türü
- Şirket Boyutu
- Theme
Genişlet alanını boş bırakın. Bu alan yalnızca bir ölçü veya özetlenmiş alan analiz edilirken kullanılır.
Negatif derecelendirmelere odaklanmak için Derecelendirmeyi etkileyenler açılan kutusunda Düşük'i seçin.
Çözümleme, analiz edilen alanın tablo düzeyinde çalışır. Bu durumda Derecelendirme ölçümüdür. Bu ölçüm müşteri düzeyinde tanımlanır. Her müşteri yüksek puan veya düşük puan verdi. Görselin bunları kullanabilmesi için tüm açıklayıcı faktörlerin müşteri düzeyinde tanımlanması gerekir.
Önceki örnekte, tüm açıklayıcı faktörlerin ölçümle bire bir veya çoka bir ilişkisi vardır. Bu durumda, her müşteri derecelendirmesine tek bir tema atadı. Benzer şekilde, müşteriler bir ülkeden veya bölgeden gelir, bir üyelik türüne sahiptir ve kuruluşlarında bir rol sahibi olur. Açıklayıcı faktörler zaten bir müşterinin öznitelikleridir ve dönüştürme gerekmez. Görsel bunları hemen kullanabilir.
Öğreticinin ilerleyen bölümlerinde, bire çok ilişkileri olan daha karmaşık örneklere bakacaksınız. Bu gibi durumlarda, analizi çalıştırabilmeniz için önce sütunların müşteri düzeyine kadar toplanması gerekir.
Açıklayıcı faktörler olarak kullanılan ölçüler ve toplamalar analiz ölçümünün tablo düzeyinde de değerlendirilir. Bu makalenin devamında bazı örnekler gösterilmiştir.
Kategorik ana etmenleri yorumlama
Şimdi düşük derecelendirmeler için ana etmenlere göz atalım.
Düşük derecelendirme olasılığını etkileyen en önemli tek faktör
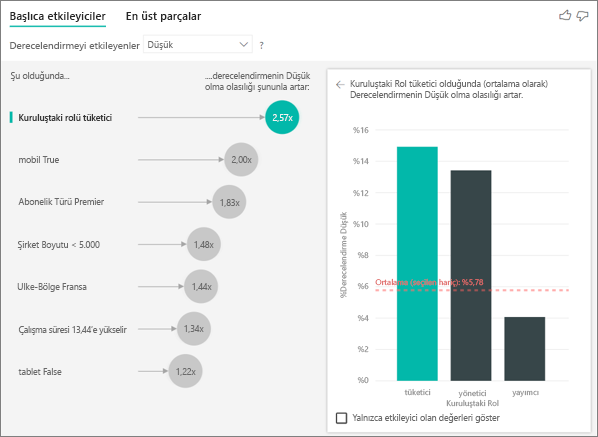
Bu örnekteki müşterinin üç rolü olabilir: tüketici, yönetici ve yayımcı. Tüketici olmak, düşük derecelendirmeye katkıda bulunan en önemli faktördür.
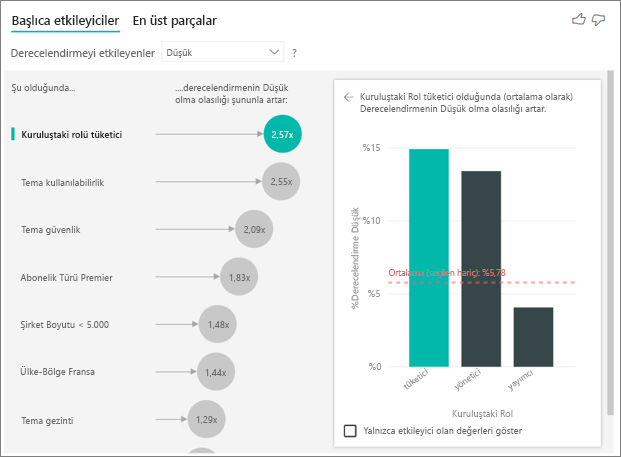
Daha kesin olarak, tüketicilerinizin hizmetinize olumsuz puan verme olasılığı 2,57 kat daha yüksektir. Ana etmenler grafiğinde , soldaki listede önce Kuruluştaki Rol tüketicisi listelenir. Kuruluş tüketicidir bölümünde Rol seçeneğini belirleyerek Power BI sağ bölmede daha fazla ayrıntı gösterir. Her rolün düşük derecelendirme olasılığı üzerindeki karşılaştırmalı etkisi gösterilir.
- Tüketicilerin %14,93'i düşük puan veriyor.
- Diğer tüm roller ortalama olarak %5,78 oranında düşük puan verir.
- Tüketicilerin düşük puan verme olasılığı diğer tüm rollere kıyasla 2,57 kat daha yüksektir. Yeşil çubuğu kırmızı noktalı çizgiye bölerek bu puanı belirleyebilirsiniz.
Düşük derecelendirme olasılığını etkileyen ikinci tek faktör
Ana etmenler görseli birçok farklı değişkenden faktörleri karşılaştırır ve derecesini alır. İkinci etmen, Kuruluştaki Rol ile hiçbir ilgisi yoktur. Listeden tema kullanılabilirlik olan ikinci etmen'i seçin.
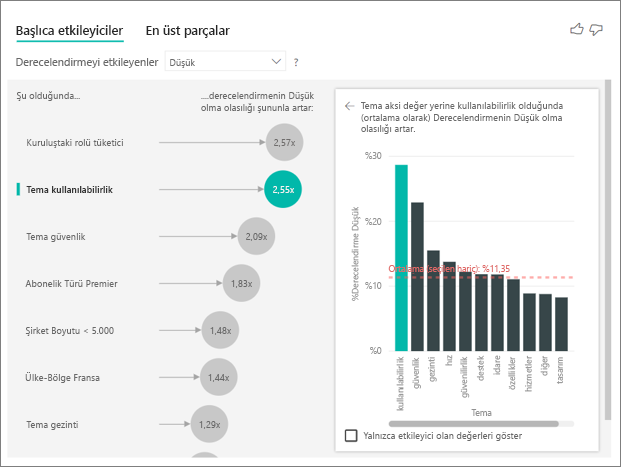
İkinci en önemli faktör, müşterinin gözden geçirme temasıyla ilgilidir. Ürünün kullanılabilirliği hakkında yorum yapan müşterilerin güvenilirlik, tasarım veya hız gibi diğer temalara yorum yapan müşterilere kıyasla düşük puan verme olasılığı 2,55 kat daha yüksekti.
Görseller arasında kırmızı noktalı çizgiyle gösterilen ortalama %5,78'den %11,35'e değiştirildi. Ortalama dinamiktir çünkü diğer tüm değerlerin ortalamasını temel alır. İlk etmen için ortalama, müşteri rolünü dışlamıştı. İkinci etmen için kullanılabilirlik temasını dışlamıştı.
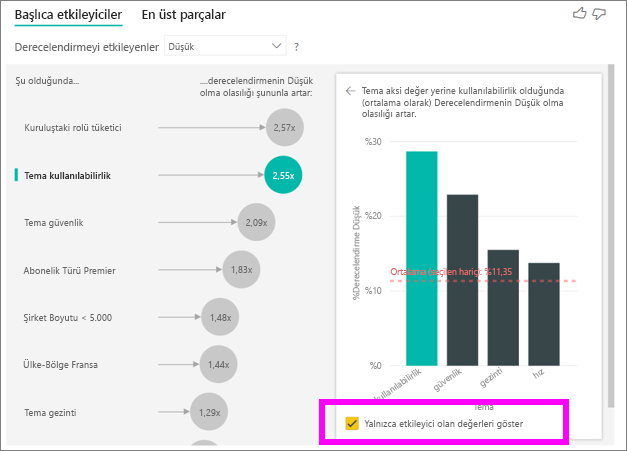
Yalnızca etkili değerleri kullanarak filtrelemek için Yalnızca etmen olan değerleri göster onay kutusunu seçin. Bu durumda düşük puan alan roller bunlardır. 12 tema, Power BI'ın düşük derecelendirmeleri yönlendiren temalar olarak tanımlamış olduğu dört temaya indirgendi.
Diğer görsellerle etkileşim kurma
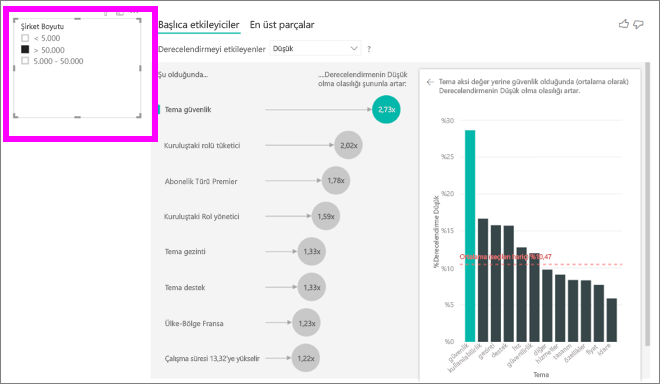
Tuvalde dilimleyici, filtre veya başka bir görsel seçtiğinizde, ana etmenler görseli verilerin yeni bölümünde analizini yeniden çalıştırır. Örneğin, Şirket Boyutu'nu rapora taşıyabilir ve dilimleyici olarak kullanabilirsiniz. Kurumsal müşterileriniz için temel etmenlerin genel popülasyondan farklı olup olmadığını görmek için bunu kullanın. Kurumsal şirket boyutu 50.000'den fazla çalışandır.
Analizi yeniden çalıştırmak için 50.000'i seçtiğinizde >etmenlerin değiştiğini görebilirsiniz. Büyük kurumsal müşteriler için düşük derecelendirmeler için en önemli etmen, güvenlikle ilgili bir temaya sahiptir. Büyük müşterilerinizin memnun olmadığı belirli güvenlik özellikleri olup olmadığını görmek için daha fazla araştırma yapmak isteyebilirsiniz.
Sürekli ana etmenleri yorumlama
Şimdiye kadar farklı kategorik alanların düşük derecelendirmeleri nasıl etkilediğini keşfetmek için görseli nasıl kullanacağınızı gördünüz. Açıklama ölçütü alanında yaş, boy ve fiyat gibi sürekli faktörlerin olması da mümkündür. Şimdi Tenure müşteri tablosundan Açıklama ölçütü'ne taşındığında ne olduğuna bakalım. Kullanım süresi, bir müşterinin hizmeti ne kadar süreyle kullandığını gösterir.
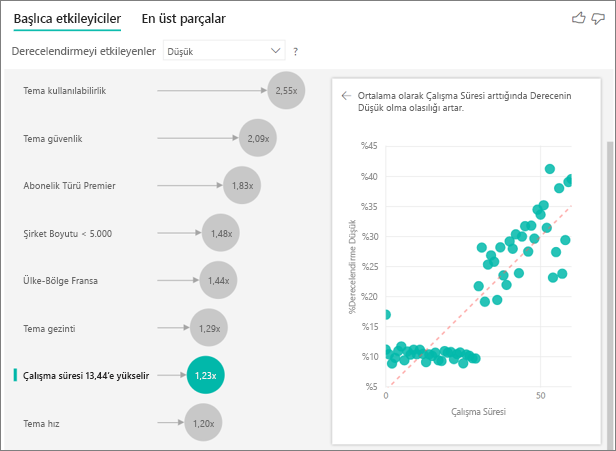
Kullanım süresi arttıkça daha düşük derecelendirme alma olasılığı da artar. Bu eğilim, uzun vadeli müşterilerin negatif puan verme olasılığının daha yüksek olduğunu göstermektedir. Bu içgörü ilginçtir ve daha sonra takip etmek isteyebileceğiniz bir içgörüdür.
Görselleştirme, her kullanım süresi 13,44 ay arttığında, ortalama olarak düşük derecelendirme olasılığının 1,23 kat arttığını gösterir. Bu durumda, 13,44 ay, standart kullanım süresi sapması gösterir. Bu nedenle aldığınız içgörü, kullanım sürelerinin standart sapma olan standart bir miktarla artırılmasının düşük derecelendirme alma olasılığını nasıl etkilediğine bakar.
Sağ bölmedeki dağılım çizimi, her kullanım süresi değeri için düşük derecelendirmelerin ortalama yüzdesini çizer. Eğimi bir eğilim çizgisiyle vurgular.
Binned sürekli anahtar etmenleri
Bazı durumlarda, sürekli faktörlerinizin otomatik olarak kategorik faktörlere dönüştürüldüğünü fark edebilirsiniz. Değişkenler arasındaki ilişki doğrusal değilse, ilişkiyi yalnızca artan veya azalan (yukarıdaki örnekte yaptığımız gibi) olarak tanımlayamıyoruz.
Etmenlerin hedefle ilgili ne kadar doğrusal olduğunu belirlemek için bağıntı testleri çalıştırıyoruz. Hedef sürekli ise Pearson bağıntısını çalıştırırız ve hedef kategorikse Point Biserial bağıntı testlerini çalıştırırız. İlişkinin yeterince doğrusal olmadığını algılarsak denetimli gruplama yürütür ve en fazla beş bölme oluştururuz. Hangi bölmelerin en anlamlı olduğunu bulmak için açıklayıcı faktörle analiz edilen hedef arasındaki ilişkiyi inceleyen denetimli bir gruplama yöntemi kullanırız.
Ölçüleri ve toplamları ana etmenler olarak yorumlama
Ölçüleri ve toplamaları çözümlemenizin içinde açıklayıcı faktörler olarak kullanabilirsiniz. Örneğin, müşteri destek bileti sayısının veya açık biletin ortalama süresinin aldığınız puan üzerindeki etkisini görmek isteyebilirsiniz.
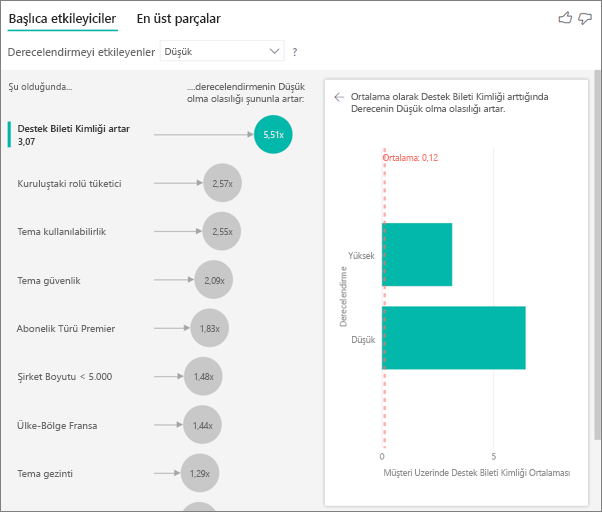
Bu durumda, bir müşterinin sahip olduğu destek bileti sayısının, verdikleri puanı etkilenip etkilemediğini görmek istiyorsunuz. Şimdi destek bileti tablosundan Destek Bileti Kimliğini getirebilirsiniz. Bir müşterinin birden çok destek bileti olabileceğinden, kimliği müşteri düzeyine toplarsınız. Çözümleme müşteri düzeyinde çalıştığından toplama önemlidir, bu nedenle tüm sürücülerin bu ayrıntı düzeyinde tanımlanması gerekir.
Kimlik sayısına bakalım. Her müşteri satırında kendisiyle ilişkilendirilmiş bir destek bileti sayısı vardır. Bu durumda destek bileti sayısı arttıkça derecelendirmenin düşük olma olasılığı 4,08 kat artar. Sağdaki görsel, müşteri düzeyinde değerlendirilen farklı Derecelendirme değerlerine göre ortalama destek bileti sayısını gösterir.
Sonuçları yorumlama: En üst segmentler
Her faktörü ayrı ayrı değerlendirmek için Ana etmenler sekmesini kullanabilirsiniz. Faktörlerin birleşiminin analiz ettiğiniz ölçümü nasıl etkilediğini görmek için Üst segmentler sekmesini de kullanabilirsiniz.
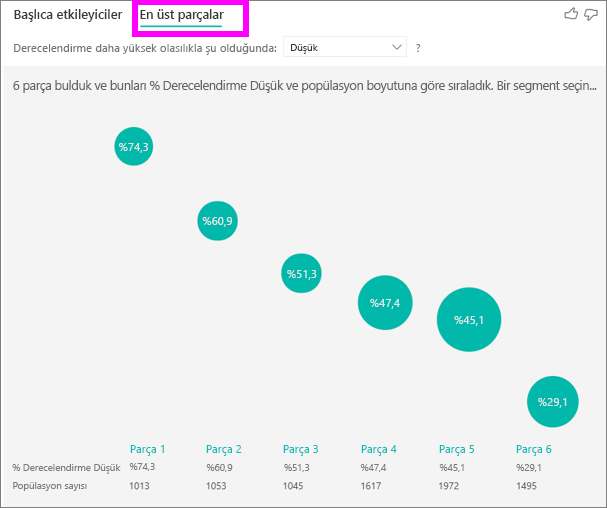
En üst segmentler başlangıçta Power BI'ın keşfettiği tüm segmentlere genel bir bakış gösterir. Aşağıdaki örnekte altı segmentin bulunduğu gösterilmektedir. Bu segmentler, segment içindeki düşük derecelendirme yüzdesine göre sıralanır. Örneğin segment 1'de %74,3 düşük müşteri derecelendirmesi vardır. Kabarcık ne kadar yüksek olursa düşük derecelendirmelerin oranı o kadar yüksektir. Kabarcığın boyutu, segment içinde kaç müşterinin olduğunu temsil eder.
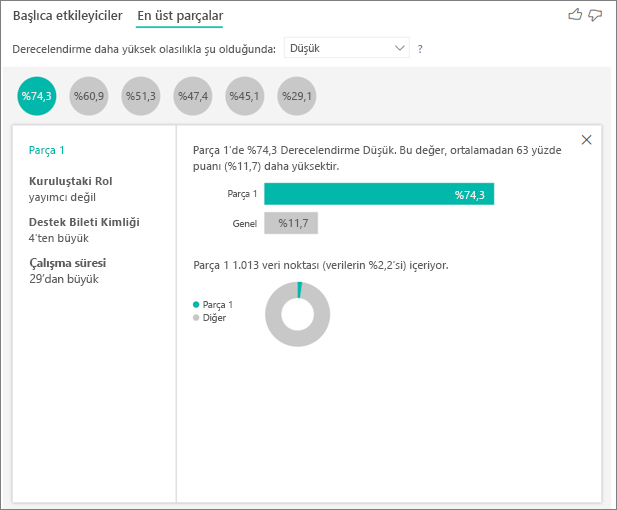
Kabarcık seçildiğinde bu segmentin ayrıntıları görüntülenir. Örneğin Segment 1'i seçerseniz, bunun görece yerleşik müşterilerden kaynaklandığını fark edebilirsiniz. 29 aydan uzun süredir müşteridirler ve dörtten fazla destek bileti vardır. Son olarak, yayımcı değildirler, bu nedenle tüketici veya yöneticidirler.
Bu grupta müşterilerin %74,3'ünün düşük derecelendirme verdiği açıklandı. Ortalama müşteri% 11,7 düşük derecelendirme verdi, bu nedenle bu segment düşük derecelendirmelerin daha büyük bir oranına sahip. Yüzde 63 daha yüksek. Segment 1 ayrıca verilerin yaklaşık %2,2'sini içerdiğinden popülasyonun adreslenebilir bir bölümünü temsil eder.
Sayı ekleme
Bazen bir etmen önemli bir etkiye sahip olabilir ancak verilerin çok azını temsil edebilir. Örneğin, Tema kullanılabilirlik düşük derecelendirmeler için üçüncü en büyük etmendir. Ancak kullanılabilirlikten şikayet eden yalnızca birkaç müşteri olabilir. Sayımlar, odaklanmak istediğiniz etmenleri önceliklendirmenize yardımcı olabilir.
Sayıları biçimlendirme bölmesinin Çözümleme kartı aracılığıyla açabilirsiniz.
Sayımlar etkinleştirildikten sonra, etmenlerin içerdiği verilerin yaklaşık yüzdesini temsil eden her bir etmen balonunun etrafında bir halka görürsünüz. Halka ne kadar çok kabarcık daire içine alırsa, o kadar fazla veri içerir. Temanın kullanılabilirlik olduğunu, verilerin küçük bir kısmını içerdiğini görebiliriz.
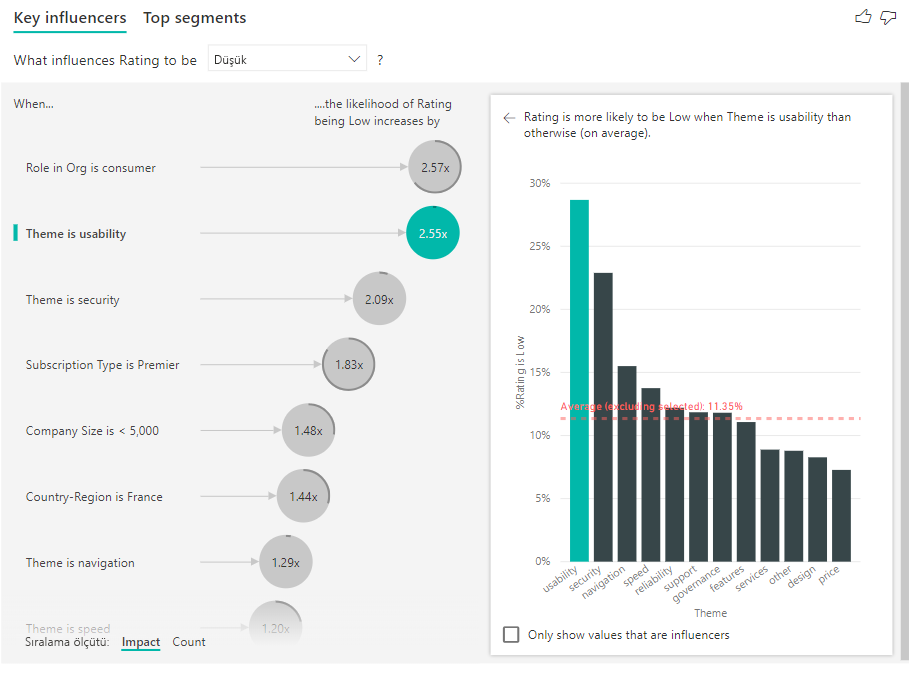
Baloncukları etki yerine önce sayıya göre sıralamak için görselin sol alt kısmındaki Sıralama ölçütü düğmesini de kullanabilirsiniz. Abonelik Türü Premier, sayıya göre en önemli etmendir.
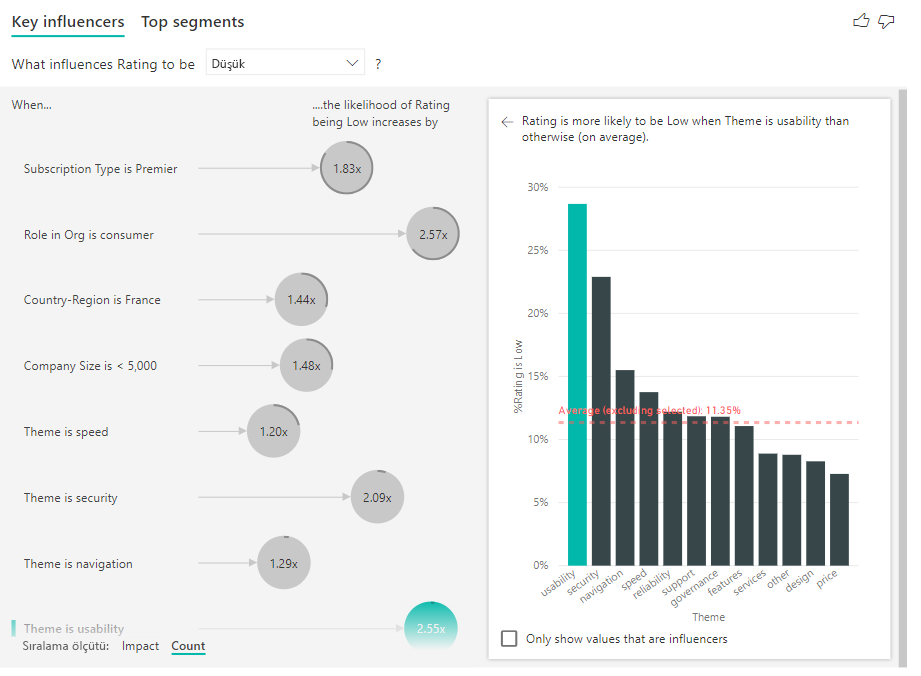
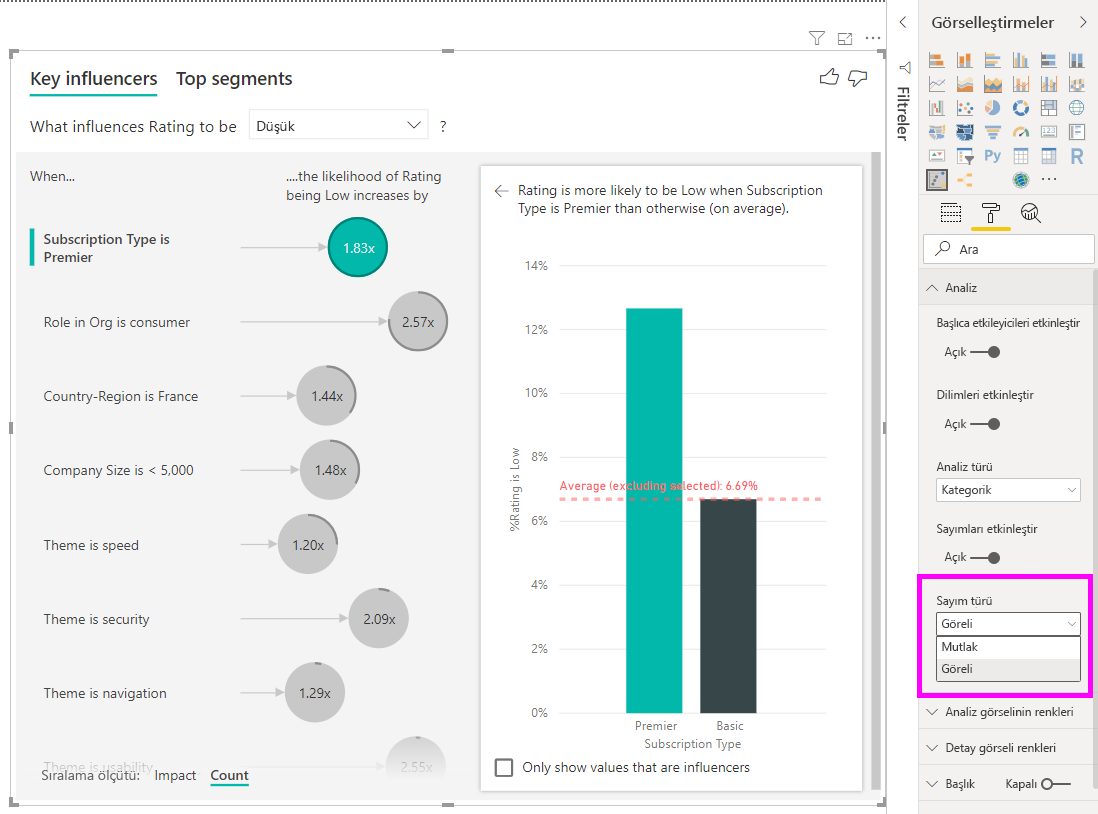
Dairenin etrafında tam halka olması, etmenlerin verilerin %100'lerini içerdiği anlamına gelir. Biçimlendirme bölmesinin Çözümleme kartındaki Sayı türü açılan listesini kullanarak, sayı türünü en yüksek etmenle göreli olacak şekilde değiştirebilirsiniz. Artık en fazla veri miktarına sahip etmen tam halkayla gösterilir ve diğer tüm sayımlar buna göre yapılır.
Sayısal bir ölçümü analiz etme
Özetlenmemiş bir sayısal alanı Çözümle alanına taşırsanız, bu senaryoyu işlemeyi tercih edebilirsiniz. Biçimlendirme Bölmesi'ne gidip Kategorik Çözümleme Türü ile Sürekli Çözümleme Türü arasında geçiş yaparak görselin davranışını değiştirebilirsiniz.
Kategorik Çözümleme Türü, yukarıda açıklandığı gibi davranır. Örneğin, 1 ile 10 arasında değişen anket puanlarına bakıyorsanız , 'Anket Puanlarının 1 olmasını etkileyen nedir?' sorusunu sorabilirsiniz.
Sürekli Çözümleme Türü , soruyu sürekli bir soru olarak değiştirir. Yukarıdaki örnekte, yeni sorumuz 'Anket Puanlarını artırmaya/azaltmaya ne etkiler?' olacaktır.
Bu ayrım, analiz ettiğiniz alanda çok sayıda benzersiz değer olduğunda yararlıdır. Aşağıdaki örnekte ev fiyatlarına bakacağız. 'House Price'ın 156.214 olmasını etkileyen nedir?' sorusunu sormak anlamlı değildir. çünkü bu çok özeldir ve bir deseni çıkarsamak için yeterli veriye sahip olmayabiliriz.
Bunun yerine "Ev Fiyatının artmasına ne etki eder" sorusunu sormak isteyebiliriz. bu da ev fiyatlarını farklı değerler yerine bir aralık olarak ele almanızı sağlar.
Sonuçları yorumlama: Önemli etmenler
Not
Bu bölümdeki örneklerde genel etki alanı House Prices verileri kullanılır. Takip etmek isterseniz örnek veri kümesini indirebilirsiniz.
Bu senaryoda ,'Ev Fiyatının artmasına neden olan şey' konusuna bakacağız. Year Built (evin inşa edildiği yıl), KitchenQual (mutfak kalitesi) ve YearRemodAdd (evin yeniden modellendiği yıl) gibi bir dizi açıklayıcı faktör ev fiyatını etkileyebilir.
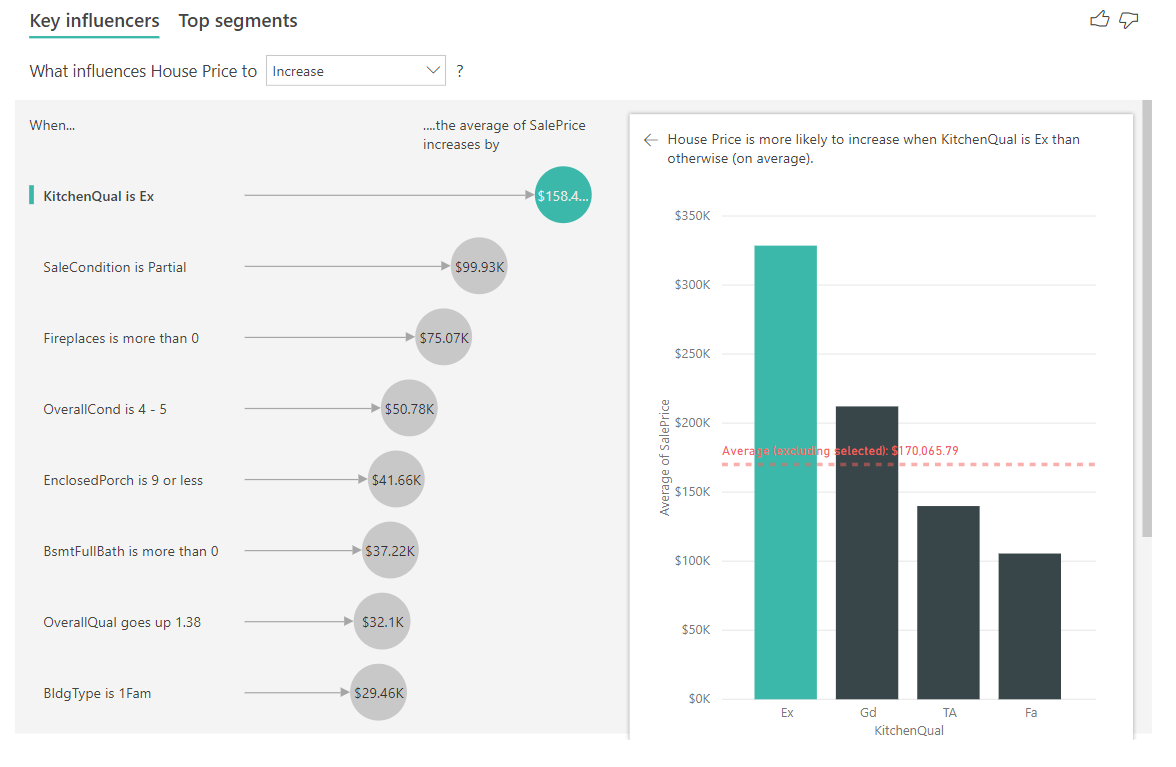
Aşağıdaki örnekte, mutfak kalitesinin Mükemmel olduğu en üst etmene bakacağız. Sonuçlar, kategorik ölçümleri birkaç önemli farkla analiz ederken gördüğümüz sonuçlara benzer:
- Sağdaki sütun grafiği yüzdeler yerine ortalamalara bakıyor. Bu nedenle, mükemmel bir mutfağı olan bir evin ortalama ev fiyatının (yeşil bar) mükemmel bir mutfak olmayan bir evin ortalama ev fiyatına kıyasla (yeşil bar) olduğunu gösterir (noktalı çizgi)
- Kabarcıktaki sayı hala kırmızı noktalı çizgi ile yeşil çubuk arasındaki farktır, ancak bir olasılık (1,93x) yerine sayı (158,49 BIN ABD doları) olarak ifade edilir. Yani ortalama olarak, mükemmel mutfakları olan evler mükemmel mutfakları olmayan evlerden neredeyse 160 bin $ daha pahalıdır.
Aşağıdaki örnekte, sürekli bir faktörün (evin yeniden modellendiği yıl) ev fiyatı üzerindeki etkisine bakacağız. Kategorik ölçümler için sürekli etmenleri analiz etme şeklimiz ile karşılaştırıldığında farklılıklar şunlardır:
- Sağ bölmedeki dağılım grafiği, yeniden modellenen yılın her ayrı değeri için ortalama ev fiyatını çizer.
- Kabarcıktaki değer, evin yeniden modellendiği yıl standart sapmasıyla (bu örnekte 20 yıl) arttığında ortalama ev fiyatının ne kadar arttığını (bu örnekte 2,87 bin ABD doları) gösterir

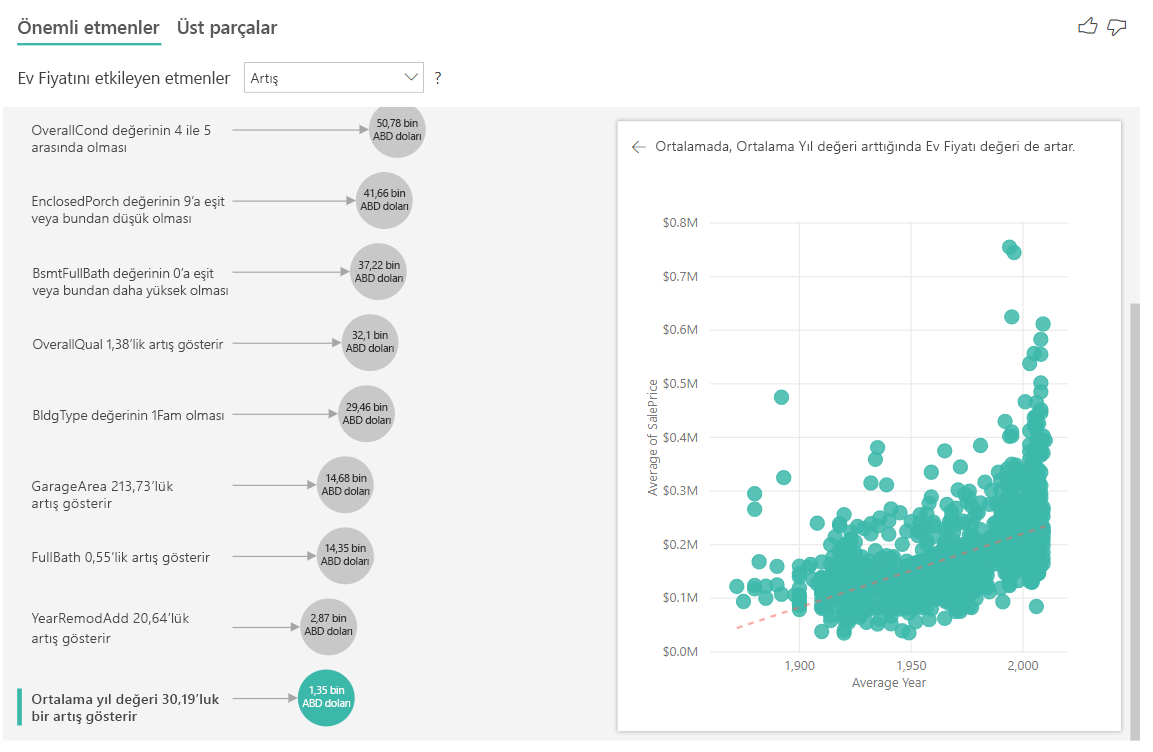
Son olarak, ölçüler söz konusu olduğunda, bir evin inşa edildiği ortalama yıla bakıyoruz. Analiz aşağıdaki gibidir:
- Sağ bölmedeki dağılım grafiği, tablodaki her ayrı değer için ortalama ev fiyatını çizer
- Kabarcıktaki değer, ortalama yıl standart sapması (bu örnekte 30 yıl) arttığında ortalama ev fiyatının ne kadar arttığını (bu örnekte 1,35 BIN ABD doları) gösterir
Sonuçları yorumlama: Üst Segmentler
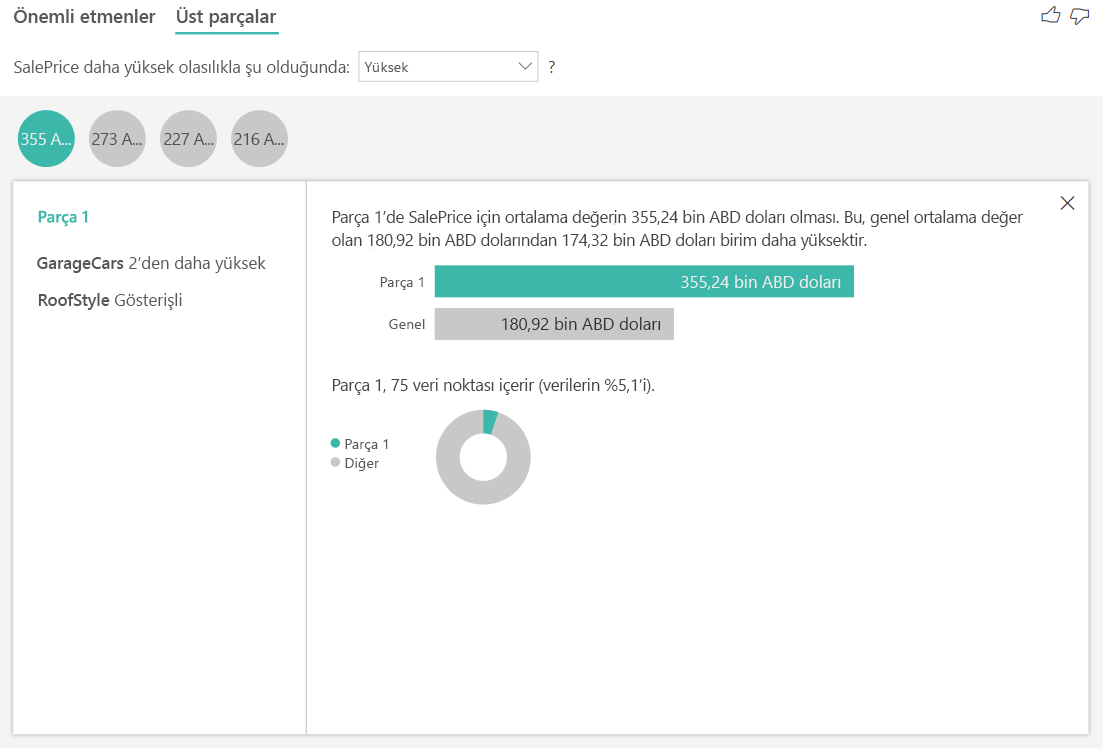
Sayısal hedefler için en üst segmentler, ortalama olarak ev fiyatlarının genel veri kümesinden daha yüksek olduğu grupları gösterir. Örneğin, aşağıda Segment 1'in GarageCars'ın (garajın sığabileceği araba sayısı) 2'den büyük olduğu ve RoofStyle'ın Hip olduğu evlerden oluştuğuna bakabiliriz. Bu özelliklere sahip evlerin ortalama fiyatı 355.000 ABD doları olan verilerdeki genel ortalamaya kıyasla 180.000 TL'dir.
Ölçü veya özetlenmiş sütun olan bir ölçümü analiz etme
Ölçü veya özetlenmiş sütun söz konusu olduğunda analiz varsayılan olarak yukarıda açıklanan Sürekli Çözümleme Türü'nü kullanır. Bu değer değiştirilemez. Ölçü/özetlenmiş sütun ile özetlenmemiş sayısal sütunu analiz etme arasındaki en büyük fark, çözümlemenin çalıştırıldığı düzeydir.
Özetlenmemiş sütunlar söz konusu olduğunda analiz her zaman tablo düzeyinde çalışır. Yukarıdaki ev fiyatı örneğinde Ev Fiyatı ölçümünü analiz ettik ve bir ev fiyatının artmasını/düşmesini neyin etkilediğini gördük. Çözümleme otomatik olarak tablo düzeyinde çalışır. Tablomuzda her ev için benzersiz bir kimlik vardır, bu nedenle analiz ev düzeyinde çalışır.
Ölçüler ve özetlenmiş sütunlar için bunları analiz etmek için gereken düzeyi hemen bilmiyoruz. Ev Fiyatı Ortalama olarak özetlenmişse, bu ortalama ev fiyatının hesaplanmış olmasını istediğimiz düzeyi göz önünde bulundurmamız gerekir. Mahalle düzeyinde ortalama ev fiyatı mı? Ya da bölgesel düzeyde?
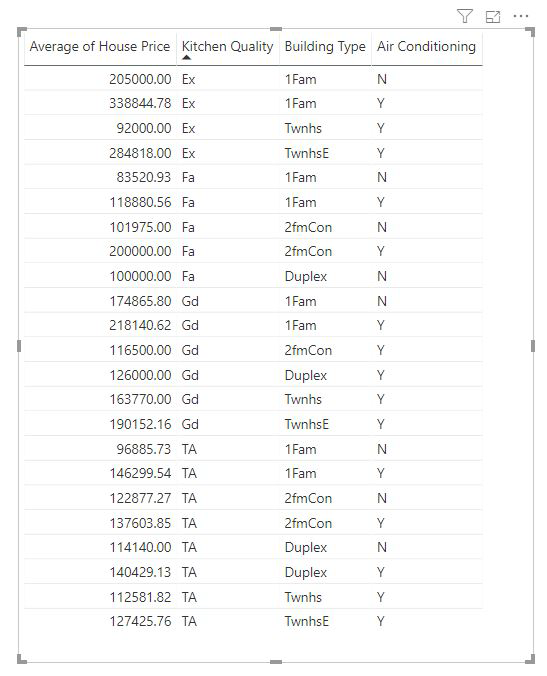
Ölçüler ve özetlenmiş sütunlar, kullanılan Açıklama ölçütü alanlarının düzeyinde otomatik olarak analiz edilir. Explain By'da ilgilendiğimiz üç alan olduğunu düşünün: Mutfak Kalitesi, Yapı Tipi ve Klima. Ortalama Ev Fiyatı , bu üç alanın her benzersiz bileşimi için hesaplanır. Değerlendirilen verilerin nasıl göründüğüne bakmak için genellikle tablo görünümüne geçmek yararlı olur.
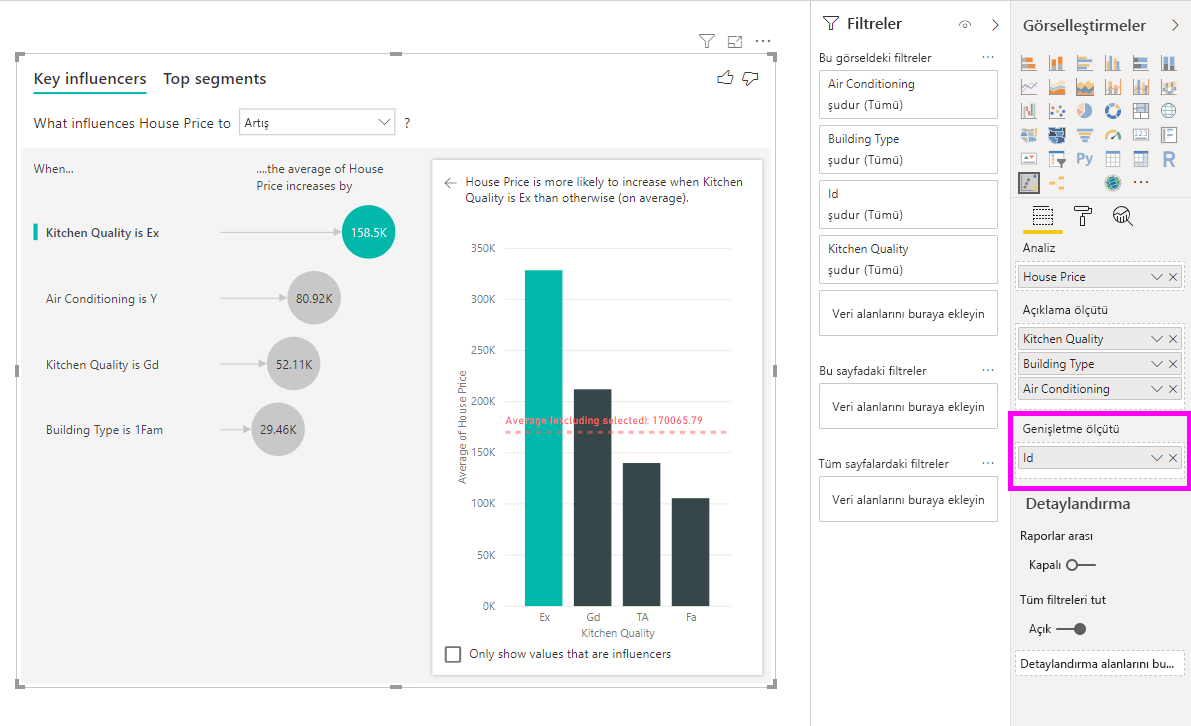
Bu analiz çok özetlenir ve bu nedenle regresyon modelinin verilerde öğrenebileceği desenleri bulması zor olacaktır. Daha iyi sonuçlar elde etmek için analizi daha ayrıntılı bir düzeyde çalıştırmalıyız. Ev fiyatını ev düzeyinde analiz etmek isteseydik, kimlik alanını analize açıkça eklememiz gerekirdi. Bununla birlikte, ev kimliğinin bir etmen olarak değerlendirilmesini istemiyoruz. Ev kimliği arttıkça ev fiyatının arttığını öğrenmek yararlı değildir. Alan kutusuna göre Genişlet seçeneği burada kullanışlıdır. Yeni etmenler aramadan çözümleme düzeyini ayarlamak için kullanmak istediğiniz alanları eklemek için Genişlet'i kullanabilirsiniz.
Genişletme Ölçütü'ne kimlik ekledikten sonra görselleştirmenin nasıl göründüğüne göz atın. Ölçünüzün değerlendirilmesini istediğiniz düzeyi tanımladıktan sonra, etmenleri yorumlamak özetlenmemiş sayısal sütunlarla tam olarak aynıdır.
Ana etmenler görselleştirmesi ile ölçüleri nasıl analiz edeceğiniz hakkında daha fazla bilgi edinmek istiyorsanız lütfen aşağıdaki videoyu izleyin. Power BI'ın verilerle ilgili fikir edinmek ve içgörüleri doğal bir şekilde ortaya çıkarabilmek için arka planda ML.NET nasıl kullandığını öğrenmek için bkz . Power BI, ML.NET kullanarak önemli etmenleri tanımlar.
Not
Bu videoda Power BI Desktop'ın önceki sürümleri veya Power BI hizmeti kullanılabilir.
Dikkat edilmesi gerekenler ve sorun giderme
Görselin sınırlamaları nelerdir?
Ana etmenler görselinin bazı sınırlamaları vardır:
- Doğrudan Sorgu desteklenmiyor
- Azure Analysis Services ve SQL Server Analysis Services için canlı Bağlan desteklenmez
- Web'de yayımlama desteklenmiyor
- .NET Framework 4.6 veya üzeri gereklidir
- SharePoint Online ekleme desteklenmiyor
Etmenlerin veya kesimlerin bulunamadığını belirten bir hata görüyorum. Bunun nedeni nedir?
Bu hata, Açıklama ölçütü'ne alanlar eklediğinizde ancak hiçbir etmen bulunamadığında oluşur.
- Analiz ettiğiniz ölçümü hem Çözümle hem de Açıklama ölçütü'ne dahil ettiniz. Açıklama ölçütü'nden kaldırın.
- Açıklayıcı alanlarınız az gözlem içeren çok fazla kategoriye sahip. Bu durum görselleştirmenin hangi faktörlerin etmen olduğunu belirlemesini zorlaştırır. Yalnızca birkaç gözleme dayanarak genelleştirmek zordur. Sayısal bir alanı analiz ediyorsanız, Çözümleme kartının altındaki Biçimlendirme Bölmesi'nde Kategorik Çözümleme'den Sürekli Çözümleme'ye geçmek isteyebilirsiniz.
- Açıklayıcı faktörleriniz genelleştirmek için yeterli gözleme sahiptir, ancak görselleştirme rapor etmek için anlamlı bir bağıntı bulamadı.
Çözümlediğim ölçümün çözümlemeyi çalıştırmak için yeterli veriye sahip olmadığını belirten bir hata görüyorum. Bunun nedeni nedir?

Görselleştirme, diğer gruplara kıyasla bir grubun verilerindeki desenlere bakarak çalışır. Örneğin, yüksek derecelendirme yapan müşterilerle karşılaştırıldığında düşük derecelendirmeler veren müşterileri arar. Modelinizdeki verilerin yalnızca birkaç gözlemi varsa desenleri bulmak zordur. Görselleştirmede anlamlı etmenleri bulmak için yeterli veri yoksa, analizi çalıştırmak için daha fazla veri gerektiğini gösterir.
Seçili durum için en az 100 gözleme sahip olmanız önerilir. Bu durumda durum, değişim gösteren müşterilerdir. Karşılaştırma için kullandığınız durumlar için de en az 10 gözlem gerekir. Bu durumda karşılaştırma durumu, değişim sıklığı olmayan müşterilerdir.
Sayısal bir alanı analiz ediyorsanız, Çözümleme kartının altındaki Biçimlendirme Bölmesi'nde Kategorik Çözümleme'den Sürekli Çözümleme'ye geçmek isteyebilirsiniz.
'Çözümle' özetlenmediğinde çözümlemenin her zaman üst tablosunun satır düzeyinde çalıştığı bir hata görüyorum. Bu düzeyin 'Genişletme ölçütü' alanlarıyla değiştirilmesine izin verilmez. Bunun nedeni nedir?
Sayısal veya kategorik bir sütunu analiz ederken, çözümleme her zaman tablo düzeyinde çalışır. Örneğin, ev fiyatlarını analiz ediyorsanız ve tablonuz bir kimlik sütunu içeriyorsa, analiz otomatik olarak ev kimliği düzeyinde çalışır.
Bir ölçüyü veya özetlenmiş sütunu analiz ederken, analizin hangi düzeyde çalıştırılmasını istediğinizi açıkça belirtmelisiniz. Yeni etmenler eklemeden ölçülerin ve özetlenmiş sütunların çözümleme düzeyini değiştirmek için Genişlet'i kullanabilirsiniz. Ev fiyatı ölçü olarak tanımlanmışsa, analiz düzeyini değiştirmek için Ev Kimliği sütununu Genişlet'e ekleyebilirsiniz.
Açıklama ölçütü'ndeki bir alanın çözümlediğim ölçümü içeren tabloyla benzersiz olarak ilişkili olmadığını belirten bir hata görüyorum. Bunun nedeni nedir?
Çözümleme, analiz edilen alanın tablo düzeyinde çalışır. Örneğin, hizmetiniz için müşteri geri bildirimlerini analiz ederseniz, bir müşterinin yüksek derecelendirme mi yoksa düşük derecelendirme mi verdiğini belirten bir tablonuz olabilir. Bu durumda analiziniz müşteri tablosu düzeyinde çalışır.
Ölçümünüzü içeren tablodan daha ayrıntılı bir düzeyde tanımlanmış ilişkili bir tablonuz varsa bu hatayı görürsünüz. Bir örnek aşağıda verilmiştir:
- Müşterileri hizmetinizin düşük derecelendirmelerini vermeye yönlendiren şeyleri analiz edebilirsiniz.
- Müşterinin hizmetinizi tüketdiği cihazın, yaptıkları incelemeleri etkilenip etkilemediğini görmek istiyorsunuz.
- Bir müşteri hizmeti birden çok farklı şekilde kullanabilir.
- Aşağıdaki örnekte müşteri 100000000, hizmetle etkileşime geçmek için hem tarayıcı hem de tablet kullanır.
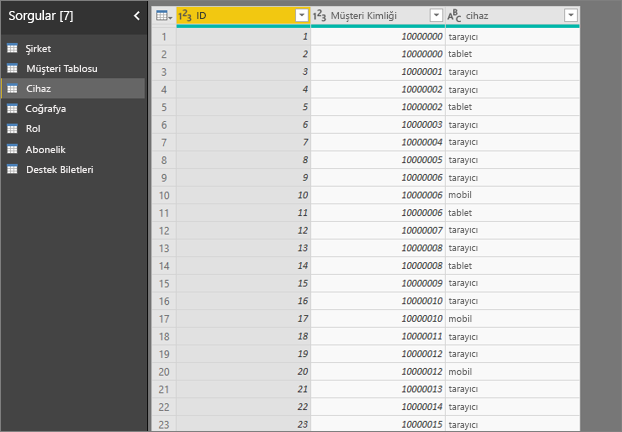
Cihaz sütununu açıklayıcı bir faktör olarak kullanmaya çalışırsanız aşağıdaki hatayı görürsünüz:

Cihaz müşteri düzeyinde tanımlanmadığından bu hata görüntülenir. Bir müşteri hizmeti birden çok cihazda kullanabilir. Görselleştirmenin desenleri bulması için cihazın müşterinin bir özniteliği olması gerekir. İşletmeyi anlamanıza bağlı olan çeşitli çözümler vardır:
- Saymak için cihazların özetlemeyi değiştirebilirsiniz. Örneğin, cihaz sayısı müşterinin verdiği puanı etkileyebilirse sayıyı kullanın.
- Hizmeti belirli bir cihazda kullanmanın müşterinin derecelendirmesini etkilenip etkilemediğini görmek için cihaz sütununu özetleyebilirsiniz.
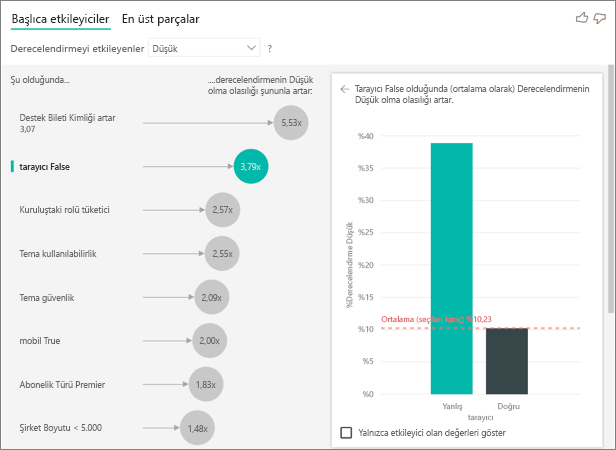
Bu örnekte veriler tarayıcı, mobil ve tablet için yeni sütunlar oluşturmak üzere özetlenmiştir (verilerinizi özetledikten sonra modelleme görünümünde ilişkilerinizi silip yeniden oluşturduğunuzdan emin olun). Bu belirli cihazları açıklama ölçütü bölümünden kullanabilirsiniz. Tüm cihazların etmen olduğu ortaya çıkar ve tarayıcı müşteri puanı üzerinde en büyük etkiye sahiptir.
Daha kesin olarak, hizmeti kullanmak için tarayıcıyı kullanmayan müşterilerin düşük puan verme olasılığı, kullanan müşterilere göre 3,79 kat daha yüksektir. Listenin alt kısmında, mobil için tersi doğrudur. Mobil uygulamayı kullanan müşterilerin düşük puan verme olasılığı, kullanmayan müşterilere göre daha yüksektir.
Ölçülerin analizime dahil edilmediğini belirten bir uyarı görüyorum. Bunun nedeni nedir?
Çözümleme, analiz edilen alanın tablo düzeyinde çalışır. Müşteri değişim değişim oranını analiz ederseniz, bir müşterinin değişim sıklığı olup olmadığını belirten bir tablonuz olabilir. Bu durumda, çözümlemeniz müşteri tablosu düzeyinde çalışır.
Ölçüler ve toplamalar varsayılan olarak tablo düzeyinde analiz edilir. Ortalama aylık harcama için bir ölçü olsaydı, bu ölçü müşteri tablosu düzeyinde analiz edilirdi.
Müşteri tablosunun benzersiz bir tanımlayıcısı yoksa, ölçüyü değerlendiremezsiniz ve analiz tarafından yoksayılır. Bu durumu önlemek için, ölçümünüzün bulunduğu tablonun benzersiz bir tanımlayıcısı olduğundan emin olun. Bu durumda, bu müşteri tablosudur ve benzersiz tanımlayıcı müşteri kimliğidir. Power Query kullanarak dizin sütunu eklemek de kolaydır.
Çözümlediğim ölçümün 10'dan fazla benzersiz değere sahip olduğunu ve bu miktarın analizimin kalitesini etkileyebileceğini belirten bir uyarı görüyorum. Bunun nedeni nedir?
Yapay zeka görselleştirmesi kategorik alanları ve sayısal alanları analiz edebilir. Kategorik alanlar söz konusu olduğunda, Değişim Sıklığı Evet veya Hayır, Müşteri Memnuniyeti ise Yüksek, Orta veya Düşük olabilir. Analiz için kategorilerin sayısını artırmak, kategori başına daha az gözlem olduğu anlamına gelir. Bu durum görselleştirmenin verilerdeki desenleri bulmasını zorlaştırır.
Sayısal alanları analiz ederken, sayısal alanları metin gibi ele alma arasında seçim yapabilirsiniz. Bu durumda, kategorik veriler için yaptığınız çözümlemenin aynısını çalıştırırsınız (Kategorik Çözümleme). Çok sayıda farklı değeriniz varsa, çözümlemeyi Sürekli Analiz'e geçirmenizi öneririz, bu da sayıların farklı değerler olarak ele almak yerine arttığı veya azaldığını gösteren desenler çıkarabildiğimiz anlamına gelir. Kategorik Çözümleme'den Sürekli Çözümleme'ye, Çözümleme kartının altındaki Biçimlendirme Bölmesi'nde geçiş yapabilirsiniz.
Daha güçlü etmenler bulmak için benzer değerleri tek bir ünitede gruplandırmanızı öneririz. Örneğin, fiyat ölçümüne sahipseniz, benzer fiyatları Yüksek, Orta ve Düşük kategorilerinde gruplandırarak ve tek tek fiyat noktalarını kullanarak daha iyi sonuçlar elde edebilirsiniz.
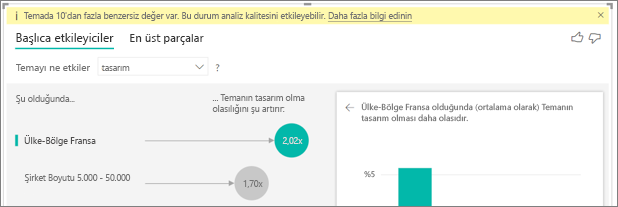
Verilerimde önemli etmenler olması gerektiği gibi görünen faktörler var, ancak bunlar değil. Bu nasıl olur?
Aşağıdaki örnekte, tüketici olan müşteriler düşük derecelendirmeler kullanır ve derecelendirmelerin %14,93'ünün düşük olduğunu gösterir. Yönetici rolünün düşük derecelendirme oranı da %13,42'dir ancak etmen olarak kabul edilmez.
Bu belirlemenin nedeni, görselleştirmenin etmenleri bulduğunda veri noktalarının sayısını da dikkate almasıdır. Aşağıdaki örnekte 29.000'den fazla tüketici ve 10 kat daha az yönetici (yaklaşık 2.900) vardır. Sadece 390 tanesi düşük derecelendirme yaptı. Görselin yönetici derecelendirmelerine sahip bir desen bulup bulmadığını veya bunun yalnızca bir şans bulma şansı olup olmadığını belirlemek için yeterli veri yok.
Ana etmenler için veri noktası sınırları nelerdir? Analizi 10.000 veri noktası örneği üzerinde çalıştırıyoruz. Bir taraftaki kabarcıklar bulunan tüm etmenleri gösterir. Diğer taraftaki sütun grafikler ve dağılım grafikleri, bu çekirdek görseller için örnekleme stratejilerine uyar.
Kategorik analiz için ana etmenleri nasıl hesaplarsınız?
Arka planda yapay zeka görselleştirmesi, ana etmenleri hesaplamak üzere lojistik regresyon çalıştırmak için ML.NET kullanır. Lojistik regresyon, farklı grupları birbiriyle karşılaştıran istatistiksel bir modeldir.
Düşük derecelendirmeleri neyin yönlendirdiğini görmek istiyorsanız lojistik regresyon, düşük puan veren müşterilerin yüksek puan veren müşterilerden nasıl farklı olduğunu gösterir. Yüksek, nötr ve düşük puanlar gibi birden çok kategoriniz varsa, düşük derecelendirme yapan müşterilerin düşük derecelendirme vermeyen müşterilerden nasıl farklı olduğunu göreceksiniz. Bu durumda düşük puan veren müşterilerin yüksek derecelendirme veya nötr derecelendirme yapan müşterilerden farkı nedir?
Lojistik regresyon, verilerdeki desenleri arar ve düşük derecelendirme yapan müşterilerin yüksek derecelendirme yapan müşterilerden nasıl farklı olabileceğini arar. Örneğin, daha fazla destek bileti olan müşterilerin, destek bileti olan veya olmayan müşterilere kıyasla düşük derecelendirme yüzdesinin daha yüksek olduğunu fark edebilir.
Lojistik regresyon kaç veri noktası olduğunu da dikkate alır. Örneğin, yönetici rolü oynayan müşteriler orantılı olarak daha fazla negatif puan veriyorsa ancak yalnızca birkaç yönetici varsa, bu faktör etkili olarak kabul edilmez. Bu belirleme, bir deseni çıkarsamak için yeterli veri noktası olmadığından yapılır. Bir faktörün etmen olarak kabul edilip edilmediğini belirlemek için Wald testi olarak bilinen istatistiksel test kullanılır. Görsel, eşiği belirlemek için 0,05 p değerini kullanır.
Sayısal analiz için ana etmenleri nasıl hesaplarsınız?
Arka planda yapay zeka görselleştirmesi, ana etmenleri hesaplamak için doğrusal regresyon çalıştırmak için ML.NET kullanır. Doğrusal regresyon, analiz ettiğiniz alanın sonucunun açıklayıcı faktörlerinize göre nasıl değiştiğini gösteren istatistiksel bir modeldir.
Örneğin, ev fiyatlarını analiz ediyorsak doğrusal bir regresyon, mükemmel bir mutfağa sahip olmanın ev fiyatı üzerindeki etkisine bakar. Mükemmel mutfakları olan evlerde genellikle mükemmel mutfakları olmayan evlerle karşılaştırıldığında daha düşük veya daha yüksek ev fiyatları var mı?
Doğrusal regresyon, veri noktalarının sayısını da dikkate alır. Örneğin, tenis kortları olan evlerin fiyatları daha yüksekse ancak tenis kortu olan birkaç evimiz varsa, bu faktör etkili olarak kabul edilmez. Bu belirleme, bir deseni çıkarsamak için yeterli veri noktası olmadığından yapılır. Bir faktörün etmen olarak kabul edilip edilmediğini belirlemek için Wald testi olarak bilinen istatistiksel test kullanılır. Görsel, eşiği belirlemek için 0,05 p değerini kullanır.
Segmentleri nasıl hesaplarsınız?
Arka planda yapay zeka görselleştirmesi ilginç alt grupları bulmak için bir karar ağacı çalıştırmak için ML.NET kullanır. Karar ağacının amacı, ilgilendiğiniz ölçümde görece yüksek bir veri noktaları alt grubuna ulaşmaktır. Düşük derecelendirmeye sahip müşteriler veya yüksek fiyatlara sahip evler olabilir.
Karar ağacı her açıklayıcı faktörü alır ve hangi faktörün en iyi bölmeyi sağladığını muhakeme etmeye çalışır. Örneğin, verileri yalnızca büyük kurumsal müşterileri içerecek şekilde filtrelerseniz bu, yüksek derecelendirme ve düşük derecelendirme yapan müşterileri ayırır mı? Ya da verileri yalnızca güvenlikle ilgili yorum yapan müşterileri içerecek şekilde filtrelemek daha iyi olabilir mi?
Karar ağacı bir bölme işlemi yaptıktan sonra veri alt grubunu alır ve bu veriler için bir sonraki en iyi bölmeyi belirler. Bu durumda alt grup, güvenlikle ilgili yorum yapan müşterilerdir. Her bölmeden sonra karar ağacı, bu grubun bir deseni çıkarabilecek kadar temsili olması için yeterli veri noktasına sahip olup olmadığını veya bunun gerçek bir segment değil, verilerdeki bir anomali olup olmadığını da değerlendirir. P değeri 0,05 olan bölme koşulunun istatistiksel önemini denetlemek için başka bir istatistiksel test uygulanır.
Karar ağacının çalışması bittikten sonra, güvenlik açıklamaları ve büyük kuruluş gibi tüm bölmeleri alır ve Power BI filtreleri oluşturur. Bu filtre bileşimi görselde bir segment olarak paketlenir.
Açıklama ölçütü alanına daha fazla alan taşırken neden belirli faktörler etmen haline gelir veya etmen olmaktan vazgeçer?
Görselleştirme tüm açıklayıcı faktörleri birlikte değerlendirir. Bir faktör kendi başına bir etmen olabilir, ancak diğer faktörlerle birlikte değerlendirildiğinde olmayabilir. Açıklayıcı faktörler olarak yatak odaları ve ev boyutu ile bir ev fiyatının yüksek olmasına neyin neden olduğunu analiz etmek istediğinizi varsayalım:
- Tek başına, daha fazla yatak odası ev fiyatlarının yüksek olması için bir sürücü olabilir.
- Analize ev boyutu dahil etmek, artık ev boyutu sabit kalırken yatak odalarına ne olduğunu inceleyebilmek anlamına gelir.
- Ev boyutu 1.500 metrekare olarak sabitlenmişse, yatak odası sayısında sürekli bir artışın ev fiyatını önemli ölçüde artırması olası değildir.
- Yatak odaları, ev büyüklüğü dikkate alınmadan önceki bir faktör kadar önemli olmayabilir.
Raporunuzu bir Power BI iş arkadaşınızla paylaşmak için her ikisinde de ayrı Power BI Pro lisansları olması veya raporun Premium kapasitede kaydedilmesi gerekir. Bkz. raporları paylaşma.