使用 Azure 数据工厂引入 Dataverse 数据
使用 Azure Synapse Link for Dataverse 将数据从 Microsoft Dataverse 导出到 Azure Data Lake Storage Gen2 后,可以使用 Azure 数据工厂创建数据流、转换数据和运行分析。
备注
Azure Synapse Link for Dataverse 以前称为“导出到 Data Lake”。 此服务已更名,从 2021 年 5 月起生效,它会继续将数据导出到 Azure Data Lake 以及 Azure Synapse Analytics。
本文介绍如何执行以下任务:
设置 Data Lake Storage Gen2 存储帐户,并将 Dataverse 数据设置为数据工厂数据流中的源。
使用数据流在数据工厂中转换 Dataverse 数据。
设置 Data Lake Storage Gen2 存储帐户,并将 Dataverse 数据设置为数据工厂数据流中的接收器。
通过创建管道运行数据流。
先决条件
此部分介绍使用数据工厂引入导出的 Dataverse 数据必须满足的先决条件。
Azure 角色。 用于登录 Azure 的用户帐户必须是参与者或负责人角色的成员,或 Azure 订阅的管理员。 若要查看您在订阅中的权限,请转到 Azure 门户,在右上角选择您的用户名,选择 ...,然后选择 我的权限。 如果您有多个订阅的访问权限,请选择适合的那个。 若要在 Azure 门户中为数据工厂创建和管理子资源 — 包括数据集、链接的服务、管道、触发器和集成运行时 — 您必须是资源组级别或更高级别的 数据工厂参与者角色。
Azure Synapse Link for Dataverse。 本指南假设您已经使用 Azure Synapse Link for Dataverse 导出了 Dataverse 数据。 在此示例中,客户表数据被导出到数据湖。
Azure 数据工厂。 本指南假定您已经在与包含导出的 Dataverse 数据的存储帐户相同的订阅和资源组下创建了数据工厂。
将 Data Lake Storage Gen2 存储帐户设置为源
打开 Azure 数据工厂,选择与包含导出的 Dataverse 数据的存储帐户位于同一订阅和资源组上的数据工厂。 然后从首页选择创建数据流。
打开数据流调试模式,选择您的首选生存时间。 可能需要最多 10 分钟的时间,但您可以继续执行后续步骤。

选择添加源。

在源设置下,执行以下操作:
- 输出流名称:输入所需名称。
- 源类型:选择内联。
- 内联数据集类型:选择 Common Data Model。
- 链接的服务:从下拉菜单选择存储帐户,然后通过提供订阅详细信息并保留所有默认配置来链接新服务。
- 采样:如果要使用您的所有数据,请选择禁用。
在源选项下,执行以下操作:
元数据格式:选择 Model.json。
根位置:在第一个框(容器)中输入容器名称或浏览找到容器名称,然后选择确定。
实体:输入表名称或浏览找到表。

检查投影选项卡,确保您的架构已成功导入。 如果您看不到任何列,选择架构选项,检查推断偏移列类型选项。 配置格式选项以匹配您的数据集,然后选择应用。
您可以在数据预览选项卡中查看数据,以确保源创建是完整且准确的。
转换 Dataverse 数据
将 Azure Data Lake Storage Gen2 帐户中的导出 Dataverse 数据设置为数据工厂数据流中的源后,有多种可能来转换数据。 详细信息:Azure 数据工厂
按照这些说明按客户表的收入字段为每一行创建排名。
在上一个转换的右下角选择 +,然后搜索并选择排名。
在排名设置选项卡上,执行以下操作:
输出流名称:输入您需要的名称,如 Rank1。
传入流:选择所需的源名称。 在此例中,是上一个步骤中的源名称。
选项:保持选项不选中。
排名列:输入生成的排名列的名称。
排序条件:选择收入列,按降序顺序排序。
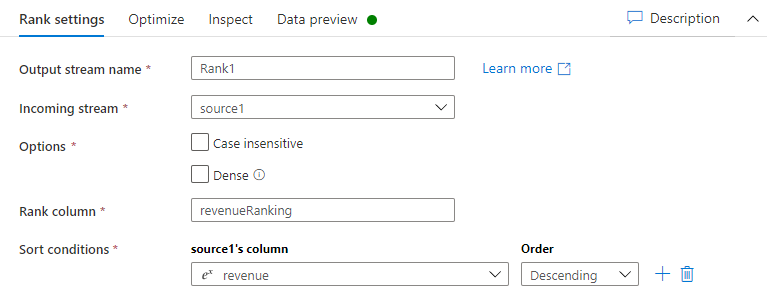
您可以在数据预览选项卡中查看数据,在此选项卡上,您会在最右侧的位置找到新的 revenueRank 列。
将 Data Lake Storage Gen2 存储帐户设置为接收器
最后,必须为数据流设置接收器。 按照以下说明将转换后的数据作为带分隔符的文本文件放在数据湖中。
在上一个转换的右下角选择 +,然后搜索并选择接收器。
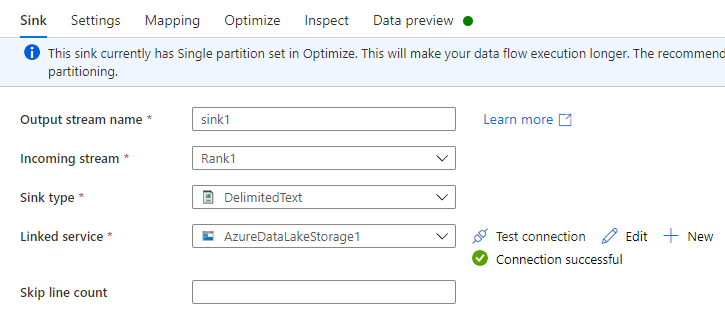
在接收器选项卡上,执行下列操作:
输出流名称: 输入所需名称,如 Sink1。
传入流:选择所需的源名称。 在此例中,是上一个步骤中的源名称。
接收器类型:选择 DelimitedText。
链接服务:选择包含您使用 Azure Synapse Link for Dataverse 服务导出的数据的 Data Lake Storage Gen2 存储容器。
在设置选项卡上,执行以下操作:
文件夹路径:在第一个框(文件系统)中输入容器名称或浏览找到容器名称,然后选择确定。
文件名选项:选择输出到单个文件。
输出到单个文件:输入文件名,如 ADFOutput
保留所有其他默认设置。
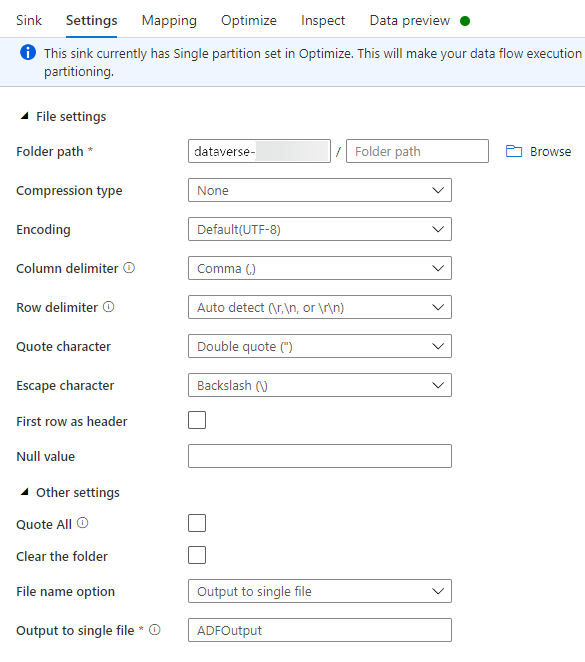
在优化选项卡上,将分区选项设置为单个分区。
您可以在数据预览选项卡中查看数据。
运行数据流
在左侧窗格中的工厂资源下,选择 +,然后选择管道。

在活动下,选择移动和转换,然后将数据流拖到工作区。
选择使用现有数据流,然后选择在之前步骤中创建的数据流。
从命令栏选择调试。
让数据流运行,直到底部视图显示已完成。 这可能需要几分钟时间。
转到最后的目标存储容器,找到转换后的表数据文件。