Continuous Integration und Continuous Delivery in Azure Data Factory
GILT FÜR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Bei Continuous Integration wird jede Änderung, die an Ihrer Codebasis vorgenommen wird, automatisch und so früh wie möglich getestet. Der Continuous Delivery-Prozess folgt auf das Testen während des Continuous Integration-Prozesses. Änderungen werden dabei in ein Staging- oder Produktionssystem gepusht.
In Azure Data Factory bedeuten Continuous Integration und Continuous Delivery (CI/CD), dass Data Factory-Pipelines von einer Umgebung (Entwicklung, Test, Produktion) in eine andere verschoben werden. Azure Data Factory nutzt Azure Resource Manager-Vorlagen zum Speichern der Konfiguration ihrer verschiedenen ADF-Entitäten (Pipelines, Datasets, Datenflüsse usw.). Es gibt zwei empfohlene Methoden zum Höherstufen einer Data Factory in eine andere Umgebung:
- Automatisierte Bereitstellung über Integration von Data Factory in Azure Pipelines
- Manuelles Hochladen einer Resource Manager-Vorlage über Integration der Data Factory-Benutzeroberfläche in Azure Resource Manager.
Hinweis
Es wird empfohlen, das Azure Az PowerShell-Modul für die Interaktion mit Azure zu verwenden. Informationen zu den ersten Schritten finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
CI/CD-Lebenszyklus
Hinweis
Weitere Informationen finden Sie unter Verbesserungen bei Continuous Deployment.
Unten ist eine Beispielübersicht des CI/CD-Lebenszyklus in einer Azure Data Factory-Instanz mit Konfiguration per Azure Repos Git angegeben. Weitere Informationen zum Konfigurieren eines Git-Repositorys finden Sie unter Quellcodeverwaltung in Azure Data Factory.
Eine Data Factory-Entwicklungsinstanz wird erstellt und mit Azure Repos Git konfiguriert. Alle Entwickler sollten über die Berechtigung zum Erstellen von Data Factory-Ressourcen wie Pipelines und Datasets verfügen.
Ein Entwickler erstellt einen Featurebranch, um eine Änderung vorzunehmen. Er debuggt die Pipelineausführungen mit seinen neuesten Änderungen. Weitere Informationen zum Debuggen einer Pipelineausführung finden Sie unter Iteratives Entwickeln und Debuggen mit Azure Data Factory.
Wenn ein Entwickler mit den vorgenommenen Änderungen zufrieden ist, erstellt er einen Pull Request vom Featurebranch zum Main- oder Kollaborationsbranch, um seine Änderungen von anderen Entwicklern überprüfen zu lassen.
Nachdem ein Pull Request genehmigt wurde und Änderungen im Mainbranch zusammengeführt wurden, werden die Änderungen in der Entwicklungsfactory veröffentlicht.
Wenn das Team bereit ist für die Bereitstellung der Änderungen in einer Test- oder UAT-Factory (User Acceptance Tests, Benutzerakzeptanztests), wechselt es zu seinem Azure Pipelines-Release und stellt die gewünschte Version der Entwicklungsfactory für UAT bereit. Diese Bereitstellung erfolgt im Rahmen einer Azure Pipelines-Aufgabe, und dabei kommen Resource Manager-Vorlagenparameter zum Einsatz, um die entsprechende Konfiguration anzuwenden.
Nachdem die Änderungen in der Testfactory überprüft wurden, stellen Sie sie mit der nächsten Aufgabe des Pipelines-Release in der Produktionsfactory bereit.
Hinweis
Nur die Entwicklungsfactory wird einem Git-Repository zugeordnet. Den Test- und Produktionsfactorys sollte kein Git-Repository zugeordnet sein, und sie sollten nur über eine Azure DevOps-Pipeline oder eine Resource Manager-Vorlage aktualisiert werden.
In der nachstehenden Abbildung sind die verschiedenen Schritte dieses Lebenszyklus hervorgehoben.
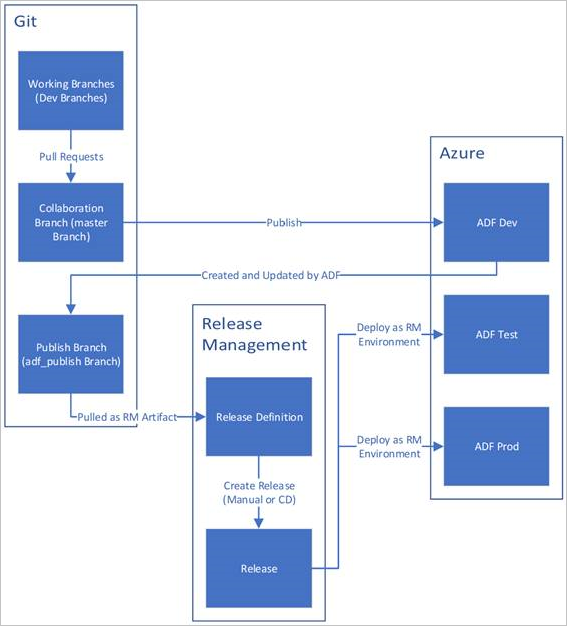
Bewährte Methoden für CI/CD
Wenn Sie die Git-Integration mit Ihrer Data Factory verwenden und über eine CI/CD-Pipeline verfügen, die Ihre Änderungen aus der Entwicklungs- in die Test- und dann in die Produktionsumgebung verschiebt, empfehlen wir Ihnen diese bewährten Methoden:
Git-Integration. Konfigurieren Sie nur Ihre Entwicklungs-Data Factory mit Git-Integration. Änderungen an den Test- und Produktionsumgebungen werden über CI/CD bereitgestellt, und eine Git-Integration wird hierfür nicht benötigt.
Skript für vor und nach der Bereitstellung. Bevor Sie den Schritt für die Resource Manager-Bereitstellung für CI/CD ausführen, müssen Sie bestimmte Aufgaben erledigen, z. B. das Beenden und erneute Starten von Triggern und das Durchführen einer Bereinigung. Wir empfehlen Ihnen, vor und nach der Bereitstellungsaufgabe PowerShell-Skripts zu verwenden. Weitere Informationen finden Sie unter Aktualisieren von aktiven Triggern. Das Data Factory Team hat am Ende dieser Seite ein Skript hinzugefügt, das Sie nutzen können.
Hinweis
Verwenden Sie PrePostDeploymentScript.Ver2.ps1, wenn Sie nur die Trigger aus-/einschalten möchten, die geändert wurden, anstatt alle Trigger während CI/CD aus-/einzuschalten.
Warnung
Stellen Sie sicher, dass Sie PowerShell Core in der ADO-Aufgabe verwenden, um das Skript auszuführen.
Warnung
Wenn Sie nicht die neuesten Versionen von PowerShell und des Data Factory-Moduls verwenden, treten beim Ausführen der Befehle möglicherweise Deserialisierungsfehler auf.
Integration Runtimes und Freigaben. Integration Runtimes werden nicht sehr häufig geändert und sind in allen Stufen von CI/CD ähnlich. Daher erwartet Data Factory, dass diese in allen Stufen von CI/CD den gleichen Integration Runtime-Namen, -Typ und -Untertyp aufweisen. Wenn Sie Integration Runtimes über alle Stufen hinweg freigeben möchten, können Sie eine ternäre Factory verwenden, die nur die freigegebenen Integration Runtimes enthält. Diese freigegebene Factory können Sie in allen Umgebungen als verknüpften Integration Runtime-Typ verwenden.
Hinweis
Die Integration Runtime-Freigabe ist nur für selbstgehostete Integration Runtimes verfügbar. Azure-SSIS-Integration Runtimes unterstützen die Freigabe nicht.
Bereitstellung eines verwalteten privaten Endpunkts. Wenn bereits ein privater Endpunkt in einer Factory vorhanden ist und Sie versuchen, eine ARM-Vorlage bereitzustellen, die einen privaten Endpunkt mit demselben Namen, jedoch mit geänderten Eigenschaften enthält, tritt bei der Bereitstellung ein Fehler auf. Das bedeutet, dass Sie einen privaten Endpunkt erfolgreich bereitstellen können, sofern dieser dieselben Eigenschaften wie der Endpunkt aufweist, der bereits in der Factory vorhanden ist. Wenn eine Eigenschaft in den Umgebungen unterschiedlich ist, können Sie diese überschreiben, indem Sie die Eigenschaft parametrisieren und den entsprechenden Wert während der Bereitstellung angeben.
Key Vault. Wenn Sie verknüpfte Dienste verwenden, deren Verbindungsinformationen in Azure Key Vault gespeichert sind, wird empfohlen, separate Schlüsseltresore für verschiedene Umgebungen beizubehalten. Sie können auch separate Berechtigungsstufen für jeden Schlüsseltresor konfigurieren. Es kann beispielsweise sein, dass Teammitglieder nicht über Berechtigungen für Produktionsgeheimnisse verfügen sollen. Bei diesem Ansatz empfehlen wir Ihnen, in allen Stufen die gleichen Geheimnisnamen beizubehalten. Wenn Sie die gleichen Geheimnisnamen beibehalten, müssen Sie nicht jede einzelne Verbindungszeichenfolge für alle CI/CD-Umgebungen parametrisieren, weil sich lediglich der Name des Schlüsseltresors ändert, und der ist ein separater Parameter.
Benennung von Ressourcen. Aufgrund der ARM-Vorlagenbeschränkungen kann es zu Problemen bei der Bereitstellung kommen, wenn Ihre Ressourcen Leerzeichen im Namen enthalten. Daher empfiehlt das Azure Data Factory-Team bei Ressourcennamen die Verwendung der Zeichen „_“ bzw. „-“ anstelle von Leerzeichen. Verwenden Sie beispielsweise „Pipeline_1“ anstelle von „Pipeline 1“.
Ändern des Repositorys. ADF verwaltet GIT-Repositoryinhalte automatisch. Das manuelle Ändern oder Hinzufügen nicht verwandter Dateien oder Ordner an einer beliebigen Stelle im ADF-Git-Repositorydatenordner kann zu Fehlern beim Laden von Ressourcen führen. Beispielsweise kann das Vorhandensein von BAK-Dateien zu einem ADF-CI/CD-Fehler führen. Daher sollten sie entfernt werden, damit ADF geladen werden kann.
Belichtungskontrolle und Feature-Flags. Bei der Arbeit in einem Team kann es vorkommen, dass Sie Änderungen zusammenführen, aber nicht wollen, dass sie in erhöhten Umgebungen wie PROD und QA ausgeführt werden. Für dieses Szenario empfiehlt das ADF-Team das DevOps-Konzept der Verwendung von Featureflags. In ADF können Sie globale Parameter und die Aktivität „IfCondition“ kombinieren, um Logiksätze auf der Grundlage dieser Umgebungsflags auszublenden.
Informationen zum Einrichten eines Featureflags finden Sie im folgenden Videotutorial:
Nicht unterstützte Funktionen
Standardmäßig ist für Data Factory ein Cherrypicking von Commits oder die selektive Veröffentlichung von Ressourcen nicht zulässig. Veröffentlichungen umfassen alle in der Data Factory vorgenommenen Änderungen.
- Data Factory-Entitäten sind voneinander abhängig. Beispielsweise hängen Trigger von Pipelines ab, während Pipelines von Datasets und anderen Pipelines abhängig sind. Die selektive Veröffentlichung einer Teilmenge von Ressourcen kann ggf. zu unerwartetem Verhalten und Fehlern führen.
- In den seltenen Fällen, in denen Sie eine selektive Veröffentlichung durchführen müssen, können Sie die Verwendung eines Hotfix erwägen. Weitere Informationen finden Sie unter Hotfix für Produktionsumgebung.
Das Azure Data Factory-Team rät davon ab, Azure RBAC-Steuerelemente einzelnen Entitäten (Pipelines, Datasets usw.) in einer Data Factory zuzuweisen. Wenn ein Entwickler beispielsweise Zugriff auf eine Pipeline oder ein Dataset hat, sollte er in der Lage sein, auf alle Pipelines oder Datasets in der Data Factory zuzugreifen. Wenn Sie der Ansicht sind, dass Sie viele Azure-Rollen innerhalb einer Data Factory implementieren müssen, ziehen Sie die Bereitstellung einer zweiten Data Factory in Betracht.
Sie können nicht aus privaten Branches veröffentlichen.
Es ist derzeit nicht möglich, Projekte in Bitbucket zu hosten.
Es ist derzeit nicht möglich, Alarme und Matrizen als Parameter zu exportieren und zu importieren.
Partielle ARM-Vorlagen in Ihrem Veröffentlichungsbranch werden seit dem 1. November 2021 nicht mehr unterstützt. Wenn dieses Feature in Ihrem Projekt verwendet wurde, wechseln Sie zu einem unterstützten Mechanismus für Bereitstellungen mit den Dateien
ARMTemplateForFactory.jsonoderlinkedTemplates.
Zugehöriger Inhalt
- Verbesserungen bei Continuous Deployment
- Automatisieren von Continuous Integration mit Azure Pipelines-Releases
- Manuelles Höherstufen einer Resource Manager-Vorlage für jede Umgebung
- Verwenden benutzerdefinierter Parameter mit einer Resource Manager-Vorlage
- Verknüpfte Resource Manager-Vorlagen
- Verwenden einer Hotfix-Produktionsumgebung
- Beispielskript für vor und nach der Bereitstellung