Iteratives Entwickeln und Debuggen mit Azure Data Factory- und Synapse Analytics-Pipelines
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Azure Data Factory und Synapse Analytics unterstützen das iterative Entwickeln und Debuggen von Pipelines. Diese Features ermöglichen Ihnen, Ihre Änderungen zu testen, bevor Sie einen Pull Request erstellen oder sie im Dienst veröffentlichen.
Das folgende Video enthält eine achtminütige Einführung und Demonstration dieses Features:
Debuggen einer Pipeline
Wenn Sie auf der Pipelinecanvas arbeiten, können Sie Ihre Aktivitäten mit der Funktion Debuggen testen. Beim Ausführen von Testläufen müssen Sie Ihre Änderungen nicht im Dienst veröffentlichen, bevor Sie Debuggen auswählen. Dieses Feature ist in Szenarien praktisch, in denen Sie sicherstellen möchten, dass die Änderungen wie erwartet funktionieren, bevor Sie den Workflow aktualisieren.
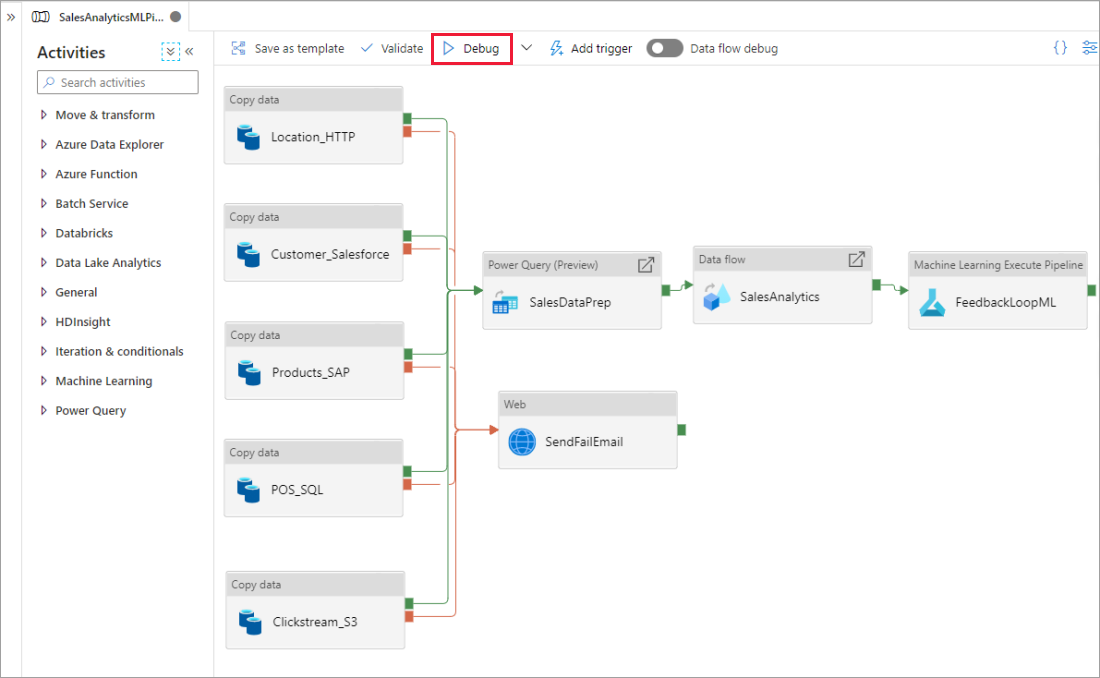
Während die Pipeline ausgeführt wird, können Sie die Ergebnisse der einzelnen Aktivitäten auf der Registerkarte Ausgabe der Pipelinecanvas sehen.
Zeigen Sie die Ergebnisse der Testläufe auf der Pipelinecanvas im Fenster Ausgabe an.

Fügen Sie nach der erfolgreichen Ausführung eines Testlaufs weitere Aktivitäten zur Pipeline hinzu, und setzen Sie das iterative Debuggen fort. Sie können einen aktiven Testlauf auch über Abbrechen beenden.
Wichtig
Durch Auswählen von Debuggen wird die Pipeline ausgeführt. Wenn die Pipeline beispielsweise die Kopieraktivität enthält, werden beim Testlauf Daten aus der Quelle in das Ziel kopiert. Daher wird empfohlen, beim Debuggen Testordner in Ihrer copy-Aktivität und Ihren anderen Aktivitäten zu verwenden. Wechseln Sie nach dem Debuggen der Pipeline zu den Ordnern, die Sie tatsächlich in normalen Vorgängen verwenden möchten.
Setzen von Haltepunkten
Sie können mit dem Dienst eine Pipeline debuggen, bis Sie eine bestimmte Aktivität auf der Pipelinecanvas erreichen. Setzen Sie einen Haltepunkt für die Aktivität, bis zu dem der Test ausgeführt werden soll, und klicken Sie auf Debuggen. Der Dienst stellt sicher, dass die Testläufe nur bis zur Breakpointaktivität auf der Pipelinecanvas ausgeführt werden. Dieses Feature namens Debug Until (Debuggen bis) ist nützlich, wenn Sie nicht die gesamte Pipeline, sondern nur eine Teilmenge der Aktivitäten in der Pipeline testen möchten.
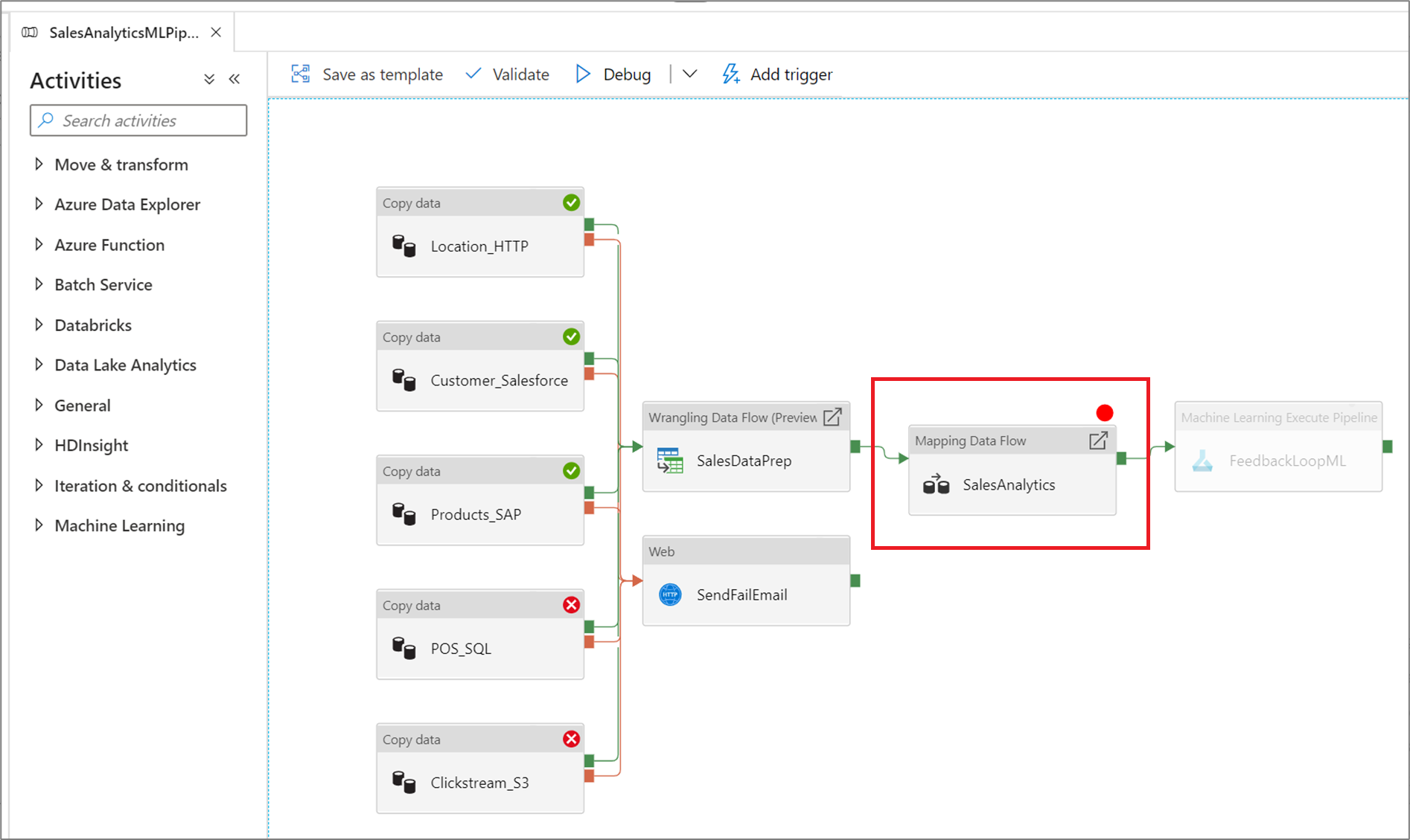
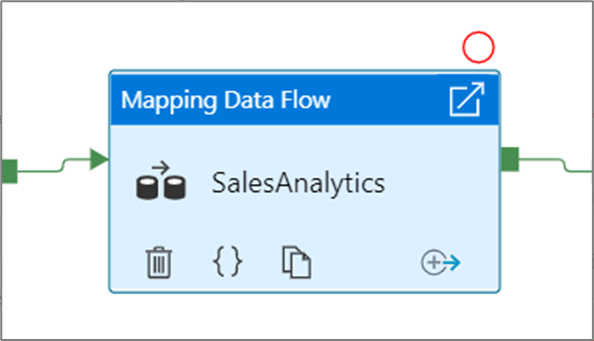
Um einen Haltepunkt festzulegen, wählen Sie ein Element auf der Pipelinecanvas aus. Eine Option Debug Until wird als ein leerer roter Kreis in der oberen rechten Ecke des Elements angezeigt.
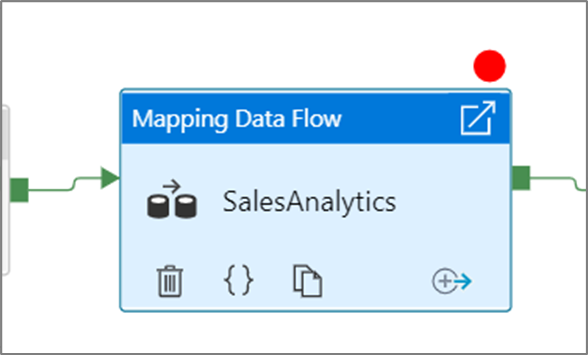
Nachdem Sie die Option Debug Until ausgewählt haben, ändert sich der leere Kreis in einen ausgefüllten roten Kreis, um anzugeben, dass der Breakpoint aktiviert ist.
Überwachen von Debugausführungen
Bei einer Debugausführung für eine Pipeline werden die Ergebnisse im Fenster Ausgabe der Pipelinecanvas gezeigt. Die Registerkarte „Ausgabe“ enthält nur die jüngste Ausführung, die während der aktuellen Browsersitzung erfolgt ist.
Um eine Verlaufsansicht von Debugausführungen oder eine Liste aller aktiven Debugausführungen anzuzeigen, können Sie zur Oberfläche Überwachung wechseln.
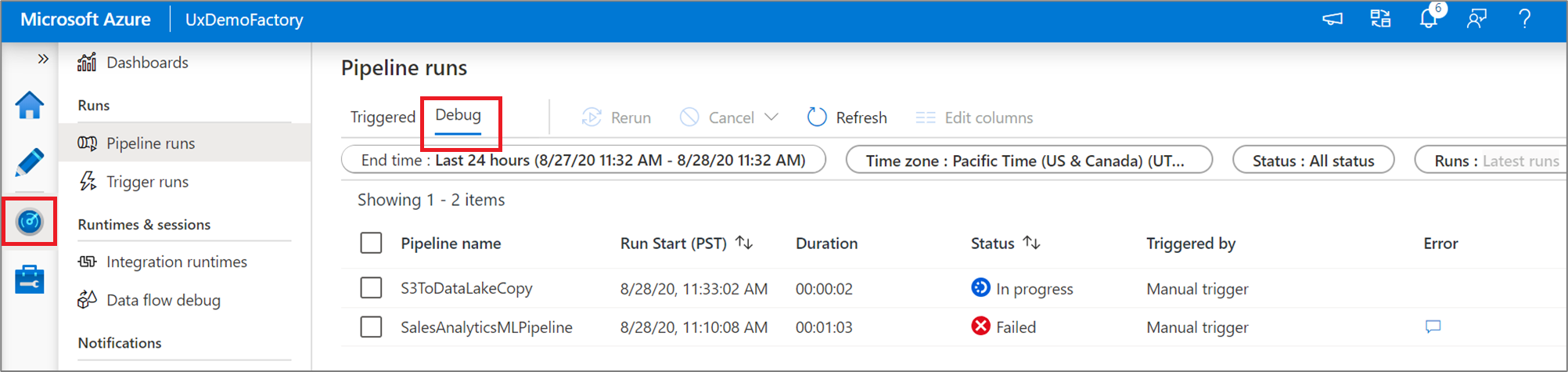
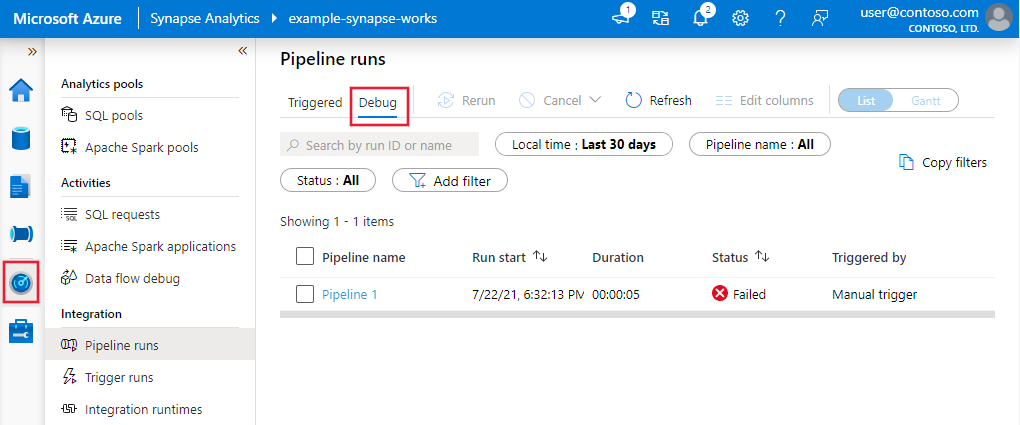
Hinweis
Der Dienst speichert den Verlauf von Debugausführungen nur 15 Tage lang.
Debuggen von Zuordnungsdatenflüssen
Zuordnungsdatenflüsse ermöglichen Ihnen, codefreie Datentransformationslogik zu erstellen, die sich nach Maß ausführen lässt. Wenn Sie Ihre Logik entwickeln, können Sie eine Debugsitzung aktivieren, um mit Ihren Daten in einem aktiven Spark-Cluster interaktiv zu arbeiten. Weitere Informationen finden Sie unter Debugmodus für den Zuordnungsdatenfluss.
Auf der Oberfläche Überwachung können Sie aktive Debugsitzungen für den Datenfluss überwachen.
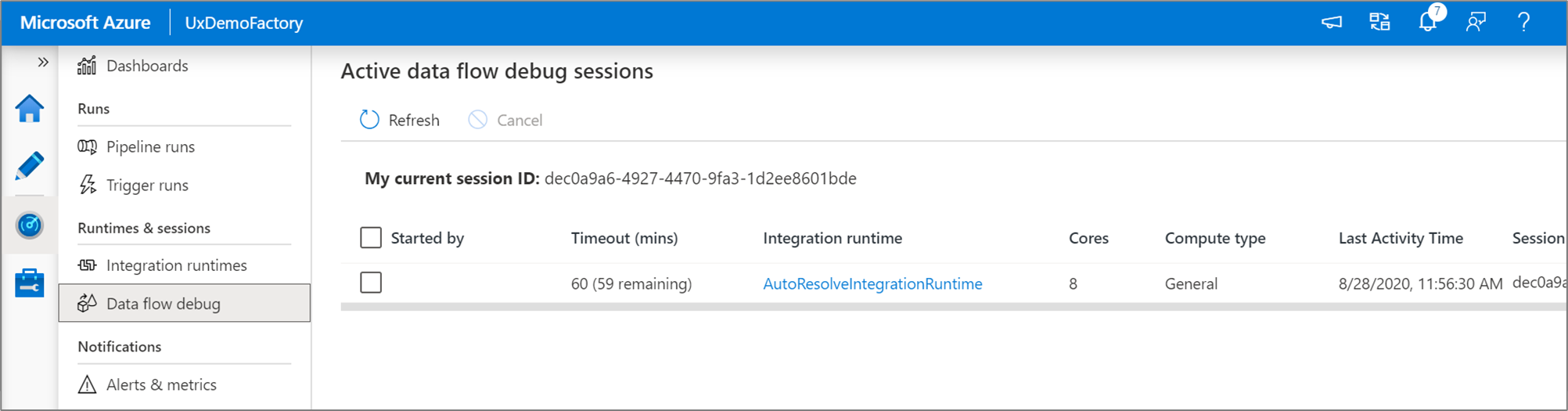
Die Datenvorschau im Datenflussdesigner und das Pipelinedebuggen von Datenflüssen sollten am besten mit kleinen Datenstichproben funktionieren. Wenn Sie jedoch Ihre Logik in einer Pipeline oder einem Datenfluss anhand großer Datenmengen testen müssen, setzen Sie die Größe der Azure Integration Runtime herauf, die in der Debugsitzung verwendet wird, d. h. erhöhen Sie die Zahl der Kerne und erweitern Sie das minimale Compute für allgemeine Zwecke.
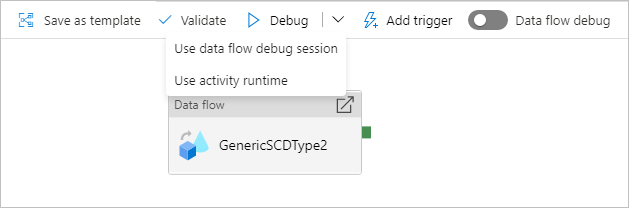
Debuggen einer Pipeline mit einer Datenflussaktivität
Bei der Ausführung einer Debugpipeline in einem Datenfluss haben Sie für Compute die Wahl zwischen zwei Optionen. Sie können entweder einen vorhandenen Debugcluster verwenden oder einen neuen Just-in-Time-Cluster für Ihre Datenflüsse einrichten.
Bei Verwendung einer vorhandenen Debugsitzung wird die Uptime des Datenflusses erheblich verkürzt, da der Cluster bereits läuft. Dies wird jedoch bei komplexen oder parallelen Workloads nicht empfohlen, da bei gleichzeitiger Ausführung mehrerer Aufträge Fehler auftreten können.
Bei Verwenden der Aktivitätslaufzeit wird ein neuer Cluster mit den Einstellungen erstellt, die in der Integration Runtime jeder Datenflussaktivität angegeben sind. Dies ermöglicht die Isolierung jedes einzelnen Auftrags und sollte für komplexe Workloads oder Leistungstests verwendet werden. Außerdem können Sie die Gültigkeitsdauer (TTL) in der Azure IR steuern, damit die für das Debuggen verwendeten Clusterressourcen während dieses Zeitraums weiterhin für zusätzliche Auftragsanforderungen verfügbar sind.
Hinweis
Wenn Sie über eine Pipeline mit Datenflüssen verfügen, die parallel ausgeführt werden, oder mit Datenflüssen, die mit großen Datasets getestet werden müssen, wählen Sie „Use Activity Runtime“ (Aktivitätsruntime verwenden) aus, damit der Dienst die in der Datenflussaktivität ausgewählte Integration Runtime verwenden kann. Dies ermöglicht das Ausführen der Datenflüsse in mehreren Clustern und die Verarbeitung der parallelen Datenflussausführungen.
Zugehöriger Inhalt
Nachdem Sie Ihre Änderungen getestet haben, stufen Sie sie mithilfe von Continuous Integration und Deployment in höhere Umgebungen hoch.