Kopieren von Daten und Senden von E-Mail-Benachrichtigungen bei Erfolg und Fehler
GILT FÜR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Tutorial erstellen Sie eine Data Factory-Pipeline, die einige Ablaufsteuerungsfunktionen vorstellt. Diese Pipeline führt eine einfache Kopieraktivität aus einem Container in Azure Blob Storage in einen anderen Container im selben Speicherkonto durch. War die Kopieraktivität erfolgreich, sendet die Pipeline eine E-Mail mit Details zum erfolgreichen Kopiervorgang (beispielsweise die geschriebene Datenmenge). War die Kopieraktivität nicht erfolgreich, sendet die Pipeline eine E-Mail mit Fehlerdetails (beispielsweise die Fehlermeldung). In diesem Tutorial erfahren Sie, wie Sie Parameter übergeben.
Eine allgemeine Übersicht über das Szenario: 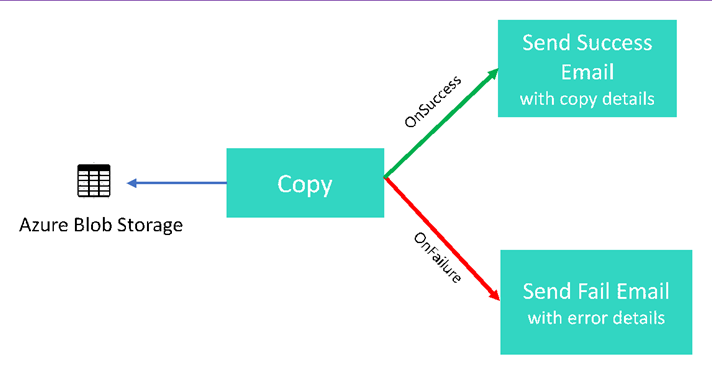
In diesem Tutorial führen Sie die folgenden Schritte aus:
- Erstellen einer Data Factory.
- Erstellen eines verknüpften Azure Storage Diensts.
- Erstellen eines Azure-Blobdatasets.
- Erstellen einer Pipeline, die eine Kopieraktivität und eine Webaktivität enthält.
- Senden von Aktivitätsausgaben an nachfolgende Aktivitäten.
- Verwenden von Parameterübergabe und Systemvariablen.
- Starten einer Pipelineausführung.
- Überwachen der Pipeline- und Aktivitätsausführungen.
In diesem Tutorial wird das Azure-Portal verwendet. Andere Mechanismen zur Interaktion mit Azure Data Factory, finden Sie unter "Schnellstart" im Inhaltsverzeichnis.
Voraussetzungen
- Azure-Abonnement. Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Azure Storage-Konto. Sie verwenden den Blob Storage als Quelldatenspeicher. Wenn Sie kein Azure Storage-Konto besitzen, finden Sie im Artikel Erstellen eines Speicherkontos Schritte zum Erstellen eines solchen Kontos.
- Azure SQL-Datenbank. Sie verwenden die Datenbank als Senkendatenspeicher. Wenn Sie in Azure SQL-Datenbank noch keine Datenbank haben, lesen Sie den Artikel Erstellen einer Datenbank in Azure SQL-Datenbank. Dort finden Sie die erforderlichen Schritte zum Erstellen einer solchen Datenbank.
Erstellen Sie eine Blob-Tabelle
Starten Sie den Editor. Kopieren Sie den folgenden Text, und speichern Sie ihn als input.txt-Datei auf Ihrem Datenträger.
John,Doe Jane,DoeFühren Sie mit einem Tool wie Azure Storage-Explorer die folgenden Schritte aus:
- Erstellen Sie den Container adfv2branch.
- Erstellen Sie im Container adfv2branch den Ordner input.
- Laden Sie die Datei input.txt in den Container hoch.
Erstellen von E-Mail-Workflow-Endpunkten
Um das Senden einer E-Mail aus der Pipeline auszulösen, verwenden Sie Azure Logic Apps, um den Workflow zu definieren. Weitere Informationen zum Erstellen eines Logik-App-Workflows finden Sie unter Erstellen eines Beispiels eines Verbrauchs-Logik-App-Workflows.
Erfolgs-E-Mail-Workflow
Erstellen eines Verbrauchs-Logik-App-Workflows mit Namen CopySuccessEmail. Fügen Sie den Anforderungstrigger mit dem Namen Wenn eine HTTP-Anforderung empfangen wird hinzu, und fügen Sie die Office 365 Outlook-Aktion E-Mail senden hinzu. Melden Sie sich bei Ihrem Office 365 Outlook-Konto an, wenn Sie dazu aufgefordert werden.

Füllen Sie für den Anforderungstrigger das Feld JSON-Schema für Anforderungstext mit dem folgenden JSON-Code aus:
{
"properties": {
"dataFactoryName": {
"type": "string"
},
"message": {
"type": "string"
},
"pipelineName": {
"type": "string"
},
"receiver": {
"type": "string"
}
},
"type": "object"
}
Der Anforderungstrigger im Workflow-Designer sollte wie das folgende Bild aussehen:
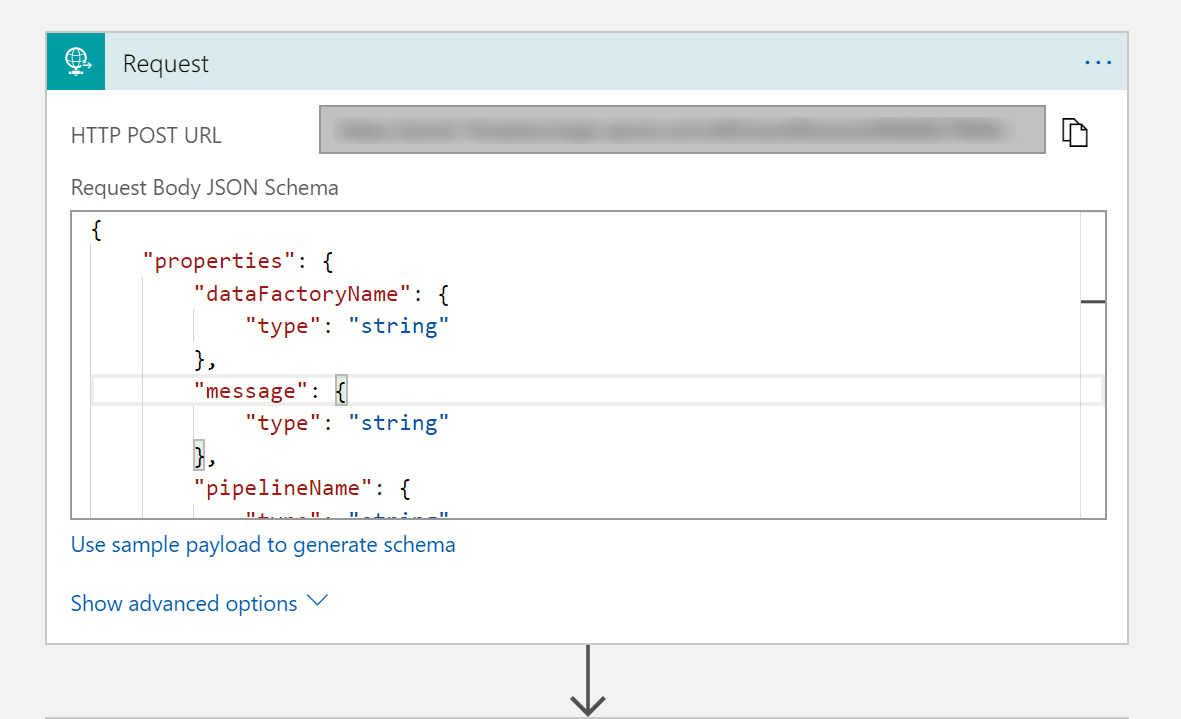
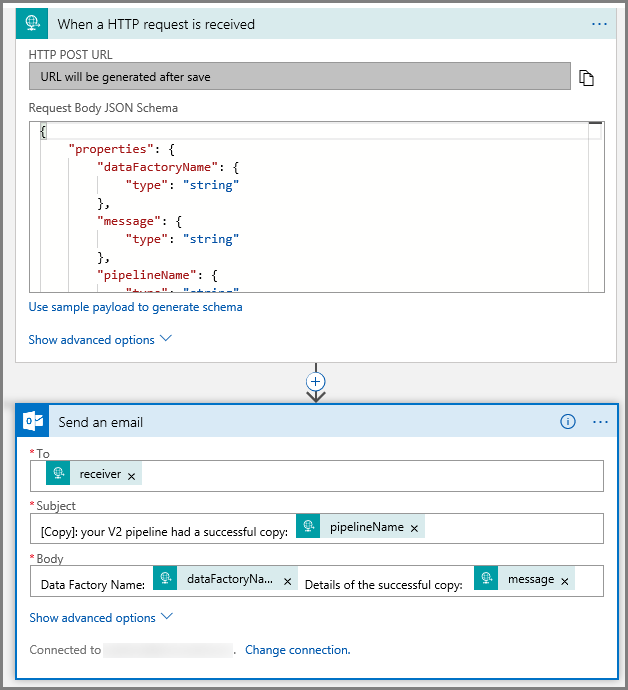
Für die Aktion E-Mail senden passen Sie an, wie Sie die E-Mail formatieren möchten, indem Sie die Eigenschaften nutzen, die im Anforderungstext des JSON-Schemas übergeben wurden. Beispiel:
Speichern Sie den Workflow. Notieren Sie sich die HTTP-Post-Anforderungs-URL für Ihren Erfolgs-E-Mail-Workflow:
//Success Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Fehler-E-Mail-Workflow
Erstellen Sie mit den gleichen Schritten einen weiteren Logik-App-Workflow mit Namen CopyFailEmail. Im Anforderungstrigger ist der Anforderungstext des JSON-Schema der gleiche. Ändern Sie das Format Ihrer E-Mail (beispielsweise Subject), um eine E-Mail für einen nicht erfolgreichen Vorgang zu erhalten. Beispiel:

Speichern Sie den Workflow. Notieren Sie sich die HTTP-Post-Anforderungs-URL für Ihren Fehler-E-Mail-Workflow:
//Fail Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Sie sollten nun über zwei Workflow-URLs verfügen:
//Success Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
//Fail Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Erstellen einer Data Factory
Starten Sie den Webbrowser Microsoft Edge oder Google Chrome. Die Data Factory-Benutzeroberfläche wird zurzeit nur in den Webbrowsern Microsoft Edge und Google Chrome unterstützt.
Erweitern Sie das Menü oben links, und wählen Sie Ressource erstellen aus. Wählen Sie dann >Integration>Data Factory aus:

Geben Sie auf der Seite Neue Data Factory unter Name den Namen ADFTutorialDataFactory ein.
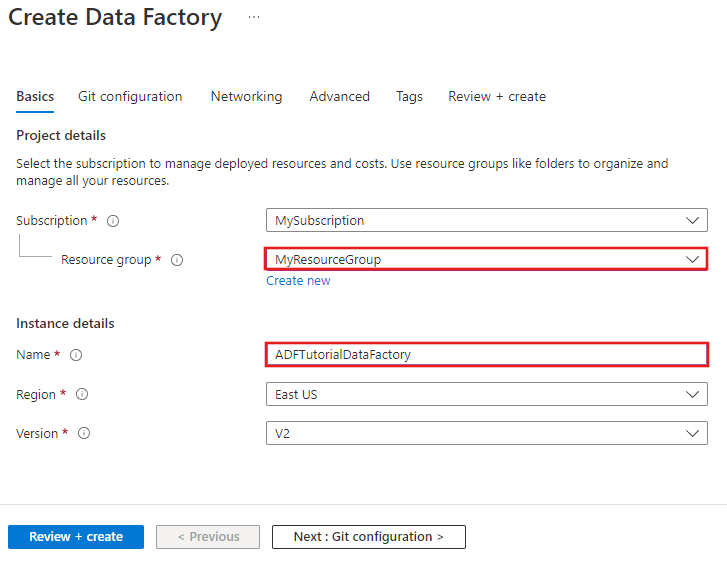
Der Name der Azure Data Factory muss global eindeutigsein. Sollte der folgende Fehler auftreten, ändern Sie den Namen der Data Factory (beispielsweise in „
ADFTutorialDataFactory“), und wiederholen Sie den Vorgang. Benennungsregeln für Data Factory-Artefakte finden Sie im Artikel Azure Data Factory – Benennungsregeln. Der Data Factory-Name „ADFTutorialDataFactory“ ist nicht verfügbar.
Wählen Sie Ihr Azure-Abonnement aus, in dem die Data Factory erstellt werden soll.
Führen Sie für die Ressourcengruppe einen der folgenden Schritte aus:
Wählen Sie die Option Use existing(Vorhandene verwenden) und dann in der Dropdownliste eine vorhandene Ressourcengruppe.
Wählen Sie Neu erstellen, und geben Sie den Namen einer Ressourcengruppe ein.
Weitere Informationen über Ressourcengruppen finden Sie unter Verwenden von Ressourcengruppen zum Verwalten von Azure-Ressourcen.
Wählen Sie V2 als Version aus.
Wählen Sie den Standort für die Data Factory aus. In der Dropdownliste werden nur unterstützte Standorte angezeigt. Die von der Data Factory verwendeten Datenspeicher (Azure Storage, Azure SQL-Datenbank usw.) und Computedienste (HDInsight usw.) können sich in anderen Regionen befinden.
Wählen Sie die Option An Dashboard anheften aus.
Klicken Sie auf Erstellen.
Nach Abschluss der Erstellung wird die Seite Data Factory wie in der Abbildung angezeigt.

Klicken Sie auf die Kachel Azure Data Factory Studio öffnen, um die Data Factory-Benutzeroberfläche auf einer separaten Registerkarte zu starten.
Erstellen einer Pipeline
In diesem Schritt erstellen Sie eine Pipeline mit einer Kopieraktivität und zwei Webaktivitäten. Zum Erstellen der Pipeline verwenden Sie folgende Features:
- Parameter für die Pipeline, auf die durch Datasets zugegriffen wird.
- Webaktivität zum Aufrufen von Logic Apps-Workflows für den Versand von Erfolgs-/Misserfolgs-E-Mails.
- Herstellen einer Verbindung zwischen Aktivitäten (bei Erfolg und Fehler)
- Verwenden der Ausgabe aus einer Aktivität als eine Eingabe für die nachfolgende Aktivität.
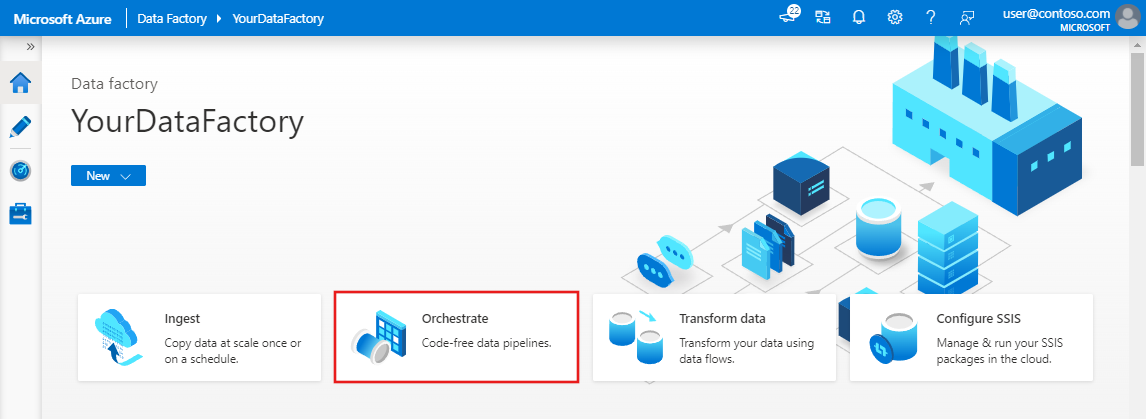
Klicken Sie auf der Startseite der Data Factory Benutzeroberfläche auf die Kachel Orchestrieren.
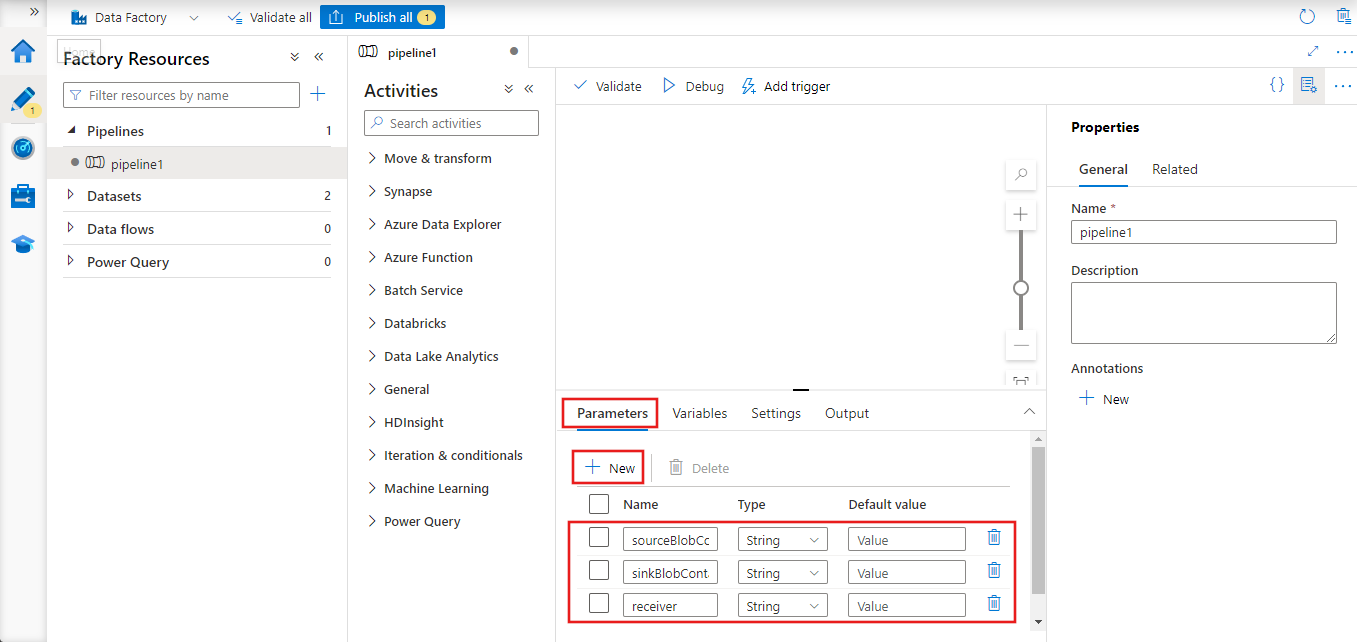
Wechseln Sie im Eigenschaftenfenster für die Pipeline zur Registerkarte Parameter, und fügen Sie mithilfe der Schaltfläche Neu die drei folgenden Zeichenfolgenparameter hinzu: „sourceBlobContainer“, „sinkBlobContainer“ und „receiver“.
- sourceBlobContainer: Parameter in der Pipeline, der vom Quell-Blobdataset verarbeitet wird.
- sinkBlobContainer – Parameter in der Pipeline, der vom Senken-Blobdataset verarbeitet wird.
- receiver – Dieser Parameter wird von den beiden Webaktivitäten in der Pipeline verwendet, die Erfolgs- oder Fehlermeldungen an den Empfänger senden, dessen E-Mail-Adresse durch diesen Parameter angegeben wird.
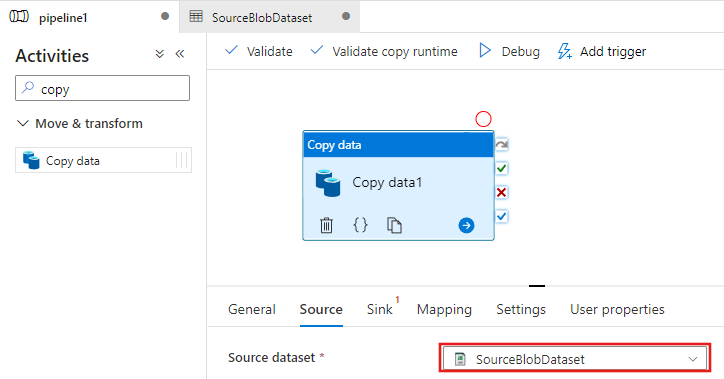
Suchen Sie in der Toolbox Aktivitäten nach Kopieren, und ziehen Sie die Aktivität Kopieren auf die Oberfläche des Pipeline-Designers.

Wählen Sie die Aktivität Kopieren aus, die Sie auf die Oberfläche des Pipeline-Designers gezogen haben. Wechseln Sie im unteren Bereich des Fensters Eigenschaften für die Aktivität Kopieren zur Registerkarte Quelle, und klicken Sie auf + Neu. In diesem Schritt erstellen Sie ein Quelldataset für die Kopieraktivität.

Klicken Sie oben im Fenster Neues Dataset auf die Registerkarte Azure, wählen Sie dann Azure Blob Storage aus, und klicken Sie dann auf Fortfahren.

Wählen Sie im Fenster Format auswählen die Option DelimitedText aus, und klicken Sie auf Fortfahren.

Daraufhin wird eine neue Registerkarte mit dem Titel Eigenschaften festlegen angezeigt. Ändern Sie den Namen des Datasets in SourceBlobDataset. Wählen Sie das Dropdownmenü Verknüpfter Dienst aus, und klicken Sie auf +Neu, um einen neuen verknüpften Dienst für Ihr Quelldataset zu erstellen.

Das Fenster Neuer verknüpfter Dienst wird angezeigt, in dem Sie die erforderlichen Eigenschaften für den verknüpften Dienst ausfüllen können.

Führen Sie im Fenster New Linked Service (Neuer verknüpfter Dienst) die folgenden Schritte aus:
- Geben Sie unter Name die Zeichenfolge AzureStorageLinkedService ein.
- Wählen Sie unter Speicherkontoname Ihr Azure-Speicherkonto aus.
- Klicken Sie auf Erstellen.
Wählen Sie im Fenster Eigenschaften festlegen, das als Nächstes angezeigt wird, die Option Dieses Dataset öffnen, um einen parameterisierten Wert für den Dateinamen einzugeben.

Geben Sie
@pipeline().parameters.sourceBlobContainerfür den Ordner undemp.txtfür den Dateinamen ein.
Wechseln Sie zurück zur Registerkarte Pipeline (oder klicken Sie auf die Pipeline in der Strukturansicht links), und wählen Sie die Aktivität Kopieren im Designer aus. Vergewissern Sie sich, dass für das neue Dataset die Option Quelldataset ausgewählt ist.
Wechseln Sie im Eigenschaftenfenster zur Registerkarte Senke, und klicken Sie für Sink Dataset (Senkendataset) auf + Neu. In diesem Schritt erstellen Sie ein Senkendataset für die Kopieraktivität. Die Vorgehensweise ähnelt dabei der Erstellung des Quelldatasets.

Wählen Sie im Fenster Neues DatasetAzure Blob Storage aus, und klicken Sie dann auf Fortsetzen. Wählen Sie dann DelimitedText im Fenster Format auswählen noch mal aus, und klicken Sie noch mal auf Fortfahren.
Geben Sie auf der Seite Eigenschaften festlegen für das Dataset SinkBlobDataset unter Name ein, und wählen Sie AzureStorageLinkedService für LinkedService aus.
Erweitern Sie den Abschnitt „Erweitert“ der Eigenschaftenseite, und wählen Sie Dieses Dataset öffnen aus.
Bearbeiten Sie auf der Registerkarte Datasetverbindung den Dateipfad. Geben Sie
@pipeline().parameters.sinkBlobContainerfür den Ordner und@concat(pipeline().RunId, '.txt')für den Dateinamen ein. Durch den Ausdruck wird die ID der aktuellen Pipelineausführung als Dateiname verwendet. Eine Liste der unterstützten Systemvariablen und Ausdrücke finden Sie unter Von Azure Data Factory unterstützte Systemvariablen sowie unter Ausdrücke und Funktionen in Azure Data Factory.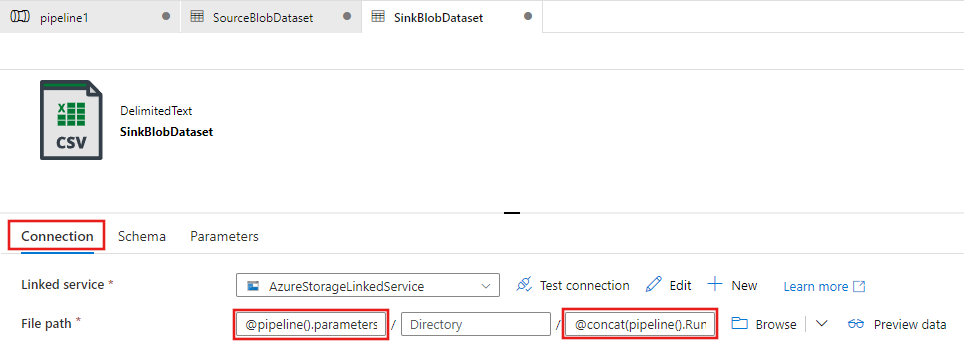
Wechseln Sie im oberen Bereich wieder zur Registerkarte Pipeline. Suchen Sie im Suchfeld nach Web, und ziehen Sie eine Webaktivität auf die Pipeline-Designeroberfläche. Legen Sie den Namen der Aktivität auf SendSuccessEmailActivity fest. Die Webaktivität ermöglicht einen Aufruf an jeden beliebigen REST-Endpunkt. Weitere Informationen zur Aktivität finden Sie unter Web Activity (Webaktivität). Diese Pipeline verwendet eine Webaktivität, um den Logik-Apps-E-Mail-Workflow aufzurufen.
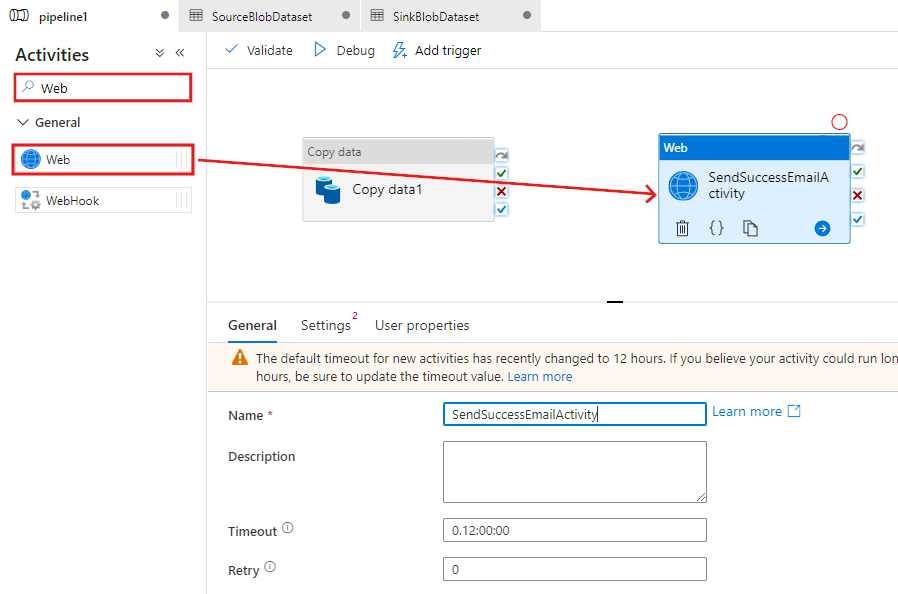
Wechseln Sie von der Registerkarte Allgemein zur Registerkarte Einstellungen, und führen Sie die folgenden Schritte aus:
Geben Sie unter URL die URL für den Logic Apps-Workflow an, der die Erfolgs-E-Mail sendet.
Wählen Sie unter Methode die Option POST aus.
Klicken Sie im Abschnitt Header auf den Link + Header hinzufügen.
Fügen Sie einen Header namens Content-Type hinzu, und legen Sie ihn auf application/json fest.
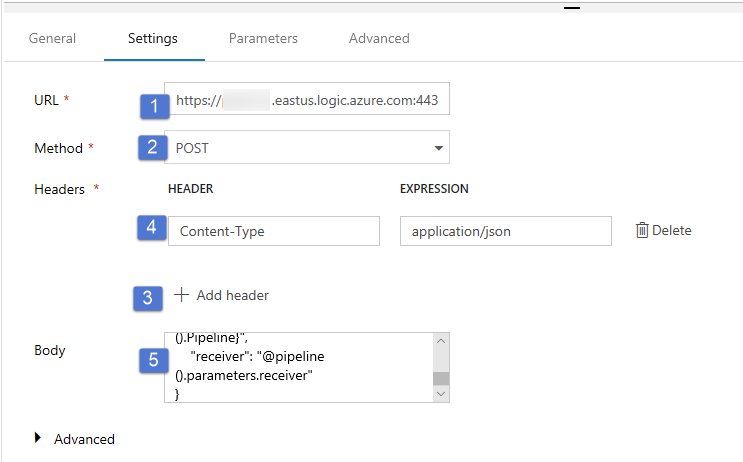
Geben Sie unter Text den folgenden JSON-Code an:
{ "message": "@{activity('Copy1').output.dataWritten}", "dataFactoryName": "@{pipeline().DataFactory}", "pipelineName": "@{pipeline().Pipeline}", "receiver": "@pipeline().parameters.receiver" }Die Nachrichtentext enthält folgende Eigenschaften:
Nachricht – Übergibt den Wert von
@{activity('Copy1').output.dataWritten. Greift auf eine Eigenschaft der vorherigen Kopieraktivität zurück, und übergibt den Wert von DataWritten. Für den Fehlerfall, übergeben Sie die Fehlerausgabe anstelle von@{activity('CopyBlobtoBlob').error.message.Data Factory-Name – Übergibt den Wert von
@{pipeline().DataFactory}. Dies ist eine Systemvariable, die Ihnen den Zugriff auf den Namen der entsprechenden Data Factory ermöglicht. Eine Liste der Systemvariablen finden Sie im Artikel SystemvariablenPipeline-Name – Übergibt den Wert von
@{pipeline().Pipeline}. Dies ist auch eine Systemvariable, die Ihnen den Zugriff auf den entsprechenden Pipelinenamen ermöglicht.Empfänger – Übergibt den Wert von „@pipeline().parameters.receiver“). Zugriff auf die Pipeline-Parameter
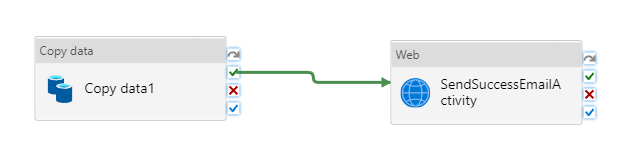
Stellen Sie eine Verbindung zwischen der Aktivität Kopieren und der Aktivität Web her, indem Sie das grüne Kontrollkästchen neben der Kopieraktivität auf die Webaktivität ziehen.
Ziehen Sie eine weitere Aktivität vom Typ Web aus der Toolbox Aktivitäten auf die Oberfläche des Pipeline-Designers, und legen Sie den Namen auf SendFailureEmailActivity fest.
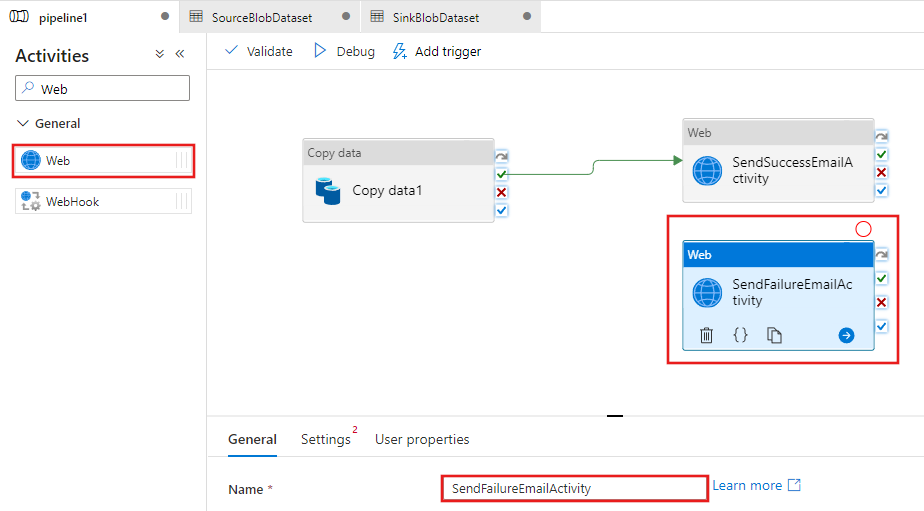
Wechseln Sie zur Registerkarte Einstellungen, und führen Sie die folgenden Schritte aus:
Geben Sie unter URL die URL für den Logic Apps-Workflow an, der die Fehler-E-Mail sendet.
Wählen Sie unter Methode die Option POST aus.
Klicken Sie im Abschnitt Header auf den Link + Header hinzufügen.
Fügen Sie einen Header namens Content-Type hinzu, und legen Sie ihn auf application/json fest.
Geben Sie unter Text den folgenden JSON-Code an:
{ "message": "@{activity('Copy1').error.message}", "dataFactoryName": "@{pipeline().DataFactory}", "pipelineName": "@{pipeline().Pipeline}", "receiver": "@pipeline().parameters.receiver" }
Klicken Sie auf der rechten Seite der Aktivität Kopieren im Pipeline-Designer auf die rote Schaltfläche X, und verschieben Sie sie per Drag and Drop auf die gerade erstellte Webaktivität SendFailureEmailActivity.

Klicken Sie zum Überprüfen der Pipeline auf der Symbolleiste auf die Schaltfläche Überprüfen. Schließen Sie das Fenster mit der Ausgabe der Pipelinevalidierung, indem Sie auf die Schaltfläche >> klicken.

Wählen Sie zum Veröffentlichen der Entitäten (Datasets, Pipelines usw.) im Data Factory-Dienst die Option Alle veröffentlichen. Warten Sie, bis die Meldung Erfolgreich veröffentlicht angezeigt wird.

Auslösen einer erfolgreichen Pipelineausführung
Um Trigger eine Pipeline ausgeführt wird, klicken Sie auf Trigger auf der Symbolleiste, und klicken Sie auf Trigger jetzt.

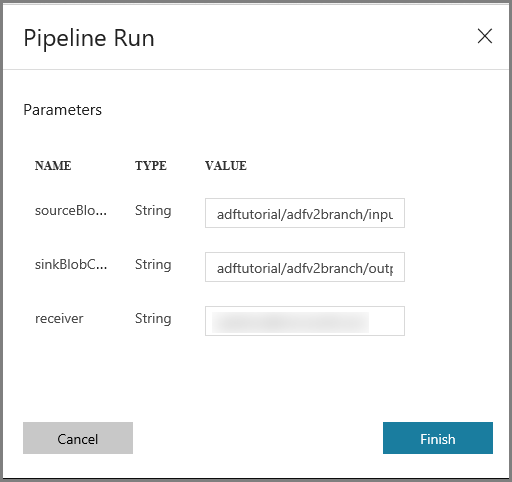
Führen Sie im Fenster Pipeline Run (Pipelineausführung) die folgenden Schritte aus:
Geben Sie für den Parameter sourceBlobContainer die Zeichenfolge adftutorial/adfv2branch/input ein.
Geben Sie für den Parameter sinkBlobContainer die Zeichenfolge adftutorial/adfv2branch/output ein.
Geben Sie eine e-Mail-Adresse von der Empfänger.
Klicken Sie auf Fertig stellen.
Überwachen der erfolgreichen Pipelineausführung
Wechseln Sie zum Überwachen der Pipelineausführung im linken Bereich zur Registerkarte Überwachen. Sie sehen die Pipelineausführung, die Sie manuell ausgelöst haben. Aktualisieren Sie die Liste mithilfe der Schaltfläche Aktualisieren.

Klicken Sie zum Anzeigen vonAktivitätsausführungen, die mit dieser Pipelineausführung verknüpft sind, in der Spalte Aktionen auf den ersten Link. Sie können zur vorherigen Ansicht zurückkehren, indem Sie oben auf Pipelines klicken. Aktualisieren Sie die Liste mithilfe der Schaltfläche Aktualisieren.

Auslösen einer nicht erfolgreichen Pipelineausführung
Wechseln Sie im linken Bereich zur Registerkarte Bearbeiten.
Um Trigger eine Pipeline ausgeführt wird, klicken Sie auf Trigger auf der Symbolleiste, und klicken Sie auf Trigger jetzt.
Führen Sie im Fenster Pipeline Run (Pipelineausführung) die folgenden Schritte aus:
- Geben Sie für den Parameter sourceBlobContainer die Zeichenfolge adftutorial/dummy/input ein. Stellen Sie sicher, dass der Ordner „dummy“ im Container „adftutorial“ nicht vorhanden ist.
- Geben Sie für den Parameter sinkBlobContainer die Zeichenfolge adftutorial/dummy/output ein.
- Geben Sie eine e-Mail-Adresse von der Empfänger.
- Klicken Sie auf Fertig stellen.
Überwachen der nicht erfolgreichen Pipelineausführung
Wechseln Sie zum Überwachen der Pipelineausführung im linken Bereich zur Registerkarte Überwachen. Sie sehen die Pipelineausführung, die Sie manuell ausgelöst haben. Aktualisieren Sie die Liste mithilfe der Schaltfläche Aktualisieren.

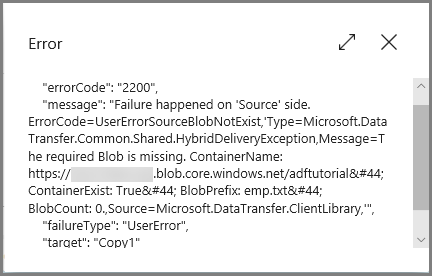
Klicken Sie für die Pipelineausführung auf den Link Fehler, um Fehlerdetails anzuzeigen.

Klicken Sie zum Anzeigen vonAktivitätsausführungen, die mit dieser Pipelineausführung verknüpft sind, in der Spalte Aktionen auf den ersten Link. Aktualisieren Sie die Liste mithilfe der Schaltfläche Aktualisieren. Beachten Sie, dass die Kopieraktivität in der Pipeline nicht erfolgreich war. Die Webaktivität hat erfolgreich eine Fehler-E-Mail an den angegebenen Empfänger gesendet.

Klicken Sie in der Spalte Aktionen auf den Link Fehler, um Fehlerdetails anzuzeigen.
Zugehöriger Inhalt
In diesem Tutorial haben Sie die folgenden Schritte ausgeführt:
- Erstellen einer Data Factory.
- Erstellen eines verknüpften Azure Storage Diensts.
- Erstellen eines Azure-Blobdatasets.
- Erstellen einer Pipeline, die eine Kopieraktivität und eine Webaktivität enthält.
- Senden von Aktivitätsausgaben an nachfolgende Aktivitäten.
- Verwenden von Parameterübergabe und Systemvariablen.
- Starten einer Pipelineausführung.
- Überwachen der Pipeline- und Aktivitätsausführungen.
Sie können jetzt mit dem Abschnitt „Konzepte“ fortfahren, um weitere Informationen zu Azure Data Factory zu erhalten.