make-series-Operator
Gilt für: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Erstellt eine Reihe angegebener aggregierter Werte entlang einer angegebenen Achse.
Syntax
T | make-series [MakeSeriesParameters] [Column =] Aggregation [default = DefaultValue] [, ...] on AxisColumn [from start] [to end] step step [by [Column =] GroupExpression [, ...]]
Erfahren Sie mehr über Syntaxkonventionen.
Parameter
| Name | Type | Erforderlich | BESCHREIBUNG |
|---|---|---|---|
| Spalte | string |
Der Name der Ergebnisspalte. Nimmt standardmäßig den vom Ausdruck abgeleiteten Namen an. | |
| DefaultValue | Skalar | Ein Standardwert, der anstelle fehlender Werte verwendet werden soll. Ist keine Zeile mit bestimmten AxisColumn- und GroupExpression-Werten vorhanden, wird dem entsprechenden Element des Arrays ein DefaultValue zugewiesen. Standard ist "0". | |
| Aggregation | string |
✔️ | Ein Aufruf einer Aggregationsfunktion, z. B. count() oder avg(), mit Spaltennamen als Argumenten. Weitere Informationen finden Sie in der Liste der Aggregationsfunktionen. Nur Aggregationsfunktionen, die numerische Ergebnisse zurückgeben, können mit dem make-series-Operator verwendet werden. |
| AxisColumn | string |
✔️ | Die Spalte, anhand derer die Reihe sortiert wird. Üblicherweise sind die Spaltenwerte vom Typ datetime oder timespan, aber es werden alle numerischen Typen akzeptiert. |
| start | Skalarwert | ✔️ | Der untere gebundene Wert von AxisColumn für jede der zu erstellenden Reihen. Wenn start nicht angegeben ist, ist dies das erste Intervall (step) jeder Reihe, das Daten enthält. |
| end | Skalarwert | ✔️ | Der obere gebundene, nicht inklusive Wert von AxisColumn. Der letzte Index der Zeitreihe ist kleiner als dieser Wert und ist gleich start plus einem ganzzahligen Vielfachen von step, das kleiner ist als end. Wenn end nicht angegeben ist, ist dies die Obergrenze des letzten Intervalls (step) jeder Reihe, das Daten enthält. |
| step | Skalarwert | ✔️ | Der Unterschied bzw. die Größe des Intervalls zwischen zwei aufeinander folgenden Elementen des AxisColumn-Arrays. Eine Liste der möglichen Zeitintervalle finden Sie unter timespan. |
| GroupExpression | Ein Ausdruck für die Spalten, der einen Satz von unterschiedlichen Werten bereitstellt. Hierbei handelt es sich in der Regel um einen Spaltennamen, der bereits einen eingeschränkten Satz von Werten bereitstellt. | ||
| MakeSeriesParameters | Null oder mehr durch Leerzeichen getrennte Parameter in Form von Name = Value , die das Verhalten steuern. Informationen finden Sie unter unterstützte make-series-Parameter. |
Hinweis
Die Parameter start, end und step werden zum Erstellen eines Arrays aus AxisColumn-Werten verwendet. Das Array besteht aus Werten zwischen start und end, wobei der Wert für step den Unterschied zwischen einem Arrayelement und dem nächsten darstellt. Alle Aggregation-Werte werden diesem Array entsprechend sortiert.
Unterstützte make-series-Parameter
| Name | BESCHREIBUNG |
|---|---|
kind |
Generiert ein Standardergebnis, wenn die Eingabe des make-series-Operators leer ist. Wert: nonempty |
hint.shufflekey=<key> |
Die shufflekey-Abfrage teilt die Abfragelast auf Clusterknoten auf, wobei ein Schlüssel zum Partitionieren der Daten verwendet wird. Weitere Informationen finden Sie unter Shuffleabfrage |
Hinweis
Die durch „make-series“ generierten Arrays sind auf 1.048.576 Werte (2^20) beschränkt. Der Versuch, ein größeres Array mit „make-series“ zu generieren, führt entweder zu einem Fehler oder zu einem abgeschnittenen Array.
Alternativer Syntax
T | make-series [Column =] Aggregation [default = DefaultValue] [, ...] on AxisColumn in range(start, stop, step) [by [Column =] GroupExpression [, ...]]
Die generierten Reihen aus der alternativen Syntax unterscheiden sich von der Hauptsyntax in zwei Aspekten:
- Der stop-Wert ist inklusiv.
- Die Quantisierung der Indexachse wird mit bin() und nicht mit bin_at() generiert, was bedeutet, dass start in der generierten Reihe möglicherweise nicht enthalten ist.
Es wird empfohlen, die Hauptsyntax von make-series zu verwenden, nicht die alternative Syntax.
Gibt zurück
Die Eingabezeilen werden in Gruppen angeordnet, die dieselben Werte wie die by -Ausdrücke und der bin_at(AxisColumn,step,start)-Ausdruck aufweisen. Anschließend werden die angegebenen Aggregationsfunktionen über jede Gruppe berechnet, dabei wird eine Zeile für jede Gruppe erzeugt. Das Ergebnis enthält die by -Spalten, die Spalte AxisColumn und auch mindestens eine Spalte für jedes berechnete Aggregat. (Aggregationen über mehrere Spalten oder mit nicht numerischen Ergebnissen werden nicht unterstützt.)
Dieses Zwischenergebnis weist so viele Zeilen auf, wie es unterschiedliche Kombinationen aus by und bin_at(AxisColumn,step,start)-Werten gibt.
Schließlich werden die Zeilen aus dem Zwischenergebnis in Gruppen angeordnet, die dieselben Werte wie die by-Ausdrücke aufweisen, und alle aggregierten Werte werden in Arrays (Werte vom dynamic-Typ) angeordnet. Für jede Aggregation gibt es eine Spalte, die das zugehörige Array mit dem entsprechenden Namen enthält. Die letzte Spalte ist ein Array, das die Werte von AxisColumn enthält, die gemäß dem angegebenen Schritt klassifiziert sind.
Hinweis
Auch wenn Sie beliebige Ausdrücke für die Aggregation und Gruppierung von Ausdrücken bereitstellen können, ist es effizienter, einfache Spaltennamen zu verwenden.
Liste der Aggregationsfunktionen
| Funktion | BESCHREIBUNG |
|---|---|
| avg() | Gibt einen Durchschnittswert für die Gruppe zurück. |
| avgif() | Gibt einen Durchschnitt mit dem Prädikat der Gruppe zurück. |
| count() | Gibt eine Anzahl der Gruppe zurück. |
| countif() | Gibt eine Anzahl mit dem Prädikat der Gruppe zurück. |
| dcount() | Gibt eine ungefähre eindeutige Anzahl der Gruppenelemente zurück. |
| dcountif() | Gibt eine ungefähre eindeutige Anzahl mit dem Prädikat der Gruppe zurück. |
| max() | Gibt den Höchstwert in der Gruppe zurück. |
| maxif() | Gibt den Maximalwert mit dem Prädikat der Gruppe zurück. |
| min() | Gibt den Mindestwert in der Gruppe zurück. |
| minif() | Gibt einen Minimalwert mit dem Prädikat der Gruppe zurück. |
| percentile() | Gibt den Perzentilwert für die Gruppe zurück. |
| take_any() | Gibt einen zufälligen, nicht leeren Wert für die Gruppe zurück. |
| stdev() | Gibt die Standardabweichung für die Gruppe zurück. |
| sum() | Gibt die Summe der Elemente in der Gruppe zurück. |
| sumif() | Gibt die Summe der Elemente mit dem Prädikat der Gruppe zurück. |
| variance() | Gibt die Varianz für die Gruppe zurück. |
Liste der Analysefunktionen für Zeitreihen
| Funktion | BESCHREIBUNG |
|---|---|
| series_fir() | Wendet einen FIR-Filter (Finite Impulse Response) an. |
| series_iir() | Wendet einen IIR-Filter (Infinite Impulse Response) an. |
| series_fit_line() | Ermittelt eine gerade Linie, die die beste Näherung der Eingabe darstellt. |
| series_fit_line_dynamic() | Ermittelt eine Linie, die die beste Näherung der Eingabe darstellt, und gibt ein dynamisches Objekt zurück. |
| series_fit_2lines() | Ermittelt zwei Linien, die die beste Näherung der Eingabe darstellen. |
| series_fit_2lines_dynamic() | Ermittelt zwei Linien, die die beste Näherung der Eingabe sind, und gibt ein dynamisches Objekt zurück. |
| series_outliers() | Bewertet Anomaliepunkte in einer Reihe. |
| series_periods_detect() | Ermittelt die wichtigsten Punkte, die in einer Zeitreihe vorhanden sind. |
| series_periods_validate() | Überprüft, ob eine Zeitreihe periodische Muster mit den angegebenen Längen enthält. |
| series_stats_dynamic() | Gibt mehrere Spalten mit den allgemeinen Statistiken zurück (min/max/variance/stdev/average). |
| series_stats() | Generiert einen dynamischen Wert mit den allgemeinen Statistiken (min/max/variance/stdev/average). |
Eine vollständige Liste der Analysefunktionen für Reihen finden Sie unter Funktionen für die Zeitreihenverarbeitung.
Liste der Reiheninterpolationsfunktionen
| Funktion | BESCHREIBUNG |
|---|---|
| series_fill_backward() | Führt eine Rückwärtsfüllinterpolation von fehlenden Werten in einer Reihe aus. |
| series_fill_const() | Ersetzt fehlende Werte in einer Reihe durch einen angegebenen konstanten Wert. |
| series_fill_forward() | Führt eine Vorwärtsfüllinterpolation von fehlenden Werten in einer Reihe aus. |
| series_fill_linear() | Führt eine lineare Interpolation von fehlenden Werten in einer Reihe aus. |
- Hinweis: Interpolationsfunktionen nehmen standardmäßig
nullals fehlenden Wert an. Geben Sie daherdefault=double(null) inmake-seriesan, wenn Sie beabsichtigen, Interpolationsfunktionen für die Reihe zu verwenden.
Beispiele
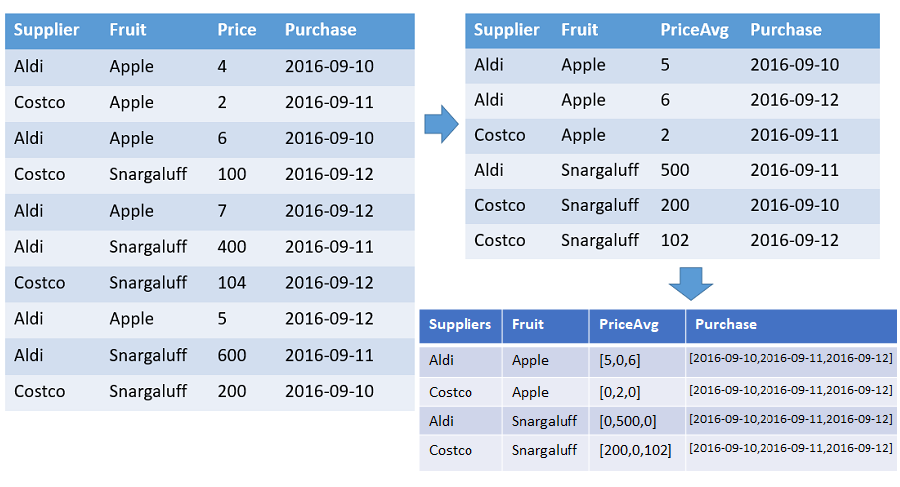
Eine Tabelle, die Arrays der Zahlen und Durchschnittspreise der einzelnen Früchte von jedem Lieferanten anzeigt, geordnet nach dem Zeitstempel mit dem angegebenen Bereich. Es gibt eine Zeile in der Ausgabe für jede einzelne Kombination von Obst und Lieferant. In den Ausgabespalten werden die Früchte, der Lieferant und die folgenden Arrays angezeigt: count, average und die gesamte Timeline (von 2016-01-01 bis 2016-01-10). Alle Arrays werden nach dem entsprechenden Zeitstempel sortiert, und alle Lücken werden mit Standardwerten aufgefüllt (in diesem Beispiel 0). Alle anderen Eingabespalten werden ignoriert.
T | make-series PriceAvg=avg(Price) default=0
on Purchase from datetime(2016-09-10) to datetime(2016-09-13) step 1d by Supplier, Fruit
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| make-series avg(metric) on timestamp from stime to etime step interval
| avg_metric | timestamp |
|---|---|
| [ 4.0, 3.0, 5.0, 0.0, 10.5, 4.0, 3.0, 8.0, 6.5 ] | [ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |
Wenn die Eingabe für make-series leer ist, erzeugt das Standardverhalten von make-series ein leeres Ergebnis.
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series avg(metric) default=1.0 on timestamp from stime to etime step interval
| count
Ausgabe
| Anzahl |
|---|
| 0 |
Die Verwendung von kind=nonempty in make-series führt zu einem nicht leeren Ergebnis der Standardwerte:
let data=datatable(timestamp:datetime, metric: real)
[
datetime(2016-12-31T06:00), 50,
datetime(2017-01-01), 4,
datetime(2017-01-02), 3,
datetime(2017-01-03), 4,
datetime(2017-01-03T03:00), 6,
datetime(2017-01-05), 8,
datetime(2017-01-05T13:40), 13,
datetime(2017-01-06), 4,
datetime(2017-01-07), 3,
datetime(2017-01-08), 8,
datetime(2017-01-08T21:00), 8,
datetime(2017-01-09), 2,
datetime(2017-01-09T12:00), 11,
datetime(2017-01-10T05:00), 5,
];
let interval = 1d;
let stime = datetime(2017-01-01);
let etime = datetime(2017-01-10);
data
| take 0
| make-series kind=nonempty avg(metric) default=1.0 on timestamp from stime to etime step interval
Ausgabe
| avg_metric | timestamp |
|---|---|
| [ 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0 ] |
[ "2017-01-01T00:00:00.0000000Z", "2017-01-02T00:00:00.0000000Z", "2017-01-03T00:00:00.0000000Z", "2017-01-04T00:00:00.0000000Z", "2017-01-05T00:00:00.0000000Z", "2017-01-06T00:00:00.0000000Z", "2017-01-07T00:00:00.0000000Z", "2017-01-08T00:00:00.0000000Z", "2017-01-09T00:00:00.0000000Z" ] |