SAP CDC advanced topics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
Learn about advanced topics for the SAP CDC connector like metadata driven data integration, debugging, and more.
One of the key strengths of pipelines and mapping data flows in Azure Data Factory and Azure Synapse Analytics is the support for metadata driven data integration. With this feature, it's possible to design a single (or few) parametrized pipeline that can be used to handle integration of potentially hundreds or even thousands of sources. The SAP CDC connector has been designed with this principle in mind: all relevant properties, whether it's the source object, run mode, key columns, etc., can be provided via parameters to maximize flexibility and reuse potential of SAP CDC mapping data flows.
To understand the basic concepts of parametrizing mapping data flows, read Parameterizing mapping data flows.
In the template gallery of Azure Data Factory and Azure Synapse Analytics, you find a template pipeline and data flow which shows how to parametrize SAP CDC data ingestion.
Mapping data flows don't necessarily require a Dataset artifact: both source and sink transformations offer a Source type (or Sink type) Inline. In this case, all source properties otherwise defined in an ADF dataset can be configured in the Source options of the source transformation (or Settings tab of the sink transformation). Using an inline dataset provides better overview and simplifies parametrizing a mapping data flow since the complete source (or sink) configuration is maintained in a one place.
For SAP CDC, the properties that are most commonly set via parameters are found in the tabs Source options and Optimize. When Source type is Inline, the following properties can be parametrized in Source options.
- ODP context: valid parameter values are
- ABAP_CDS for ABAP Core Data Services Views
- BW for SAP BW or SAP BW/4HANA InfoProviders
- HANA for SAP HANA Information Views
- SAPI for SAP DataSources/Extractors
- when SAP Landscape Transformation Replication Server (SLT) is used as a source, the ODP context name is SLT~<Queue Alias>. The Queue Alias value can be found under Administration Data in the SLT configuration in the SLT cockpit (SAP transaction LTRC).
- ODP_SELF and RANDOM are ODP contexts used for technical validation and testing, and are typically not relevant.
- ODP name: provide the ODP name you want to extract data from.
- Run mode: valid parameter values are
- fullAndIncrementalLoad for Full on the first run, then incremental, which initiates a change data capture process and extracts a current full data snapshot.
- fullLoad for Full on every run, which extracts a current full data snapshot without initiating a change data capture process.
- incrementalLoad for Incremental changes only, which initiates a change data capture process without extracting a current full snapshot.
- Key columns: key columns are provided as an array of (double-quoted) strings. For example, when working with SAP table VBAP (sales order items), the key definition would have to be ["VBELN", "POSNR"] (or ["MANDT","VBELN","POSNR"] in case the client field is taken into account as well).
In the Optimize tab, a source partitioning scheme (see optimizing performance for full or initial loads) can be defined via parameters. Typically, two steps are required:
- Define the source partitioning scheme.
- Ingest the partitioning parameter into the mapping data flow.
The format in step 1 follows the JSON standard, consisting of an array of partition definitions, each of which itself is an array of individual filter conditions. These conditions themselves are JSON objects with a structure aligned with so-called selection options in SAP. In fact, the format required by the SAP ODP framework is basically the same as dynamic DTP filters in SAP BW:
{ "fieldName": <>, "sign": <>, "option": <>, "low": <>, "high": <> }
For example
{ "fieldName": "VBELN", "sign": "I", "option": "EQ", "low": "0000001000" }
corresponds to a SQL WHERE clause ... WHERE "VBELN" = '0000001000', or
{ "fieldName": "VBELN", "sign": "I", "option": "BT", "low": "0000000000", "high": "0000001000" }
corresponds to a SQL WHERE clause ... WHERE "VBELN" BETWEEN '0000000000' AND '0000001000'
A JSON definition of a partitioning scheme containing two partitions thus looks as follows
[
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2011", "high": "2015" }
],
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2016", "high": "2020" }
]
]
where the first partition contains fiscal years (GJAHR) 2011 through 2015, and the second partition contains fiscal years 2016 through 2020.
Note
Azure Data Factory doesn't perform any checks on these conditions. For example, it is in the user's responsibility to ensure that partition conditions don't overlap.
Partition conditions can be more complex, consisting of multiple elementary filter conditions themselves. There are no logical conjunctions that explicitly define how to combine multiple elementary conditions within one partition. The implicit definition in SAP is as follows:
- including conditions ("sign": "I") for the same field name are combined with OR (mentally, put brackets around the resulting condition)
- excluding conditions ("sign": "E") for the same field name are combined with OR (again, mentally, put brackets around the resulting condition)
- the resulting conditions of steps 1 and 2 are
- combined with AND for including conditions,
- combined with AND NOT for excluding conditions.
As an example, the partition condition
[
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1000" },
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1010" },
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2010", "high": "2025" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2023" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2021" }
]
corresponds to a SQL WHERE clause ... WHERE ("BUKRS" = '1000' OR "BUKRS" = '1010') AND ("GJAHR" BETWEEN '2010' AND '2025') AND NOT ("GJAHR" = '2021' or "GJARH" = '2023')
Note
Make sure to use the SAP internal format for the low and high values, include leading zeroes, and express calendar dates as an eight character string with the format "YYYYMMDD".
To ingest the partitioning scheme into a mapping data flow, create a data flow parameter (for example, "sapPartitions"). To pass the JSON format to this parameter, it has to be converted to a string using the @string() function:
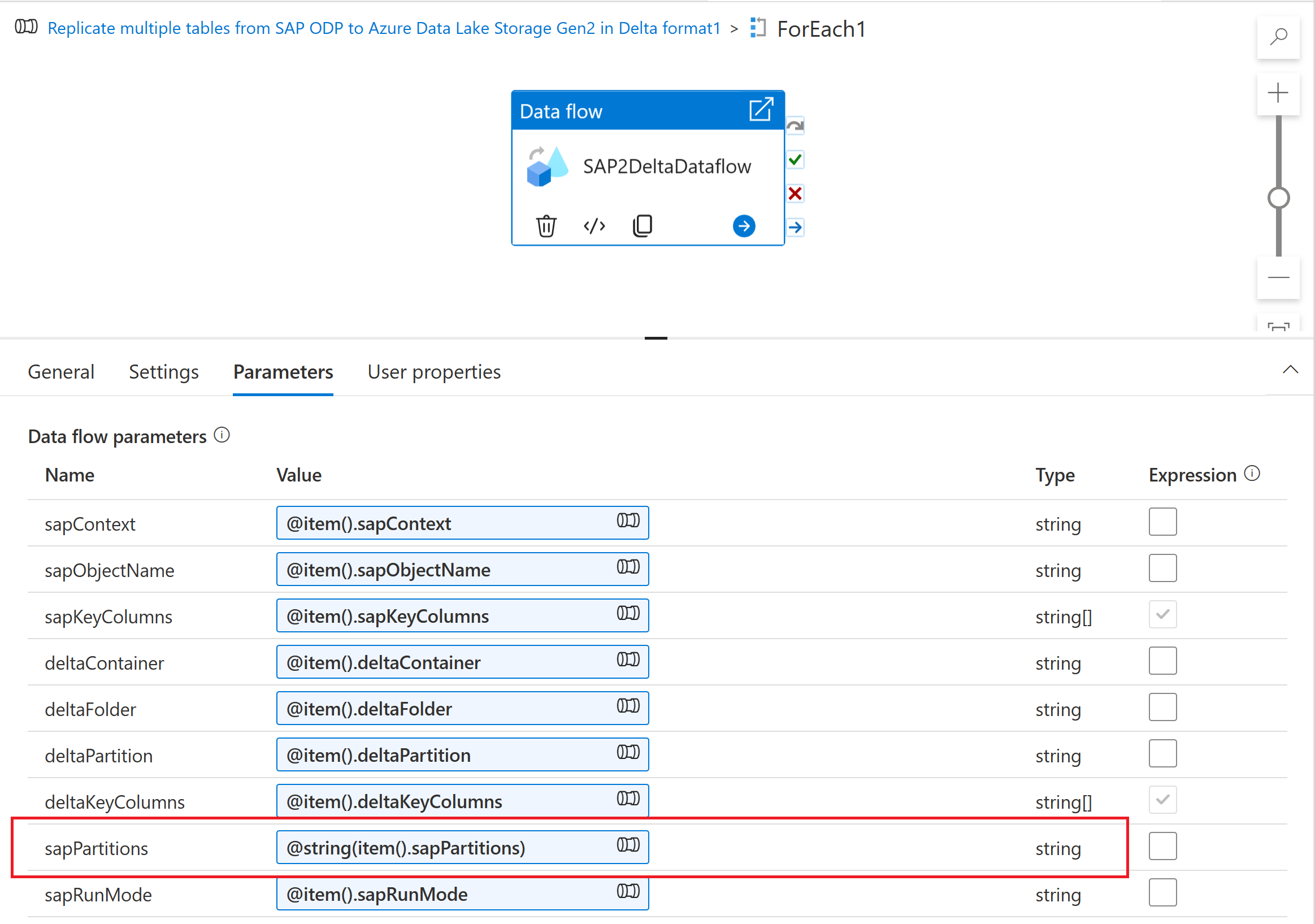
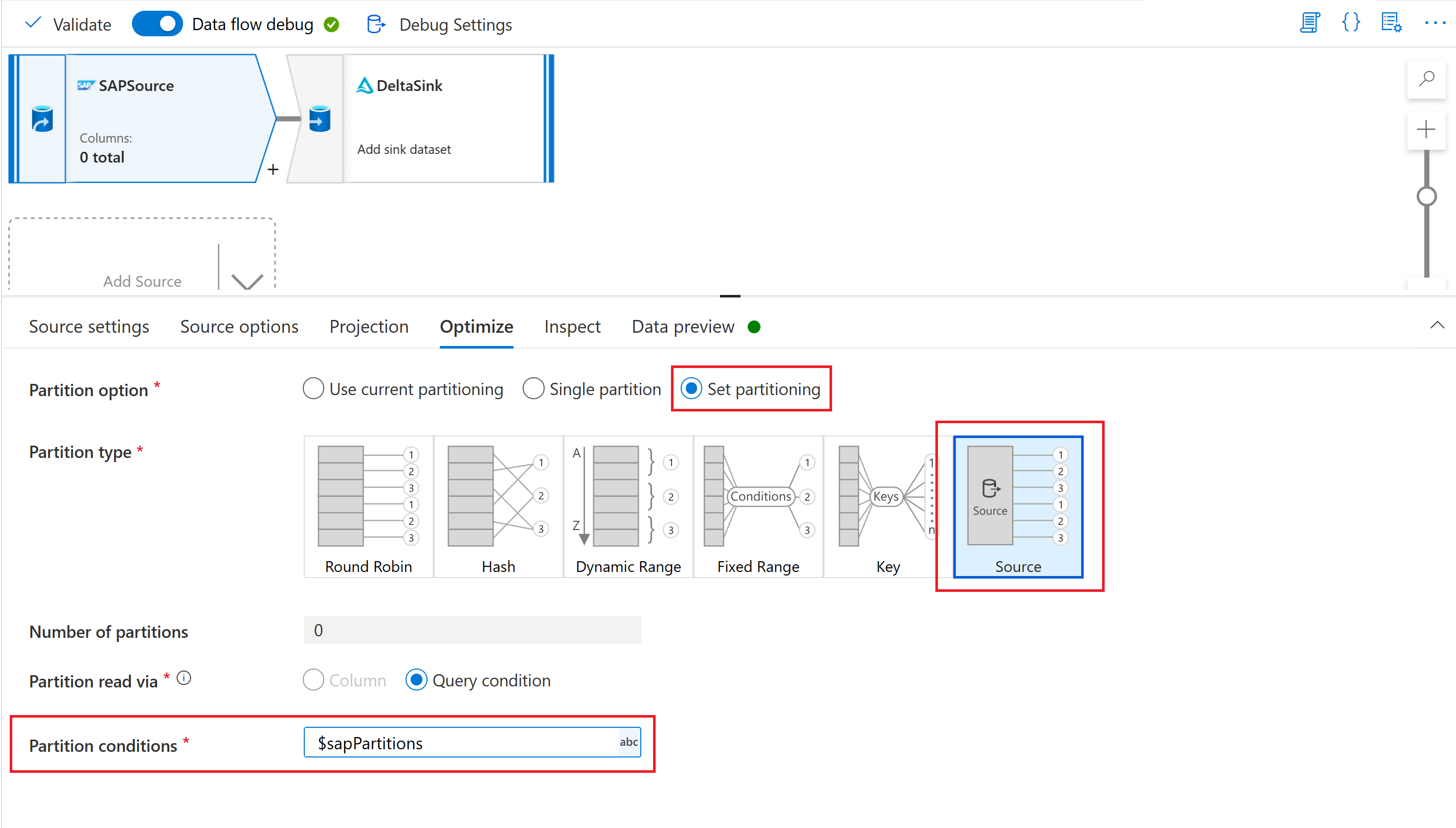
Finally, in the optimize tab of the source transformation in your mapping data flow, select Partition type "Source", and enter the data flow parameter in the Partition conditions property.
When using a parametrized data flow to extract data from multiple SAP CDC sources, it's important to parametrize the Checkpoint Key in the data flow activity of your pipeline. The checkpoint key is used by Azure Data Factory to manage the status of a change data capture process. To avoid that the status of one CDC process overwrites the status of another one, make sure that the checkpoint key values are unique for each parameter set used in a dataflow.
Note
A best practice to ensure uniqueness of the Checkpoint Key is to add the checkpoint key value to the set of parameters for your dataflow.
For more information on the checkpoint key, see Transform data with the SAP CDC connector.
Azure Data Factory pipelines can be executed via triggered or debug runs. A fundamental difference between these two options is, that debug runs execute the dataflow and pipeline based on the current version modeled in the user interface, while triggered runs execute the last published version of a dataflow and pipeline.
For SAP CDC, there's one more aspect that needs to be understood: to avoid an impact of debug runs on an existing change data capture process, debug runs use a different "subscriber process" value (see Monitor SAP CDC data flows) than triggered runs. Thus, they create separate subscriptions (that is, change data capture processes) within the SAP system. In addition, the "subscriber process" value for debug runs has a life time limited to the browser UI session.
Note
To test stability of a change data capture process with SAP CDC over a longer period of time (say, multiple days), data flow and pipeline need to be published, and triggered runs need to be executed.