Parquet format in Data Factory in Microsoft Fabric
This article outlines how to configure Parquet format in the data pipeline of Data Factory in Microsoft Fabric.
Supported capabilities
Parquet format is supported for the following activities and connectors as a source and destination.
| Category | Connector/Activity |
|---|---|
| Supported connector | Amazon S3 |
| Amazon S3 Compatible | |
| Azure Blob Storage | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| File system | |
| FTP | |
| Google Cloud Storage | |
| HTTP | |
| Lakehouse Files | |
| Oracle Cloud Storage | |
| SFTP | |
| Supported activity | Copy activity (source/destination) |
| Lookup activity | |
| GetMetadata activity | |
| Delete activity |
Parquet format in copy activity
To configure Parquet format, choose your connection in the source or destination of data pipeline copy activity, and then select Parquet in the drop-down list of File format. Select Settings for further configuration of this format.
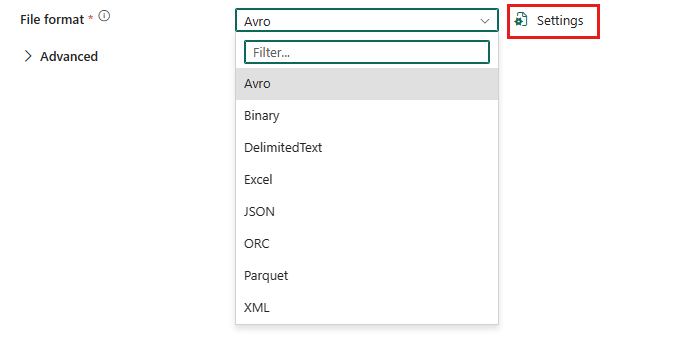
Parquet format as source
After you select Settings in the File format section, the following properties are shown in the pop-up File format settings dialog box.
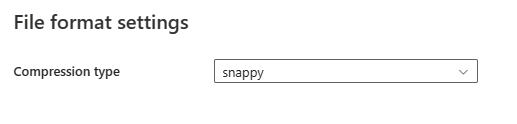
- Compression type: Choose the compression codec used to read Parquet files in the drop-down list. You can choose from None, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2), or lz4hadoop.
Parquet format as destination
After you select Settings, the following properties are shown in the pop-up File format settings dialog box.
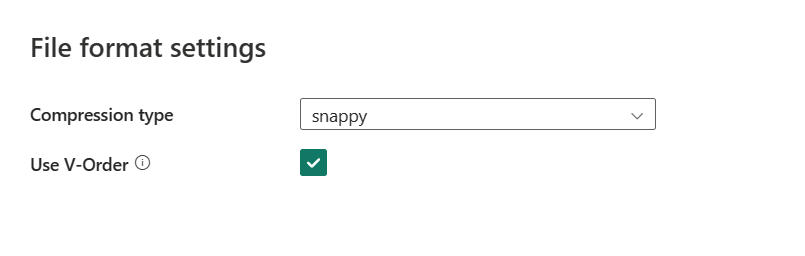
Compression type: Choose the compression codec used to write Parquet files in the drop-down list. You can choose from None, gzip (.gz), snappy, lzo, Brotli (.br), Zstandard, lz4, lz4frame, bzip2 (.bz2), or lz4hadoop.
Use V-Order: Enable a write time optimization to the parquet file format. For more information, see Delta Lake table optimization and V-Order. It is enabled by default.
Under Advanced settings in the Destination tab, the following Parquet format related properties are displayed.
- Max rows per file: When writing data into a folder, you can choose to write to multiple files and specify the maximum rows per file. Specify the maximum rows that you want to write per file.
- File name prefix: Applicable when Max rows per file is configured. Specify the file name prefix when writing data to multiple files, resulted in this pattern:
<fileNamePrefix>_00000.<fileExtension>. If not specified, the file name prefix is auto generated. This property doesn't apply when the source is a file based store or a partition option enabled data store.
Table summary
Parquet as source
The following properties are supported in the copy activity Source section when using the Parquet format.
| Name | Description | Value | Required | JSON script property |
|---|---|---|---|---|
| File format | The file format that you want to use. | Parquet | Yes | type (under datasetSettings):Parquet |
| Compression type | The compression codec used to read Parquet files. | Choose from: None gzip (.gz) snappy lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
No | compressionCodec: gzip snappy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
Parquet as destination
The following properties are supported in the copy activity Destination section when using the Parquet format.
| Name | Description | Value | Required | JSON script property |
|---|---|---|---|---|
| File format | The file format that you want to use. | Parquet | Yes | type (under datasetSettings):Parquet |
| Use V-Order | A write time optimization to the parquet file format. | selected or unselected | No | enableVertiParquet |
| Compression type | The compression codec used to write Parquet files. | Choose from: None gzip (.gz) snappy lzo Brotli (.br) Zstandard lz4 lz4frame bzip2 (.bz2) lz4hadoop |
No | compressionCodec: gzip snappy lzo brotli zstd lz4 lz4frame bz2 lz4hadoop |
| Max rows per file | When writing data into a folder, you can choose to write to multiple files and specify the maximum rows per file. Specify the maximum rows that you want to write per file. | <your max rows per file> | No | maxRowsPerFile |
| File name prefix | Applicable when Max rows per file is configured. Specify the file name prefix when writing data to multiple files, resulted in this pattern: <fileNamePrefix>_00000.<fileExtension>. If not specified, the file name prefix is auto generated. This property doesn't apply when the source is a file based store or a partition option enabled data store. |
<your file name prefix> | No | fileNamePrefix |
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for