Risolvere i problemi relativi alle pipeline di Azure Data Factory e Synapse
SI APPLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutto, dallo spostamento dati al data science, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Vedere le informazioni su come iniziare una nuova prova gratuita!
Questo articolo illustra i metodi più comuni per la risoluzione dei problemi relativi alle attività di controllo esterne in Azure Data Factory e nelle pipeline Synapse.
Connettore e attività di copia
Per problemi relativi al connettore, ad esempio un errore durante l'attività di copia, vedere Risolvere i problemi dei connettori.
Azure Databricks
Codice errore: 3200
Messaggio: Errore 403.
Causa:
The Databricks access token has expired.Consiglio: per impostazione predefinita, il token di accesso di Azure Databricks è valido per 90 giorni. Creare un nuovo token e aggiornare il servizio collegato.
Codice errore: 3201
Messaggio:
Missing required field: settings.task.notebook_task.notebook_path.Causa:
Bad authoring: Notebook path not specified correctly.Consiglio: specificare il percorso del notebook nell'attività Databricks.
Messaggio:
Cluster... does not exist.Causa:
Authoring error: Databricks cluster does not exist or has been deleted.Consiglio: verificare che sia presente il cluster Databricks.
Messaggio:
Invalid Python file URI... Please visit Databricks user guide for supported URI schemes.Causa:
Bad authoring.Consiglio: specificare i percorsi assoluti per gli schemi di indirizzamento dell'area di lavoro o
dbfs:/folder/subfolder/foo.pyper i file archiviati nel Databricks File System (DFS).
Messaggio:
{0} LinkedService should have domain and accessToken as required properties.Causa:
Bad authoring.Consiglio: verificare la definizione del servizio collegato.
Messaggio:
{0} LinkedService should specify either existing cluster ID or new cluster information for creation.Causa:
Bad authoring.Consiglio: verificare la definizione del servizio collegato.
Messaggio:
Node type Standard_D16S_v3 is not supported. Supported node types: Standard_DS3_v2, Standard_DS4_v2, Standard_DS5_v2, Standard_D8s_v3, Standard_D16s_v3, Standard_D32s_v3, Standard_D64s_v3, Standard_D3_v2, Standard_D8_v3, Standard_D16_v3, Standard_D32_v3, Standard_D64_v3, Standard_D12_v2, Standard_D13_v2, Standard_D14_v2, Standard_D15_v2, Standard_DS12_v2, Standard_DS13_v2, Standard_DS14_v2, Standard_DS15_v2, Standard_E8s_v3, Standard_E16s_v3, Standard_E32s_v3, Standard_E64s_v3, Standard_L4s, Standard_L8s, Standard_L16s, Standard_L32s, Standard_F4s, Standard_F8s, Standard_F16s, Standard_H16, Standard_F4s_v2, Standard_F8s_v2, Standard_F16s_v2, Standard_F32s_v2, Standard_F64s_v2, Standard_F72s_v2, Standard_NC12, Standard_NC24, Standard_NC6s_v3, Standard_NC12s_v3, Standard_NC24s_v3, Standard_L8s_v2, Standard_L16s_v2, Standard_L32s_v2, Standard_L64s_v2, Standard_L80s_v2.Causa:
Bad authoring.Consiglio: consultare il messaggio di errore.
Codice errore: 3202
Messaggio:
There were already 1000 jobs created in past 3600 seconds, exceeding rate limit: 1000 job creations per 3600 seconds.Causa:
Too many Databricks runs in an hour.Consiglio: controllare la velocità di creazione del processo per tutte le pipeline che usano l'area di lavoro di Databricks. Se le pipeline avviano troppe esecuzioni di Databricks aggregate, migrare alcune pipeline a una nuova area di lavoro.
Messaggio:
Could not parse request object: Expected 'key' and 'value' to be set for JSON map field base_parameters, got 'key: "..."' instead.Causa:
Authoring error: No value provided for the parameter.Consiglio: esaminare il JSON della pipeline e verificare che per tutti i parametri del notebook baseParameters sia specificato un valore non vuoto.
Messaggio:
User: 'SimpleUserContext{userId=..., name=user@company.com, orgId=...}' is not authorized to access cluster.Causa: l'utente che ha generato il token di accesso non è autorizzato a accedere al cluster Databricks specificato nel servizio collegato.
Consiglio: verificare che l'utente disponga delle autorizzazioni richieste nell'area di lavoro.
Messaggio:
Job is not fully initialized yet. Please retry later.Causa: il processo non è stato inizializzato.
Consiglio: attendere e riprovare più tardi.
Codice errore: 3203
Messaggio:
The cluster is in Terminated state, not available to receive jobs. Please fix the cluster or retry later.Causa: il cluster è stato arrestato. In caso di cluster interattivi, il problema potrebbe essere una race condition.
Consiglio: per evitare questo errore, usare cluster di processo.
Codice errore: 3204
Messaggio:
Job execution failed.Causa: i messaggi di errore indicano diversi problemi, ad esempio uno stato imprevisto del cluster o un'attività specifica. Spesso non vengono visualizzati messaggi di errore.
Consiglio: N/D
Codice errore: 3208
Messaggio:
An error occurred while sending the request.Causa: la connessione di rete al servizio Databricks è stata interrotta.
Consiglio: se si usa un runtime di integrazione self-hosted, assicurarsi che la connessione di rete sia affidabile dai nodi del runtime di integrazione. Se si usa il runtime di integrazione di Azure, in genere l'esecuzione di un nuovo tentativo funziona.
L'output dell'esecuzione booleana viene avviato come stringa anziché come INT previsto
Sintomi: l'output dell'esecuzione booleana inizia come stringa (ad esempio
"0"o"1") anziché come IN previsto (ad esempio0o1).
Questa modifica è stata notata il 28 settembre 2021 alle 9.00 circa quando la pipeline che si basa su questo output ha avuto esito negativo. Non è stata apportata alcuna modifica alla pipeline e i dati di output booleani sono stati ricevuti come previsto prima dell'errore.

Causa: questo problema è causato da una modifica recente ed è un comportamento voluto. Dopo la modifica, se il risultato è un numero che inizia con zero, Azure Data Factory convertirà il numero nel valore ottale, il che è un bug. Questo numero è sempre 0 o 1, cosa che non ha mai causato problemi prima della modifica. Per correggere la conversione ottale, l'output della stringa viene quindi passato dall'esecuzione dagli Appunti così com'è.
Consiglio: modificare la condizione if impostando un valore simile a
if(value=="0").
Azure Data Lake Analytics.
La tabella seguente si riferisce a U-SQL.
Codice errore: 2709
Messaggio:
The access token is from the wrong tenant.Causa: tenant Microsoft Entra non corretto.
Causa: tenant Microsoft Entra non corretto.
Messaggio:
We cannot accept your job at this moment. The maximum number of queued jobs for your account is 200.Causa: questo errore è causato dalla limitazione in Data Lake Analytics.
Consiglio: ridurre il numero di processi inviati a Data Lake Analytics. Modificare i trigger e le impostazioni di concorrenza per le attività o aumentare i limiti di Data Lake Analytics.
Messaggio:
This job was rejected because it requires 24 AUs. This account's administrator-defined policy prevents a job from using more than 5 AUs.Causa: questo errore è causato dalla limitazione in Data Lake Analytics.
Consiglio: ridurre il numero di processi inviati a Data Lake Analytics. Modificare i trigger e le impostazioni di concorrenza per le attività o aumentare i limiti di Data Lake Analytics.
Codice errore: 2705
Messaggio:
Forbidden. ACL verification failed. Either the resource does not exist or the user is not authorized to perform the requested operation.<br/> <br/> User is not able to access Data Lake Store. <br/> <br/> User is not authorized to use Data Lake Analytics.Causa: l'entità servizio o il certificato non hanno accesso al file nella risorsa di archiviazione.
Consiglio: verificare che l'entità servizio o il certificato forniti dall'utente per i processi Data Lake Analytics possano accedere sia all'account Data Lake Analytics, sia all'istanza Data Lake Storage predefinita dalla cartella radice.
Codice errore: 2711
Messaggio:
Forbidden. ACL verification failed. Either the resource does not exist or the user is not authorized to perform the requested operation.<br/> <br/> User is not able to access Data Lake Store. <br/> <br/> User is not authorized to use Data Lake Analytics.Causa: l'entità servizio o il certificato non hanno accesso al file nella risorsa di archiviazione.
Consiglio: verificare che l'entità servizio o il certificato forniti dall'utente per i processi Data Lake Analytics possano accedere sia all'account Data Lake Analytics, sia all'istanza Data Lake Storage predefinita dalla cartella radice.
Messaggio:
Cannot find the 'Azure Data Lake Store' file or folder.Causa: il percorso del file U-SQL è errato o non è possibile accedere con le credenziali del servizio associato.
Consiglio: verificare percorso e credenziali forniti nel servizio associato.
Codice errore: 2704
Messaggio:
Forbidden. ACL verification failed. Either the resource does not exist or the user is not authorized to perform the requested operation.<br/> <br/> User is not able to access Data Lake Store. <br/> <br/> User is not authorized to use Data Lake Analytics.Causa: l'entità servizio o il certificato non hanno accesso al file nella risorsa di archiviazione.
Consiglio: verificare che l'entità servizio o il certificato forniti dall'utente per i processi Data Lake Analytics possano accedere sia all'account Data Lake Analytics, sia all'istanza Data Lake Storage predefinita dalla cartella radice.
Codice errore: 2707
Messaggio:
Cannot resolve the account of AzureDataLakeAnalytics. Please check 'AccountName' and 'DataLakeAnalyticsUri'.Causa: account Data Lake Analytics errato nel servizio associato.
Consiglio: verificare di aver inserito l'account corretto.
Codice errore: 2703
Messaggio:
Error Id: E_CQO_SYSTEM_INTERNAL_ERROR (or any error that starts with "Error Id:").Causa: l'errore riguarda Data Lake Analytics.
Consiglio: si è verificato un errore nel processo inviato a Data Lake Analytics e nello script. Cercare la causa in Data Lake Analytics. Accedere all'account Data Lake Analytics dal portale e cercare il processo usando l'ID di esecuzione attività di Data Factory (non usare l'ID di esecuzione della pipeline). Nel processo è possibile trovare più informazioni sull'errore per risolvere il problema.
Se la soluzione non è chiara, contattare il team di supporto di Data Lake Analytics e fornire l'URL del processo, che contiene il nome dell'account e l'ID del processo.
Funzioni di Azure
Codice errore: 3602
Messaggio:
Invalid HttpMethod: '%method;'.Causa: il metodo HTTP specificato nel payload delle attività non è supportato dall'attività della funzione di Azure.
Consiglio: i metodi HTTP supportati sono: PUT, POST, GET, DELETE, OPTIONS, HEAD e TRACE.
Codice errore: 3603
Messaggio:
Response Content is not a valid JObject.Causa: la funzione di Azure chiamata non ha restituito in risposta un payload JSON. L'attività della funzione Azure della pipeline Synapse e Azure Data Factory supporta solo risposte con contenuto JSON.
Consiglio: aggiornare la funzione di Azure in modo che restituisca un payload JSON valido, come quello di una funzione C#
(ActionResult)new OkObjectResult("{\"Id\":\"123\"}");
Codice errore: 3606
Messaggio: chiave della funzione mancante nell'attività della funzione di Azure.
Causa: la definizione dell'attività della funzione di Azure non è completa.
Consiglio: verificare che nella definizione JSON dell'attività della funzione di input di Azure sia presente una proprietà con nome
functionKey.
Codice errore: 3607
Messaggio:
Azure function activity missing function name.Causa: la definizione dell'attività della funzione di Azure non è completa.
Consiglio: verificare che nella definizione JSON dell'attività della funzione di input di Azure sia presente una proprietà con nome
functionName.
Codice errore: 3608
Messaggio:
Call to provided Azure function '%FunctionName;' failed with status-'%statusCode;' and message - '%message;'.Causa: i dettagli della funzione di Azure nella definizione dell'attività potrebbero non essere corretti.
Consiglio: correggere i dettagli della funzione di Azure e riprovare.
Codice errore: 3609
Messaggio:
Azure function activity missing functionAppUrl.Causa: la definizione dell'attività della funzione di Azure non è completa.
Consiglio: verificare che nella definizione JSON dell'attività della funzione di input di Azure sia presente una proprietà con nome
functionAppUrl.
Codice errore: 3610
Messaggio:
There was an error while calling endpoint.Causa: l'URL della funzione potrebbe non essere corretto.
Consiglio: verificare che il valore di
functionAppUrlnel JSON dell'attività sia corretto e riprovare.
Codice errore: 3611
Messaggio:
Azure function activity missing Method in JSON.Causa: la definizione dell'attività della funzione di Azure non è completa.
Consiglio: verificare che nella definizione JSON dell'attività della funzione di input di Azure sia presente una proprietà con nome
method.
Codice errore: 3612
Messaggio:
Azure function activity missing LinkedService definition in JSON.Causa: la definizione dell'attività della funzione di Azure non è completa.
Consiglio: verificare che nella definizione JSON dell'attività della funzione di input di Azure siano presenti dettagli sul servizio collegato.
Azure Machine Learning
Codice errore: 4101
Messaggio:
AzureMLExecutePipeline activity '%activityName;' has invalid value for property '%propertyName;'.Causa: formato errato o definizione della proprietà mancante
%propertyName;.Consiglio: controllare che nell'attività
%activityName;la proprietà%propertyName;sia definita con i dati corretti.
Codice errore: 4110
Messaggio:
AzureMLExecutePipeline activity missing LinkedService definition in JSON.Causa: la definizione dell'attività AzureMLExecutePipeline non è completa.
Consiglio: verificare che nella definizione JSON dell'attività della funzione di input AzureMLExecutePipeline i dettagli del servizio siano collegati correttamente.
Codice errore: 4111
Messaggio:
AzureMLExecutePipeline activity has wrong LinkedService type in JSON. Expected LinkedService type: '%expectedLinkedServiceType;', current LinkedService type: Expected LinkedService type: '%currentLinkedServiceType;'.Causa: la definizione dell'attività non è corretta.
Consiglio: verificare che nella definizione JSON dell'attività della funzione di input AzureMLExecutePipeline i dettagli del servizio siano collegati correttamente.
Codice errore: 4112
Messaggio:
AzureMLService linked service has invalid value for property '%propertyName;'.Causa: formato errato o definizione della proprietà "%propertyName;" mancante.
Consiglio: verificare che la proprietà
%propertyName;del servizio collegato sia definita con i dati corretti.
Codice errore: 4121
Messaggio:
Request sent to Azure Machine Learning for operation '%operation;' failed with http status code '%statusCode;'. Error message from Azure Machine Learning: '%externalMessage;'.Causa: le credenziali usate per accedere a Azure Machine Learning sono scadute.
Consiglio: verificare che le credenziali siano valide e riprovare.
Codice errore: 4122
Messaggio:
Request sent to Azure Machine Learning for operation '%operation;' failed with http status code '%statusCode;'. Error message from Azure Machine Learning: '%externalMessage;'.Causa: le credenziali fornite nel servizio associato di Azure Machine Learning non sono valide o non dispongono dell'autorizzazione per l'operazione.
Consiglio: verificare che le credenziali del servizio associato siano valide e che dispongano dell'autorizzazione per accedere a Azure Machine Learning.
Codice errore: 4123
Messaggio:
Request sent to Azure Machine Learning for operation '%operation;' failed with http status code '%statusCode;'. Error message from Azure Machine Learning: '%externalMessage;'.Causa: le proprietà dell'attività, ad esempio
pipelineParameters, non sono valide per la pipeline di Azure Machine Learning (ML).Consiglio: verificare che il valore delle proprietà dell'attività corrisponda al payload previsto per la pipeline Azure Machine Learning pubblicata specificato in Servizio associato.
Codice errore: 4124
Messaggio:
Request sent to Azure Machine Learning for operation '%operation;' failed with http status code '%statusCode;'. Error message from Azure Machine Learning: '%externalMessage;'.Causa: l'endpoint della pipeline Azure Machine Learning pubblicato non esiste.
Consiglio: verificare che l'endpoint della pipeline Azure Machine Learning pubblicato in Servizio associato sia presente in Azure Machine Learning.
Codice errore: 4125
Messaggio:
Request sent to Azure Machine Learning for operation '%operation;' failed with http status code '%statusCode;'. Error message from Azure Machine Learning: '%externalMessage;'.Causa: si è verificato un errore del server in Azure Machine Learning.
Consiglio: Riprovare in un secondo momento. Se il problema persiste, contattare il team di Azure Machine Learning.
Codice errore: 4126
Messaggio:
Azure ML pipeline run failed with status: '%amlPipelineRunStatus;'. Azure ML pipeline run Id: '%amlPipelineRunId;'. Please check in Azure Machine Learning for more error logs.Causa: l'esecuzione della pipeline di Azure Machine Learning non è riuscita.
Consiglio: verificare la presenza di altri log di errore in Azure Machine Learning e correggere la pipeline.
Azure Synapse Analytics
Codice errore: 3250
Messaggio:
There are not enough resources available in the workspace, details: '%errorMessage;'Causa: risorse insufficienti
Consiglio: provare a terminare i processi in esecuzione nell'area di lavoro, riducendo il numero di vCore richiesti, aumentando la quota dell'area di lavoro o usando un'altra area di lavoro.
Codice errore: 3251
Messaggio:
There are not enough resources available in the pool, details: '%errorMessage;'Causa: risorse insufficienti
Consiglio: provare a terminare i processi in esecuzione nel pool, riducendo il numero di vCore richiesti, aumentando le dimensioni massime del pool o usando un altro pool.
Codice errore: 3252
Messaggio:
There are not enough vcores available for your spark job, details: '%errorMessage;'Causa: quota macchina virtuale insufficiente
Consiglio: provare a ridurre il numero di vCore richiesti o ad aumentare la quota di vCore. Per altre informazioni, vedere Concetti di base di Apache Spark.
Codice errore: 3253
Messaggio:
There are substantial concurrent MappingDataflow executions which is causing failures due to throttling under the Integration Runtime used for ActivityId: '%activityId;'.Causa: è stata raggiunta la soglia di limitazione.
Consiglio: ripetere la richiesta dopo un periodo di attesa.
Codice errore: 3254
Messaggio:
AzureSynapseArtifacts linked service has invalid value for property '%propertyName;'.Causa: formato errato o definizione della proprietà "%propertyName;" mancante.
Consiglio: controllare che il servizio collegato abbia la proprietà "%propertyName;" definita con i dati corretti.
Comune
Codice errore: 2103
Messaggio:
Please provide value for the required property '%propertyName;'.Causa: non è stato inserito il valore richiesto per la proprietà.
Consiglio: inserire il valore indicato nel messaggio e riprovare.
Codice errore: 2104
Messaggio:
The type of the property '%propertyName;' is incorrect.Causa: il tipo di proprietà indicato non è corretto.
Consiglio: correggere il tipo di proprietà e riprovare.
Codice errore: 2105
Messaggio:
An invalid json is provided for property '%propertyName;'. Encountered an error while trying to parse: '%message;'.Causa: il valore della proprietà non è valido o nel formato previsto.
Consiglio: consultare la documentazione della proprietà e verificare che il valore fornito includa formato e tipo corretti.
Codice errore: 2106
Messaggio:
The storage connection string is invalid. %errorMessage;Causa: la stringa di connessione per la risorsa di archiviazione non è valida o il formato non è corretto.
Consiglio: trovare la risorsa di archiviazione nel portale di Azure, quindi copiare e incollare la stringa di connessione nel servizio associato e riprovare.
Codice errore: 2110
Messaggio:
The linked service type '%linkedServiceType;' is not supported for '%executorType;' activities.Causa: il servizio collegato specificato nell'attività non è corretto.
Consiglio: verificare che il tipo di servizio collegato sia uno di quelli supportati per l'attività. Ad esempio, il tipo di servizio collegato per le attività HDI può essere HDInsight o HDInsightOnDemand.
Codice errore: 2111
Messaggio:
The type of the property '%propertyName;' is incorrect. The expected type is %expectedType;.Causa: il tipo di proprietà indicato non è corretto.
Consiglio: correggere il tipo di proprietà e riprovare.
Codice errore: 2112
Messaggio:
The cloud type is unsupported or could not be determined for storage from the EndpointSuffix '%endpointSuffix;'.Causa: il tipo di cloud non è supportato o non può essere determinato da EndpointSuffix per l'archiviazione.
Consiglio: archiviare in un altro cloud e riprovare.
Personalizzazione
La tabella seguente si applica a Azure Batch.
Codice errore: 2500
Messaggio:
Hit unexpected exception and execution failed.Causa:
Can't launch command, or the program returned an error code.Consiglio: assicurarsi che il file eseguibile esista. Se il programma si è avviato, verificare che stdout.txt e stderr.txt siano stati caricati nell'account di archiviazione. È consigliabile includere i log nel codice per il debug.
Codice errore: 2501
Messaggio:
Cannot access user batch account; please check batch account settings.Causa: chiave di accesso a Batch o nome del pool errati.
Consiglio: verificare il nome del pool e la chiave di accesso a Batch nel servizio collegato.
Codice errore: 2502
Messaggio:
Cannot access user storage account; please check storage account settings.Causa: il nome dell'account di archiviazione o la chiave di accesso non sono corretti.
Consiglio: verificare il nome dell'account di archiviazione e la chiave di accesso nel servizio collegato.
Codice errore: 2504
Messaggio:
Operation returned an invalid status code 'BadRequest'.Causa: troppi file nel
folderPathdell'attività personalizzata.resourceFilesnon può contenere più di 32.768 caratteri.Consiglio: rimuovere i file non necessari o comprimerli e aggiungere un comando di decompressione per estrarli.
Ad esempio, usare
powershell.exe -nologo -noprofile -command "& { Add-Type -A 'System.IO.Compression.FileSystem'; [IO.Compression.ZipFile]::ExtractToDirectory($zipFile, $folder); }" ; $folder\yourProgram.exe
Codice errore: 2505
Messaggio:
Cannot create Shared Access Signature unless Account Key credentials are used.Causa: le attività personalizzate supportano solo account di archiviazione che usano una chiave di accesso.
Consiglio: consultare la descrizione dell'errore.
Codice errore: 2507
Messaggio:
The folder path does not exist or is empty: ...Causa: nell'account di archiviazione nel percorso specificato non sono presenti file.
Consiglio: il percorso della cartella deve contenere i file eseguibili da usare.
Codice errore: 2508
Messaggio:
There are duplicate files in the resource folder.Causa: in sottocartelle di folderPath sono presenti più file con lo stesso nome.
Consiglio: le attività personalizzate rendono flat la struttura in folderPath. Se è necessario mantenere la struttura di cartelle, comprimere i file ed estrarli in Azure Batch usando un comando di decompressione.
Ad esempio, usare
powershell.exe -nologo -noprofile -command "& { Add-Type -A 'System.IO.Compression.FileSystem'; [IO.Compression.ZipFile]::ExtractToDirectory($zipFile, $folder); }" ; $folder\yourProgram.exe
Codice errore: 2509
Messaggio:
Batch url ... is invalid; it must be in Uri format.Causa: gli URL Batch devono essere simili a
https://mybatchaccount.eastus.batch.azure.comConsiglio: consultare la descrizione dell'errore.
Codice errore: 2510
Messaggio:
An error occurred while sending the request.Causa: URL batch non valido.
Consiglio: verificare l'URL del batch.
HDInsight
Codice errore: 206
Messaggio:
The batch ID for Spark job is invalid. Please retry your job.Causa: l'errore è stato causato da un problema interno del servizio.
Consiglio: questo problema potrebbe essere temporaneo. Riprovare il processo dopo qualche minuto.
Codice errore: 207
Messaggio:
Could not determine the region from the provided storage account. Please try using another primary storage account for the on demand HDI.Causa: errore interno durante il tentativo di determinare l'area dall'account di archiviazione primario.
Consiglio: provare un'altra risorsa di archiviazione.
Codice errore: 208
Messaggio:
Service Principal or the MSI authenticator are not instantiated. Please consider providing a Service Principal in the HDI on demand linked service which has permissions to create an HDInsight cluster in the provided subscription and try again.Causa: si è verificato un errore interno durante il tentativo di leggere l'entità servizio o di creare un'istanza dell'autenticazione MSI.
Consiglio: fornire un'entità servizio con autorizzazioni per creare un cluster HDInsight nella sottoscrizione fornita e riprovare. Verificare che le identità gestite siano configurate correttamente.
Codice errore: 2300
Messaggio:
Failed to submit the job '%jobId;' to the cluster '%cluster;'. Error: %errorMessage;.Causa: il messaggio di errore è simile a
The remote name could not be resolved.. L'URI cluster fornito potrebbe non essere valido.Consiglio: verificare che il cluster non sia stato eliminato e che l'URI sia corretto. Quando si apre l'URI in un browser, dovrebbe essere visualizzata interfaccia utente di Ambari. Se il cluster si trova in una rete virtuale, l'URI dovrebbe essere privato. Per aprirlo, usare una macchina virtuale all'interno della stessa rete virtuale.
Per altre informazioni, vedere Connettersi direttamente ai servizi Apache Hadoop.
Causa: se il messaggio di errore è simile a
A task was canceled., si è verificato il timeout dell'invio del processo.Consiglio: il problema potrebbe riguardare la connettività generale di HDInsight o la connettività di rete. Per prima cosa, verificare che l'interfaccia utente di HDInsight Ambari sia disponibile in qualsiasi browser. In seguito, controllare che le credenziali siano ancora valide.
Se si usa un runtime di integrazione self-hosted, procedere come segue usando la macchina virtuale o il computer in cui è installato il runtime. Provare quindi a inviare di nuovo il processo.
Per altre informazioni, vedere Interfaccia utente Web Ambari.
Causa: quando il messaggio di errore contiene un messaggio simile a
User admin is locked out in AmbarioUnauthorized: Ambari user name or password is incorrect, le credenziali di HDInsight sono errate o sono scadute.Consiglio: correggere le credenziali e distribuire di nuovo il servizio collegato. Verificare prima di tutto che le credenziali funzionino in HDInsight aprendo l'URI del cluster in qualsiasi browser e tentando di eseguire l'accesso. Se le credenziali non funzionano, è possibile reimpostarle nel portale di Azure.
Se si usa un cluster ESP, reimpostare la password con Reimpostazione password self-service.
Causa: se il messaggio di errore è simile a
502 - Web server received an invalid response while acting as a gateway or proxy server, questo errore viene restituito dal servizio HDInsight.Consiglio: quando si arresta il processo del server Ambari, spesso si verifica un errore 502. È possibile riavviare i servizi Ambari riavviando il nodo head.
Connettersi a uno dei nodi su HDInsight tramite SSH.
Identificare l'host del nodo head attivo eseguendo
ping headnodehost.Quando il server Ambari si trova sul nodo, connettersi al nodo head attivo tramite SSH.
Riavviare il nodo head attivo.
Per altre informazioni, vedere la documentazione sulla risoluzione dei problemi di Microsoft Azure HDInsight. Ad esempio:
Causa: se il messaggio di errore è simile a
Unable to service the submit job request as templeton service is busy with too many submit job requestsoQueue root.joblauncher already has 500 applications, cannot accept submission of application, il numero di processi inviati contemporaneamente a HDInsight è eccessivo.Consiglio: limitare il numero di processi inviati contemporaneamente a HDInsight. Se i processi vengono inviati dalla stessa attività, fare riferimento alla concorrenza delle attività di Data Factory. Modificare i trigger in modo che le esecuzioni simultanee della pipeline vengano distribuite nel tempo.
Vedere la documentazione di HDInsight per configurare
templeton.parallellism.job.submitcome suggerito dall'errore.
Codice errore: 2301
Messaggio:
Could not get the status of the application '%physicalJobId;' from the HDInsight service. Received the following error: %message;. Please refer to HDInsight troubleshooting documentation or contact their support for further assistance.Causa: problemi del cluster HDInsight o del servizio.
Consiglio: questo errore si verifica quando il servizio non riceve una risposta dal cluster HDInsight quando tenta di richiedere lo stato del processo in esecuzione. Questo problema potrebbe essere dovuto al cluster stesso oppure a un'interruzione del servizio HDInsight.
Per altre informazioni, vedere la Documentazione sulla risoluzione dei problemi di HDInsight oppure contattare il supporto Tecnico Microsoft.
Codice errore: 2302
Messaggio:
Hadoop job failed with exit code '%exitCode;'. See '%logPath;/stderr' for more details. Alternatively, open the Ambari UI on the HDI cluster and find the logs for the job '%jobId;'. Contact HDInsight team for further support.Causa: l'errore si è verificato dopo l'invio del processo al cluster HDI.
Raccomandazione:
- Controllare l'interfaccia utente di Ambari:
- Verificare che tutti i servizi siano ancora in esecuzione.
- Nell'interfaccia utente di Ambari, controllare la sezione degli avvisi della dashboard.
- Per altre informazioni su avvisi e relative soluzioni, vedere Gestione e monitoraggio di un cluster.
- Controllare la memoria YARN. Se l'uso di memoria YARN è alto, l'elaborazione dei processi potrebbe subire ritardi. Se le risorse disponibili non sono sufficienti per gestire l'applicazione o il processo Spark, aumentare il numero di istanze del cluster per garantire che il cluster abbia memoria e core sufficienti.
- Eseguire un processo di esempio.
- Se si esegue lo stesso processo nel back-end HDInsight, verificare che sia stato completato. Per esempi di esecuzione, vedere Eseguire gli esempi di MapReduce inclusi in HDInsight
- Se il processo non è ancora riuscito in HDInsight, identificare i registri e le informazioni dell'applicazione da fornire all'assistenza:
- Controllare se il processo è stato inviato a YARN. In caso contrario, usare
--master yarn. - Se l'esecuzione dell'applicazione è stata completata, recuperare ora di inizio e di fine dell'applicazione YARN. Se l'esecuzione dell'applicazione non è stata completata, recuperare l'ora di inizio/avvio.
- Esaminare e recuperare il registro applicazioni con
yarn logs -applicationId <Insert_Your_Application_ID>. - Esaminare e recuperare i log di YARN Resource Manager nella directory
/var/log/hadoop-yarn/yarn. - Se questa procedura non risolve il problema, contattare il team Microsoft Azure HDInsight per supporto e fornire i log indicati con le indicazioni su data e ora.
- Controllare se il processo è stato inviato a YARN. In caso contrario, usare
Codice errore: 2303
Messaggio:
Hadoop job failed with transient exit code '%exitCode;'. See '%logPath;/stderr' for more details. Alternatively, open the Ambari UI on the HDI cluster and find the logs for the job '%jobId;'. Try again or contact HDInsight team for further support.Causa: l'errore si è verificato dopo l'invio del processo al cluster HDI.
Raccomandazione:
- Controllare l'interfaccia utente di Ambari:
- Verificare che tutti i servizi siano ancora in esecuzione.
- Nell'interfaccia utente di Ambari, controllare la sezione degli avvisi della dashboard.
- Per altre informazioni su avvisi e relative soluzioni, vedere Gestione e monitoraggio di un cluster.
- Controllare la memoria YARN. Se l'uso di memoria YARN è alto, l'elaborazione dei processi potrebbe subire ritardi. Se le risorse disponibili non sono sufficienti per gestire l'applicazione o il processo Spark, aumentare il numero di istanze del cluster per garantire che il cluster abbia memoria e core sufficienti.
- Eseguire un processo di esempio.
- Se si esegue lo stesso processo nel back-end HDInsight, verificare che sia stato completato. Per esempi di esecuzione, vedere Eseguire gli esempi di MapReduce inclusi in HDInsight
- Se il processo non è ancora riuscito in HDInsight, identificare i registri e le informazioni dell'applicazione da fornire all'assistenza:
- Controllare se il processo è stato inviato a YARN. In caso contrario, usare
--master yarn. - Se l'esecuzione dell'applicazione è stata completata, recuperare ora di inizio e di fine dell'applicazione YARN. Se l'esecuzione dell'applicazione non è stata completata, recuperare l'ora di inizio/avvio.
- Esaminare e recuperare il registro applicazioni con
yarn logs -applicationId <Insert_Your_Application_ID>. - Esaminare e recuperare i log di YARN Resource Manager nella directory
/var/log/hadoop-yarn/yarn. - Se questa procedura non risolve il problema, contattare il team Microsoft Azure HDInsight per supporto e fornire i log indicati con le indicazioni su data e ora.
- Controllare se il processo è stato inviato a YARN. In caso contrario, usare
Codice errore: 2304
Messaggio:
MSI authentication is not supported on storages for HDI activities.Causa: i servizi di archiviazione collegati usati nel servizio HDInsight (HDI) o nell'attività HDI sono configurati con un'autenticazione MSI non supportata.
Consiglio: fornire stringhe di connessione complete per gli account di archiviazione usati nel servizio HDI collegato o nell'attività HDI.
Codice errore: 2305
Messaggio:
Failed to initialize the HDInsight client for the cluster '%cluster;'. Error: '%message;'Causa: le informazioni di connessione per il cluster HDI non sono corrette, l'utente indicato non dispone delle autorizzazioni per eseguire l'azione richiesta o il servizio HDInsight non riesce a rispondere alle richieste di Azure Data Factory.
Consiglio: verificare che le informazioni dell'utente siano corrette e che sia possibile aprire l'interfaccia utente di Ambari per il cluster HDI in un browser nella macchina virtuale in cui è installato il runtime di integrazione (in caso di runtime di integrazione self-hosted), o in un qualsiasi computer (per Azure IR).
Codice errore: 2306
Messaggio:
An invalid json is provided for script action '%scriptActionName;'. Error: '%message;'Causa: il file JSON fornito per l'azione di scripting non è valido.
Consiglio: il messaggio di errore dovrebbe consentire di identificare il problema. Correggere la configurazione JSON e riprovare.
Per altre informazioni vedere Servizio collegato Azure HDInsight su richiesta.
Codice errore: 2310
Messaggio:
Failed to submit Spark job. Error: '%message;'Causa: il servizio ha provato a creare un batch in un cluster Spark usando l'API Livy (livy/batch), ma ha ricevuto un errore.
Consiglio: per correggere il problema, attenersi al messaggio di errore. Se le informazioni non sono sufficienti per risolverlo, contattare il team HDI e fornire ID del batch e ID del processo, disponibili nell'output dell'attività eseguita all'interno della pagina di monitoraggio del servizio. Per una risoluzione dei problemi più approfondita, recuperare il log completo del processo batch.
Per altre informazioni su come recuperare il log completo, vedere Ottenere il log completo di un processo batch.
Codice errore: 2312
Messaggio:
Spark job failed, batch id:%batchId;. Please follow the links in the activity run Output from the service Monitoring page to troubleshoot the run on HDInsight Spark cluster. Please contact HDInsight support team for further assistance.Causa: errore del processo nel cluster HDInsight Spark.
Consiglio: per risolvere i problemi di esecuzione nel cluster HDInsight Spark, vedere i collegamenti nell'output dell'attività eseguita all'interno della pagina di monitoraggio del servizio. Contattare il team di supporto di HDInsight per ricevere assistenza.
Per altre informazioni su come recuperare il log completo, vedere Ottenere il log completo di un processo batch.
Codice errore: 2313
Messaggio:
The batch with ID '%batchId;' was not found on Spark cluster. Open the Spark History UI and try to find it there. Contact HDInsight support for further assistance.Causa: il batch è stato eliminato nel cluster HDInsight Spark.
Consiglio: risolvere i problemi relativi ai batch nel cluster HDInsight Spark. Contattare l'assistenza di HDInsight per richiedere supporto.
Per altre informazioni su come raccogliere il log completo, vedere Ottenere il log completo di un processo batch e condividere il log completo con il supporto di HDInsight per un'assistenza più approfondita.
Codice errore: 2328
Messaggio:
Failed to create the on demand HDI cluster. Cluster or linked service name: '%clusterName;', error: '%message;'Causa: il messaggio di errore include i dettagli relativi al problema.
Consiglio: il messaggio di errore dovrebbe consentire di risolvere il problema.
Codice errore: 2329
Messaggio:
Failed to delete the on demand HDI cluster. Cluster or linked service name: '%clusterName;', error: '%message;'Causa: il messaggio di errore include i dettagli relativi al problema.
Consiglio: il messaggio di errore dovrebbe consentire di risolvere il problema.
Codice errore: 2331
Messaggio:
The file path should not be null or empty.Causa: il percorso del file specificato è vuoto.
Consiglio: fornire il percorso di un file esistente.
Codice errore: 2340
Messaggio:
HDInsightOnDemand linked service does not support execution via SelfHosted IR. Your IR name is '%IRName;'. Please select an Azure IR instead.Causa: il servizio HDInsightOnDemand collegato non supporta l'esecuzione tramite il runtime di integrazione self-hosted.
Consiglio: selezionare un runtime di integrazione Azure e riprovare.
Codice errore: 2341
Messaggio:
HDInsight cluster URL '%clusterUrl;' is incorrect, it must be in URI format and the scheme must be 'https'.Causa: il formato dell'URL specificato non è corretto.
Consiglio: correggere l'URL del cluster e riprovare.
Codice errore: 2342
Messaggio:
Failed to connect to HDInsight cluster: '%errorMessage;'.Causa: le credenziali specificate non sono corrette per il cluster o si è verificato un problema di configurazione della rete o di connessione, oppure il runtime di integrazione non riesce a collegarsi al cluster.
Raccomandazione:
verificare che le credenziali siano corrette aprendo l'interfaccia utente di Ambari per il cluster HDInsight in un browser.
Se il cluster si trova in una rete virtuale (VNet) e si usa un runtime di integrazione self-hosted, l'URL di HDI deve essere quello privato nelle reti virtuali e dopo il nome del cluster deve essere specificato
-int.Puoi ad esempio modificare
https://mycluster.azurehdinsight.net/inhttps://mycluster-int.azurehdinsight.net/. Notare-intdopomycluster, ma prima di.azurehdinsight.netSe il cluster si trova nella VNet, si usa il runtime di integrazione self-hosted e l'URL privato e si verificano ancora problemi di connessione, la macchina virtuale in cui è installato il runtime di integrazione non riesce a connettersi a HDI.
Collegarsi alla macchina virtuale in cui è installato il runtime di integrazione e aprire l'interfaccia utente di Ambari in un browser. Per il cluster, usare l'URL privato. Dal browser la connessione dovrebbe funzionare. In caso contrario, contattare il team di supporto HDInsight per ricevere assistenza.
Se non si usa un runtime di integrazione self-hosted, dovrebbe essere possibile accedere pubblicamente al cluster HDI. Aprire l'interfaccia utente di Ambari in un browser e verificare che si apra correttamente. In caso di problemi con il cluster o i relativi servizi, contattare il team di supporto HDInsight per ricevere assistenza.
Il runtime di integrazione (self-hosted o di Azure) deve essere in grado di accedere all'URL del cluster HDI usato nel servizio collegato per consentire la connessione di test e il funzionamento delle esecuzioni. Questo stato può essere verificato aprendo l'URL da un browser da una macchina virtuale o da un computer pubblico.
Codice errore: 2343
Messaggio:
User name and password cannot be null or empty to connect to the HDInsight cluster.Causa: password o nome utente non inseriti.
Consiglio: specificare le credenziali corrette per la connessione a HDI e riprovare.
Codice errore: 2345
Messaggio:
Failed to read the content of the hive script. Error: '%message;'Causa: file di script non esistente o il servizio non riesce a connettersi al percorso dello script.
Consiglio: verificare che lo script sia presente e che le credenziali del servizio collegato associato siano corrette per consentire la connessione.
Codice errore: 2346
Messaggio:
Failed to create ODBC connection to the HDI cluster with error message '%message;'.Causa: il servizio ha tentato di stabilire una connessione ODBC (Open Database Connectivity) al cluster HDI, ma il tentativo non è andato a buon fine a causa di un errore.
Raccomandazione:
- verificare di aver configurato correttamente la connessione ODBC/JDBC (Java Database Connectivity) connection.
- Per JDBC, se si usa la stessa rete virtuale, è possibile ottenere la connessione da:
Hive -> Summary -> HIVESERVER2 JDBC URL - Per assicurarsi che la configurazione di JDBC sia corretta, vedere Eseguire una query Apache Hive tramite il driver JDBC in HDInsight.
- Per Open Database (ODB), vedere Esercitazione: Eseguire una query in Apache Hive con ODBC e PowerShell per assicurarsi che la configurazione sia corretta.
- Per JDBC, se si usa la stessa rete virtuale, è possibile ottenere la connessione da:
- Verificare che Hiveserver2, Hive Metastore e Hiveserver2 Interactive siano attivi e in funzione.
- Controllare l'interfaccia utente di Ambari:
- Verificare che tutti i servizi siano ancora in esecuzione.
- Esaminare la sezione degli avvisi nella dashboard all'interno dell'interfaccia utente di Ambari.
- Per altre informazioni su avvisi e relative soluzioni, vedere Gestione e monitoraggio di un cluster.
- Se questa procedura non ha consentito di risolvere il problema, contattare il team di Microsoft Azure HDInsight.
- verificare di aver configurato correttamente la connessione ODBC/JDBC (Java Database Connectivity) connection.
Codice errore: 2347
Messaggio:
Hive execution through ODBC failed with error message '%message;'.Causa: il servizio ha inviato lo script hive per l'esecuzione al cluster HDI con una connessione ODBC e lo script non è andato a buon fine in HDI.
Raccomandazione:
- verificare di aver configurato correttamente la connessione ODBC/JDBC (Java Database Connectivity) connection.
- Per JDBC, se si usa la stessa rete virtuale, è possibile ottenere la connessione da:
Hive -> Summary -> HIVESERVER2 JDBC URL - Per assicurarsi che la configurazione di JDBC sia corretta, vedere Eseguire una query Apache Hive tramite il driver JDBC in HDInsight.
- Per Open Database (ODB), vedere Esercitazione: Eseguire una query in Apache Hive con ODBC e PowerShell per assicurarsi che la configurazione sia corretta.
- Per JDBC, se si usa la stessa rete virtuale, è possibile ottenere la connessione da:
- Verificare che Hiveserver2, Hive Metastore e Hiveserver2 Interactive siano attivi e in funzione.
- Controllare l'interfaccia utente di Ambari:
- Verificare che tutti i servizi siano ancora in esecuzione.
- Esaminare la sezione degli avvisi nella dashboard all'interno dell'interfaccia utente di Ambari.
- Per altre informazioni su avvisi e relative soluzioni, vedere Gestione e monitoraggio di un cluster.
- Se questa procedura non ha consentito di risolvere il problema, contattare il team di Microsoft Azure HDInsight.
- verificare di aver configurato correttamente la connessione ODBC/JDBC (Java Database Connectivity) connection.
Codice errore: 2348
Messaggio:
The main storage has not been initialized. Please check the properties of the storage linked service in the HDI linked service.Causa: le proprietà del servizio di archiviazione collegato non sono configurate correttamente.
Consiglio: nel servizio di archiviazione collegato per le attività HDI sono supportate solo le stringhe di connessione complete. Verificare che non siano in uso autorizzazioni o applicazioni MSI.
Codice errore: 2350
Messaggio:
Failed to prepare the files for the run '%jobId;'. HDI cluster: '%cluster;', Error: '%errorMessage;'Causa: le credenziali fornite per la connessione alla risorsa di archiviazione in cui si trova il file non sono corrette o il file non esiste.
Consiglio: questo errore si verifica quando il servizio si prepara per le attività HDI e tenta di copiare i file nella risorsa di archiviazione principale prima di inviare il processo a HDI. Verificare che il file sia presente nel percorso specificato e che la connessione alla risorsa di archiviazione funzioni correttamente. Poiché le attività HDI non supportano l'autenticazione MSI negli account di archiviazione relativi alle attività HDI, verificare che le chiavi dei servizi collegati siano complete o che sia in uso Azure Key Vault.
Codice errore: 2351
Messaggio:
Could not open the file '%filePath;' in container/fileSystem '%container;'.Causa: il file non è presente nel percorso indicato.
Consiglio: controllare se il file è presente e che le credenziali del servizio collegato, con le informazioni di connessione che rimandano a questo file, siano corrette.
Codice errore: 2352
Messaggio:
The file storage has not been initialized. Please check the properties of the file storage linked service in the HDI activity.Causa: le proprietà del servizio di archiviazione file collegato non sono configurate correttamente.
Consiglio: verificare che le proprietà del servizio di archiviazione file collegato siano configurate correttamente.
Codice errore: 2353
Messaggio:
The script storage has not been initialized. Please check the properties of the script storage linked service in the HDI activity.Causa: le proprietà del servizio di archiviazione script collegato non sono configurate correttamente.
Consiglio: verificare che le proprietà del servizio di archiviazione script collegato siano configurate correttamente.
Codice errore: 2354
Messaggio:
The storage linked service type '%linkedServiceType;' is not supported for '%executorType;' activities for property '%linkedServicePropertyName;'.Causa: il tipo di servizio di archiviazione collegato non è supportato dall'attività.
Consiglio: verificare che il tipo di servizio collegato selezionato sia uno di quelli supportati dall'attività. Le attività HDI supportano i servizi collegati AzureBlobStorage e AzureBlobFSStorage.
Per altre informazioni, vedere Confronto delle opzioni di archiviazione disponibili per l'uso con cluster Azure HDInsight
Codice errore: 2355
Messaggio:
The '%value' provided for commandEnvironment is incorrect. The expected value should be an array of strings where each string has the format CmdEnvVarName=CmdEnvVarValue.Causa: il valore specificato per
commandEnvironmentnon è corretto.Consiglio: verificare che il valore indicato sia simile a:
\"variableName=variableValue\" ]Controllare anche che tutte le variabili siano presenti solo una volta nell'elenco.
Codice errore: 2356
Messaggio:
The commandEnvironment already contains a variable named '%variableName;'.Causa: il valore specificato per
commandEnvironmentnon è corretto.Consiglio: verificare che il valore indicato sia simile a:
\"variableName=variableValue\" ]Controllare anche che tutte le variabili siano presenti solo una volta nell'elenco.
Codice errore: 2357
Messaggio:
The certificate or password is wrong for ADLS Gen 1 storage.Causa: le credenziali specificate non sono corrette.
Consiglio: verificare che nelle informazioni di connessione in ADLS Gen 1 sia presente il collegamento al servizio e che la connessione di test vada a buon fine.
Codice errore: 2358
Messaggio:
The value '%value;' for the required property 'TimeToLive' in the on demand HDInsight linked service '%linkedServiceName;' has invalid format. It should be a timespan between '00:05:00' and '24:00:00'.Causa: il formato del valore indicato per la proprietà richiesta
TimeToLivenon è valido.Consiglio: aggiornare il valore all'intervallo suggerito e riprovare.
Codice errore: 2359
Messaggio:
The value '%value;' for the property 'roles' is invalid. Expected types are 'zookeeper', 'headnode', and 'workernode'.Causa: il valore fornito per la proprietà
rolesnon è valido.Consiglio: aggiornare il valore con uno di quelli suggeriti e riprovare.
Codice errore: 2360
Messaggio:
The connection string in HCatalogLinkedService is invalid. Encountered an error while trying to parse: '%message;'.Causa: la stringa di connessione specificata per
HCatalogLinkedServicenon è valida.Consiglio: aggiornare il valore con una stringa di connessione Azure SQL corretta e riprovare.
Codice errore: 2361
Messaggio:
Failed to create on demand HDI cluster. Cluster name is '%clusterName;'.Causa: creazione del cluster non riuscita, il servizio non ha ricevuto un errore dal servizio HDInsight.
Consiglio: aprire il portale di Azure e cercare la risorsa HDI con il nome fornito, quindi controllare lo stato di provisioning. Contattare il team di supporto di HDInsight per ricevere assistenza.
Codice errore: 2362
Messaggio:
Only Azure Blob storage accounts are supported as additional storages for HDInsight on demand linked service.Causa: la risorsa di archiviazione specificata non è un archivio BLOB di Azure.
Consiglio: indicare un account di archiviazione BLOB di Azure come account di archiviazione aggiuntivo per il servizio HDInsight su richiesta collegato.
Errore SSL quando il servizio collegato usa il cluster ESP HDInsight
Messaggio:
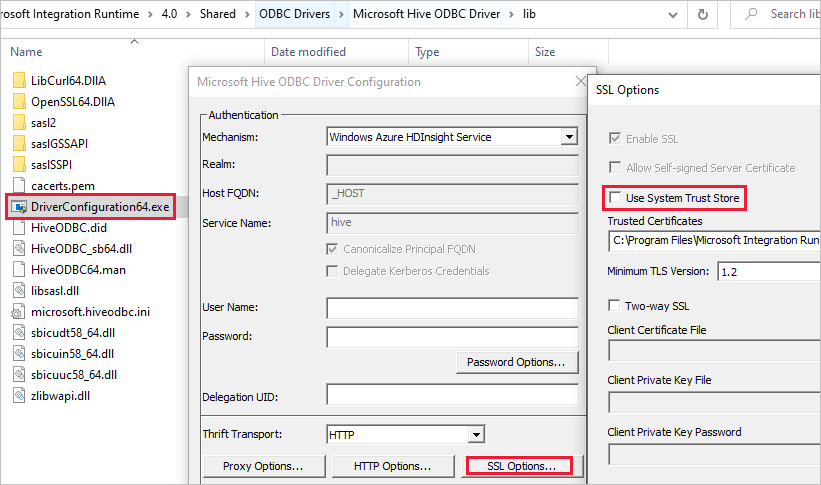
Failed to connect to HDInsight cluster: 'ERROR [HY000] [Microsoft][DriverSupport] (1100) SSL certificate verification failed because the certificate is missing or incorrect.'Causa: il problema è probabilmente correlato all'archivio attendibilità del sistema.
Risoluzione: è possibile passare al percorso Microsoft Integration Runtime\4.0\Shared\ODBC Drivers\Microsoft Hive ODBC Driver\lib e aprire DriverConfiguration64.exe per modificare l'impostazione.
Attività HDI bloccata durante la preparazione del cluster
Se l'attività HDI è bloccata durante la preparazione del cluster, seguire le linee guida seguenti:
Assicurarsi che il timeout sia maggiore di quello descritto di seguito e attendere il completamento dell'esecuzione o il timeout, quindi attendere ii Time To Live (TTL) prima di inviare nuovi processi.
Il tempo predefinito massimo necessario per l'avviamento di un cluster è di 2 ore e, se si dispone di uno script init, si aggiungeranno massimo altre 2 ore.
Assicurarsi che sia stato effettuato il provisioning dell'archiviazione e dell'infrastruttura HDI nella stessa area.
Assicurarsi che l'entità servizio usata per accedere al cluster HDI sia valida.
Se il problema persiste, come soluzione alternativa, eliminare il servizio collegato HDI e ricrearlo con un nuovo nome.
Attività Web
Codice errore: 2001
Messaggio:
The length of execution output is over limit (around 4MB currently).Causa: l'output di esecuzione è maggiore di 4 MB, ma la dimensione massima supportata del payload della risposta di output è di 4 MB.
Consiglio: assicurarsi che le dimensioni dell'output di esecuzione non superino i 4 MB. Per altre informazioni, vedere Come sfruttare lo Scale Out per le dimensioni dello spostamento dei dati usando Azure Data Factory.
Codice errore: 2002
Messaggio:
The payload including configurations on activity/dataSet/linked service is too large. Please check if you have settings with very large value and try to reduce its size.Causa: il payload che si sta tentando di inviare è troppo grande.
Consiglio: fare riferimento a Payload troppo grande.
Codice errore: 2003
Messaggio:
There are substantial concurrent external activity executions which is causing failures due to throttling under subscription <subscription id>, region <region code> and limitation <current limit>. Please reduce the concurrent executions. For limits, refer https://aka.ms/adflimits.Causa: troppe attività eseguite contemporaneamente. Ciò può verificarsi quando un numero eccessivo di pipeline viene attivato contemporaneamente.
Consiglio: ridurre la concorrenza della pipeline. Potrebbe essere necessario distribuire il tempo di trigger delle pipeline.
Codice errore: 2010
Messaggio:
The Self-hosted Integration Runtime ‘<SHIR name>’ is offlineCausa: il runtime di integrazione self-hosted è offline o il runtime di integrazione di Azure è scaduto o non è registrato.
Consiglio: assicurarsi che il runtime di integrazione self-hosted sia operativo. Per altre informazioni, vedere Risolvere i problemi relativi al runtime di integrazione self-hosted.
Codice errore: 2105
Messaggio:
The value type '<provided data type>', in key '<key name>' is not expected type '<expected data type>'Causa: i dati generati nell'espressione di contenuto dinamico non corrispondono alla chiave e causano un errore di analisi JSON.
Consiglio: esaminare il campo chiave e correggere la definizione del contenuto dinamico.
Codice errore: 2108
Messaggio:
Error calling the endpoint '<URL>'. Response status code: 'NA - Unknown'. More details: Exception message: 'NA - Unknown [ClientSideException] Invalid Url: <URL>. Please verify Url or integration runtime is valid and retry. Localhost URLs are allowed only with SelfHosted Integration Runtime'Causa: impossibile raggiungere l'URL specificato. Ciò può verificarsi a seguito di un problema di connessione di rete, se l'URL non è risolvibile o se è stato usato un URL localhost in un runtime di integrazione di Azure.
Consiglio: verificare che l'URL fornito sia accessibile.
Messaggio:
Error calling the endpoint '%url;'. Response status code: '%code;'Causa: la richiesta non è andata a buon fine per un problema sottostante relativo, ad esempio alla connettività di rete, per un errore DNS, per la convalida del certificato del server o per un timeout.
Consiglio: usare Fiddler/Netmon/Wireshark per convalidare la richiesta.
Uso di Fiddler
Uso di Fiddler per creare una sessione HTTP dell'applicazione Web monitorata:
Scaricare, installare e aprire Fiddler.
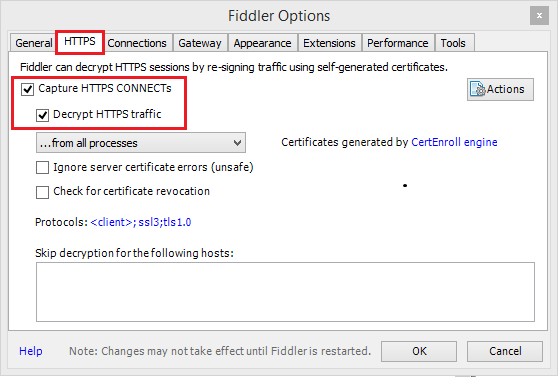
Se l'applicazione Web usa HTTPS, aprire Tools (Strumenti)>Options (Opzioni)>HTTPS.
Nella scheda HTTPS, selezionare sia Capture HTTPS CONNECTs (Acquisisci connessioni HTTP) che Decrypt HTTPS traffic (Decrittografa traffico HTTPS).
Se l'applicazione usa certificati TLS/SSL, aggiungere il certificato di Fiddler al dispositivo.
Passare a Strumenti>Opzioni Fiddler>HTTPS>Azioni>Esporta certificato radice sul desktop.
Disattivare l'acquisizione in File>Capture Traffic (Acquisisci traffico). In alternativa, premere F12.
Cancellare la cache del browser in modo che tutti gli elementi presenti vengano rimossi e debbano essere scaricati di nuovo.
Creare una richiesta:
Selezionare la scheda Composer (Compositore).
Configurare il metodo HTTP e l'URL.
Se necessario, aggiungere intestazioni e un corpo della richiesta.
Seleziona Execute.
Attivare di nuovo l'acquisizione del traffico e completare la transazione problematica nella pagina.
Passare a: File>Salva>Tutte le sessioni.
Per altre informazioni, vedere Getting started with Fiddler (Introduzione a Fiddler).
Codice errore: 2113
Messaggio:
ExtractAuthorizationCertificate: Unable to generate a certificate from a Base64 string/password combinationCausa: impossibile generare il certificato dalla combinazione di stringa/password Base64.
Consiglio: verificare che la combinazione di certificato PFX e password con codifica Base64 in uso sia immessa correttamente.
Codice errore: 2403
Messaggio:
Get access token from MSI failed for Datafactory <DF mname>, region <region code>. Please verify resource url is valid and retry.Causa: impossibile acquisire un token di accesso dall'URL della risorsa specificato.
Consiglio: verificare di aver specificato l'URL della risorsa corretto per l'identità gestita.
Generali
Errore NULL del token di continuazione REST
Messaggio di errore: {"token":null,"range":{"min":..}
Causa: quando si eseguono query su più partizioni/pagine, il servizio back-end restituisce il token di continuazione in formato JObject con 3 proprietà: token, intervalli di chiavi min e max, ad esempio {"token":null,"range":{"min":"05C1E9AB0DAD76","max":"05C1E9CD673398"}}). A seconda dei dati di origine, l'esecuzione di query può restituire 0, il che indica un token mancante anche se sono presenti più dati da recuperare.
Consiglio: quando continuationToken è diverso da null, come stringa {"token":null,"range":{"min":"05C1E9AB0DAD76","max":"05C1E9CD673398"}}, è necessario chiamare nuovamente l'API queryActivityRuns con il token di continuazione della risposta precedente. È necessario passare di nuovo la stringa completa per l'API di query. Le attività verranno restituite nelle pagine successive per il risultato della query. È consigliabile ignorare la presenza di una matrice vuota nella pagina. Finché il valore di continuationToken completo ! è uguale a null, è necessario continuare a eseguire query. Per altre informazioni, vedere API REST per la query di esecuzione della pipeline.
Problema di attività bloccata
Quando si osserva che l'attività è in esecuzione per un periodo molto più lungo rispetto alle normali esecuzioni e non presenta progressi, potrebbe essere bloccata. È possibile provare ad annullarla e riprovare per verificare se il problema si risolve. Se si tratta di un'attività di copia, è possibile ottenere informazioni sul monitoraggio delle prestazioni e sulla risoluzione dei problemi in Risolvere i problemi relativi alle prestazioni dell'attività di copia; se si tratta di un flusso di dati, consultare Mapping delle prestazioni dei flussi di dati e la guida all'ottimizzazione.
Il Payload è troppo grande
Messaggio di errore: The payload including configurations on activity/dataSet/linked service is too large. Please check if you have settings with very large value and try to reduce its size.
Causa: il payload per ogni esecuzione attività include la configurazione dell'attività, le configurazioni associate di set di dati e servizi collegati, se disponibili, e una piccola percentuale di proprietà di sistema generate per tipo di attività. Il limite di queste dimensioni del payload è 896 kB, come indicato nella documentazione relativa ai limiti di Azure per Data Factory e Azure Synapse Analytics.
Consiglio: è probabile che questo limite venga raggiunto perché si passano uno o più valori di parametri di grandi dimensioni dall'output dell'attività upstream o dall'esterno, soprattutto se si passano dati effettivi tra le attività nel flusso di controllo. Controllare se è possibile ridurre le dimensioni dei valori dei parametri di grandi dimensioni o ottimizzare la logica della pipeline per evitare di passare tali valori tra le attività e gestirli all'interno dell'attività.
La compressione non supportata causa il danneggiamento dei file
Sintomi: si tenta di decomprimere un file archiviato in un contenitore BLOB. Una singola attività di copia in una pipeline ha un'origine con il tipo di compressione impostato su "deflate64" (o qualsiasi tipo non supportato). Questa attività viene eseguita correttamente e produce il file di testo contenuto nel file ZIP. Tuttavia, si è verificato un problema con il testo nel file e quest'ultimo sembra danneggiato. Quando questo file viene decompresso localmente, l'approccio è corretto.
Causa: il file ZIP è compresso dall'algoritmo "deflate64", mentre la libreria ZIP interna di Azure Data Factory supporta solo "deflate". Se il file ZIP è compresso dal sistema Windows e le dimensioni complessive del file superano un determinato numero, Windows userà "deflate64" per impostazione predefinita, un metodo non supportato in Azure Data Factory. D'altra parte, se le dimensioni del file sono inferiori o se si usano alcuni strumenti ZIP di terze parti che supportano la specifica dell'algoritmo di compressione, Windows userà "deflate" per impostazione predefinita.
Suggerimento
In realtà, sia Formato binario in Azure Data Factory e Synapse Analytics che Formato di testo delimitato in Azure Data Factory e Azure Synapse Analytics indicano chiaramente che il formato "deflate64" non è supportato in Azure Data Factory.
Esegui pipeline passa il parametro della matrice come stringa alla pipeline figlio
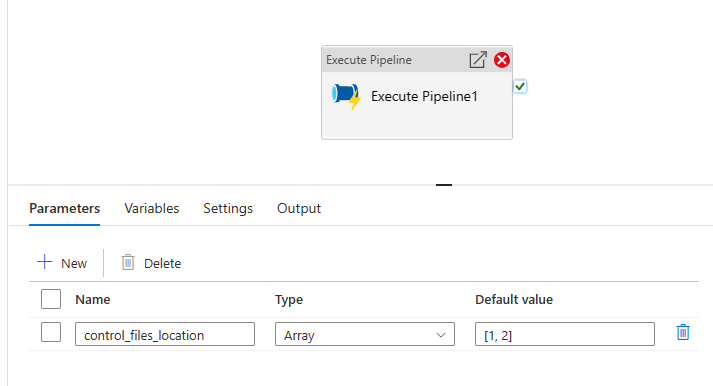
Messaggio di errore: Operation on target ForEach1 failed: The execution of template action 'MainForEach1' failed: the result of the evaluation of 'foreach' expression '@pipeline().parameters.<parameterName>' is of type 'String'. The result must be a valid array.
Causa: anche se nella pipeline di esecuzione si crea il parametro di matrice di tipo, come illustrato nell'immagine seguente, la pipeline avrà esito negativo.
Ciò è dovuto al fatto che il payload viene passato dalla pipeline padre al figlio come stringa. È possibile vederlo quando si controlla l'input passato alla pipeline figlio.
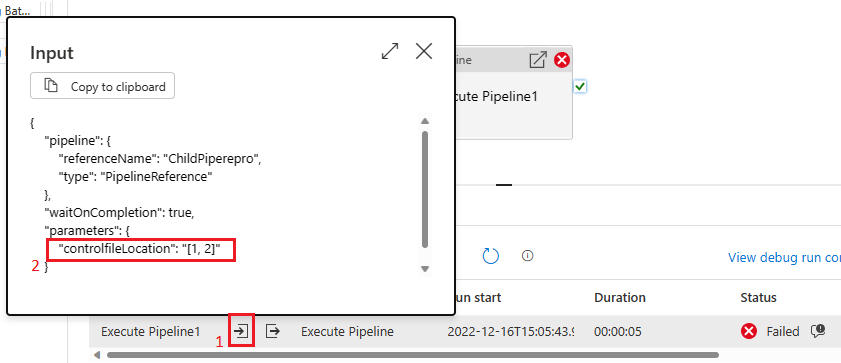
Consiglio: per risolvere il problema, è possibile sfruttare la funzione di creazione della matrice come illustrato nell'immagine seguente.
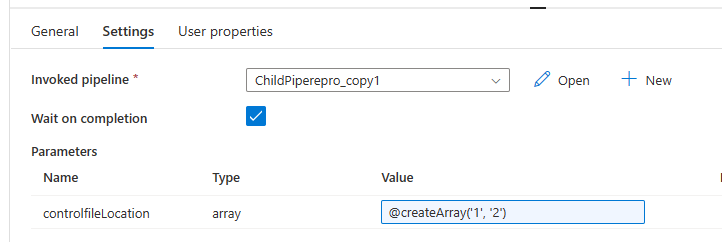
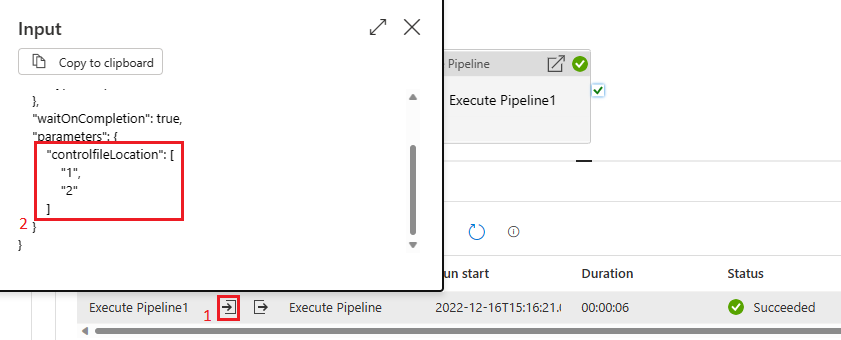
La pipeline avrà quindi esito positivo. E possiamo vedere nella casella di input che il parametro passato è una matrice.
Contenuto correlato
Per altre informazioni sulla risoluzione dei problemi, usare le risorse seguenti: