Eseguire il debug di processi Apache Spark in esecuzione in Azure HDInsight
Questo articolo illustra come tenere traccia ed eseguire il debug di processi Apache Spark in esecuzione nei cluster HDInsight. Eseguire il debug usando l'interfaccia utente yarn di Apache Hadoop, l'interfaccia utente di Spark e il server cronologia Spark. Si avvierà un processo Spark usando un notebook disponibile nel cluster Spark, Machine Learning: analisi predittiva dei dati del controllo degli alimenti tramite MLlib. Usare la procedura seguente per tenere traccia di un'applicazione inviata usando anche qualsiasi altro approccio, ad esempio spark-submit.
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
Un cluster Apache Spark in HDInsight. Per istruzioni, vedere l'articolo dedicato alla creazione di cluster Apache Spark in Azure HDInsight.
Si sarà già avviato il notebook Machine Learning: analisi predittiva dei dati del controllo degli alimenti tramite MLlib. Per istruzioni su come eseguire questo notebook, seguire il collegamento.
Tenere traccia di un'applicazione nell'interfaccia utente di YARN
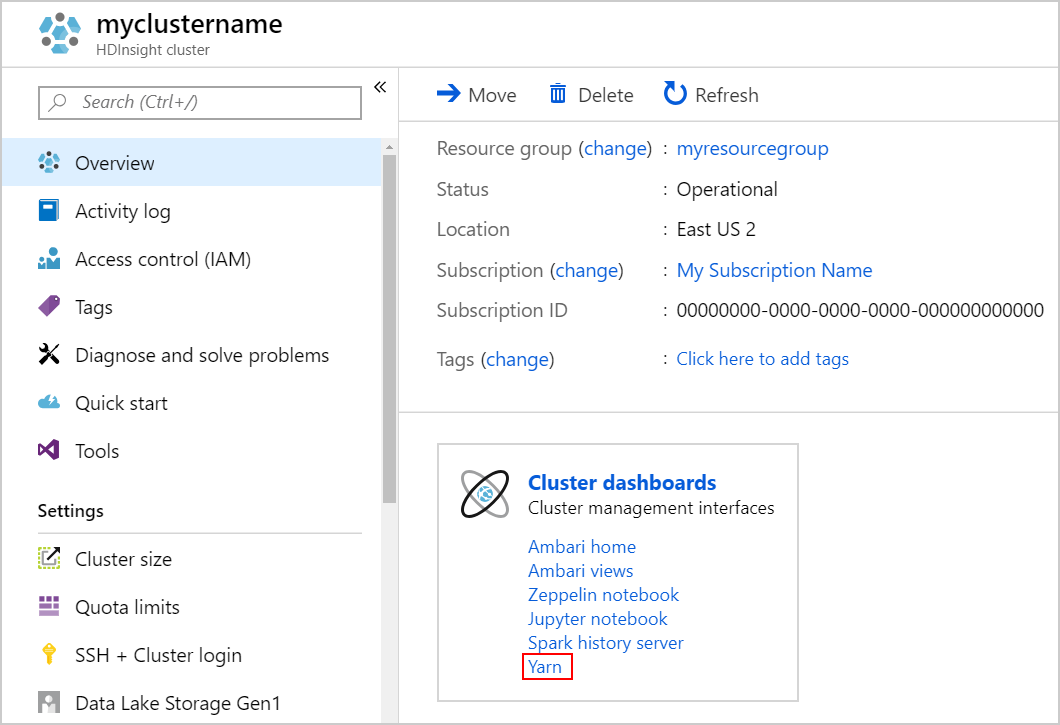
Avviare l'interfaccia utente di YARN Selezionare Yarn in Dashboard cluster.
Suggerimento
In alternativa, è anche possibile avviare l'interfaccia utente di YARN dall'interfaccia utente di Ambari. Per avviare l'interfaccia utente di Ambari, selezionare Home page di Ambari in Dashboard del cluster. Dall'interfaccia utente di Ambari passare a Collegamenti rapidi> YARN>all'interfaccia utente di Resource Manager >attiva.
Poiché è stato avviato il processo Spark con Jupyter Notebooks, l'applicazione ha il nome remotesparkmagics (il nome per tutte le applicazioni avviate dai notebook). Selezionare l'ID applicazione in base al nome dell'applicazione per ottenere altre informazioni sul processo. Questa azione avvia la visualizzazione dell'applicazione.
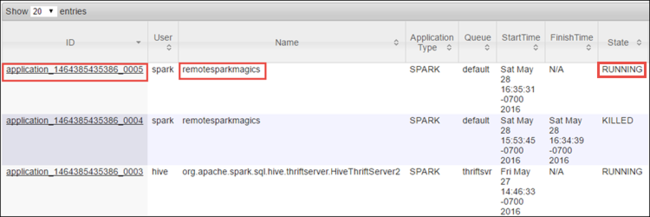
Per tali applicazioni avviate dai notebook di Jupyter, lo stato è sempre IN ESECUZIONE fino a quando non si esce dal notebook.
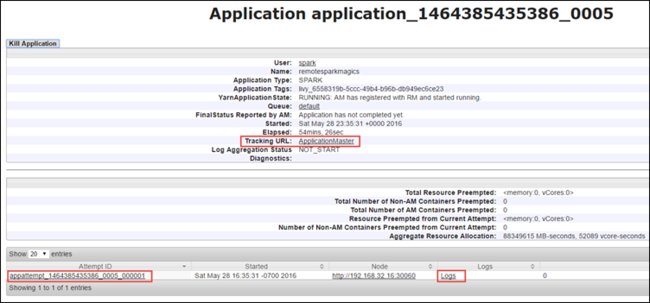
Nella visualizzazione dell'applicazione è possibile eseguire il drill-down per trovare i contenitori associati all'applicazione e i log (stdout o stderr). È anche possibile avviare l'interfaccia utente di Spark facendo clic sul collegamento corrispondente all' URL di verifica, come illustrato di seguito.
Tenere traccia di un'applicazione nell'interfaccia utente di Spark
Nell'interfaccia utente di Spark è possibile eseguire il drill-down dei processi Spark generati dall'applicazione avviata in precedenza.
Per avviare l'interfaccia utente di Spark, dalla visualizzazione dell'applicazione selezionare il collegamento rispetto all'URL di rilevamento, come illustrato nella schermata precedente. È possibile visualizzare tutti i processi Spark avviati dall'applicazione in esecuzione in Jupyter Notebook.
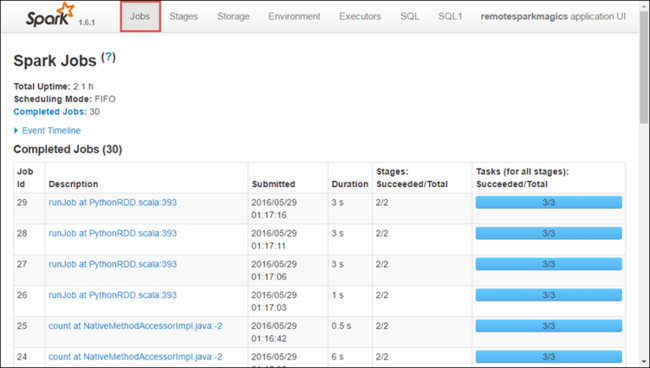
Selezionare la scheda Execuors (Executor ) per visualizzare le informazioni di elaborazione e archiviazione per ogni executor. È anche possibile recuperare lo stack di chiamate selezionando il collegamento Thread Dump .You can also retrieve the call stack by select the Thread Dump link.
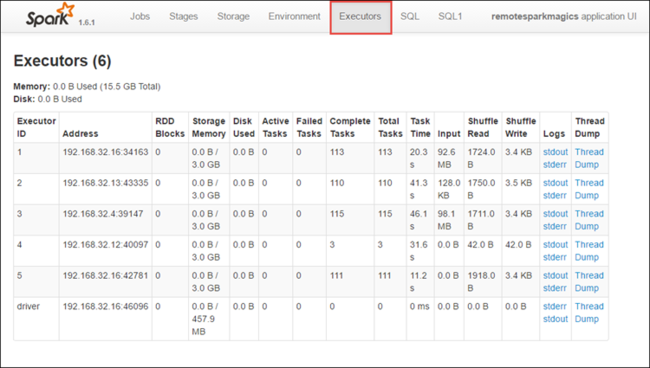
Selezionare la scheda Fasi per visualizzare le fasi associate all'applicazione.
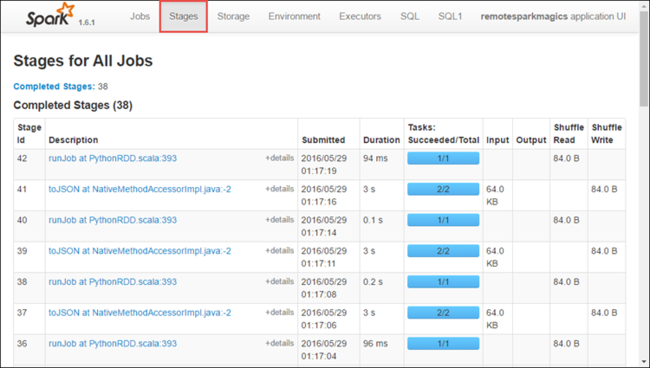
Ogni fase può avere più attività per cui è possibile visualizzare le statistiche di esecuzione, come illustrato di seguito.
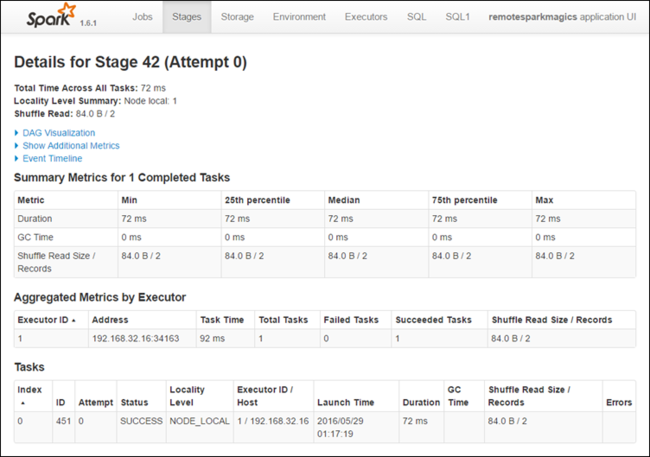
Nella pagina dei dettagli relativi alle fasi è possibile avviare la visualizzazione DAG. Espandere il collegamento DAG Visualization nella parte superiore della pagina, come illustrato di seguito.
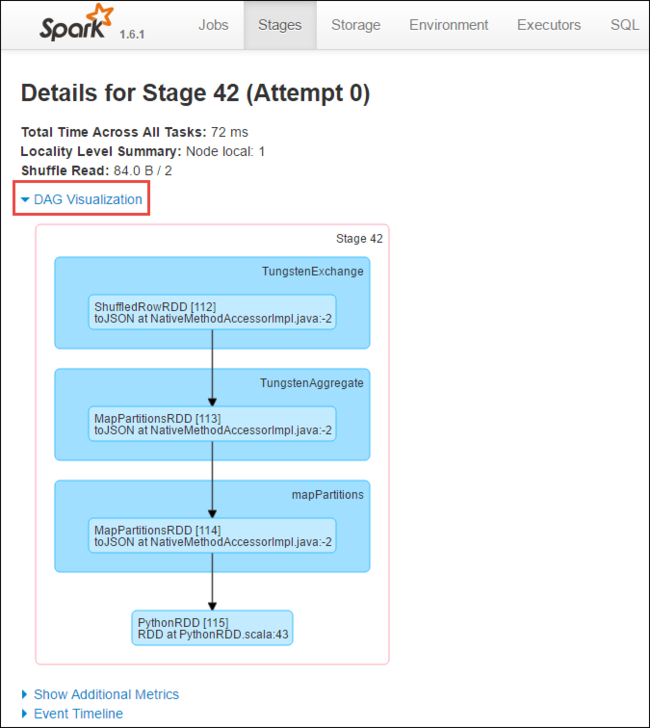
DAG o Direct Aclyic Graph rappresenta le diverse fasi dell'applicazione. Ogni casella blu nel grafico rappresenta un'operazione Spark richiamata dall'applicazione.
Nella pagina dei dettagli relativi alle fasi è anche possibile avviare la visualizzazione della sequenza temporale dell'applicazione. Espandere il collegamento Event Timeline nella parte superiore della pagina, come illustrato di seguito.
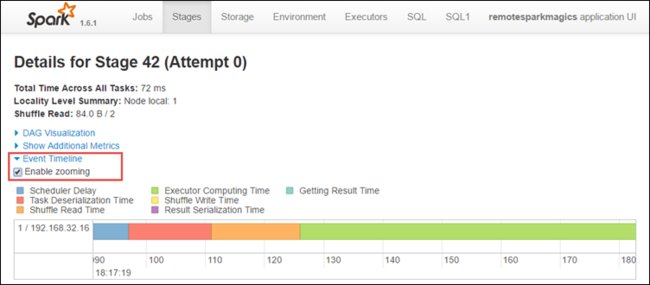
Questa immagine visualizza gli eventi Spark sotto forma di sequenza temporale. La visualizzazione della sequenza temporale è disponibile in tre livelli, tra processi, all'interno di un processo e all'interno di una fase. L'immagine precedente mostra la visualizzazione della sequenza temporale per una determinata fase.
Suggerimento
Se si seleziona la casella di controllo Enable zooming , è possibile scorrere a sinistra e destra nella visualizzazione della sequenza temporale.
Altre schede nell'interfaccia utente di Spark forniscono anche informazioni utili sull'istanza di Spark.
- Archiviazione scheda: se l'applicazione crea un set di dati RDD, è possibile trovare informazioni nella scheda Archiviazione.
- Scheda Ambiente: questa scheda fornisce informazioni utili sull'istanza di Spark, ad esempio:
- Versione di Scala
- Directory dei log eventi associata al cluster
- Numero di core executor per l'applicazione
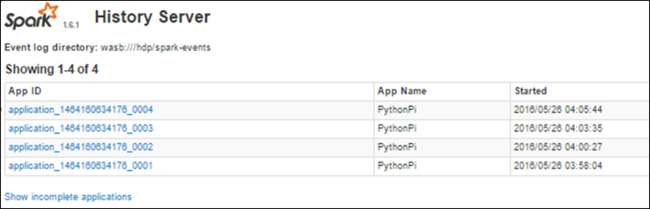
Trovare informazioni sui processi completati tramite Server cronologia Spark
Una volta completato un processo, le informazioni corrispondenti vengono salvate in modo permanente nel Server cronologia Spark.
Per avviare il server cronologia Spark, nella pagina Panoramica selezionare Server cronologia Spark in Dashboard cluster.
Suggerimento
In alternativa, è anche possibile avviare l'interfaccia utente del Server cronologia Spark dall'interfaccia utente di Ambari. Per avviare l'interfaccia utente di Ambari, nel pannello Panoramica selezionare Home di Ambari in Dashboard del cluster. Dall'interfaccia utente di Ambari passare a Spark2 Quick Links Spark2 History Server UI (Interfaccia>utente del server cronologia Spark2).>
Vengono elencate tutte le applicazioni completate. Selezionare un ID applicazione per eseguire il drill-down in un'applicazione per altre informazioni.